Convolutional Neural Networks(4):Feature map size,Padding and Stride
在CNN(1)中,我们用到下图来说明卷积之后feature maps尺寸和深度的变化。这一节中,我们讨论feature map size, padding and stride。
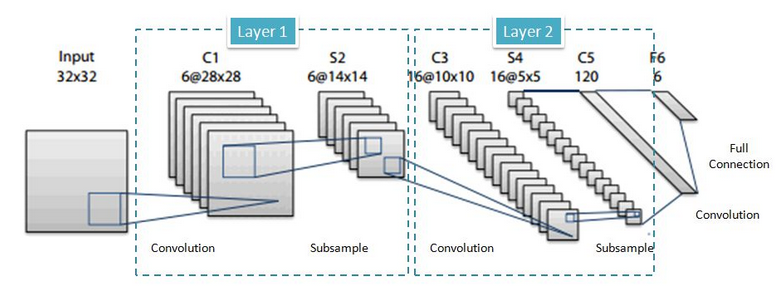
首先,在Layer1中,输入是32x32的图片,而卷积之后为28x28,试问filter的size(no padding)? (答案是5x5)。 如果没答上来,请看下图:
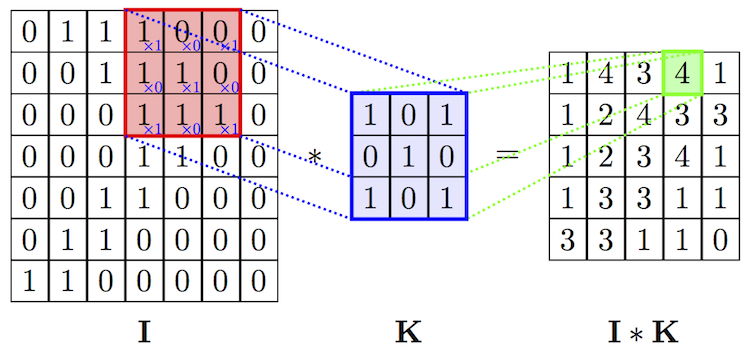
I是一张7x7的图片,filter是3x3的,I*K生成的feature map是5x5的。所以我们推出feature map size公式为:

其中n(l)表示在l层中图片的大小,f(l)是filter的大小所以在最初的问题中filtersize=32-28+1=5。
而在convolution操作中,有一个padding参数可以在原图外围加上空白格,从而使feature map的size不发生变化。通常不使用padding的Convolution称为Valid Convolution,而使用padding输出相同size的feature map,则称为Same Convolution。Feature map和Padding的Size计算公式为:
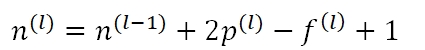
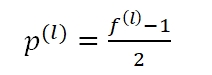
其中,p(l)是padding的大小。使用Padding的原因主要有二:
第一,因为architecture的原因,不希望图片尺寸发生变化;
其二,如果不使用padding,在图片边缘的pixel只被计算了一次,其数据被低估了。
Stride是表示filter工作间隔的参数,默认是1,根据需要可以设置为其他值,在设置了Stride之后,feature map的计算公式为:

其中,s(l)是stride步幅的大小。当然,图片并不都是正方的,我们可以分别计算feature map的width和height
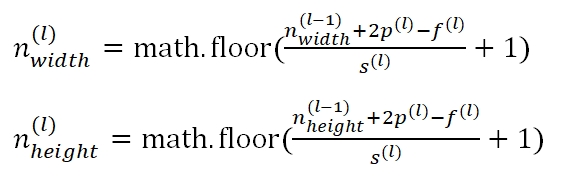
Convolutional Neural Networks(4):Feature map size,Padding and Stride的更多相关文章
- 机器视觉:Convolutional Neural Networks, Receptive Field and Feature Maps
CNN 大概是目前 CV 界最火爆的一款模型了,堪比当年的 SVM.从 2012 年到现在,CNN 已经广泛应用于CV的各个领域,从最初的 classification,到现在的semantic se ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- A Beginner's Guide To Understanding Convolutional Neural Networks(转)
A Beginner's Guide To Understanding Convolutional Neural Networks Introduction Convolutional neural ...
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks Part 2
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
- (转)A Beginner's Guide To Understanding Convolutional Neural Networks
Adit Deshpande CS Undergrad at UCLA ('19) Blog About A Beginner's Guide To Understanding Convolution ...
- [转]An Intuitive Explanation of Convolutional Neural Networks
An Intuitive Explanation of Convolutional Neural Networks https://ujjwalkarn.me/2016/08/11/intuitive ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- 【论文翻译】MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 论文链接:https://arxi ...
- Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/ 里面有很多相当好的文章 http://cs231n.github.io/convolutional-networks/ Table of Cont ...
随机推荐
- Linux安装Python3以及虚拟环境
python3的linux环境编译安装 1.linux下安装软件的方式 选则yum工具,方便,自行解决软件之间的依赖关系,自动下载且安装 1.配置yum源 可以选择阿里云源,清华源等 配置第一个仓库, ...
- Python 的 time 模块导入及其方法
时间模块很重要,Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能,讲解一下Python 的 time 模块导入及其方法. 1,time 模块导入 import time; # ...
- Django - Xadmin (三) 分页、搜索和批量操作
Django - Xadmin (三) 分页.搜索和批量操作 分页和 ShowList 类 因为 list_view 视图函数里面代码太多,太乱,所以将其里面的用于处理表头.处理表单数据的关键代码提取 ...
- .linux基础命令三
一. 两台服务器免密登录: 1. 生成密钥 ssh-keygen的命令手册,通过”man ssh-keygen“命令查看指令: 通过命令”ssh-keygen -t rsa“创建一对密匙,包括公匙和私 ...
- MongoDB的使用学习之(二)简介
原文链接:http://www.cnblogs.com/yxlblogs/p/3681089.html MongoDB 是一个高性能,开源,无模式的文档型数据库,是当前 NoSQL 数据库产品中最热门 ...
- JSP学习(3)
JSP学习(3) JSP内置对象 Web容器创建的一组对象,不使用new关键字就可以使用的内置对象 用户服务器请求 缓冲区:Buffer,就是内存的一块区域,用来保存临时数据. get与post的区别 ...
- ubuntu18.04 设置环境变量
1.第一步:命令行输入 sudo gedit /etc/profile 2.第二步:将你想要设置环境变量的内容追加到文件结尾 例如:export JAVA_HOME=/usr/java/latest ...
- python的list内存分配算法
前提:python为了提高效率会为list预先分配一定的内存空间供其使用,避免在每次append等操作都去申请内存,下面简单分析下list的内存分配算法,主要就是两段. 1.当没有元素时,newsiz ...
- Vue.js 技术揭秘学习 (2) Vue 实例挂载的实现
Vue 中我们是通过 $mount 实例方法去挂载 vm 的 $mount 方法实际上会去调用 mountComponent 方法,mountComponent 核心就是先实例化一个渲染Watcher ...
- Java 逻辑运算符相关解析
问:定简单说说 Java 中 & 与 && 有什么区别?| 与 || 呢? 答:& 是位运算符,&& 是布尔逻辑运算符,| 与 || 类似同理.在进行逻 ...