javaIO--数据流之IO流与字节流
0、IO流
0.1、IO(Input Output)流的概念
Java中将不同设备之间的数据传输抽象为“流”:Stream
设备指的是:磁盘上的文件,网络连接,另一个主机等等
按流向分:输入流,输出流:都是针对内存来说的
- 输入流,只能从其中读取数据
- 输出流,只能把数据放入其中

按每次处理的数据单位分:字节流,字符流
1.字节流:每次处理一个字节
2.字符流:每次处理一个字符

0.2、IO流抽象基类
通常流的分类,如果没有特定指出,都是按操作数据单位来说的
字节流:两个方向
InputStream:输入字节流
OutputStream:输出字节流
字节流继承图:

字符流:两个方向
Reader:输入字符流
Writer:输出字符流
字符流继承图:

1、字节流
1.1字节输出流抽象基类:OutputStream




1.1.1 FileOutputStream实现类


构造方法:(输出流会自动创建输出对象)
FileOutputStream(File file)
通过一个File对象创建一个文件输出流对象
FileOutputStream(String name)
通过一个字符串构建一个文件输出流对象
FileOutputStream(File file,boolean append)
通过文件对象创建文件输出流对象,并指定是否追加
FileOutputStream(String name,boolean append)
通过一个字符串构建一个文件输出流对象,并指定是否追加
note:如果没有实际对象,对对象的操作并不会作用于实际文件
写出数据到流对象:
void write(byte[] bytes)
一次写一个字节数组的数据
void write(int b)
一次写一个字节
void write(byte[] bytes,int off,int len)
一次写一个字节数组的一部分
关闭流对象:
void close()
关闭此文件输出流并释放与此流有关的所有系统资源
关闭流的两个作用:
1.让流不能再继续使用
2.释放和此流相关的系统资源
1.1.2 FileInputStream实现类


构造方法:(必须要求输入对象事先存在)
FileInputStream(File file)
通过File对象创建一个文件输入流对象FileInputStream(String name)
通过一个字符串创建一个文件输入流对象 String可以是完整路径字符串
int read()
从输入流中读取一个字节
int read(byte[] b)
从输入流中读取字节,放到字节数组中,返回字节个数
int read(byte[] b,int off,int len)
从输入流中读取字节,放到字节数组中,只放到指定位置(不常用)



1.1.3自带关闭资源的try语句块
为了替换finally臃肿的写法,JDK7出现了自带关闭资源的try语句块,可以不用显式的写finally语句。
用法:
将需要关闭的资源定义或者初始化语句放到try后的括号里,程序会自动关闭这些资源,前提是这些类实现了AutoCloseable接口或者Closeable接口
格式:
try(需要自动关闭的资源声明或者初始化){
//正常逻辑语句
}

案例:字节读取
1.一次读取一个字节
2.用循环改进读取字节
3.简化循环读取字节
4.一次读取一个字节数组
5.加上异常处理读取字节数组
6.改进异常处理读取字节数组
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException; /*
* FileInputStream(File name)
* FileInputStream(String name)
*/
public class FileInputStreamDemo { public static void main(String[] args) throws Exception {
//输入流关联的文件必须事先存在,否则异常,输出流目标文件可以自动创建
FileInputStream fis = new FileInputStream(new File("a.txt")); // FileInputStream fis2 = new FileInputStream("a.txt"); //一次读取一个字节:
// int b = fis.read();
// System.out.println(b);
/*
b = fis.read();
System.out.println(b);
b = fis.read();
System.out.println(b);
b = fis.read();
System.out.println(b);
b = fis.read();
System.out.println(b);
*/
//用循环改进
/*
int b = 0;
while(true){
b = fis.read();
if(b == -1){
break;
}else{
System.out.println(b);
}
}
*/
//最终代码
// int b = 0;
// while((b = fis.read()) != -1){
// System.out.println(b);
// } //一次读取一个字节数组
/*
byte[] bys = new byte[1024];
int len = fis.read(bys);
System.out.println(len); //用字节数组构建字符串
String str = new String(bys, 0, len);
System.out.println(str);
*/ //循环读取数据
int len = 0;
byte[] bys = new byte[1024];
while((len = fis.read(bys) + test()) != -1){
System.out.print(new String(bys,0,len));
} //释放资源
fis.close(); } public static int test(){
System.out.println("方法被调用了");
return 0;
} }
字节读取
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException; /*
* 加上异常处理的程序
*
* 1.7后新特性:自带关闭资源的try块
*
*/
public class FileInputStreamDemo2 { public static void main(String[] args) {
/*
//提升作用域
FileInputStream fis = null;
try {
fis = new FileInputStream("a.txt");//此条语句有可能不执行成功 //
int len = 0;
byte[] bys = new byte[1024];
while((len = fis.read(bys)) != -1){
System.out.print(new String(bys,0,len));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
//用来释放非内存资源
//释放资源
//非空判断
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
} //如果有多个变量,继续关闭
} */ //自动关闭资源的try块
try(
FileInputStream fis = new FileInputStream("a.txt");
//
){
//正常的逻辑语句
int len = 0;
byte[] bys = new byte[1024];
while((len = fis.read(bys)) != -1){
System.out.print(new String(bys,0,len));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} } }
异常处理改进

案例:写出数据到流
import java.io.File;
import java.io.FileOutputStream; /*
* FileOutputStream(File name)
* FileOutputStream(File name,boolean append)
* FileOutputStream(String name)
* FileOutputStream(String name,boolean append)
*
* 创建对象 --> 使用写出方法写出数据到流 --> 释放资源
*
* 写入到文件中的数据.如果使用记事本等程序打开,会经过转码的过程. ( 字节-->字符 )
*/
public class FileOutputStreamDemo1 { public static void main(String[] args) throws Exception {
//
FileOutputStream fos = new FileOutputStream(new File("a.txt"),true);
/*
//
FileOutputStream fos2 = new FileOutputStream(new File("a.txt"), true); //
FileOutputStream fos3 = new FileOutputStream("a.txt"); //
FileOutputStream fos4 = new FileOutputStream("a.txt",true);
*/
//一次写一个字节
// fos.write(98); //一次写一个字节数组
// byte[] bys = {97,98,99,100,101,102,103,104};
// fos.write(bys); //一次写一个字节数组的一部分
// fos.write(bys, 2, 3); //实现换行
fos.write("abc\r\ndef".getBytes());//使用系统默认的字符集编码成字节数组 : //释放资源
fos.close(); //流关闭之后不能再写数据
// fos.write(97); } }
写出数据到流
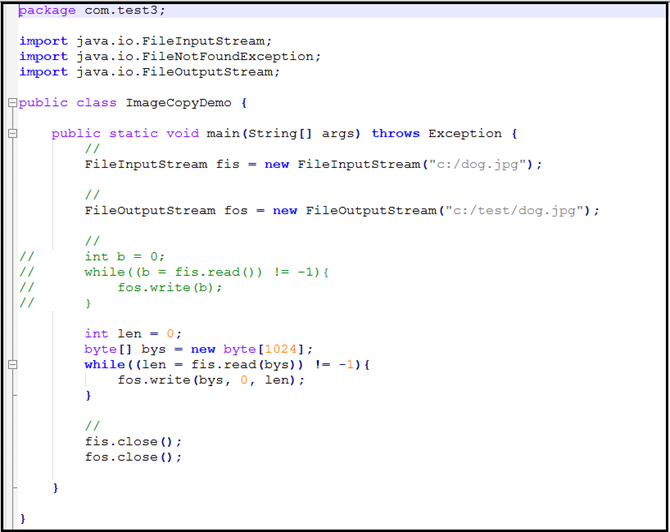
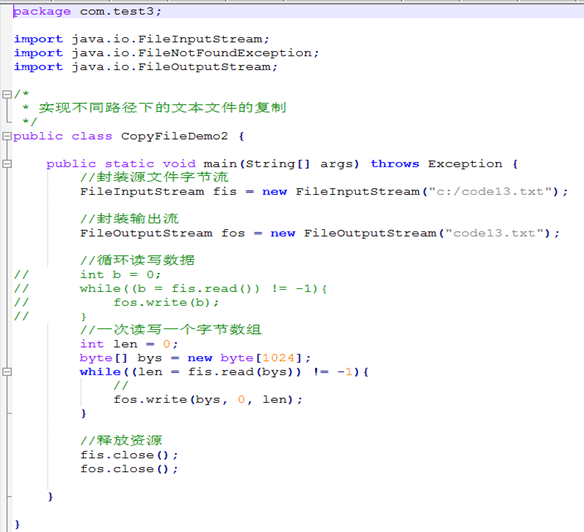
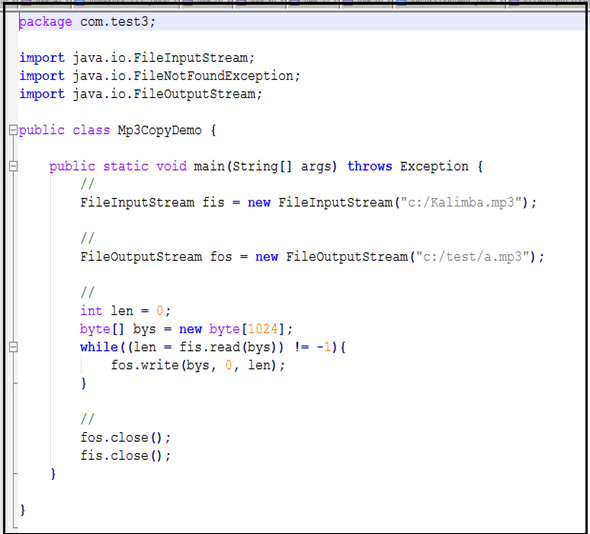
案例:文件的复制
思路:
1.使用源文件创建文件输入流对象
2.使用目标文件创建文件输出流对象
3.复制数据
4.关闭资源 实现同一个项目路径下的文本文件的复制
实现不同路径下的文本文件的复制
实现图片的复制
实现mp3的复制

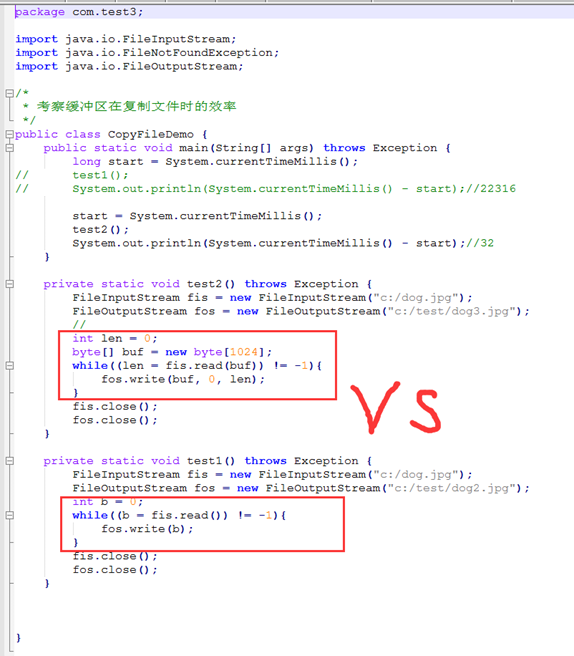
1.1.4 自带缓冲区的字节流
一次读取(或者写入)一个字节数组的数据在效率上提升了很多,字节数组实际上相当于一个缓冲区。
Java提供了自带缓冲区的流,不必自己再定义额外的字节数组充当缓冲区了。

自带缓冲区的字节输入流 vs 自带缓冲区的字节输出流
BufferedInputStream BufferedOutputStream




package java.io;
public class BufferedOutputStream extends FilterOutputStream {
protected byte buf[];
protected int count;
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
/** Flush the internal buffer */
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
/* If the request length exceeds the size of the output buffer,
flush the output buffer and then write the data directly.
In this way buffered streams will cascade harmlessly. */
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();
}
System.arraycopy(b, off, buf, count, len);
count += len;
}
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
}
BufferedOutputStream
package java.io;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater; public
class BufferedInputStream extends FilterInputStream { private static int DEFAULT_BUFFER_SIZE = 8192; private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8; protected volatile byte buf[]; private static final
AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater =
AtomicReferenceFieldUpdater.newUpdater
(BufferedInputStream.class, byte[].class, "buf"); /**
* The index one greater than the index of the last valid byte in the buffer.
* 0<count<buf.length
*/
protected int count; /**
* The current position in the buffer. This is the index of the next character to be read from the buf[].
* 0<pos<count. buf[pos] is the next byte to be supplied as input;
*/
protected int pos; /**
* The value of the pos field at the time the last
* mark method was called.
* This value is always in the range -1 through pos.
* If there is no marked position in the input
* stream, this field is -1. If
* there is a marked position in the input
* stream, then buf[markpos]
* is the first byte to be supplied as input
* after a reset operation. If
* markpos is not -1,
* then all bytes from positions buf[markpos]
* through buf[pos-1] must remain
* in the buffer array (though they may be
* moved to another place in the buffer array,
* with suitable adjustments to the values
* of count, pos,
* and markpos); they may not
* be discarded unless and until the difference
* between pos and markpos
* exceeds marklimit.
*
* @see java.io.BufferedInputStream#mark(int)
* @see java.io.BufferedInputStream#pos
*/
protected int markpos = -1; /**
* The maximum read ahead allowed after a call to the
* mark method before subsequent calls to the
* reset method fail.
* Whenever the difference between pos
* and markpos exceeds marklimit,
* then the mark may be dropped by setting
* markpos to -1.
*
* @see java.io.BufferedInputStream#mark(int)
* @see java.io.BufferedInputStream#reset()
*/
protected int marklimit; /**
* Check to make sure that underlying input stream has not been
* nulled out due to close; if not return it;
*/
private InputStream getInIfOpen() throws IOException {
InputStream input = in;
if (input == null)
throw new IOException("Stream closed");
return input;
} /**
* Check to make sure that buffer has not been nulled out due to
* close; if not return it;
*/
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
} /**
* Creates a BufferedInputStream and saves its argument, the input stream in, for later use. An internal buffer array is created and stored in buf.
* @param in the underlying input stream.
*/
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
} /**
* Creates a BufferedInputStream with the specified buffer size, and saves its argument, the input stream in, for later use. An internal buffer array of length size is created and stored in buf.
* @param in the underlying input stream.
* @param size the buffer size.
* @exception IllegalArgumentException if {@code size <= 0}.
*/
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
} /**
* Fills the buffer with more data, taking into account
* shuffling and other tricks for dealing with marks.
* Assumes that it is being called by a synchronized method.
* This method also assumes that all data has already been read in,
* hence pos > count.
*/
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buffer.length) /* no room left in buffer */
if (markpos > 0) { /* can throw away early part of the buffer */
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else { /* grow buffer */
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
} public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
} private int read1(byte[] b, int off, int len) throws IOException {
int avail = count - pos;
if (avail <= 0) {
/* If the requested length is at least as large as the buffer, and
if there is no mark/reset activity, do not bother to copy the
bytes into the local buffer. In this way buffered streams will
cascade harmlessly. */
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);
}
fill();
avail = count - pos;
if (avail <= 0) return -1;
}
int cnt = (avail < len) ? avail : len;
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
pos += cnt;
return cnt;
} public synchronized int read(byte b[], int off, int len)
throws IOException
{
getBufIfOpen(); // Check for closed stream
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
} int n = 0;
for (;;) {
int nread = read1(b, off + n, len - n);
if (nread <= 0)
return (n == 0) ? nread : n;
n += nread;
if (n >= len)
return n;
// if not closed but no bytes available, return
InputStream input = in;
if (input != null && input.available() <= 0)
return n;
}
} public synchronized long skip(long n) throws IOException {
getBufIfOpen(); // Check for closed stream
if (n <= 0) {
return 0;
}
long avail = count - pos; if (avail <= 0) {
// If no mark position set then don't keep in buffer
if (markpos <0)
return getInIfOpen().skip(n); // Fill in buffer to save bytes for reset
fill();
avail = count - pos;
if (avail <= 0)
return 0;
} long skipped = (avail < n) ? avail : n;
pos += skipped;
return skipped;
} public synchronized int available() throws IOException {
int n = count - pos;
int avail = getInIfOpen().available();
return n > (Integer.MAX_VALUE - avail)
? Integer.MAX_VALUE
: n + avail;
} public synchronized void mark(int readlimit) {
marklimit = readlimit;
markpos = pos;
} public synchronized void reset() throws IOException {
getBufIfOpen(); // Cause exception if closed
if (markpos < 0)
throw new IOException("Resetting to invalid mark");
pos = markpos;
} public boolean markSupported() {
return true;
} public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
}
BufferedInputSream
1.1.5测试各种流在复制文件时的效率
FileInputStream
FileOutputStream
基本字节流(节点流):
一次读取一个字节;
一次读取一个字节数组的数据
BufferedInputStream
BufferedOutputStream
缓冲区流(包装流):
一次读取一个字节;
一次读取一个字节数组的数据


javaIO--数据流之IO流与字节流的更多相关文章
- java io流(字节流)复制文件
java io流(字节流) 复制文件 //复制文件 //使用字节流 //复制文本文件用字符流,复制其它格式文件用字节流 import java.io.*; public class Index{ pu ...
- IO流(字节流复制)01
package ioDemo; import java.io.*; /** * IO流(字节流复制) * Created by lcj on 2017/11/2. */ public class bu ...
- JavaSE学习笔记(14)---File类和IO流(字节流和字符流)
JavaSE学习笔记(14)---File类和IO流(字节流和字符流) File类 概述 java.io.File 类是文件和目录路径名的抽象表示,主要用于文件和目录的创建.查找和删除等操作. 构造方 ...
- IO流总结---- 字节流 ,字符流, 序列化 ,数据操作流,打印流 , Properties 集合
笔记内容: 什么是流 字节流 字符流 序列化 数据操作流(操作基本数据类型的流)DataInputStream 打印流 Properties 集合 什么是流: 流是个抽象的概念,是对输入输出设备的抽象 ...
- Java基础(八)——IO流1_字节流、字符流
一.概述 1.介绍 I/O是 Input/Output 的缩写,IO流用来处理设备之间的数据传输,如读/写文件,网络通讯等.Java对数据的操作是通过流的方式进行.java.io 包下提供了各种&qu ...
- 【JAVA IO流之字节流】
字节流部分和字符流部分的体系架构很相似,有四个基本流:InputStream.OutputStream.BufferedInputStream.BufferedOutputStream,其中,Inpu ...
- Java笔记(二十六)……IO流上 字节流与字符流
概述 IO流用来处理设备之间的数据传输 Java对数据的操作时通过流的方式 Java用于操作流的对象都在IO包中 流按操作的数据分为:字节流和字符流 流按流向不同分为:输入流和输出流 IO流常用基类 ...
- Java---IO加强(3)-IO流的操作规律
一般写关于操作文件的读取的几个通用步骤!!! 1.明确源和目的. 源:InputStream Reader 一定是被读取的. 目的:OutputStream Writer 一定是被写入的. 2.处理的 ...
- 【Java IO流】字节流和字符流详解
字节流和字符流 对于文件必然有读和写的操作,读和写就对应了输入和输出流,流又分成字节和字符流. 1.从对文件的操作来讲,有读和写的操作——也就是输入和输出. 2.从流的流向来讲,有输入和输出之分. 3 ...
- JavaSE(十二)之IO流的字节流(一)
前面我们学习的了多线程,今天开始要学习IO流了,java中IO流的知识非常重要.但是其实并不难,因为他们都有固定的套路. 一.流的概念 流是个抽象的概念,是对输入输出设备的抽象,Java程序中 ...
随机推荐
- 监控Linux服务器上python服务脚本
提供给公司使用的测试平台这两天频繁地挂掉,影响到相关同事的正常使用,决定在服务器上写个监控脚本,监控到服务挂了就启动起来,一分钟检查一次.注:后台服务使用的是python.监控脚本如下: NUM=`p ...
- redis学习(三)
如何保障reids的数据安全和性能? 一.持久化选项 1.快照snapshotting 它可以将存在于某一时刻的所有数据都写入硬盘里面. 配置选项示例: save 60 1000 注:从最近一次创 ...
- 20191209 Linux就该这么学(1-3)
1. 部署虚拟环境安装 Linux 系统 RPM 是为了简化安装的复杂度,而 Yum软件仓库是为了解决软件包之间的依赖关系. 2. 新手必须掌握的Linux命令 通常来讲,计算机硬件是由运算器.控制器 ...
- [转帖]数据库默认驱动、URL、端口
超详细的各种数据库默认驱动.URL.端口总结 http://database.51cto.com/art/201906/598043.htm 学习了解一下. 概述 今天主要对各种数据库默认端口和UR ...
- 洛谷 P1233 木棍加工 题解
题面 Dilworth定理:在数学理论中的序理论与组合数学中,Dilworth定理根据序列划分的最小数量的链描述了任何有限偏序集的宽度. 反链是一种偏序集,其任意两个元素不可比:而链则是一种任意两个元 ...
- 从入门到自闭之Python基础——函数初识
1. 文件操作: 读操作: 格式:f = open("文件路径",mode = "r",encoding = "utf-8") f : 代表 ...
- python中self与__init__怎么解释能让小白弄懂?
python中self与__init__怎么解释能让小白弄懂? 这个问题其实没那么简单. 只说一下自己的理解. python 里所有的 object 都有三个属性, 标识(identity), 类型( ...
- Exceptionless
参考 Exceptionless - .Net Core开源日志框架
- C#解决并发的设计思路
解决并发的方案,应用场景,一个报名的方法,可是要限制报名的人数:一,如果是单机版,就是部署一个服务器站点的我们可以使用很经典的lock锁,或者queue队列,针对单机版二,如果是部署了集群的站点1&g ...
- Property 'showModal' does no t exist on type 'JQuery<HTMLElement>'
在 TS 代码中使用 jQuery 等库时配合插件使用,但是插件的开发人员并没有为其扩展 jQuery 的类型定义,这是使用插件的方法必然会报 TS 的类型错误,这时候要快速选择忽略该报错的最直接的方 ...