Temporal-Difference Control: SARSA and Q-Learning
SARSA
SARSA algorithm also estimate Action-Value functions rather than State-Value function. The difference between SARSA and Monte Carlo is: SARSA does not need to wait the actual return untill the end of the episode, instead it learns from each time step using estimations of the return.
In every step, the agent takes an action A from state S, then it receives a reward R and gets to a new state S'. Based on the policy π, we know the algorithm will greedily pick the action A'. So now we have:S,A,R,S',A', and the task is to estimate Q function of S,A pair.

We borrow the idea of estimating State-Value functions and use it onto Action-Value function estimation, then we get:
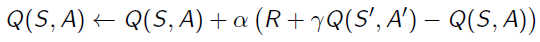
Here is the Sudo code for SARSA:

On-Policy vs Off-Policy
If we look into the learning process, there are actually two steps, firstly taking an action A from state S based on policy π, geting the reward R, and the next state S' coming; the second step is using the Q-function of action A' followd the same policy π. Both of the two steps use the same policy π, but actually they can be different. On the first step, the policy is called Target Policy, which is the policy that we will update. The second policy is Behavior Policy, this is how we pick the oprimal action from S'. Q-Learning uses different Policies on the two steps.
Q-Learning
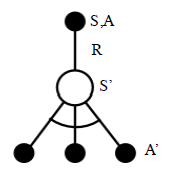
From state S', Q-Learning algorithm picks the action maximizing the Q-function. It stands at state S', looking into all possible actions, and then chooses the best one.
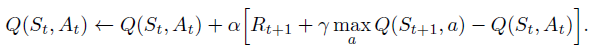

Temporal-Difference Control: SARSA and Q-Learning的更多相关文章
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 增强学习(五)----- 时间差分学习(Q learning, Sarsa learning)
接下来我们回顾一下动态规划算法(DP)和蒙特卡罗方法(MC)的特点,对于动态规划算法有如下特性: 需要环境模型,即状态转移概率\(P_{sa}\) 状态值函数的估计是自举的(bootstrapping ...
- 【PPT】 Least squares temporal difference learning
最小二次方时序差分学习 原文地址: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd= ...
- 论文笔记之:Human-level control through deep reinforcement learning
Human-level control through deep reinforcement learning Nature 2015 Google DeepMind Abstract RL 理论 在 ...
- 如何用简单例子讲解 Q - learning 的具体过程?
作者:牛阿链接:https://www.zhihu.com/question/26408259/answer/123230350来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- 深度强化学习介绍 【PPT】 Human-level control through deep reinforcement learning (DQN)
这个是平时在实验室讲reinforcement learning 的时候用到PPT, 交期末作业.汇报都是一直用的这个,觉得比较不错,保存一下,也为分享,最早该PPT源于师弟汇报所做.
- The Difference between Gamification and Game-Based Learning
http://inservice.ascd.org/the-difference-between-gamification-and-game-based-learning/ Have you trie ...
- deep Q learning小笔记
1.loss 是什么 2. Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作.如下式,通过更新参数 θθ 使Q函数逼近最优Q值 深度神经网络可以自动提取复杂特征,因此,面对高 ...
随机推荐
- num1,随堂笔记(3月10日)
1.计算机发展史(略) 2.我们所使用的计算机包括了计算机硬件.操作系统和应用程序与网络. 3.计算机硬件构成---CPU(运算器和控制器).内存.硬盘.输入设备和输出设备. ①CPU是计算机的主要计 ...
- 运用在伪类content上的html特殊字符
原文转载于:https://www.cnblogs.com/wujindong/p/5630656.html 项目中用到的一些特殊字符和图标 html代码 <div class="cr ...
- evpp心跳机制
client server xin good
- systemd 相关及服务启动失败原因
1 查看启用的units systemctl list-unit-files | grep enabled 2 查看指定服务的日志 按服务单元过滤 journalctl -u j 查看j.serv ...
- 【03】Python 文件读写 JSON
1 打开文件 文件操作步骤: 1.打开文件获取文件的句柄,句柄就理解为这个文件 2.通过文件句柄操作文件 3.关闭文件. 1.1 打开方法 f = open('xxx.txt') #需f.close( ...
- Git整理[1] git cherry-pick的使用
简单地说 git cherry-pick为”挑拣”提交 ,挑取某次提交合并到其他分支上,而不用合并整个分支. 参数: git cherry-pick [<options>] <com ...
- bullet学习日记
最近需要bullet用物理引擎做一个测量类的项目,因为半途接手,物理部分其实已经实现,但犹于对bullet基本不了解,导致相关部分完全改不动,这两天静下心来把物理引擎用法了解了一翻,顺便做点笔记,以便 ...
- android 8.0 适配(总结)
android 8.0 对应的 sdk 版本 26 1. 通知栏 Android 8.0 引入了通知渠道,其允许您为要显示的每种通知类型创建用户可自定义的渠道.用户界面将通知渠道称之为通知类别. 针 ...
- Linux内核设计与实现 总结笔记(第十四章)块I/O层
一.剖析一个块设备 块设备最小的可寻址单元是扇区. 扇区大小一般是2的整数倍,最常见的是512字节. 因为各种软件的用途不同,所以他们都会用到自己的最小逻辑可寻址单元----块.块只能基于文件系统,是 ...
- Python pdfkit
序言 住在地下室的人,依然有仰望星空的权利. pdfkit python使用pdfkit中,如果使用pdfkit.fromurl 或者pdfkit.fromstring等,就会出现上述错误.而且如果你 ...