流畅的Python (Fluent Python) —— 第二部分01
2.1 内置序列类型概览
Python 标准库用 C 实现了丰富的序列类型,列举如下。
容器序列
list、 tuple 和 collections.deque 这些序列能存放不同类型的数据。
扁平序列
str、 bytes、 bytearray、 memoryview 和 array.array,这类序列只能容纳一种类型。
序列类型还能按照能否被修改来分类。
可变序列
list、 bytearray、 array.array、 collections.deque 和 memoryview。
不可变序列
tuple、 str 和 bytes。
列表推导是构建列表(list)的快捷方式,而生成器表达式则可以用来创建其他任何类型的序列。
# 列表推导式,讲一个字符串变为Unicode码位的列表
# 列表推导式不会有变量泄露的问题
symbols = '!@#$%^&*'
codes = [ord(symbol) for symbol in symbols]
print(codes)
2.2.2 列表推导同filter和map的比较
filter 和 map 合起来能做的事情,列表推导也可以做,而且还不需要借助难以理解和阅读的 lambda 表达式。
# 功能:如果 ord(s) > 127 则 将 ord(s) 存入新列表
symbols = '$¢£¥€¤'
beyond_ascii1 = [ord(s) for s in symbols if ord(s) > 127] # 列表推导
print(beyond_ascii1) beyond_ascii2 = list(filter(lambda c: c > 127, map(ord, symbols)))
print(beyond_ascii2)
'''
map/filter实现同样的功能,但可能更慢
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,
然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
Python3.x 返回迭代器对象
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,
返回包含每次 function 函数返回值的新列表。
lambda:匿名函数
'''
# 生成器表达式:遵守了迭代器协议,节约内存
# 特点:圆括号
symbols = '$¢£¥€¤'
t1 = tuple(ord(symbol) for symbol in symbols)
print(t1) # 使用生成器表达式,初始化元组和数组
import array
# I 为参数 表明操作的是整数 C 为单个字符
a1 = array.array('I', (ord(symbol) for symbol in symbols))
print(a1)
2.3.2 元组拆包
元组拆包可以应用到任何可迭代对象上,唯一的硬性要求是,被可迭代对象中的元素数量必须要跟接受这些元素的元组的空档数一致。除非我们用 * 来表示忽略多余的元素。
# 元组不仅仅是不可变列表
# 除了用作不可变的列表,它还可以用于没有字段名的记录。
lax_coordinates = (33.9425, -118.408056) # 存储经伟度
# 分别赋值(元组拆包)
city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014)
# 元组列表
traveler_ids = [('USA', ''), ('BRA', 'CE342567'), ('ESP', 'XDA205856')]
for passport in sorted(traveler_ids):
print('%s/%s' % passport)
# 一个 % 就将 password 元组里的两个元素对应过去格式化字符串的空档中。
另外一个很优雅的写法当属不使用中间变量交换两个变量的值:
# 优雅写法,无需中间变量交换
a, b = 1, 2
b, a = a, b
还可以用 * 运算符把一个可迭代对象拆开作为函数的参数
print(divmod(20, 8))
# 还可以用 * 运算符把一个可迭代对象拆开作为函数的参数
# 一点像指针?
t = (20, 8)
print(divmod(*t))
在 Python 中,函数用 *args 来获取不确定数量的参数算是一种经典写法了。于是 Python 3 里,这个概念被扩展到了平行赋值中:
# 在平行赋值中, * 前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置
a, *body, c, d = range(5)
print(a)
print(*body)
另外元组拆包还有个强大的功能,那就是可以应用在嵌套结构中。
2.3.3 嵌套元组拆包
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)), # 每个元组内有 4 个元素,其中最后一个元素是一对坐标。
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
print('{:15} | {:^9} | {:^9}'.format('', 'lat.', 'long.')) # {:^9}:中间对齐 (宽度为9)
fmt = '{:15} | {:9.4f} | {:9.4f}' # {:9.4f} 右对齐 (默认, 宽度为9),带符号保留小数点后四位
for name, cc, pop, (latitude, longitude) in metro_areas: # 我们把输入元组的最后一个元素拆包到由变量构成的元组里,这样就获取了坐标
if longitude <= 0: # if longitude <= 0: 这个条件判断把输出限制在西半球的城市
print(fmt.format(name, latitude, longitude))
2.3.4 具名元组
from collections import namedtuple
City = namedtuple('City', 'name country population coordinates') # 创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串
tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667)) # 存放在对应字段里的数据要以一串参数的形式传入到构造函数中(注意,元组的构造函数却只接受单一的可迭代对象)。
print(tokyo)
print(tokyo.population) # 你可以通过字段名或者位置来获取一个字段的信息
print(tokyo.coordinates)
print(tokyo[0])
print(City._fields) # _fields 属性是一个包含这个类所有字段名称的元组。
LatLong = namedtuple('LatLong', 'lat long')
delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
delhi = City._make(delhi_data) # 用 _make() 通过接受一个可迭代对象来生成这个类的一个实例,它的作用跟City(*delhi_data) 是一样的。
print(delhi._asdict()) # _asdict() 把具名元组以 collections.OrderedDict 的形式返回,我们可以利用它来把元组里的信息友好地呈现出来。
for key, value in delhi._asdict().items():
print(key + ' : ', value)
现在我们知道了,元组是一种很强大的可以当作记录来用的数据类型。它的第二个角色则是充当一个不可变的列表。下面就来看看它的第二重功能。
除了跟增减元素相关的方法之外,元组支持列表的其他所有方法。还有一个例外,元组没有 __reversed__ 方法,但是这个方法只是个优化而已, reversed(my_tuple) 这个用法在没有 __reversed__ 的情况下也是合法的。
2.4 切片 :实际上切片操作比人们所想象的要强大很多。
2.4.1 为什么切片和区间会忽略最后一个元素
1. 当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素: range(3) 和 my_list[:3] 都返回 3 个元素。
2. 当起止位置信息都可见时,我们可以快速计算出切片和区间的长度,用后一个数减去第一个下标(stop - start)即可。
3. 这样做也让我们可以利用任意一个下标来把序列分割成不重叠的两部分,只要写成my_list[:x] 和 my_list[x:] 就可以了。
2.4.2 对对象进行切片
我们还可以用 s[a:b:c] 的形式对 s 在 a 和 b 之间以 c 为间隔取值。 c 的值还可以为负,负值意味着反向取值。对 seq[start:stop:step] 进行求值的时候, Python 会调用seq.__getitem__(slice(start, stop, step))。
这时使用有名字的切片比用硬编码的数字区间要方便得多,注意示例里的 for 循环的可读性有多强。
invoice = """
0.....6................................40........52...55........
1909 Pimoroni PiBrella $17.50 3 $52.50
1489 6mm Tactile Switch x20 $4.95 2 $9.90
1510 Panavise Jr. - PV-201 $28.00 1 $28.00
1601 PiTFT Mini Kit 320x240 $34.95 1 $34.95
"""
SKU = slice(0, 6)
DESCRIPTION = slice(6, 40)
UNIT_PRICE = slice(40, 52)
QUANTITY = slice(52, 55)
ITEM_TOTAL = slice(55, None)
line_items = invoice.split('\n')[2:]
print(line_items)
for item in line_items:
print(item[UNIT_PRICE], item[DESCRIPTION])
'''
invoice.split('\n')[2:] 将 invoice 以 '\n' 来分隔成列表,[2:]表示除去前两行,一行是"""后面,一行是数字那行
执行 item[UNIT_PRICE] 时,读取 UNIT_PRICE ,则执行 slice(40, 52)
将 item 按照定义好的规则切片,
'''
如果把切片放在赋值语句的左边,或把它作为 del 操作的对象,我们就可以对序列进行嫁接、切除或就地修改操作。
2.5 对序列使用+和*
建立由列表组成的列表
有时我们会需要初始化一个嵌套着几个列表的列表,譬如一个列表可能需要用来存放不同的学生名单,或者是一个井字游戏板 上的一行方块。想要达成这些目的,最好的选择是使用列表推导。
board = [['_'] * 3 for i in range(3)] # 正确写法
print(board)
board[1][2] = 'X'
print(board) # 这种方法是错误的
weird_board = [['_'] * 3] * 3 # 含有 3 个指向同一对象的引用的列表是毫无用处的
print(weird_board)
weird_board[0][1] = 'O'
print(weird_board)
# 错误就等同,追加同一个对象三次
row = ['_'] * 3
board = []
for i in range(3):
board.append(row)
*= 在可变和不可变序列上的作用
l = [1, 2, 3]
print(id(l))
l *= 2
print(id(l)) # 运用增量乘法后,列表的 ID 没变,新元素追加到列表上
# str 是个例外,因为字符串 += 太普遍了 所以CPython对其进行了优化,留出了可获扩展空间
t = (1, 2, 3)
print(id(t))
t *= 2
print(id(t)) # 运用增量乘法后,新的元组被创建。
对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再追加新的元素
# 一个谜题
t = (1, 2, [30, 40])
t[2] += [50, 60]
print(t)
# 1.不要把可变对象放在元组里
# 2.增量赋值不是一个原子操作。我们刚才也看到了,它虽然抛出了异常,但还是完成了操作。
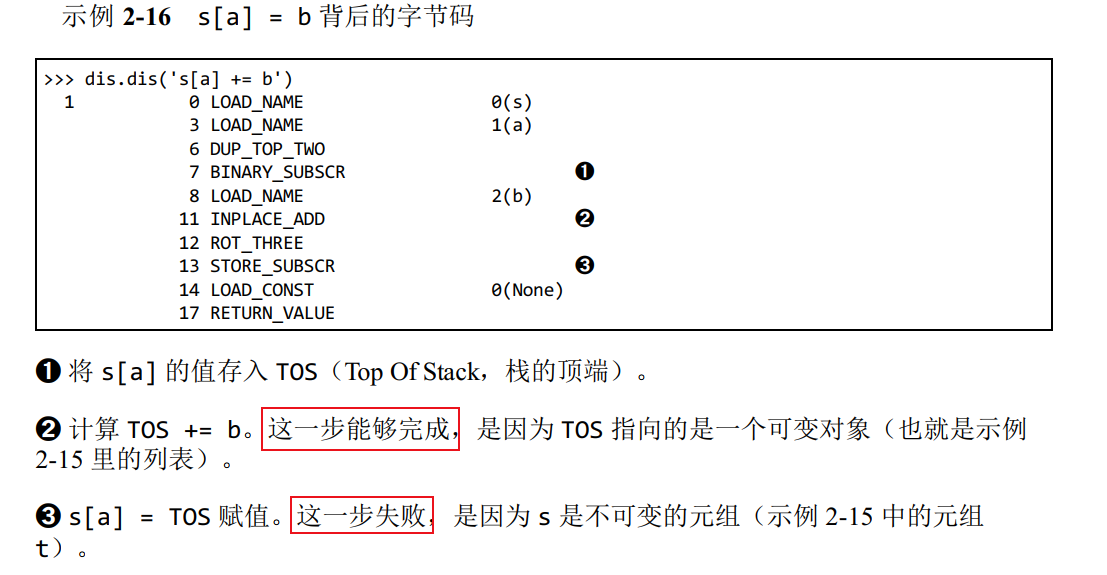
7 # 3.查看 Python 的字节码并不难,而且它对我们了解代码背后的运行机制很有帮助
流畅的Python (Fluent Python) —— 第二部分01的更多相关文章
- 流畅的Python (Fluent Python) —— 前言
本书重点: 这本书并不是一本完备的 Python 使用手册,而是会强调 Python 作为编程语言独有的特性,这些特性或者是只有 Python 才具备的,或者是在其他大众语言里很少见的. Python ...
- 流畅的Python (Fluent Python) —— 第一部分
Python 最好的品质之一是一致性. 魔术方法(magic method)是特殊方法的昵称.特殊方法也叫双下方法. 1.1 一摞Python风格的纸牌 import collections Card ...
- python 自动化之路 day 01 人生若只如初见
本节内容 Python介绍 发展史 Python 2 or 3? 安装 Hello World程序 Python 注释 变量 用户输入 模块初识 .pyc是个什么鬼? 数据类型初识 数据运算 表达式i ...
- Python深入学习之《Fluent Python》 Part 1
Python深入学习之<Fluent Python> Part 1 从上个周末开始看这本<流畅的蟒蛇>,技术是慢慢积累的,Python也是慢慢才能写得优雅(pythonic)的 ...
- Fluent Python: Classmethod vs Staticmethod
Fluent Python一书9.4节比较了 Classmethod 和 Staticmethod 两个装饰器的区别: 给出的结论是一个非常有用(Classmethod), 一个不太有用(Static ...
- Python开发【第二篇】:初识Python
Python开发[第二篇]:初识Python Python简介 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- Python自动化 【第二篇】:Python基础-列表、元组、字典
本节内容 模块初识 .pyc简介 数据类型初识 数据运算 列表.元组操作 字符串操作 字典操作 集合操作 字符编码与转码 一.模块初识 Python的强大之处在于他有非常丰富和强大的标准库和第三方库, ...
- Python开发【第二十三篇】:持续更新中...
Python开发[第二十三篇]:持续更新中...
- Python开发【第二十二篇】:Web框架之Django【进阶】
Python开发[第二十二篇]:Web框架之Django[进阶] 猛击这里:http://www.cnblogs.com/wupeiqi/articles/5246483.html 博客园 首页 ...
随机推荐
- 新年第一发--HDU1848--Fibonacci again and again(SG函数)
Problem Description 任何一个大学生对菲波那契数列(Fibonacci numbers)应该都不会陌生,它是这样定义的:F(1)=1;F(2)=2;F(n)=F(n-1)+F(n-2 ...
- wannafly 挑战赛9 E 组一组 (差分约束)
链接:https://www.nowcoder.com/acm/contest/71/E 时间限制:C/C++ 3秒,其他语言6秒 空间限制:C/C++ 65536K,其他语言131072K Spec ...
- PTA编程总结三
7-1 抓老鼠啊~亏了还是赚了? (20 分) 某地老鼠成灾,现悬赏抓老鼠,每抓到一只奖励10元,于是开始跟老鼠斗智斗勇:每天在墙角可选择以下三个操作:放置一个带有一块奶酪的捕鼠夹(T),或者放置一块 ...
- spring boot + mybatis + layui + shiro后台权限管理系统
后台管理系统 版本更新 后续版本更新内容 链接入口: springboot + shiro之登录人数限制.登录判断重定向.session时间设置:https://blog.51cto.com/wyai ...
- How jQuery UI Works
https://learn.jquery.com/jquery-ui/how-jquery-ui-works/ jQuery UI contains many widgets that maintai ...
- post与get方法的区别
1. GET请求:请求的数据会附加在URL之后,以?分割URL和传输数据,多个参数用&连接.URL的编码格式采用的是ASCII编码,而不是unicode,即是说所有的非ASCII字符都要编码之 ...
- java基础--继承、实现、依赖、关联、聚合、组合的联系与区别
继承 指的是一个类或者接口继承另一个类或者接口,而且可以增加自己的新功能. 实现 指的是一个class类实现interface接口. 依赖 简单说,就是一个类中的方法用到了另一个类,一般依赖关系在ja ...
- Jmeter 设置连接oracle数据库
一.添加需要数据库驱动jar包 方式1:直接将jar包复制到jmeter的lib目录,或lib/ext目录:(亲测两个目录都可以使用) 方式2:使用jmeter的Test Plan引入相应的jar包: ...
- 【洛谷T89353 【BIO】RGB三角形】
题目链接 这个题我一开始显然直接暴力 然后30分(但是应用数据分治的我通过复杂度判断并且其余输出0的能力硬生生的拿下了60分) 主要还是讲正解 这里有一个结论 这样一个图,红点的值可以通过两个黄点来判 ...
- .Net Core-3.0-新闻:宣告推出.NET Core 3.0 Preview 7
ylbtech-.Net Core-3.0-新闻:宣告推出.NET Core 3.0 Preview 7 1.返回顶部 1. 今天,我们宣布推出.NET Core 3.0 Preview 7.我们已 ...