ELK-全文检索技术-kibana操作elasticsearch
前言:建议kibana语法一定要学好!
1 软件安装
1.1 ES的安装
第一步:解压压缩包,放到一个没有中文没有空格的位置
第二步:修改配置文件
1、 jvm.options 第22和23行
-Xms128m
-Xmx128m
2、 elasticsearch.yml 第33行和37行
path.data: D:\class96\elasticsearch-6.2.4\data
#
# Path to log files:
#
path.logs: D:\class96\elasticsearch-6.2.4\logs
第三步:直接双击批处理文件
效果如下:
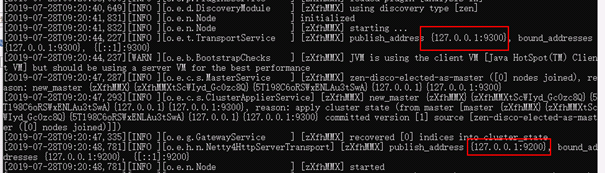
两个端口号
9200 http协议的端口号
9300 tcp协议的端口号
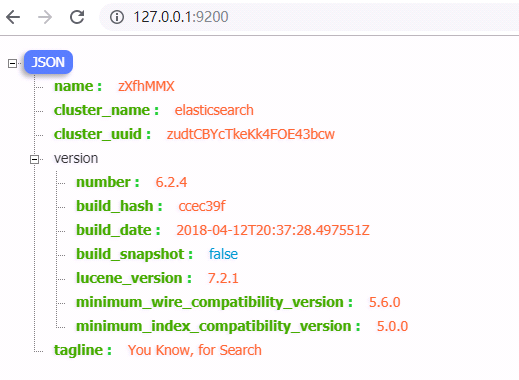
使用http访问
1.2 安装操作ES的客户端软件Kibana
需要说明的是:
1、Kibana软件的版本一定要和ES的版本保持一致
2、Kibana需要依赖nodejs的环境
第一步:安装nodejs
双击安装

验证安装效果
Dos窗口中输入 node –v
第二步:安装kibana,解压
第三步:构建kibana和ES的关联关系
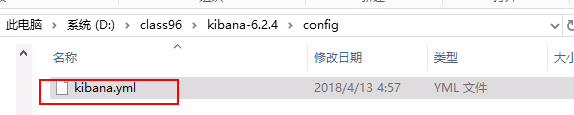
第21行
elasticsearch.url: http://localhost:9200
第四步:启动kibana
双击启动
1.3 安装IK分词器
第一步:解压

第二步:把改完名为ik的文件夹直接拷贝到es软件的plugins文件夹下

第三步:重启ES软件
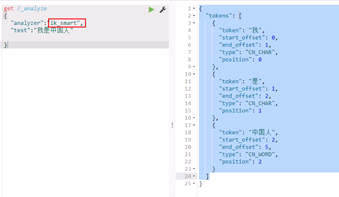
第四步:在kibana中测试
IK分词器提供了两种分词效果
Ik_max_word
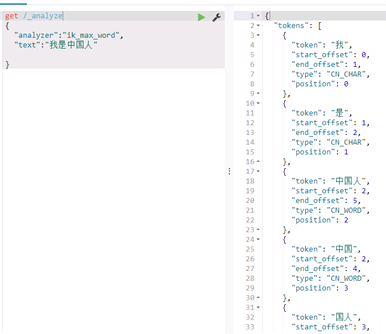
Ik_smart
2 了解几个概念
|
mysql数据库 |
ES |
|
Database |
Indices index的复数 |
|
Table |
Type 一般一个索引库中只有一个type |
|
数据 |
Document |
|
约束 列存储什么数据类型之类的 |
Mapping 规定字段什么数据类型、什么分词器 |
|
Column |
Field |
3 Kibana的操作
1.4 操作索引库index
创建索引库 heima代表一个索引库的名称
put heima
get heima
delete heima
1.5 操作映射和类型
比如:创建一个商品类型goods 有一下字段 goodsName price image
1、创建类型并且制定每个字段的属性(数据类型、是否存储、是否索引、哪种分词器)
put heima/_mapping/goods
{
"properties":{
"goodsName":{
"type":"text",
"analyzer":"ik_max_word",
"index":true,
"store":true
},
"price":{
"type":"double",
"index":true,
"store":true
},
"image":{
"type":"keyword",
"index":false,
"store":true
}
}
}
2、查看映射
get heima/_mapping[/goods]
3、 一起创建索引库和映射+类型
put heima2
{
"mappings": {
"goods": {
"properties": {
"goodsName": {
"type": "text",
"store": true,
"analyzer": "ik_max_word"
},
"image": {
"type": "keyword",
"index": false,
"store": true
},
"price": {
"type": "double",
"store": true
}
}
}
}
}
1.6 操作document
1.6.1 不指定id的新增
post heima/goods
{
"goodsName":"小米6X手机",
"price":1199,
"image":"http://image.im.com/123.jpg"
}
效果:
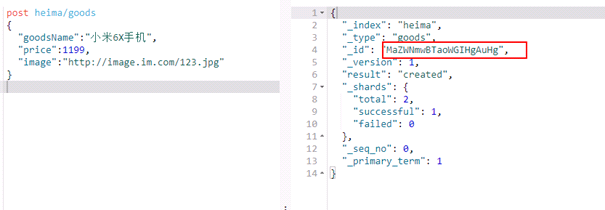
根据id查询文档
get heima/goods/MaZWNmwBTaoWGIHgAuHg
1.6.2 指定id的新增
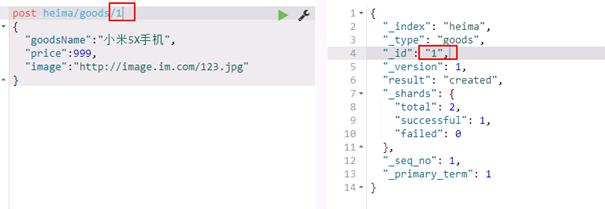
1.6.3 修改
put heima/goods/2
{
"goodsName":"小米6X手机",
"price":1199,
"image":"http://image.im.com/123.jpg"
}
使用put和post是一样的效果 根据id修改,如果没有id就是新增
1.6.4 删除
DELETE heima/goods/MaZWNmwBTaoWGIHgAuHg
DELETE heima/goods/1
1.6.5 自定义模板(了解)
put heima3
{
"mappings": {
"goods": {
"properties": {
"goodsName": {
"type": "text",
"store": true,
"analyzer": "ik_max_word"
},
"image": {
"type": "keyword",
"index": false,
"store": true
},
"price": {
"type": "double",
"store": true
}
},
"dynamic_templates":[
{
"myString":{
"match_mapping_type":"string",
"mapping":{
"type":"keyword"
}
}
}
]
}
}
}
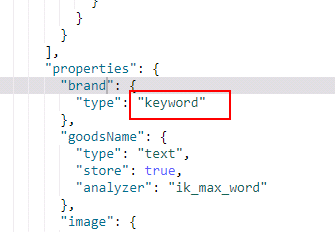
新增数据
get heima3/_mapping
{
"goodsName":"小米6X手机",
"price":1199,
"image":"http://image.im.com/123.jpg",
"brand":"小米"
}
查看brand的映射
2 查询(重点)
2.1 MatchAll
get heima/_search
{
"query":{
"match_all": {}
}
}
2.1 Term
get heima/_search
{
"query":{
"term": {
"goodsName":"小米"
}
}
}
2.2 分词match
get heima/_search
{
"query":{
"match": {
"goodsName": "小米手机"
}
}
}
2.3 Range范围查询
get heima/_search
{
"query":{
"range": {
"price": {
"gte": 100,
"lte": 1000
}
}
}
}
2.4 Fuzzy容错
get heima/_search
{
"query":{
"fuzzy": {
"goodsName": {
"value": "大米",
"fuzziness": 1
}
}
}
}
2.5 Bool组合查询
get heima/_search
{
"query":{
"bool":
{
"must": {"match":{"goodsName":"手机"}},
"must_not": {"range":{"price": {
"gte": 100,
"lte": 1000
}
}
}
}
}
}
3 过滤(重点)
3.1
、显示字段的过滤
get heima/_search
{
"_source":{
"excludes":["goodsName"] //排除
不显示goodsName
"includes":["goodsName"] //只显示goodsName
},
"query":{
"match_all": {}
}
}
}
3.2
、查询结果的过滤
get heima/_search
{
"query":{
"bool": {
"must":
{"term":{"goodsName":"手机"}},
"filter": {
"range": {
"price": {
"gte": 2000,
"lte": 5000
}
}
}
}
}
}
}
4
分页 和mysql分页一致的(重点)
get heima/_search
{
"query":{
"match_all": {}
},
"from":0, 起始位置 和mysql一样 (当前页-1)*size
"size":2
}
}
5
排序(重点)
get heima/_search
{
"query":{
"match_all": {}
},
"from":0,
"size":10,
"sort":{
"price":"desc"
}
}
}
6
高亮(重点)
get heima/_search
{
"query":{
"term": {
"goodsName": "小米"
}
},
"highlight":{
"pre_tags": "<font style='color:red'>",
"post_tags": "</font>",
"fields": {
"goodsName": {}
}
}
}
}
7
聚合(了解)
Min max count avg sum group by
桶: 就是group by 根据什么分组
度量:聚合函数的结果
3.3
创建测试数据
1、测试数据:
PUT /car
{
"mappings": {
"orders": {
"properties": {
"color": {
"type": "keyword"
},
"make": {
"type": "keyword"
}
}
}
}
}
POST /car/orders/_bulk
{ "index": {}}
{ "price" : 10000,
"color" : "红", "make" : "本田", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000,
"color" : "红", "make" : "本田", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000,
"color" : "绿", "make" : "福特", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000,
"color" : "蓝", "make" : "丰田", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000,
"color" : "绿", "make" : "丰田", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000,
"color" : "红", "make" : "本田", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000,
"color" : "红", "make" : "宝马", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000,
"color" : "蓝", "make" : "福特", "sold" : "2014-02-12" }
Term的聚合:根据color分组
3.4
演示聚合
get /car/orders/_search
{
"size":0,
"aggs":{
"populor_color":{
"terms": {
"field": "color",
"size": 10
}
}
}
}
3.5
聚合中计算平均值
get /car/orders/_search
{
"size":0,
"aggs":{
"populor_color":{
"terms": {
"field": "color",
"size": 10
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
8
使用java操作ES
Java代码操作ES有三种方式
1、ES原生api
2、ES rest风格api
3、SpringDataElasticSearch框架操作ES
https://www.elastic.co/guide/en/elasticsearch/client/index.html
第一步:创建maven项目
导入两个依赖
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.2.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.35</version>
</dependency>
</dependencies>
第二步:在代码中准备client
public class EsManager {
private TransportClient
client = null;
@Before
public
void init() throws Exception{
client
= new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
}
@After
public
void end(){
client.close();
}
}
第三步:各种查询
@Test
public void queryTest()
throws Exception{
//
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
// QueryBuilder queryBuilder =
QueryBuilders.matchQuery("goodsName","小米手机");
// QueryBuilder queryBuilder =
QueryBuilders.termQuery("goodsName","小米");
// FuzzyQueryBuilder queryBuilder
= QueryBuilders.fuzzyQuery("goodsName", "大米");
//
queryBuilder.fuzziness(Fuzziness.ONE);
// QueryBuilder queryBuilder =
QueryBuilders.rangeQuery("price").gte(1000).lte(2000);
BoolQueryBuilder
queryBuilder = QueryBuilders.boolQuery();
queryBuilder.must(QueryBuilders.rangeQuery("price").gte(1000).lte(8000));
queryBuilder.mustNot(QueryBuilders.termQuery("goodsName",
"华为"));
SearchResponse searchResponse = client.prepareSearch("heima").setQuery(queryBuilder).get();
SearchHits searchHits =
searchResponse.getHits();
long totalHits
= searchHits.getTotalHits();
System.out.println("总记录数:"+totalHits);
SearchHit[] hits =
searchHits.getHits();
for (SearchHit
hit : hits) {
String sourceAsString =
hit.getSourceAsString();
Goods goods =
JSON.parseObject(sourceAsString, Goods.class);
System.out.println(goods);
}
}
ELK-全文检索技术-kibana操作elasticsearch的更多相关文章
- 使用kibana操作elasticsearch实现增删改查
本篇博客,本人写的是方法,大家将对应的字段放入对应的位置就可以了 注:elasticsearch中,索引相当于MySQL中的数据库,类型相当于数据库中的表,即索引名就为数据库库名,类型就为表名 1.创 ...
- Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,
Linux下,非Docker启动Elasticsearch 6.3.0 查看java版本,需要1.8版本 java -version yum -y install java 创建用户,因为elasti ...
- elk快速入门-在kibana中如何使用devtools操作elasticsearch
在kibana中如何使用devtools操作elasticsearch:前言: 首先需要安装elasticsearch,kibana ,下载地址 https://www.elastic.co/cn/d ...
- Es图形化软件使用之ElasticSearch-head、Kibana,Elasticsearch之-倒排索引操作、映射管理、文档增删改查
今日内容概要 ElasticSearch之-ElasticSearch-head ElasticSearch之-安装Kibana Elasticsearch之-倒排索引 Elasticsearch之- ...
- windows系统中 利用kibana创建elasticsearch索引等操作
elasticsearch之借用kibana平台创建索引 1.安装好kibana平台 确保kibana以及elasticsearch正常运行 2.打开kibana平台在Dev Tools 3.创建一个 ...
- Kibana基础之直接操作ElasticSearch
1.入门级别操作 Elasticsearch采用Rest风格API,其API就是一次http请求,你可以用任何工具发起http请求 创建索引的请求格式: 请求方式:PUT 请求路径:/索引库名 请求参 ...
- net平台下c#操作ElasticSearch详解
net平台下c#操作ElasticSearch详解 ElasticSearch系列学习 ElasticSearch第一步-环境配置 ElasticSearch第二步-CRUD之Sense Elasti ...
- java操作elasticsearch实现基本的增删改查操作
一.在进行java操作elasticsearch之前,请确认好集群的名称及对应的ES节点ip和端口 1.查看ES的集群名称 #进入elasticsearch.yml配置文件/opt/elasticse ...
- ElasticSearch-.net平台下c#操作ElasticSearch详解
ElasticSearch系列学习 ElasticSearch第一步-环境配置 ElasticSearch第二步-CRUD之Sense ElasticSearch第三步-中文分词 ElasticSea ...
随机推荐
- [BZOJ3786] 星系探索(括号序列+Splay)
3786: 星系探索 Time Limit: 40 Sec Memory Limit: 256 MBSubmit: 2191 Solved: 644[Submit][Status][Discuss ...
- 高性能JavaScript之加载和执行
JS在浏览器中的性能,可以认为是开发者所面临的最重要的可行性问题.这个问题因JS的阻塞特性变得复杂,也就是说当浏览器在执行JS代码时,不能同时做其他任何事情.事实上,大多数浏览器都使用单一进程来处理U ...
- spring整合之后运行报什么只读错误。Write operations are not allowed in read-only mode (FlushMode.MANUAL): Turn your Session into FlushMode.COMMIT/AUTO or remove 'readOnly' marker from transaction definition.
解决办法, 再大dao的实现类上添加注解: @Transactional(readOnly = false ) 不让它只读就行了
- 如何在外部获取当前A标签的ID值
<div class="diskmain"> <ul id="folder"> <li><span class='do ...
- 【Linux】GDB用法详解(5小时快速教程)
GDB是一个强大的命令行调试工具.虽然X Window提供了GDB的图形版DDD,但是我仍然更钟爱在命令行模式下使用GDB.大家知道命令行的强大就是在于,其可以形成执行序列,形成脚本. UNIX下的软 ...
- PHP 设置Cookie值注意项
Cookie 中的value值只能添加设置为String类型的字符串数据,但我们需要添加如数组,json串等其他类型的数据时,我们就要先对数据进行转换,再存入Cookie里了. Cookie 存储数组 ...
- 继成极光推送SDk的实现
进入极光推送官网:https://www.jiguang.cn/push 注册,创建应用,申请APPKey等操作 代码实现: 确认android studio的 Project 根目录的主 gradl ...
- 【flask】处理表单数据
表单数据的处理涉及很多内容,除去表单提交不说,从获取数据到保存数据大致会经历以下步骤: 解析请求,获取表单数据. 对数据进行必要的转换,比如将勾选框的植转换为Python的布尔值. 验证数据是否符合 ...
- ControlTemplate in WPF —— Menu
<ResourceDictionary xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" x ...
- Java学习之==>int和Integer的区别和联系
一.区别 1.类型 int是java中原始八种基本数据类型之一: Integer是一个类,包装整型提供了很多日常的操作: 2.存储位置和大小 int是由jvm底层提供,由Java虚拟机规范,int型数 ...