29. ClustrixDB 分布式架构/并发控制
介绍
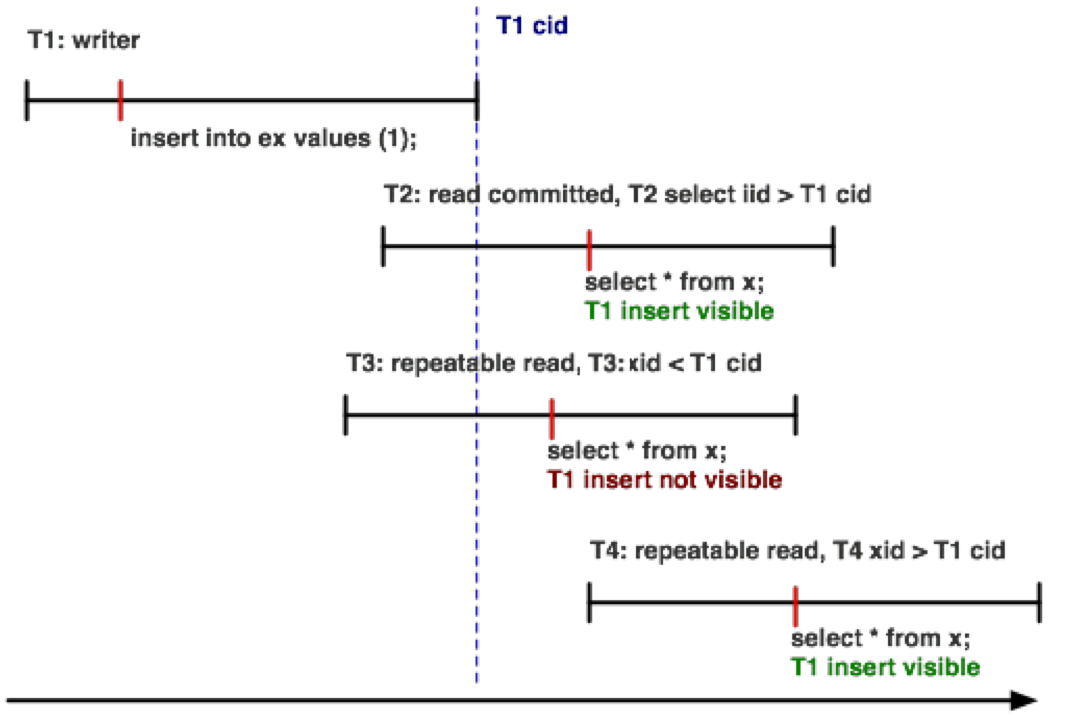
ClustrixDB使用多版本并发控制(MVCC)和2阶段锁(2PL)的组合来支持混合的读写工作负载。在我们的系统中,读取器享受无锁快照隔离,而写入器使用2PL来管理冲突。并发控制的组合意味着读取器不会干扰写入器(反之亦然),写入器使用显式锁定来排序更新
多版本并发控制
ClustrixDB实现了一个分布式MVCC方案,以确保读取器是无锁的,因此读取器和写入器之间不会相互干扰。当编写者修改系统中的行时,ClustrixDB维护每一行的版本历史。事务中的每个语句都使用对数据的无锁访问来检索行的相关版本。
可见性规则
ClustrixDB中的可见性规则由与每个事务和语句执行相关联的一组id(标识符)控制。由事务修改的行仅在修改事务提交后对其他事务可见。一旦事务提交,它就会生成一个提交id (cid),修改在这个id上是可见的。
下面的图表显示了事务的生命周期。
| Transaction Lifespan | |
|---|---|
 |
|
| xid | Transaction start id. Marks the logical beginning of the transaction. |
| iid | Invocation id. Marks the beginning of a statement within a transaction. |
| cid |
Commit id. Marks the id at which transaction changes are visible to other transactions. |
隔离级别
每个隔离级别都有一组不同的可见性规则。下表描述了事务之间行可见性的基本规则。
|
Isolation Level
|
Snapshot Anchor
|
Comment
|
|---|---|---|
| Read committed | statement |
比ANSI定义的read committed更严格。允许每个语句读取一致的快照。 事务中的每个后续语句都将获得一个新的iid,因此每个新语句都可以看到在语句开始执行之前提交的行(但在执行过程中不会看到)。 最类似于Oracle的一致读隔离。 当语句(调用)id >修改事务提交id时,行是可见的。 |
|
Repeatable read (default) |
transaction |
比ANSI定义的可重复读更严格。允许对每个事务读取一致的快照。 事务中的每个后续语句都在事务开始时看到数据库。 事务还可以观察在事务中对数据库所做的更改。 当事务id >修改事务提交id时,行是可见的。 |
| Serializable | transaction |
严格的ANSI隔离级别。系统用于在集群中执行数据移动。 当事务id >修改事务提交id时可见的行。 当MVCC调度程序不能保证事务的可串行性时,数据库返回一个错误。 注意:可序列化隔离目前不适用于最终用户事务。 |
下面的示例演示了事务可见性如何在不同的隔离级别上工作。
ID 生成器
ClustrixDB使用全局惟一的有序事务id (xid)和语句调用id (iid)来控制行可见性。xid和iid生成器都使用系统范围的时钟和惟一节点id的组合来创建全局惟一的有序标识符。
版本历史和垃圾收集
ClustrixDB通过undo日志维护版本历史。由于undo日志必须已经维护了关于事务回滚的行以前版本的信息,所以我们可以使用这些信息来访问MVCC的行以前版本。该技术允许ClustrixDB维护按主键聚集的表,而不是管理大量堆空间。对于插入和更新,垃圾收集在我们修剪undp日志时发生。但是,ClustrixDB保留了足够的undo日志历史记录来服务当前执行的事务。除了将undo日志修剪限制在本地检查点规则之外,我们还根据系统中最古老事务的id限制修剪。
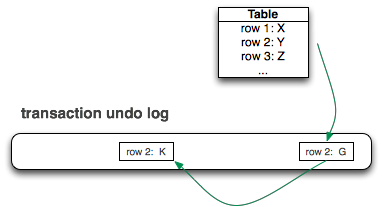
上面的关系图演示了系统如何在undo日志中保留该行的多个版本。每一行包含一个日志序列号(LSN),它指向该行的前一个版本。我们知道,当之前的LSN指针先于修剪LSN时,我们已经到达了历史链的末端。
写操作的两阶段锁定
乐观并发控制在存在冲突(两个事务试图同时更新同一行)时不能很好地工作。在这种情况下,纯MVCC系统将回滚一个或两个冲突的事务并重新启动操作。因为ClustrixDB不需要使用预先确定的事务(例如,存储过程中的所有逻辑),所以这些错误可能会出现在应用程序中。此外,还可以创建实时锁定场景,在这种场景中,由于持续的冲突,事务无法取得进展。
为了克服这些问题,ClustrixDB使用锁来解决写-写冲突。写入器总是在进行任何更改之前读取最新提交的信息并获取锁。
分布式锁管理器
ClustrixDB实现了一个分布式锁管理器来扩展对热表的写访问。在集群中,每个节点维护锁域的一部分。没有一个节点包含集群的所有锁信息。
行级和表级锁定
ClustrixDB为每次接触几行的事务实现行级锁(运行时可配置的变量)。对于影响表的重要部分的语句,查询优化器将把行级锁提升为表锁。
29. ClustrixDB 分布式架构/并发控制的更多相关文章
- 28. ClustrixDB 分布式架构/评估模型
本节描述如何在数据库中计算查询.在ClustrixDB中,我们跨节点切片数据,然后将查询发送到数据.这是数据库的基本原则之一,它允许随着添加更多节点而几乎线性地扩展. 有关如何分布数据的概念,请参阅数 ...
- 27. ClustrixDB 分布式架构/一致性、容错和可用性
一致性 许多分布式数据库都采用最终一致性而不是强一致性来实现可伸缩性.但是,最终的一致性会增加应用程序开发人员的复杂性,他们必须针对可能出现的数据不一致的异常进行开发. ClustrixDB提供了一个 ...
- 26. ClustrixDB 分布式架构/数据分片
数据分片 介绍 共享磁盘vs.无共享 分布式数据库系统可分为两大类数据存储架构:(1)共享磁盘和(2)无共享. Shared Disk Architecture Shared Nothing Arch ...
- 31. ClustrixDB 分布式架构/查询优化器
ClustrixDB查询优化器有何不同 ClustrixDB查询优化器的核心是能够执行一个具有最大并行性的查询和多个具有最大并发性的并发查询.这是通过分布式查询规划器和编译器以及分布式无共享执行引擎实 ...
- 30. ClustrixDB 分布式架构/Rebalancer
Rebalancer是一个自动化系统,用于维护集群中数据的健康分布.通过修改数据的分布和位置来响应“不健康”集群是Rebalancer的工作.Rebalancer是一个在线进程,它影响对集群的更改,对 ...
- shiro权限控制(二):分布式架构中shiro的实现
前言:前段时间在搭建公司游戏框架安全验证的时候,就想到之前web最火的shiro框架,虽然后面实践发现在netty中不太适用,最后自己模仿shiro写了一个缩减版的,但是中间花费两天时间弄出来的shi ...
- 分布式架构中shiro
分布式架构中shiro 前言:前段时间在搭建公司游戏框架安全验证的时候,就想到之前web最火的shiro框架,虽然后面实践发现在netty中不太适用,最后自己模仿shiro写了一个缩减版的,但是中间花 ...
- nginx+iis+redis+Task.MainForm构建分布式架构 之 (redis存储分布式共享的session及共享session运作流程)
本次要分享的是利用windows+nginx+iis+redis+Task.MainForm组建分布式架构,上一篇分享文章制作是在windows上使用的nginx,一般正式发布的时候是在linux来配 ...
- windows+nginx+iis+redis+Task.MainForm构建分布式架构 之 (nginx+iis构建服务集群)
本次要分享的是利用windows+nginx+iis+redis+Task.MainForm组建分布式架构,由标题就能看出此内容不是一篇分享文章能说完的,所以我打算分几篇分享文章来讲解,一步一步实现分 ...
随机推荐
- JDBC基本操作
前言:什么是JDBC 维基百科的简介: Java 数据库连接,(Java Database Connectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提 ...
- [c++] 计算太阳高度角
/* 输入参数: Longitude - 经度(单位"度") Latitude - 纬度(单位"度") Year - 年 Month - 月 Day - 日 H ...
- Next Closest Time
Given a time represented in the format "HH:MM", form the next closest time by reusing the ...
- [转帖]docker清理日志
docker清理日志 2017年05月03日 10:37:27 不想当码农的程序员 阅读数 12827 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn. ...
- Java 中的动态代理
一.概述 1. 什么是代理 我们大家都知道微商代理,简单地说就是代替厂家卖商品,厂家“委托”代理为其销售商品.关于微商代理,首先我们从他们那里买东西时通常不知道背后的厂家究竟是谁,也就是说,“委托者” ...
- k8s部分名称解释
k8s部分名词解释 NameSpace:命名空间 Namespace是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组.常见的pods, services, repl ...
- sqlalchemy.exc.InternalError: (pymysql.err.InternalError) (1091, "Can't DROP 'users_ibfk_1'; check that column/key exists") [SQL: ALTER TABLE users DROP FOREIGN KEY users_ibfk_1]
flask 迁移数据库报错 报错: sqlalchemy.exc.InternalError: (pymysql.err.InternalError) (1091, "Can't DROP ...
- 直通BAT必考题系列:JVM性能调优的6大步骤,及关键调优参数详解
JVM内存调优 对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数. 1.Full GC 会对整个堆进行整理,包括Young.Tenured和Perm.Full GC因为需要对 ...
- Nginx的快速安装
1. 准备工作 1. CenterOS7.x.vmware虚拟机,安装过程参考 https://jingyan.baidu.com/article/eae0782787b4c01fec548535.h ...
- linux shell 数组的使用
引言 在Linux平台上工作,我们经常需要使用shell来编写一些有用.有意义的脚本程序.有时,会经常使用shell数组.那么,shell中的数组是怎么表现的呢,又是怎么定义的呢?接下来逐一的进行讲解 ...