IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
1. ik分词器的下载和安装,测试
第一: 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases ,这里你需要根据你的Es的版本来下载对应版本的IK,这里我使用的是6.3.2的ES,所以就下载ik-6.3.2.zip的文件。
第二: 解压-->将文件复制到 es的安装目录/plugin/ik下面即可,完成之后效果如下:
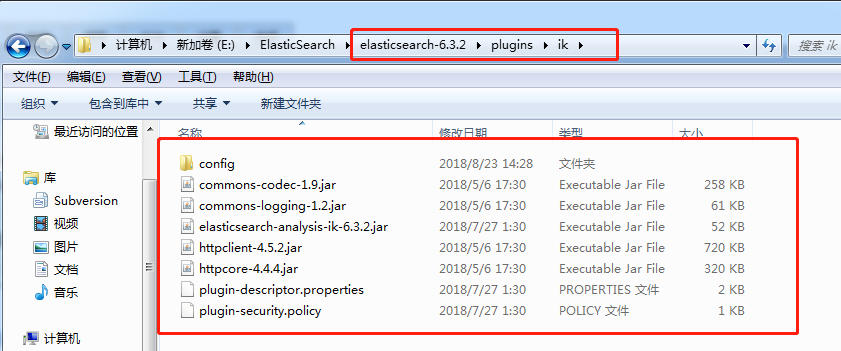
到这里已经完成了,不需要去elasticSearch的 elasticsearch.yml 文件去配置。
第三:重启ElasticSearch
第四:测试效果
未使用ik分词器的时候测试分词效果:

- POST book/_analyze
- {
- "text": "我是中国人"
- }
- //结果是:
- {
- "tokens": [
- {
- "token": "我",
- "start_offset": 0,
- "end_offset": 1,
- "type": "<IDEOGRAPHIC>",
- "position": 0
- },
- {
- "token": "是",
- "start_offset": 1,
- "end_offset": 2,
- "type": "<IDEOGRAPHIC>",
- "position": 1
- },
- {
- "token": "中",
- "start_offset": 2,
- "end_offset": 3,
- "type": "<IDEOGRAPHIC>",
- "position": 2
- },
- {
- "token": "国",
- "start_offset": 3,
- "end_offset": 4,
- "type": "<IDEOGRAPHIC>",
- "position": 3
- },
- {
- "token": "人",
- "start_offset": 4,
- "end_offset": 5,
- "type": "<IDEOGRAPHIC>",
- "position": 4
- }
- ]
- }
使用IK分词器之后,结果如下:
- POST book_v6/_analyze
- {
- "analyzer": "ik_max_word",
- "text": "我是中国人"
- }
- //结果如下:
- {
- "tokens": [
- {
- "token": "我",
- "start_offset": 0,
- "end_offset": 1,
- "type": "CN_CHAR",
- "position": 0
- },
- {
- "token": "是",
- "start_offset": 1,
- "end_offset": 2,
- "type": "CN_CHAR",
- "position": 1
- },
- {
- "token": "中国人",
- "start_offset": 2,
- "end_offset": 5,
- "type": "CN_WORD",
- "position": 2
- },
- {
- "token": "中国",
- "start_offset": 2,
- "end_offset": 4,
- "type": "CN_WORD",
- "position": 3
- },
- {
- "token": "国人",
- "start_offset": 3,
- "end_offset": 5,
- "type": "CN_WORD",
- "position": 4
- }
- ]
- }
对于上面两个分词效果的解释:
1. 如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
2. 如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字。
2. 创建指定分词器的索引
索引创建之后就可以使用ik进行分词了,当你使用ES搜索的时候也会使用ik对搜索语句进行分词,进行匹配。
- PUT book_v5
- {
- "settings":{
- "number_of_shards": "6",
- "number_of_replicas": "1",
- //指定分词器
- "analysis":{
- "analyzer":{
- "ik":{
- "tokenizer":"ik_max_word"
- }
- }
- }
- },
- "mappings":{
- "novel":{
- "properties":{
- "author":{
- "type":"text"
- },
- "wordCount":{
- "type":"integer"
- },
- "publishDate":{
- "type":"date",
- "format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd"
- },
- "briefIntroduction":{
- "type":"text"
- },
- "bookName":{
- "type":"text"
- }
- }
- }
- }
- }
关于ik分词器的分词类型(可以根据需求进行选择):
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。如下:
- POST book_v6/_analyze
- {
- "analyzer": "ik_smart",
- "text": "我是中国人"
- }
- //结果
- {
- "tokens": [
- {
- "token": "我",
- "start_offset": 0,
- "end_offset": 1,
- "type": "CN_CHAR",
- "position": 0
- },
- {
- "token": "是",
- "start_offset": 1,
- "end_offset": 2,
- "type": "CN_CHAR",
- "position": 1
- },
- {
- "token": "中国人",
- "start_offset": 2,
- "end_offset": 5,
- "type": "CN_WORD",
- "position": 2
- }
- ]
- }
IK分词器的安装与使用IK分词器创建索引的更多相关文章
- ElasticSearch(六):IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. 1. i ...
- docker上安装elasticsearch和ik分词器插件和header,实现分词功能
docker run -di --name=tensquare_es -p 9200: -p 9300:9300 elasticsearch:5.6.8 创建elasticsearch容器(如果版本不 ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- docker 安装ElasticSearch的中文分词器IK
首先确保ElasticSearch镜像已经启动 安装插件 方式一:在线安装 进入容器 docker exec -it elasticsearch /bin/bash 在线下载并安装 ./bin/ela ...
- es的插件 ik分词器的安装和使用
今天折腾了一天,在es 5.5.0 上安装ik.一直通过官方给定的命令没用安装成功,决定通过手工是形式进行安装.https://github.com/medcl/elasticsearch-analy ...
- Linux安装ElasticSearch-2.2.0-分词器插件(IK)
1.在gitpub上搜索elasticsearch-analysis,能够看到所有elasticsearch的分词器: 2.安装IK分词器:https://github.com/medcl/elast ...
- Elasticsearch5.0.1 + Kibana5.0.1 + IK 5.0.1安装记录
最近工作需要,开始研究ES,当前ES的最新版本为5.0.1,从之前的2.x的版本号一下升级到5.x,主要是之前Elastic的产品版本号因为收购等原因很乱,ES 2.X版本的和Kibana 4.x版本 ...
- solr 7+tomcat 8 + mysql实现solr 7基本使用(安装、集成中文分词器、定时同步数据库数据以及项目集成)
基本说明 Solr是一个开源项目,基于Lucene的搜索服务器,一般用于高级的搜索功能: solr还支持各种插件(如中文分词器等),便于做多样化功能的集成: 提供页面操作,查看日志和配置信息,功能全面 ...
- elasticsearch分词插件的安装
IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Luen ...
随机推荐
- java代码调用exe(cmd命令)
public class ShellCommand{ public static void execCmd(String cmd, boolean wait) { execC ...
- 【leetcode】960. Delete Columns to Make Sorted III
题目如下: We are given an array A of N lowercase letter strings, all of the same length. Now, we may cho ...
- MFC:OnCreate PreCreateWindow PreSubclassWindow
OnCreate PreCreateWindow PreSubclassWindow PreCreateWindow和PreSubclassWindow是虚函数,而OnCreate是一个消息响应函数. ...
- 什么是DOM(文档对象模型)?
㈠什么是DOM? 文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口. DOM 定义了访问 HTML 和 XML 文档的标准: ...
- jquery pageY属性 语法
jquery pageY属性 语法 作用:pageY() 属性是鼠标指针的位置,相对于文档的上边缘.直线模组 语法:event.page 参数: 参数 描述 event 必需.规定要使用的事件 ...
- css 内容居中
css: parent{display:table;} child{display:table-cell;vertical-align:middle;}
- ASE高级软件工程 第一周博客作业
1.自我介绍 我叫姚顺,是来自哈尔滨工业大学计算机学院的一名大四本科生,专业方向计算机科学,目前在KC组实习.平时的业余时间主要用来打篮球,听音乐,跑步,当然还有游戏(划掉).之前的大学三年主要用来做 ...
- luoguP1041 传染病控制 x
P1041 传染病控制 题目背景 近来,一种新的传染病肆虐全球.蓬莱国也发现了零星感染者,为防止该病在蓬莱国大范围流行,该国政府决定不惜一切代价控制传染病的蔓延.不幸的是,由于人们尚未完全认识这种传染 ...
- Jmeter(三) 从上传图片来入门Jmeter
用Jmeter上传用户头像到人人网 先用抓包工具Fiddler把上传操作的报文抓取下来 开启Jmeter,在测试计划中创建一个线程组,取名为“图片上传” 再在线程组中创建一个HTTP请求 在请求报文中 ...
- 关于多个py文件生成一个可运行exe文件(用pyinstaller)
首先下载Pyinstaller,在cmd命令下执行:pip installer Pyinstaller,不需要关心安装在哪 然后把所有相关的py文件都放在一个目录下 在那个目录下执行cmd命令:pyi ...