spark network-common
概述
Spark底层使用netty作为节点间通信的桥梁。其实现在common/network-common包中。common/network-common包主要是对netty进行了一层封装,主要是定义了一套消息格式,粘包拆包,链路生命周期对应方法实现等功能。我们首先来看一下network-common包的包结构:
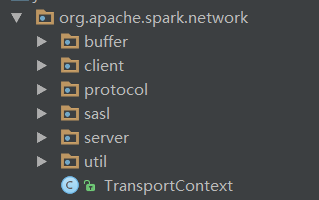
其中buffer包为实现Netty的ByteBuf和Java NIO的ByteBuffer相互转换操作的类,client包包含客户端的实现类,protocol包包含了消息格式/类型定义的类,sasl包包含了连接认证和加密的类,server包包含了服务端的实现类,util为相关的工具类包。而在根目录下面的`TransportContext`类主要保存了Spark网络连接的上下文,以及创建客户端/服务端的方法,上层应用直接调用这个类的相关方法来创建客户端/服务端,而不用调用底层的客户端/服务端实现类。
消息格式&类型
我们知道TCP是以字节流在网络上传输数据的,而应用程序中的数据是以结构化方式来定义的,所以如何将结构化数据转化为字节流传输到网络,以及如何将来自网络的字节流转换为结构化数据供应用程序使用,这就需要定义一个消息格式。在Netty中默认提供了几个消息转换的实现类,比如按换行符解析消息,按定长来解析消息等。Spark没有使用Netty自带的类实现消息的发送和解析,而是自定义了一个消息格式,客户端和服务端都依赖这个消息格式来进行编解码。Spark中的消息格式如下:
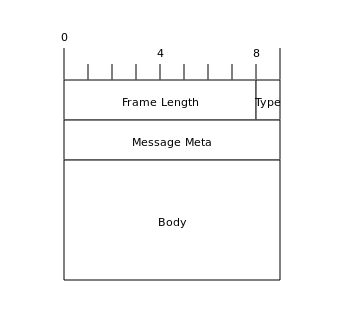
其中前8个字节称为Frame Length,用来记录整个消息包的大小,之后1个字节称为Type,用来标示消息类型(目前Spark存在10种消息类型),之后是两个变长的部分,即Message Meta和Body。其中Message Meta主要是每类消息用来保存相关元数据的部分,在每类消息中的具体结构都不相同,这个在之后介绍每种消息类型时再具体分析。之后是Body字段,用来保存消息的消息体(即消息的有效载荷所在的地方)。在Spark的消息中,Body之前的部分(Frame Length, Type, Message Meta)称为消息头,Body为消息体。Spark中有几种消息类型只有消息头,没有消息体,还有的消息存在有效载荷,但是不是包装在消息的消息体里,而是在消息外部,紧跟消息(如StreamResponse)。接下来我们逐一分析每种消息。首先看一下Spark的消息类型结构:
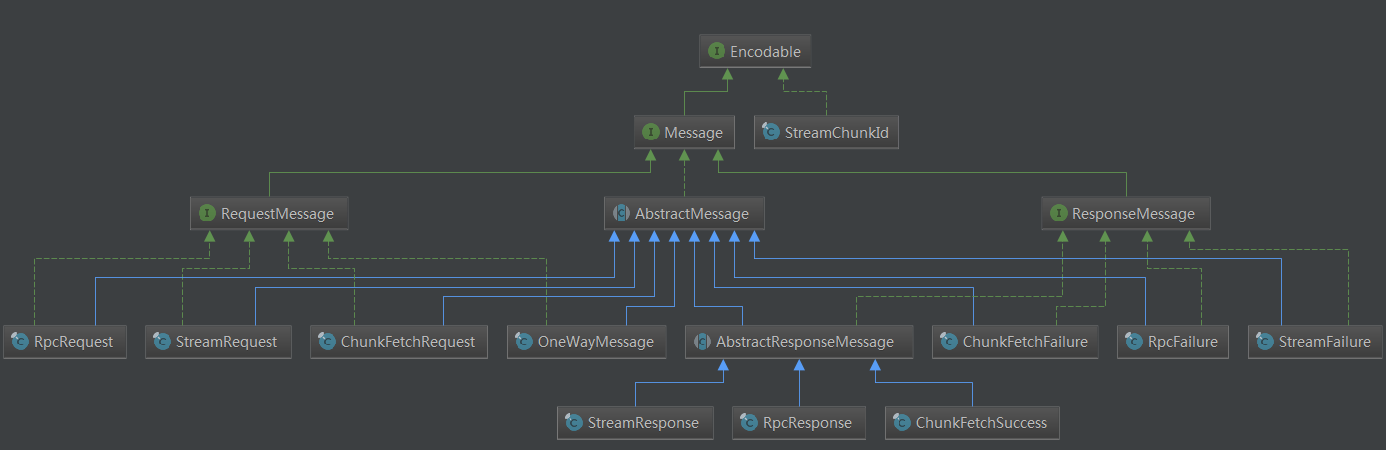
可见Spark中有两类消息:RequestMessage和ResponseMessage,分别对应发送出去的请求,和接收到的响应。按照消息功能可以分为四类消息:RPC类型消息,OneWayMessage消息,ChunkFetch类型消息,Stream类型消息。
RPC消息
RPC类型的消息是Spark用来进行RPC操作时发送的消息,主要用来发送控制类的消息。RPC消息包括RpcRequest,RpcFailure,RpcResponse。每个RpcRequest消息都要求服务端回传一个RPC响应(RpcFailure/RpcResponse),在发送RpcRequst消息时,会在客户端注册一个回调函数,并绑定到消息的唯一标识符requestId上。当服务端回传RPC响应时,客户端会根据回传消息中的requestId,找到注册的回调函数,然后调用回调函数来执行服务端响应后的逻辑。我们分别看一下RPC的三种消息格式:
RpcRequest&RpcResponse:
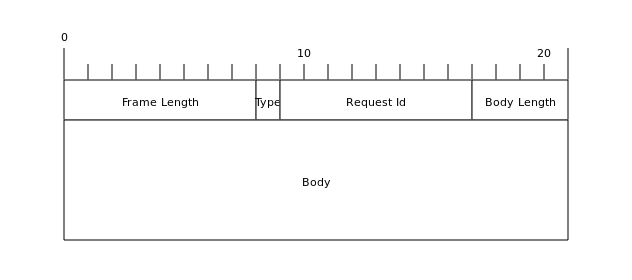
其中RpcRequest和RpcResponse两种消息类型的消息格式是相同的,上文提到的Message Meta字段,在这里对应Request Id和Body Length字段。其中Request Id为8个字节,用来作为消息的唯一标识。Body Length为4个字节,用来记录Body的长度。之后就是Body(消息体)数据。
RpcFailure:

RpcFailure消息与RpcRequest和RpcResponse不同,RpcFailure没有消息体,RpcFailure的错误信息是直接写在消息头中的。RpcFailure的Message Meta部分,在这里被分成了三个字段,Request Id占据8个字节,之后是Message Length,占据4个字节,用来记录错误信息(Error Message)的长度,最后是变长的Error Message字段,保存错误信息。
OneWayMessage 消息
OneWayMessage消息与RPC消息类似,也是Spark用来发送控制命令的消息类型。与RPC消息不同的是,OneWayMessage消息不需要服务端回传响应,客户端只负责发送出OneWayMessage消息,而无需服务端回传响应。OneWayMessage的消息结构如下:
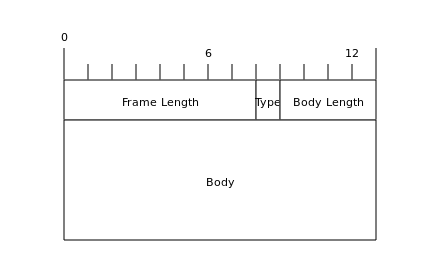
由于OneWayMessage不需要服务端回传,所以在OneWayMessage的Message Meta部分,只有Body Length,用来记录Body的长度,而没有Request Id字段。
ChunkFetch消息
ChunkFetch类型消息在Spark中用来标示与数据传输相关的操作,如shuffle数据,RDD block数据等。ChunkFetch类型包括ChunkFetchRequest,ChunkFetchSuccess,ChunkFetchFailure三种消息。这三种类型的消息结构如下:
ChunkFetchRequest:

ChunkFetchRequest中的Message Meta部分,分为了两个字段Stream Id,占据8个字节用来标示请求的资源流的id,Chunk Index占据4个字节,标示请求资源的第几个chunk。
ChunkFetchSuccess:
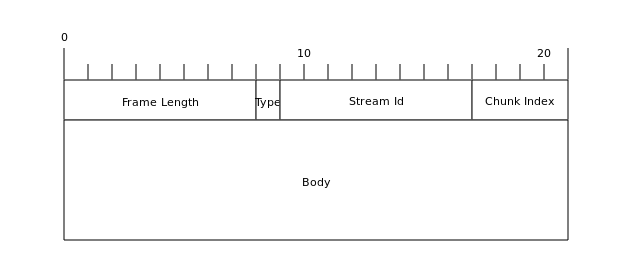
ChunkFetchSuccess类型消息与ChunkFetchRequest类似,只不过带上了包含请求的资源的消息体。
ChunkFetchFailure:

ChunkFetchFailure消息的Message Meta包含四个字段,其中前两个字段Stream Id和Chunk Index与ChunkFetchSuccess和ChunkFetchRequest相同,第三个字段Message Length为4个字节,记录错误信息的长度,第四个字段Error Message变长,记录错误信息。ChunkFetchFailure类型消息没有消息体。
Stream消息
Stream类型消息在Spark中主要用来将driver上的jar包/文件/文件夹传出到executor上。Stream类型包括StreamRequest,StreamFailure和StreamResponse三种消息。当executor需要driver 的jar包或文件时,就会向driver发送一个StreamRequset请求,之后driver会将数据封装在StreamResponse中,返回给executor。executor在接收到来自driver的StreamReponse的消息后,会建立一个临时的handler,使用这个handler解析对应的jar包/文件/文件夹信息(具体Stream解析流程见下文分析)。这三种类型消息的结构如下:
StreamRequest:

StreamRequest消息Message Meta包含两个字段:Stream Id Length占据4个字节,用来记录Stream Id长度,Stream Id变长,用来保存请求的Stream Id。
StreamResponse:
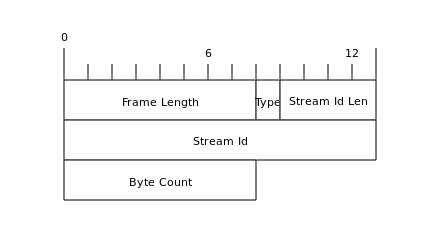
StreamResponse与StreamRequest类似,只是在变长的Stream Id字段后,增加了8个字节的Byte Count字段,用来标示返回的流数据大小。这里需要注意的是,Spark中返回的流数据不是写在StreamResponse的消息体中的(StreamResponse实际没有消息体),而是直接跟在这个消息Byte Count这8个字节之后。在解码时,读取Byte Count字节后面的Byte Count个字节,就是返回的流数据。
StreamFailure:

StreamFailure的Message Meta包含四个字段,Stream Id Length和Stream Id与StreamResponse和StreamRequest消息中的字段一致,Message Length字段标示错误信息的长度,最后是一个边长的Error Message字段,保存错误信息。
客户端&服务端创建
Spark中的客户端和服务端的创建基本上就是对Netty做了一层封装,本质上还是Netty客户端/服务端的创建流程。如果对Netty创建客户端/服务端的流程还不是很了解的话,请移步【这里是Netty学习的链接】。
我们知道,Netty在创建客户端和服务端的时候,除了设置客户端和服务端特定的参数,还需要设置handler。而在Spark中客户端和服务端的handler的设置最终都是调用TransportContext.initializePipeline方法。而这个方法返回的是一个TransportChannelHandler类型。所以在Spark中,实际是将客户端和服务端的handler都封装在了TransportChannelHandler中,而在TransportChannelHandler中通过消息类型的不同,在转发给对应的RequestHandler或ResponseHandler来执行。我们看一下TransportContext.initializePipeline方法:
public TransportChannelHandler initializePipeline(
SocketChannel channel,
RpcHandler channelRpcHandler) {
// 省略try-catch代码
TransportChannelHandler channelHandler = createChannelHandler(channel, channelRpcHandler);
channel.pipeline()
.addLast("encoder", encoder)
.addLast(TransportFrameDecoder.HANDLER_NAME, NettyUtils.createFrameDecoder())
.addLast("decoder", decoder)
.addLast("idleStateHandler", new IdleStateHandler(0, 0, conf.connectionTimeoutMs() / 1000))
.addLast("handler", channelHandler);
return channelHandler;
}
可见Spark中Netty的ChannelPipeline中的handler结构如下:
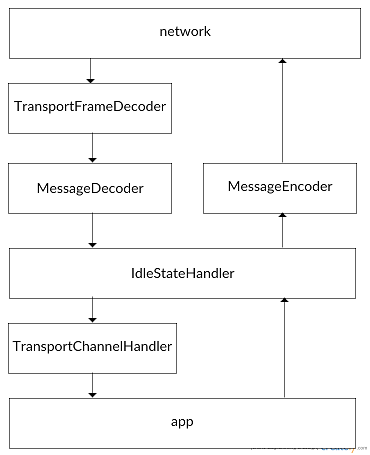
来自网络的请求首先经过TransportFrameDecoder进行粘包拆包,然后将数据传递给MessageDecoder,由MessageDecoder进行解码,之后再经过IdleStateHandler来检查Channel空闲情况,最终将解码了的消息传递给TransportChannelHandler。在TransportChannelHandler中根据消息类型的不同转发给不同的处理方法进行处理,将消息发送给上层的代码。
而来自上层代码的消息要发送到网络时,首先经过IdleStateHandler判断Channel空闲情况,之后经过MessageEncoder进行编码然后发送到网络。接下来我们重点看一下TransportChannelHandler是如何将消息分发到对应的处理器上的。
其中TransportFrameDecoder,MessageDecoder,MessageEncoder类,只要了解了上文介绍的每个消息类型的结构后就不难理解其中的源码实现了,这里就不再做分析了。
### TransportChannelHandler
TransportChannelHandler继承了Netty的SimpleChannelInboundHandler类,对Netty Inbound接口的生命周期进行了实现,我们在这里就拿最关键的read方法来看一下TransportChannelHandler是如何将从网络接收到的消息转发给实际的处理器执行的:
public void channelRead0(ChannelHandlerContext ctx, Message request) throws Exception {
if (request instanceof RequestMessage) {
requestHandler.handle((RequestMessage) request);
} else {
responseHandler.handle((ResponseMessage) request);
}
}
还记得我们之前提到的,Spark中的消息分为两大类:RequestMessage(请求消息)和ResponseMessage(响应消息),10种消息类型或者是请求消息或者是响应消息。所以在TransportChannelHandler.channelRead0中就根据消息类型的不同,将请求消息转发给TrannsportRequestHandler,将响应消息转发给TransportResponseHandler。
TransportRequestHandler
RequestMessage是由请求发起方(客户端)发送给响应方(服务端)的消息,RequestHandler是在响应方(服务端)实现的代码,用来处理来自请求发起方(客户端)RequestMessage。在TransportRequestHandler中,根据RequestMessage消息类型的不同,将消息委托给对应的方法来处理:
public void handle(RequestMessage request) {
if (request instanceof ChunkFetchRequest) {
processFetchRequest((ChunkFetchRequest) request);
} else if (request instanceof RpcRequest) {
processRpcRequest((RpcRequest) request);
} else if (request instanceof OneWayMessage) {
processOneWayMessage((OneWayMessage) request);
} else if (request instanceof StreamRequest) {
processStreamRequest((StreamRequest) request);
} else {
throw new IllegalArgumentException("Unknown request type: " + request);
}
}
在这里我们以RpcRequest为例,看一下对RpcRequest的处理方法:
private void processRpcRequest(final RpcRequest req) {
// 省略异常检查代码
rpcHandler.receive(reverseClient, req.body().nioByteBuffer(), new RpcResponseCallback() {
@Override
public void onSuccess(ByteBuffer response) {
respond(new RpcResponse(req.requestId, new NioManagedBuffer(response)));
}
@Override
public void onFailure(Throwable e) {
respond(new RpcFailure(req.requestId, Throwables.getStackTraceAsString(e)));
}
});
}
可见最终是调用RpcHandler.receive方法来处理消息,并创建了一个回调实例传入RpcHandler.receive方法,在之后消息被处理后,会根据处理成功还是失败调用回调实例的onSuccess或onFailure方法,从而向客户端发送响应消息(ResponseMessage)。RpcHandler为抽象方法,在Spark中有多个实现,其中我们会在`spark rpc`这篇文章中介绍其中的一个实现NettyRpcHandler,这个类用来接收来自TransportRequestHandler的消息,并发送给上层的Rpc实现代码进行处理。
TransportResponseHandler
ResponseMessage是由响应方(服务端)发送给请求发起方(客户端)的消息,ResponseHandler是在请求发起方(客户端)的代码,用来处理来自响应方(服务端)响应的ResponsMessage。TransportResponseHandler处理ResponseMessage的方式与TransportRequestHandler相同,也是根据ResponseMessage的类型,调用不同的处理方法进行处理:
public void handle(ResponseMessage message) throws Exception {
// 省略非关键代码和异常检查
String remoteAddress = NettyUtils.getRemoteAddress(channel);
if (message instanceof ChunkFetchSuccess) {
ChunkFetchSuccess resp = (ChunkFetchSuccess) message;
ChunkReceivedCallback listener = outstandingFetches.get(resp.streamChunkId);
outstandingFetches.remove(resp.streamChunkId);
listener.onSuccess(resp.streamChunkId.chunkIndex, resp.body());
} else if (message instanceof ChunkFetchFailure) {
ChunkFetchFailure resp = (ChunkFetchFailure) message;
ChunkReceivedCallback listener = outstandingFetches.get(resp.streamChunkId);
outstandingFetches.remove(resp.streamChunkId);
listener.onFailure(resp.streamChunkId.chunkIndex, new ChunkFetchFailureException(
"Failure while fetching " + resp.streamChunkId + ": " + resp.errorString));
} else if (message instanceof RpcResponse) {
RpcResponse resp = (RpcResponse) message;
RpcResponseCallback listener = outstandingRpcs.get(resp.requestId);
outstandingRpcs.remove(resp.requestId);
listener.onSuccess(resp.body().nioByteBuffer());
} else if (message instanceof RpcFailure) {
RpcFailure resp = (RpcFailure) message;
RpcResponseCallback listener = outstandingRpcs.get(resp.requestId);
outstandingRpcs.remove(resp.requestId);
listener.onFailure(new RuntimeException(resp.errorString));
} else if (message instanceof StreamResponse) {
StreamResponse resp = (StreamResponse) message;
StreamCallback callback = streamCallbacks.poll();
StreamInterceptor interceptor = new StreamInterceptor(this, resp.streamId, resp.byteCount, callback);
TransportFrameDecoder frameDecoder = (TransportFrameDecoder)channel.pipeline().get(TransportFrameDecoder.HANDLER_NAME);
frameDecoder.setInterceptor(interceptor);
streamActive = true;
} else if (message instanceof StreamFailure) {
StreamFailure resp = (StreamFailure) message;
StreamCallback callback = streamCallbacks.poll();
callback.onFailure(resp.streamId, new RuntimeException(resp.error));
}
}
可见TransportResponseHandler.handler方法将所有的处理逻辑都写在一起了,我们以RpcResponse为例来看一下处理逻辑。还记得我们在之前介绍过的Rpc消息中的Request Id字段,在客户端发送RpcRequest消息的时候,会将回调监听器注册到TransportResponseHandler的outstandingRpcs这个map中,而注册的key就是Request Id。在客户端接收到来自服务端的RpcResponse消息后,就会根据消息中的Request Id在outstandingRpcs中找到之前注册的回调监听器,并调用监听器的onSuccess方法,来处理RpcResponse消息。
spark network-common的更多相关文章
- Spark1.6之后为何使用Netty通信框架替代Akka
解决方案: 一直以来,基于Akka实现的RPC通信框架是Spark引以为豪的主要特性,也是与Hadoop等分布式计算框架对比过程中一大亮点. 但是时代和技术都在演化,从Spark1.3.1版本开始,为 ...
- 搭建Spark的单机版集群
一.创建用户 # useradd spark # passwd spark 二.下载软件 JDK,Scala,SBT,Maven 版本信息如下: JDK jdk-7u79-linux-x64.gz S ...
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- Spark单机版集群
一.创建用户 # useradd spark # passwd spark 二.下载软件 JDK,Scala,SBT,Maven 版本信息如下: JDK jdk-7u79-linux-x64.gz S ...
- 基于Spark Streaming + Canal + Kafka对Mysql增量数据实时进行监测分析
Spark Streaming可以用于实时流项目的开发,实时流项目的数据源除了可以来源于日志.文件.网络端口等,常常也有这种需求,那就是实时分析处理MySQL中的增量数据.面对这种需求当然我们可以通过 ...
- Spark记录-实例和运行在Yarn
#运行实例 #./bin/run-example SparkPi 10 #./bin/spark-shell --master local[2] #./bin/pyspark --master l ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- spark完全分布式集群搭建
最近学习Spark,因此想把相关内容记录下来,方便他人参考,也方便自己回忆吧 spark开发环境的介绍资料很多,大同小异,很多不能一次配置成功,我以自己的实际操作过程为准,详细记录下来. 1.基本运行 ...
- spark on yarn,client模式时,执行spark-submit命令后命令行日志和YARN AM日志
[root@linux-node1 bin]# ./spark-submit \> --class com.kou.List2Hive \> --master yarn \> --d ...
- spark on yarn,cluster模式时,执行spark-submit命令后命令行日志和YARN AM日志
[root@linux-node1 bin]# ./spark-submit \> --class com.kou.List2Hive \> --master yarn \> --d ...
随机推荐
- Windows10显示桌面我的电脑等图标
1.桌面右键,选择最后一项:个性化 2. 选择:主题 --> 桌面图标设置 3. 将需要显示的图标勾上就可以啦.
- caffe(7) solver及其配置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 # caffe train --solver=*_slover ...
- vsftp迁移记录笔记
由于之前的服务器用的window下的ftp安全性和稳定性都不好,所以我们才把ftp迁移到linux环境下 vsftp概述: vsftpd 它可以运行在多平台系统上面,是一个完全免费的.开放源代码的f ...
- mesg---设置当前终端的写权限
mesg命令用于设置当前终端的写权限,即是否让其他用户向本终端发信息.将mesg设置y时,其他用户可利用write命令将信息直接显示在您的屏幕上. 语法 mesg(参数) 参数 y/n:y表示运行向当 ...
- Hadoop2 伪分布式部署
一.简单介绍 二.安装部署 三.执行hadoop样例并測试部署环境 四.注意的地方 一.简单介绍 Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop的框架最核心的设计就是: ...
- 线程池系列三:ThreadPoolExecutor讲解
三.一个用队列处理线程池例子 package demo; import java.util.Queue; import java.util.concurrent.ArrayBlockingQueue; ...
- 巧用FPGA中资源
随着FPGA的广泛应用,所含的资源也越来越丰富,从基本的逻辑单元.DSP资源和RAM块,甚至CPU硬核都能集成在一块芯片中.在做FPGA设计时,如果针对FPGA中资源进行HDL代码编写,对设计的资源利 ...
- IIS Modules Overview
Introduction The IIS 7 and above Web server feature set is componentized into more than thirty indep ...
- 23.IDEA 运行junit单元测试方法
转自:https://blog.csdn.net/weixin_42231507/article/details/80714716 配置Run,增加Junit 最终配置如下:
- nginx大量TIME_WAIT的解决办法--转
原文地址:http://liuyieyer.iteye.com/blog/2214722?utm_source=tuicool&utm_medium=referral 由于网站使用nginx做 ...