Elasticsearch ML
Elastic公司在收购了Prelert半年之后,终于在Elasticsearch 5中推出了Machine Learning功能。Prelert本身就擅长做时序性数据的异常检测,从这点上讲也比较契合elasticsearch的数据特征。在做了一段时间的PoC之后,发现这个功能的最大作用就是troubleshooting过程中帮助定位日志的时间和空间,提高日志搜索的目的性,最终还是服务于elasticsearch。只不过这个功能需要额外的license,不然只有一个月的试用期,略显不爽。
还是先说是Perlert,Perlert做异常检测的基本原理在其CTO Stephen Dodson的文章中有详细介绍:《Anomaly Detection in Application Performance Monitoring Data》。通读全文,发现核心算法基于概率统计的假设检验,针对时间序列的time window(Elasticseaerch中叫bucket span)学习出P-value,用于甄别异常。
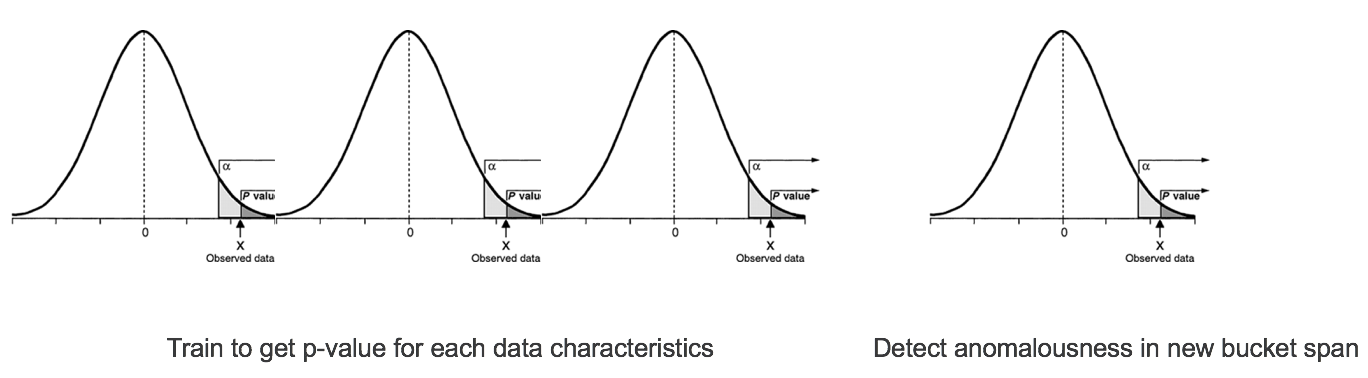
大致原理如上图,当然在实现中有对非正态分布数据的处理以及对P-value计算的优化。
了解了原理,回到Elasticsearch Machine Learning,虽然感觉没有用到什么Machine Learnig的算法,但是确实针对时序性的运维数据分析,非常实用。
笔者的PoC基于Elasticstack 5.5.2,在kibana上目前支持创建三种类型的job:
single metrics job:只针对index的某一个field的数据分析。
multi metrics job:可以对index的多个field进行数据分析。并不是多个field在一起分析,而是每个field的数据单独分析。
advance job:像multi metrics job一样可以支持多个field数据的分析,同时在一个field数据的分析过程中,加上别的field的影响因素。
一些有用的操作:
single job的创建过程中,对数值型的数据提供了一些aggreate方法,用于对要分析的数据预处理:

multi job支持split data操作,即对某个field的value进行partition。比如分析http_response_time的数据,可以按照field:http_response_status_code的value(200,404,500)分别进对应行分析,这对于某些情况下,提高异常检测的精准度非常有意义。
multi job还支持设定key field(influencer),在找到异常点后,可以显示该点的key field的值对这个异常的贡献有多大。这个功能对应上文所说的帮助精确定位日志查询。比如常设clientId, nodeArea等具有明确意义的field为key filed,可以帮助troubleshooting。
Advance job具有multi job的所有功能,同时又增强了detector功能,除了by_partition,还支持by_field, over_field等数据范围划分的操作。
本来,选取bucket span是创建job的过程中最难把握的环节,但在5.5之后,elastic提供了auto estimate bucket span的功能,在一定程度上解决了这方面的问题。
Frequency:bucket span时间内进行异常检测的间隔,防止bucket span设置的太大,异常检测出来的时效性过低。
Example:
1. 数据准备:进入elasticsearch的数据未必能直接做learning,很多有价值的数据存在raw data里面。可以通过logstash的grok方法把需要进行分析的属性提取出来,以key-value的形式存入elasticsearch.
2.创建job,比如创建一个advance job。
选择index=>add new detector & add influencer => start job.
在add new detector的时候需要注意选择是over field和partition field的区别,over field是基于存在某属性的所有bucket span进行detector,有点儿聚类的感觉。 Partition field是按照某个属性的值进行划分partition,在所属partition范围内进行detector。
3. 结果查询。
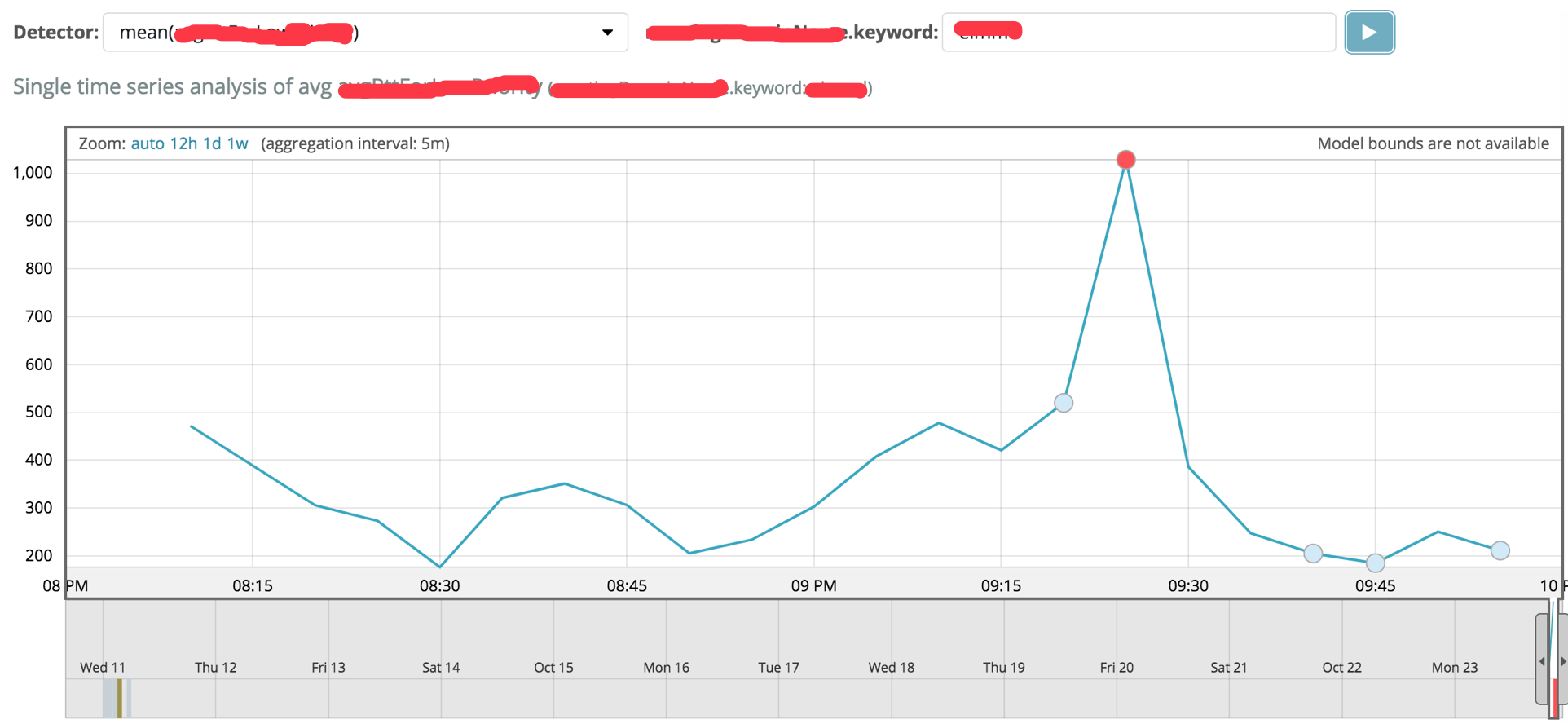
可以看到single metrics views里面检测出来的异常点, 可以按照influencer进行再次的过滤,使得influencer的在图上更近突出。通过点击可以查看异常的的具体信息。
可以通过Anomaly Explorer窗口通过view by influencer来观察最有可能出异常的influencer值。
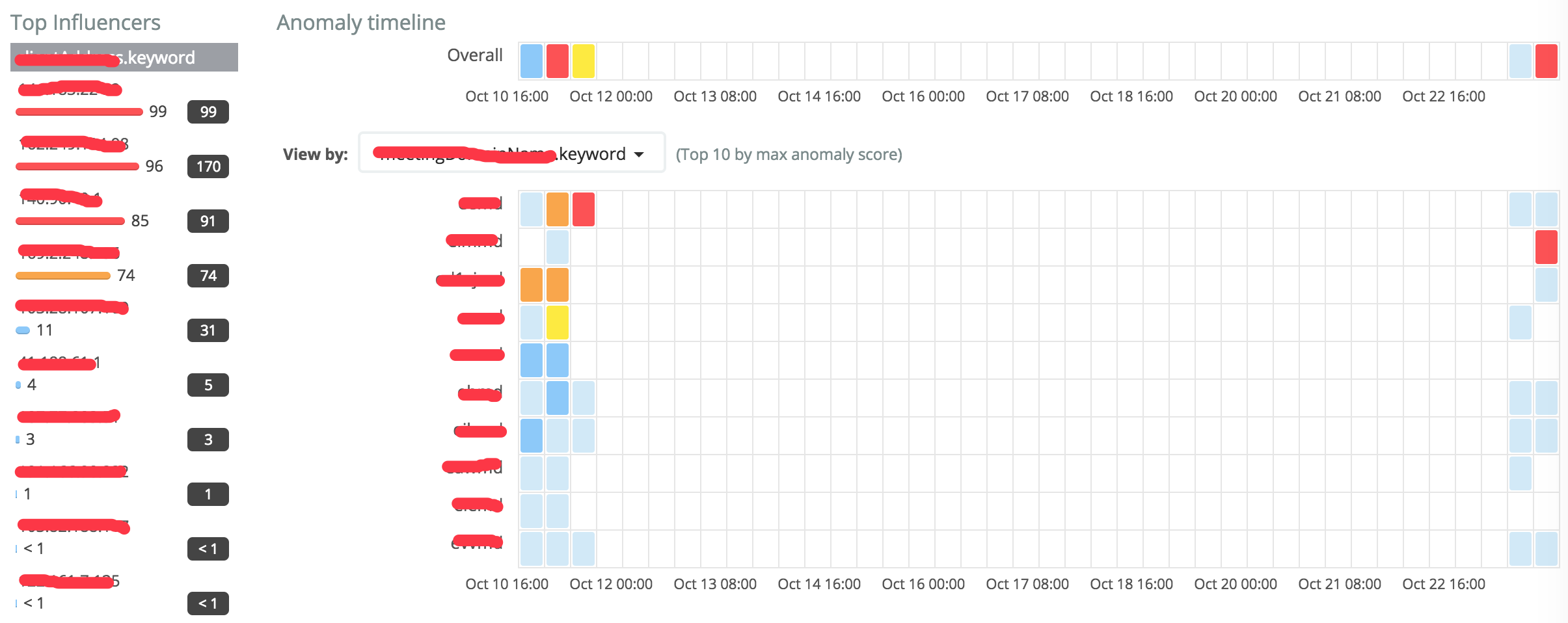
总之,Elasticsearch的Machine Learning主要还是为了配合search功能使用的,帮助更好的进行日志查询。
Elasticsearch ML的更多相关文章
- ElasticSearch Kibana 和Logstash 安装x-pack记录
前言 最近用到了ELK的集群,想想还是用使用官方的x-pack的monitor功能对其进行监控,这里先上图看看: 环境如下: 操作系统: window 2012 R2 ELK : elasticsea ...
- Java Elasticsearch新手入门教程
概要: 1.使用Eclipse搭建Elasticsearch详情参考下面链接 2.Java Elasticsearch 配置 3.ElasticSearch Java Api(一) -添加数据创建索引 ...
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- ELK部署详解--elasticsearch
#Elasticsearch 是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析.它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编 ...
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- Spark 整合ElasticSearch
Spark 整合ElasticSearch 因为做资料搜索用到了ElasticSearch,最近又了解一下 Spark ML,先来演示一个Spark 读取/写入 ElasticSearch 简单示例. ...
- elasticsearch 的查询 /_nodes/stats 各字段意思
/_nodes/stats 字段意思 “” 1 { 2 "_nodes": {3 "total": 1, "successful" ...
- 利用ML&AI判定未知恶意程序——里面提到ssl恶意加密流检测使用N个payload CNN + 字节分布包长等特征综合判定
利用ML&AI判定未知恶意程序 导语:0x01.前言 在上一篇ML&AI如何在云态势感知产品中落地中介绍了,为什么我们要预测未知恶意程序,传统的安全产品已经无法满足现有的安全态势.那么 ...
- (转载)Centos下Elasticsearch安装详细教程
原文地址:http://www.cnblogs.com/sunny1009/articles/7874251.html Centos下Elasticsearch安装详细教程 1.Elasticsear ...
随机推荐
- 【17.69%】【codeforces 659F】Polycarp and Hay
time limit per test4 seconds memory limit per test512 megabytes inputstandard input outputstandard o ...
- Linux常用 bash
学会Linux常用 bash命令 目录 基本操作1.1. 文件操作1.2. 文本操作1.3. 目录操作1.4. SSH, 系统信息 & 网络操作 基本 Shell 编程2.1. 变量2.2. ...
- C# await 高级用法
原文:C# await 高级用法 本文告诉大家 await 的高级用法,包括底层原理. 昨天看到太子写了一段代码,我开始觉得他修改了编译器,要不然下面的代码怎么可以编译通过 await "林 ...
- HSQL一个简短的引论
前言 在对dao层写測试类的时候,我们须要一个測试数据库,一般我们会是专门建立一个真实的測试数据库,可是有了HSQLDB事情就变得简单了起来. 正题 一.简单介绍: hsql数据库是一款纯Ja ...
- Qt::WindowFlags枚举类型(Qt::Widget是独立窗口和子窗口两用的,Qt::Window会有标题栏)
Qt::Widget : QWidget构造函数的默认值,如新的窗口部件没有父窗口部件,则它是一个独立的窗口,否则就是一个子窗口部件. Qt::Window : 无论是否有父窗口部件,新窗口部件都是一 ...
- Python Numpy基础教程
Python Numpy基础教程 本文是一个关于Python numpy的基础学习教程,其中,Python版本为Python 3.x 什么是Numpy Numpy = Numerical + Pyth ...
- Clojure实现的简单短网址服务(Compojure、Ring、Korma库演示样例)
用clojure写了一个简单的短网址服务(一半抄自<Clojure 编程>).在那基础上增加了数据库,来持久化数据. 功能 用Get方法缩短一个网址: 然后在短网址列表就能够查看了, 接下 ...
- android:layout_gravity和android:gravity属性差异
gravity的中文意思就是"重心",就是表示view横向和纵向的停靠位置 android:gravity:是对view控件本身来说的,是用来设置view本身的文本应该显示在vie ...
- 大约PCA算法学习总结
文章来源:http://blog.csdn.net/xizhibei ============================= PCA,也就是说,PrincipalComponents Analys ...
- WPF版的HideCaret()
原文:WPF版的HideCaret() WPF版的HideCaret() 周银辉 事情是这样的: 一般说来,对于那些拥有句柄的TextBox(RichTextBox同理)控件,比如win32的,Win ...