从SQL Server到MySQL,近百亿数据量迁移实战
从SQL Server到MySQL,近百亿数据量迁移实战
2018-05-29 10:52:48
212
沪江成立于 2001 年,作为较早期的教育学习网站,当时技术选型范围并不大:Java 的版本是 1.2,C# 尚未诞生,MySQL 还没有被 Sun 收购,版本号是 3.23。工程师们选择了当时最合适的微软体系,并在日后的岁月里,逐步从 ASP 过度到 .net,数据库也跟随 SQL Server 进行版本升级。
十几年过去了,技术社区已经发生了天翻地覆的变化。沪江部分业务还基本在 .net 体系上,这给业务持续发展带来了一些限制,在人才招聘、社区生态、架构优化、成本风险方面都面临挑战。集团经过慎重考虑,发起了大规模的去 Windows 化项目。这其中包含两个重点子项目:开发语言从 C# 迁移到 Java,数据库从 SQL Server 迁移到 MySQL。
本文主要向大家介绍,从 SQL Server 迁移到 MySQL 所面临的问题和我们的解决方案。
迁移方案的基本流程
设计迁移方案需要考量以下几个指标:
迁移前后的数据一致性;
业务停机时间;
迁移项目是否对业务代码有侵入;
需要提供额外的功能:表结构重构、字段调整。
经过仔细调研,在平衡复杂性和业务方需求后,迁移方案设计为两种:停机数据迁移和在线数据迁移。如果业务场景允许数小时的停机,那么使用停机迁移方案,复杂度低,数据损失风险低。如果业务场景不允许长时间停机,或者迁移数据量过大,无法在几个小时内迁移完成,那么就需要使用在线迁移方案了。
数据库停机迁移的流程:
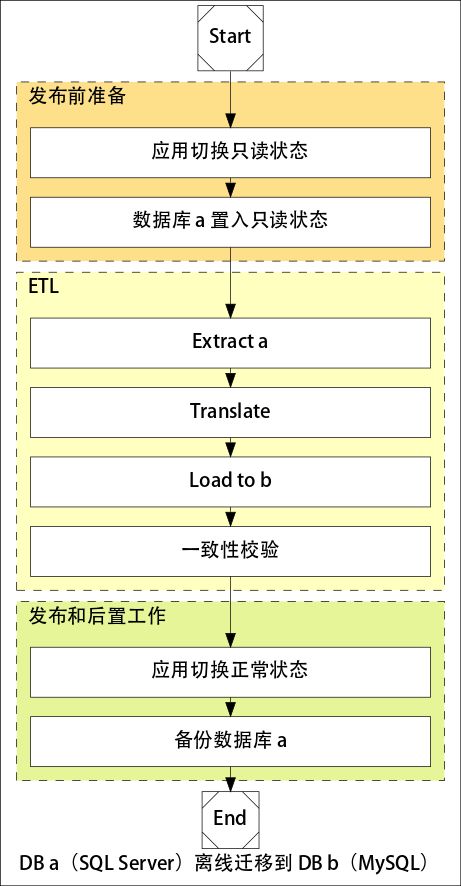
停机迁移逻辑比较简单,使用 ETL(Extract Translate Load) 工具从 Source 写入 Target,然后进行一致性校验,最后确认应用运行 OK,将 Source 表名改掉进行备份。
在线迁移的流程:
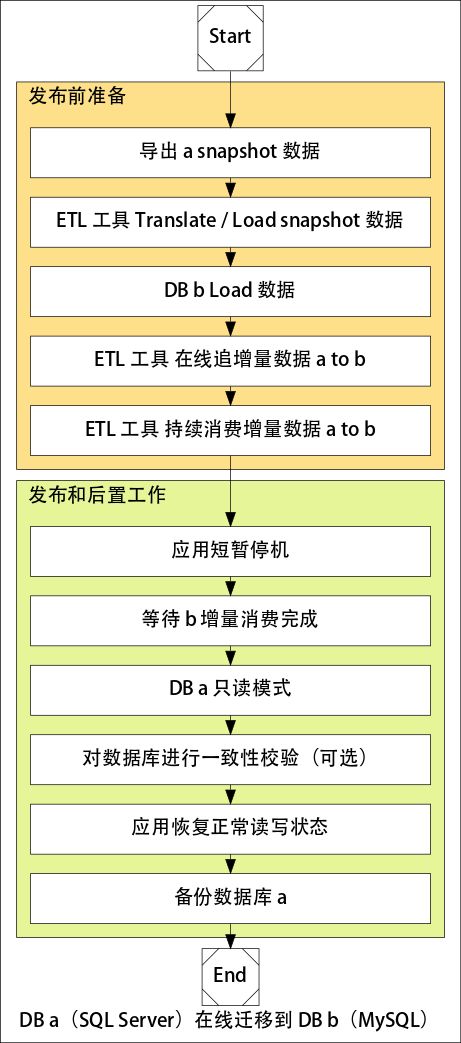
在线迁移的方案稍微复杂一些,流程上有准备全量数据,然后实时同步增量数据, 在数据同步跟上(延迟秒级别)之后,进行短暂停机(Hang 住,确保没有流量),就可以使用新的应用配置,并使用新的数据库。
需要解决的问题
从 SQL Server 迁移到 MySQL,核心是完成异构数据库的迁移。
基于两种数据迁移方案,我们需要解决以下问题:
两个数据库的数据结构是否可以一一对应?出现不一致如何处理?
MySQL 的使用方式和 SQL Server 使用方式是否一致?有哪些地方需要注意?
如何确保迁移前后的数据一致性?
在迁移中,如何支持数据结构调整?
如何保证业务不停情况下,实现在线迁移?
数据迁移后如果发现业务异常需要回滚,如何处理新产生的数据?
为了解决以上问题,我们需要引入一整套解决方案,包含以下部分:
指导文档 A:SQL Server 转换 MySQL 的数据类型对应表;
指导文档 B:MySQL 的使用方式以及注意点;
支持表结构变更,从 SQL Server 到 MySQL 的 ETL 工具;
支持 SQL Server 到 MySQL 的在线 ETL 工具;
一致性校验工具;
一个回滚工具。
让我们一一来解决这些问题。
SQL Server 到 MySQL 指导文档
非常幸运的是,MySQL 官方早就准备了一份如何从其他数据库迁移到 MySQL 的白皮书。MySQL :: Guide to Migrating from Microsoft SQL Server to MySQL 里提供了详尽的从 SQL Server 到 MySQL 的对应方案。 包含了:
SQL Server to MySQL - Datatypes 数据类型对应表;
SQL Server to MySQL - Predicates 逻辑算子对应表;
SQL Server to MySQL - Operators and Date Functions 函数对应表;
T-SQL Conversion Suggestions 存储过程转换建议。
需要额外处理的数据类型:

在实际进行中,还额外遇到了一个用来解决树形结构存储的字段类型 Hierarchyid。这个场景需要额外进行业务调整。
我们在内部做了针对 MySQL 知识的摸底排查工作,并进行了若干次的 MySQL 使用技巧培训,将工程师对 MySQL 的认知拉到一根统一的线。
关于存储过程使用,我们和业务方也达成了一致:所有 SQL Server 存储过程使用业务代码进行重构,不能在 MySQL 中使用存储过程。原因是存储过程增加了业务和 DB 的耦合,会让维护成本变得极高。另外,MySQL 的存储过程功能和性能都较弱,无法大规模使用。
最后我们提供了一个 MySQL 开发规范文档,借数据库迁移的机会,将之前相对混乱的表结构设计做了统一约束(部分有业务绑定的设计,在考虑成本之后没有做调整)。
ETL 工具
ETL 的全称是 Extract Translate Load(读取、转换、载入),数据库迁移最核心过程就是 ETL 过程。如果将 ETL 过程简化,去掉 Translate 过程,就退化为一个简单的数据导入导出工具。我们可以先看一下市面上常见的导入导出工具,了解他们的原理和特性,方便我们选型。
MySQL 同构数据库数据迁移工具:
mysqldump 和 mysqlimport:MySQL 官方提供的 SQL 导入导出工具;
pt-table-sync:Percona 提供的主从同步工具;
XtraBackup:Percona 提供的备份工具。
异构数据库迁移工具:
Database migration and synchronization tools:国外一家提供数据库迁移解决方案的公司;
DataX :阿里巴巴开发的数据库同步工具;
yugong :阿里巴巴开发的数据库迁移工具;
MySQL Workbench :MySQL 提供的 GUI 管理工具,包含数据库迁移功能;
Data Integration - Kettle :国外的一款 GUI ETL 工具;
Ispirer :提供应用程序、数据库异构迁移方案的公司;
DB2DB 数据库转换工具 :国产的一款商业数据库迁移软件;
Navicat Premium :经典的数据库管理工具,带数据迁移功能;
DBImport :个人维护的迁移工具,非常简陋,需要付费。
看上去异构数据库迁移工具和方案很多,但经过我们调研,其中不少是为老派的传统行业服务的。比如 Kettle / Ispirerer,他们关注的特性,不能满足互联网公司对性能、迁移耗时的要求。简单筛选后,以下几款工具进入了我们候选列表(为了做特性对比,加入几个同构数据库迁移工具):
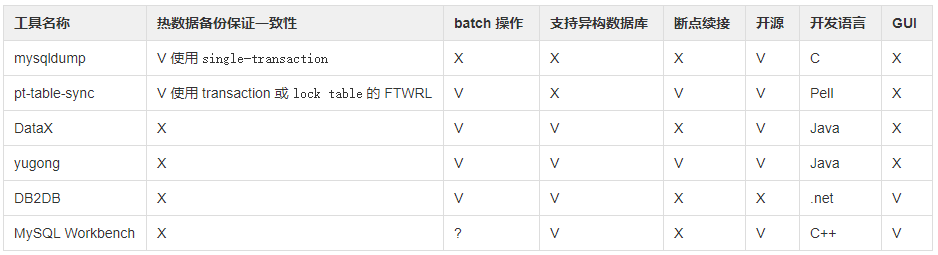
由于异构数据库迁移,真正能够进入我们选型的只有 DataX / yugong / DB2DB / MySQL Workbench。经过综合考虑,我们最终选用了三种方案,DB2DB 提供小数据量、简单模式的停机模式支持,足以应付小数据量的停机迁移,开发工程师可以自助完成。DataX 为大数据量的停机模式提供服务,使用 JSON 进行配置,通过修改查询 SQL,可以完成一部分结构调整工程。yugong 的强大可定制性也为在线迁移提供了基础,我们在官方开源版本的基础之上,增加了以下额外功能:
支持 SQL Server 作为 Source 和 Target;
支持 MySQL 作为 Source;
支持 SQL Server 增量更新;
支持使用 YAML 作为配置格式;
调整 yugong 为 fat jar 模式运行;
支持表名、字段名大小写格式变化,驼峰和下划线自由转换;
支持表名、字段名细粒度自定义;
支持复合主键迁移;
支持迁移过程中完成 Range / Time / Mod / Hash 分表;
支持新增、删除字段。
关于 yugong 的二次开发,我们也积累了一些经验,下文会详细分享。
一致性校验工具
在 ETL 之后,需要有一个流程来确认数据迁移前后是否一致。虽然理论上不会有差异,但是如果中间有程序异常,或者数据库在迁移过程中发生操作,数据就会不一致。
业界有没有类似的工具呢?有,Percona 提供了 pt-table-checksum 这样的工具,这个工具设计从 master 使用 checksum 来和 slave 进行数据对比。这个设计场景是为 MySQL 主从同步设计,显然无法完成从 SQL Server 到 MySQL 的一致性校验。尽管如此,它的一些技术设计特性也值得参考:
一次检查一张表;
每次检查表,将表数据拆分为多个 trunk 进行检查;
使用 REPLACE...SELECT 查询,避免大表查询的长时间带来的不一致性;
每个 trunk 的查询预期时间是 0.5s;
动态调整 trunk 大小,使用指数级增长控制大小;
查询超时时间 1s / 并发量 25;
支持故障后断点恢复;
在数据库内部维护 src / diff,meta 信息;
通过 Master 提供的信息自动连接上 slave;
必须 Schema 结构一致。
我们选择 yugong 作为 ETL 工具的一大原因也是因为它提供了多种模式。支持 CHECK / FULL / INC / AUTO 四种模式。其中 CHECK 模式就是将 yugong 作为数据一致性检查工具使用。yugong 工作原理是通过 JDBC 根据主键范围变化,将数据取出进行批量对比。
这个模式会遇到一点点小问题,如果数据库表没有主键,将无法进行顺序对比。其实不同数据库有自己的逻辑主键,Oracle 有 rowid,SQL Server 有 physloc。这种方案可以解决无主键进行比对的问题。
如何回滚
我们需要考虑一个场景,在数据库迁移成功之后业务已经运行了几个小时,但是遇到了一些 Critical 级别的问题,必须回滚到迁移之前状态。这时候如何保证这段时间内的数据更新到老的数据库里面去?
最朴素的做法是,在业务层面植入 DAO 层的打点,将 SQL 操作记录下来到老数据库进行重放。这种方式虽然直观,但是要侵入业务系统,直接被我们否决了。其实这种方式是 binlog statement based 模式,理论上我们可以直接从 MySQL 的 binlog 里面获取数据变更记录。以 row based 方式重放到 SQL Server。
这时候又涉及到逆向 ETL 过程,因为很可能 Translate 过程中,做了表结构重构。我们的解决方法是,使用 Canal 对 MySQL binlog 进行解析,然后将解析之后的数据作为数据源,将其中的变更重放到 SQL Server。
由于回滚的过程也是 ETL,基于 yugong,我们继续定制了 SQL Server 的写入功能,这个模式类似于在线迁移,只不过方向是从 MySQL 到 SQL Server。
其他实践
我们在迁移之前做了大量压测工作, 并针对每个迁移的 DB 进行线上环境一致的全真演练。我们构建了和生产环境机器配置一样、数据量一样的测试环境,并要求每个系统在上线之前都进行若干次演练。演练之前准备详尽的操作手册和事故处理方案。演练准出的标准是:能够在单次演练中不出任何意外,时间在估计范围内。通过演练我们保证了整个操作时间可控,减少操作时的风险。
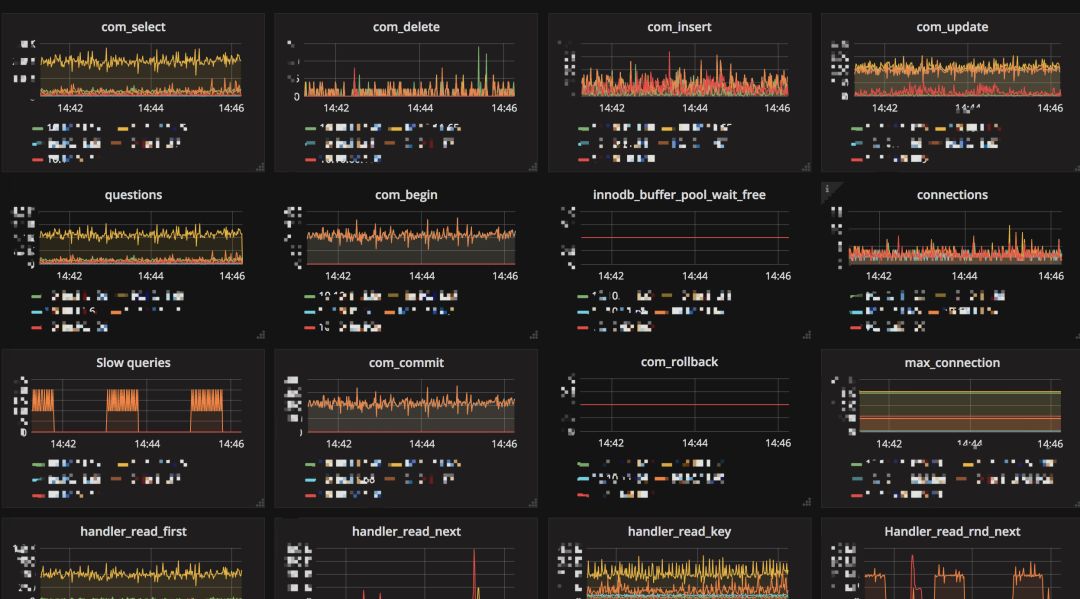
为了让数据库的状态能更为直观地展现出来,我们对 MySQL / SQL Server 添加了细致的 Metrics 监控。在测试和迁移过程中,可以便利地看到数据库的响应情况。

为了方便 DBA 快速 Review SQL。我们提供了一些工具,直接将代码库中的 SQL 拎出来,可以方便地进行 SQL Review。再配合其他 SQL Review 工具,比如 Meituan-Dianping / SQLAdvisor,可以实现一部分自动化,提高 DBA 效率,避免线上出现明显的 Slow SQL。
小结
基于这几种方案我们打了一套组合拳。经过将近一年的使用,进行了 28 个通宵,迁移了 42 个系统,完成了包括用户、订单、支付、电商、学习、社群、内容和工具的迁移。迁移的数据总规模接近百亿,所有迁移项目均一次成功。迁移过程中积累了丰富的实战经验,保障了业务快速向前发展。
在线迁移的原理和流程
上文介绍了从 SQL Server 到 MySQL 异构数据库迁移的基本问题和全量解决方案。全量方案可以满足一部分场景的需求,但是这个方案仍然是有缺陷的:迁移过程中需要停机,停机的时长和数据量相关。对于核心业务来说,停机就意味着损失。比如用户中心的服务,以它的数据量来使用全量方案,会导致迁移过程中停机若干个小时。而一旦用户中心停止服务,几乎所有依赖于这个中央服务的系统都会停摆。
能不能做到无缝地在线迁移呢?系统不需要或者只需要极短暂的停机?作为有追求的技术人,我们一定要想办法解决这些问题。
针对 Oracle 到 MySQL,市面上已经有比较成熟的解决方案——alibaba 的 yugong 项目。在解决 SQL Server 到 MySQL 在线迁移之前,我们先研究一下 yugong 是如何做到 Oracle 的在线迁移。
下图是 yugong 针对 Oracle 到 MySQL 的增量迁移流程:

这其中有四个步骤:
增量数据收集(创建 Oracle 表的增量物化视图);
进行全量复制;
进行增量复制(可并行进行数据校验);
原库停写,切到新库。
Oracle 物化视图(Materialized View)是 Oracle 提供的一个机制。一个物化视图就是主库在某一个时间点上的复制,可以理解为是这个时间点上的 Snapshot。当主库的数据持续更新时,物化视图的更新则是要通过独立的批量更新完成,称之为 refreshes。一批 refreshes 之间的变化,就可以对应到数据库的内容变化情况。物化视图经常用来将主库的数据复制到从库,也常常在数据仓库用来缓存复杂查询。
物化视图有多种配置方式,这里比较关心刷新方式和刷新时间。刷新方式有三种:
Complete Refresh:删除所有数据记录重新生成物化视图;
Fast Refresh:增量刷新;
Force Refresh:根据条件判断使用 Complete Refresh 和 Fast Refres。
刷新机制有两种模式: Refresh-on-commit 和 Refresh-On-Demand。
Oracle 基于物化视图,就可以完成增量数据的获取,从而满足阿里的数据在线迁移。将这个技术问题泛化一下,想做到在线增量迁移需要有哪些特性?
我们得到如下结论(针对源数据库):
增量变化:支持增量获得增量数据库变化;
延迟:获取变化数据这个动作耗时需要尽可能低;
幂等一致性:变化数据的消费应当做到幂等,即不管目标数据库已有数据什么状态,都可以无差别消费。
回到我们面临的问题上来,SQL Server 是否有这个机制满足这三个特性呢?答案是肯定的,SQL Server 官方提供了 CDC 功能。
CDC 的工作原理
什么是 CDC?CDC 全称 Change Data Capture,设计目的就是用来解决增量数据的。它是 SQL Server 2008 新增的特性,在这之前可以使用 SQL Server 2005 中的 after insert / afterdelete / after update Trigger 功能来获得数据变化。
CDC 的工作原理如下:
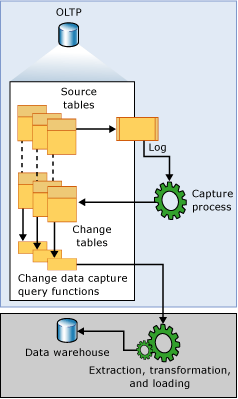
当数据库表发生变化时候,Capture process 会从 transaction log 里面获取数据变化,然后将这些数据记录到 Change Table 里面。有了这些数据,用户可以通过特定的 cdc 存储查询函数将这些变化数据查出来。
CDC 的数据结构和基本使用
CDC 的核心数据就是那些 Change Table 了,这里我们给大家看一下Change Table 长什么样,可以有个直观的认识。
通过以下的函数打开一张表(fruits)的 CDC 功能。
-- enable cdc for dbsys.sp_cdc_enable_db;-- enable by tableEXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'fruits', @role_name = NULL;-- list cdc enabled tableSELECT name, is_cdc_enabled from sys.databases where is_cdc_enabled = 1;
左右滑动可完整查看
至此 CDC 功能已经开启,如果需要查看哪些表开启了 CDC 功能,可以使用一下 SQL:
-- list cdc enabled tableSELECT name, is_cdc_enabled from sys.databases where is_cdc_enabled = 1;
左右滑动可完整查看
开启 CDC 会导致产生一张 Change Table 表 cdc.dbo_fruits_CT,这张表的表结构如何呢?
.schema cdc.dbo_fruits_CTname default nullable type length indexed-------------- ------- -------- ------------ ------ -------__$end_lsn null YES binary 10 NO__$operation null NO int 4 NO__$seqval null NO binary 10 NO__$start_lsn null NO binary 10 YES__$update_mask null YES varbinary 128 NOid null YES int 4 NOname null YES varchar(255) 255 NO
左右滑动可完整查看
这张表的 __ 开头的字段是 CDC 所记录的元数据, id 和 name 是 fruits 表的原始字段。这意味着 CDC 的表结构和原始表结构是一一对应的。
接下来我们做一些业务操作,让数据库的数据发生一些变化,然后查看 CDC 的 Change Table:
-- 1 stepDECLARE @begin_time datetime, @end_time datetime, @begin_lsn binary(10), @end_lsn binary(10);-- 2 stepSET @begin_time = '2017-09-11 14:03:00.000';SET @end_time = '2017-09-11 14:10:00.000';-- 3 stepSELECT @begin_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than', @begin_time);SELECT @end_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', @end_time);-- 4 stepSELECT * FROM cdc.fn_cdc_get_all_changes_dbo_fruits(@begin_lsn, @end_lsn, 'all');
左右滑动可完整查看
这里的操作含义是:
定义存储过程中需要使用的 4 个变量;
begintime / endtime 是 Human Readable 的字符串格式时间;
beginlsn / endlsn 是通过 CDC 函数转化过的 Log Sequence Number,代表数据库变更的唯一操作 ID;
根据 beginlsn / endlsn 查询到 CDC 变化数据。
查询出来的数据如下所示:
__$start_lsn __$end_lsn __$seqval __$operation __$update_mask id name-------------------- ---------- -------------------- ------------ -------------- -- ------0000dede0000019f001a null 0000dede0000019f0018 2 03 1 apple0000dede000001ad0004 null 0000dede000001ad0003 2 03 2 apple20000dede000001ba0003 null 0000dede000001ba0002 3 02 2 apple20000dede000001ba0003 null 0000dede000001ba0002 4 02 2 apple30000dede000001c10003 null 0000dede000001c10002 2 03 3 apple40000dede000001cc0005 null 0000dede000001cc0002 1 03 3 apple4
左右滑动可完整查看
可以看到 Change Table 已经如实的记录了我们操作内容,注意 __$operation 代表了数据库操作:
1 删除
2 插入
3 更新前数据
4 更新后数据
根据查出来的数据,我们可以重现这段时间数据库的操作:
新增了 id 为 1 / 2 的两条数据;
更新了 id 为 2 的数据;
插入了 id 为 3 的数据;
删除了 id 为 3 的数据。
CDC 调优
有了 CDC 这个利器,意味着我们的方向是没有问题的,终于稍稍吁了一口气。但除了了解原理和使用方式,我们还需要深入了解 CDC 的工作机制,对其进行压测、调优,了解其极限和边界,否则一旦线上出现不可控的情况,就会对业务带来巨大损失。
我们先看看 CDC 的工作流程,就可以知道有哪些核心参数可以调整:
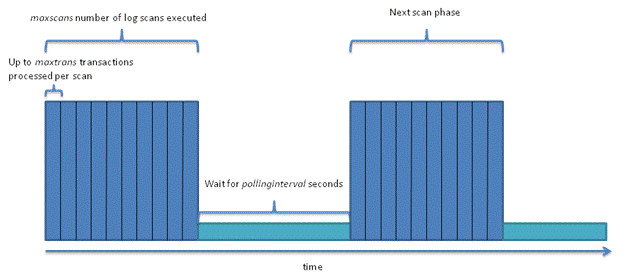
上图是 CDC Job 的工作流程:
蓝色区域是一次 Log 扫描执行的最大扫描次数:maxscans number(maxscans);
蓝色区域同时被最大扫描 transcation 数量控制:maxtrans;
浅蓝色区域是扫描间隔时间,单位是秒:pollinginterval。
这三个参数平衡着 CDC 的服务器资源消耗、吞吐量和延迟,根据具体场景,比如大字段,宽表,BLOB 表,可以调整从而达到满足业务需要。他们的默认值如下:
maxscan 默认值 10;
maxtrans 默认值 500;
pollinginterval 默认值 5 秒。
CDC 压测
掌握了能够调整的核心参数,我们即将对 CDC 进行了多种形式的测试。在压测之前,我们还需要确定关键的健康指标,这些指标有:
内存:buffer-cache-hit / page-life-expectancy / page-split 等;
吞吐:batch-requets / sql-compilations / sql-re-compilations / transactions count;
资源消耗:user-connections / processes-blocked / lock-waits / checkpoint-pages;
操作系统层面:CPU 利用率、磁盘 IO。
出于篇幅考虑,我们无法将所有测试结果贴出来,这里放一个在并发 30 下面插入一百万数据(随机数据)进行展示:

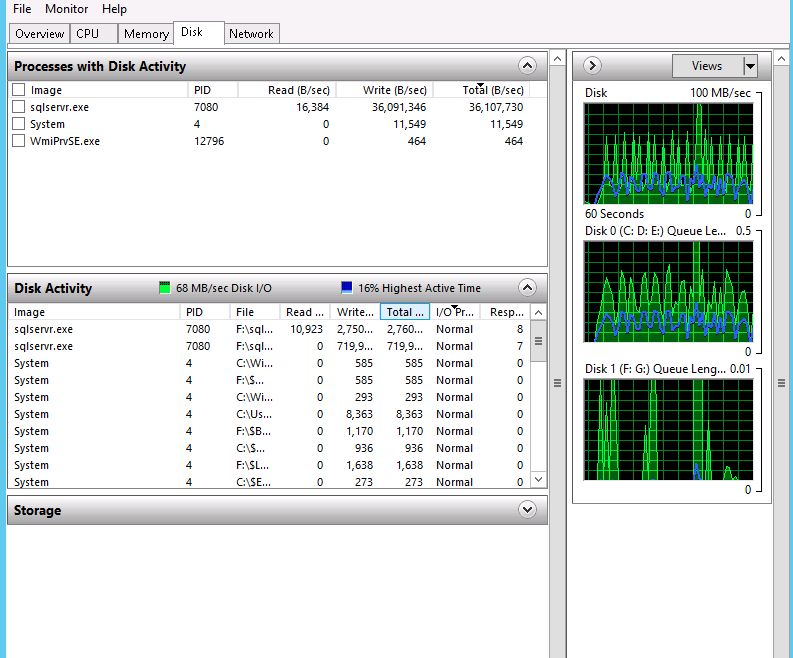
测试结论是,在默认的 CDC 参数下面:
CDC 的开启/关闭过程中会导致若干个 Process Block,大流量请求下面(15k TPS)过程会导致约 20 个左右 Process Block。这个过程中对服务器的 IO / CPU 无明显波动,开启/关闭瞬间会带来 mssql.sql-statistics.sql-compilations 剧烈波动。CDC 开启后,在大流量请求下面对 QPS / Page IO 无明显波动,对服务器的 IO / CPU 也无明显波动, CDC 开启后可以在 16k TPS 下正常工作。
如果对性能不达标,官方有一些简单的优化指南:
调整 maxscan maxtrans pollinginterval;
减少在插入后立刻插入;
避免大批量写操作;
限制需要记录的字段;
尽可能关闭 net changes;
没任务压力时跑 cleanup;
监控 log file 大小和 IO 压力,确保不会写爆磁盘;
要设置 filegroup_name;
开启 spcdcenable_table 之前设置 filegroup。
yugong 的在线迁移机制
截至目前为止,我们已经具备了 CDC 这个工具,但是这仅仅提供了一种可能性,我们还需要一个工具将 CDC 的数据消费出来,并喂到 MySQL 里面去。
还好有 yugong。Yugong 官方提供了 Oracle 到 MySQL 的封装,并且抽象了 Source / Target / SQL Tempalte 等接口,我们只要实现相关接口,就可以完成从 SQL Server 消费数据到 MySQL 了。
这里我们不展开,我后续还会专门写一篇文章讲如何在 yugong 上面进行开发。可以提前剧透一下,我们已经将支持 SQL Server 的 yugong 版本开源了。
如何回滚
数据库迁移这样的项目,我们不仅仅要保证单向从 SQL Server 到 MySQL 的写入,同时要从 MySQL 写入 SQL Server。
这个流程同样考虑增量写入的要素:增量消费、延迟、幂等一致性。
MySQL 的 binlog 可以满足这三个要素,需要注意的是,MySQL binlog 有三种模式,Statement based、Row based 和 Mixed。只有 Row based 才能满足幂等一致性的要求。
确认理论上可行之后,我们一样需要一个工具将 binlog 读取出来,并且将其转化为SQL Server 可以消费的数据格式,然后写入 SQL Server。
我们目光转到 alibaba 的另外一个项目 Canal。Canal 是阿里中间件团队提供的 binlog 增量订阅 & 消费组件。之所以叫组件,是由于 Canal 提供了 Canal-Server 应用和 Canal Client Library,Canal 会模拟成一个 MySQL 实例,作为 Slave 连接到 Master 上面,然后实时将 binlog 读取出来。至于 binlog 读出之后想怎么使用,权看用户如何使用。
我们基于 Canal 设计了一个简单的数据流,在 yugong 中增加了这么几个功能:
SQL Server 的写入功能
消费 Canal 数据源的功能
Canal Server 中的 binlog 只能做一次性消费,内部实现是一个 Queue,为了满足我们可以重复消费数据的能力,我们还额外设计了一个环节,将 Canal 的数据放到 Queue 中,在未来任意时间可以重复消费数据。我们选择了 Redis 作为这个 Queue,数据流如下:

最佳实践
数据库的迁移在去 Windows 中,是最容不得出错的环节。应用是无状态的, 出现问题可以通过回切较快地回滚。但数据库的迁移就需要考虑周到,做好资源准备,发布流程,故障预案处理。
考虑到多个事业部都需要经历这样一个过程,我们项目组将每一个步骤都固化下来,形成了一个最佳实践。我们的迁移步骤如下,供大家参考:
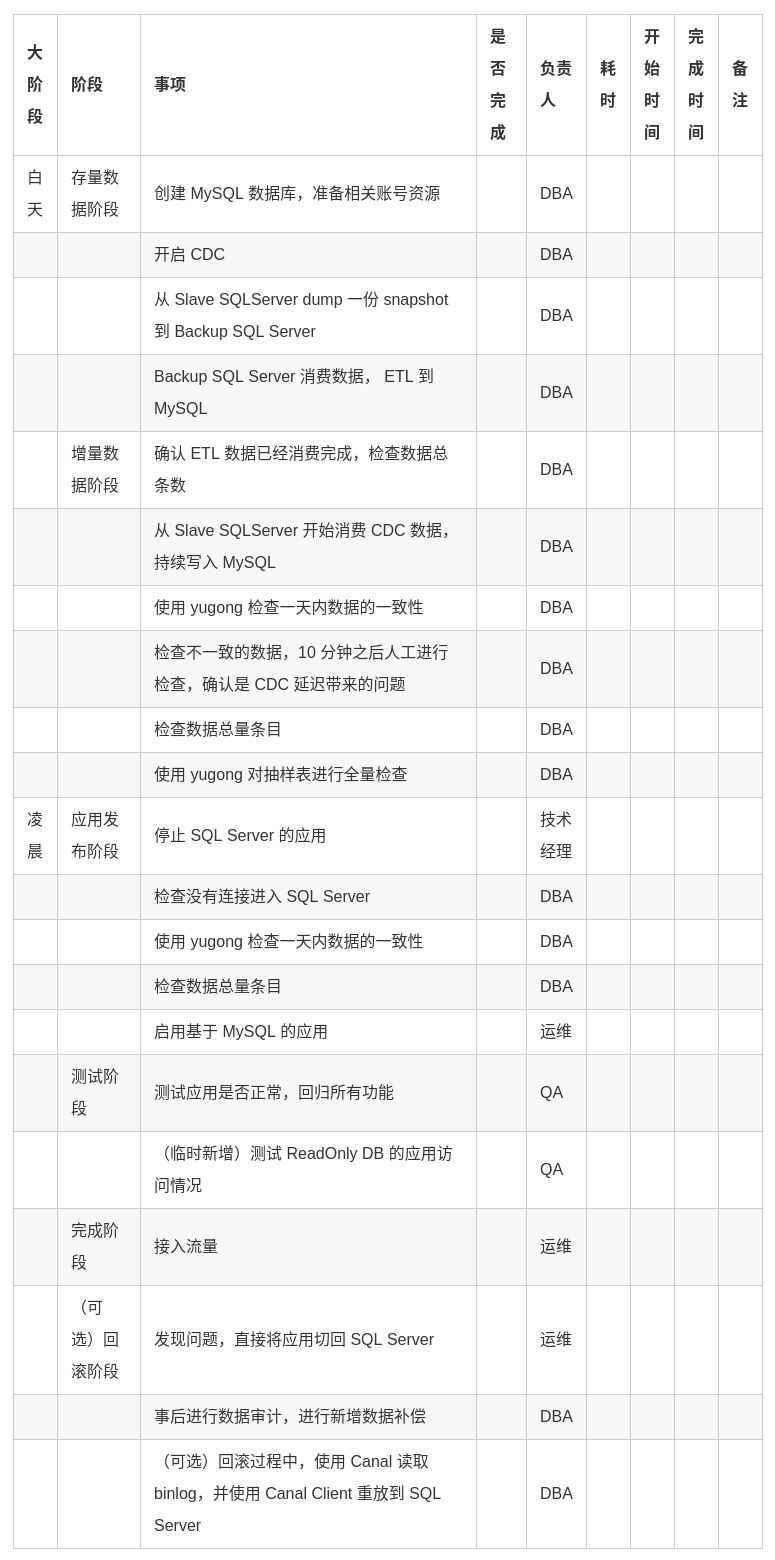
参考链接
MySQL :: Guide to Migrating from Microsoft SQL Server to MySQL: https://www.mysql.com/it/why-mysql/white-papers/guide-to-migrating-from-sql-server-to-mysql/
mysqldump: https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
mysqlimport: https://dev.mysql.com/doc/refman/5.7/en/mysqlimport.html
pt-table-sync: https://www.percona.com/doc/percona-toolkit/LATEST/pt-table-sync.html
XtraBackup: https://www.percona.com/software/mysql-database/percona-xtrabackup
Database migration and synchronization tools: https://www.convert-in.com/
DataX: https://github.com/alibaba/DataX
yugong: https://github.com/alibaba/yugong
MySQL Workbench: https://www.mysql.com/cn/products/workbench/
Data Integration - Kettle: https://community.hds.com/docs/DOC-1009855
Ispirer: https://www.ispirer.cn/products/sql-server-to-mysql-migration
DB2DB 数据库转换工具: http://www.szmesoft.com/DB2DB
Navicat Premium: https://www.navicat.com/en/products/navicat-premium
DBImport: http://www.cnblogs.com/cyq1162/p/5637978.html
Meituan-Dianping/SQLAdvisor: https://github.com/Meituan-Dianping/SQLAdvisor
Materialized View Concepts and Architecture:https://docs.oracle.com/cd/B10500_01/server.920/a96567/repmview.htm
Tuning the Performance of Change Data Capture in SQL Server 2008 | Microsoft Docs:https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/dd266396(v=sql.100
alibaba/yugong: 阿里巴巴去Oracle数据迁移同步工具(全量+增量,目标支持MySQL/DRDS):https://github.com/alibaba/yugong
alibaba/canal: 阿里巴巴mysql数据库binlog的增量订阅&消费组件 。阿里云DRDS( https://www.aliyun.com/product/drds )、阿里巴巴TDDL 二级索引、小表复制powerd by canal.:https://github.com/alibaba/canal)
原文地址:http://dbaplus.cn/news-157-2067-1.html
从SQL Server到MySQL,近百亿数据量迁移实战的更多相关文章
- Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南)
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9941208.html 主讲人:大石头 时间:2018-11-10 晚上20:00 地点:钉钉群(组织代码 ...
- [翻译] C# 8.0 新特性 Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南) 【由浅至深】redis 实现发布订阅的几种方式 .NET Core开发者的福音之玩转Redis的又一傻瓜式神器推荐
[翻译] C# 8.0 新特性 2018-11-13 17:04 by Rwing, 1179 阅读, 24 评论, 收藏, 编辑 原文: Building C# 8.0[译注:原文主标题如此,但内容 ...
- 掌握这些 Redis 技巧,百亿数据量不在话下!
一.Redis封装架构讲解 实际上NewLife.Redis是一个完整的Redis协议功能的实现,但是Redis的核心功能并没有在这里面,而是在NewLife.Core里面. 这里可以打开看一下,Ne ...
- MS Sql Server 查询数据库中所有表数据量
方法一: SELECT a.name,b.rows FROM sysobjects a INNER JOIN sysindexes b ON a.id=b.id ,) AND a.Type='u' O ...
- SQL Server to MySQL
使用 Navicat 导入向导迁移 会遇到以下问题 SQL Server 中的 GUID 类型字段会变成 {guid} 多个外层花括号, 导致程序问题. 部分字段类型长度不大一致, 需要手工调整. . ...
- 数据库 SQL Server 到 MySQL 迁移方法总结
最近接手一起老项目数据库 SQL Server 到 MySQL 的迁移.因此迁移前进行了一些调查和总结.下面是一些 SQL Server 到 MySQL 的迁移方法. 1. 使用 SQLyog 迁移 ...
- Linux + .net core 开发升讯威在线客服系统:同时支持 SQL Server 和 MySQL 的实现方法
前段时间我发表了一系列文章,开始介绍基于 .net core 的在线客服系统开发过程. 有很多朋友一直提出希望能够支持 MySQL 数据库,考虑到已经有朋友在用 SQL Server,我在升级的过程中 ...
- Linux 运行升讯威在线客服系统:同时支持 SQL Server 和 MySQL 的实现方法
前段时间我发表了一系列文章,开始介绍基于 .net core 的在线客服系统开发过程. 有很多朋友一直提出希望能够支持 MySQL 数据库,考虑到已经有朋友在用 SQL Server,我在升级的过程中 ...
- 通过sql server 连接mysql
图文:通过sql server 连接mysql 1.在SQL SERVER服务器上安装MYSQL ODBC驱动; 驱动下载地址:http://dev.mysql.com/downloads/con ...
随机推荐
- 杂项-QXM:CFA(特许金融分析师)
ylbtech-杂项-QXM:CFA(特许金融分析师) 1.返回顶部 1. CFA是“特许金融分析师”(Chartered Financial Analyst)的简称,它是证券投资与管理界的一种职业资 ...
- bzoj4889
http://www.lydsy.com/JudgeOnline/problem.php?id=4889 人傻常数大 bzoj上跑不过 洛谷上能过两到三个点 我写的是树套树啊 怎么跑的比分块还慢 每次 ...
- bzoj1833
http://www.lydsy.com/JudgeOnline/problem.php?id=1833 2.5个小时就花在这上面了... 水到200题了...然并卵,天天做水题有什么前途... #i ...
- PCB 模拟Windows管理员域帐号安装软件
在我们PCB行业中,局域网的电脑一般都会加入域控的,这样可以方便集中管理用户权限,并可以对访问网络资源可以进行权限限制等. 由于加入了域控对帐号权限的管理,这样一来很多人都无权限安装软件,比如:PCB ...
- PCB 钻孔补偿那点事
没有优秀的个人,只有优秀的团队,在团队共同的协作下,PCB CAM自动化[net处理]与[钻孔处理] 第一阶段开发项完成了,,后续工作可以转向PCB规则引擎开发了.这里说说PCB工程钻孔补偿的那点事, ...
- 基于Spark Streaming预测股票走势的例子(二)
上一篇博客中,已经对股票预测的例子做了简单的讲解,下面对其中的几个关键的技术点再作一些总结. 1.updateStateByKey 由于在1.6版本中有一个替代函数,据说效率比较高,所以作者就顺便研究 ...
- 研磨JavaScript系列(三):函数的魔力
JavaScript的代码中就只有function一种形式,function就是函数的类型.在其他的编程语言中可能还存在Procedure或者是method等代码概念,在JavaScript中只有fu ...
- 如何调用com组件中包含IntPtr类型参数的函数
背景 公司的支付平台最近对接了西安移动的支付接口,接口中签名的方法是对方提供了一个com组件,组件中包含了一个签名的方法和一个验签的方法,注册了签名之后,在vs中进行了引用,引用之后,查看组件的定义如 ...
- 百度之星2017初赛B1006 小小粉丝度度熊
思路: 考虑到补签卡一定是连续放置才更优,所以直接根据起始位置枚举.预先处理区间之间的gap的前缀和,在枚举过程中二分即可.复杂度O(nlog(n)). 实现: #include <iostre ...
- python框架之Flask基础篇(四)-------- 其他操作
1.蓝图 要用蓝图管理项目,需要导入的包是:from flask import Buleprint 具体大致分为三步: 1.先在子模块中导入蓝图包,然后再创建蓝图对象. 2.然后将子模块中的视图函数存 ...