Python爬虫: "追新番"网站资源链接爬取
“追新番”网站
追新番网站提供最新的日剧和日影下载地址,更新比较快。
个人比较喜欢看日剧,因此想着通过爬取该网站,做一个资源地图
可以查看网站到底有哪些日剧,并且随时可以下载。
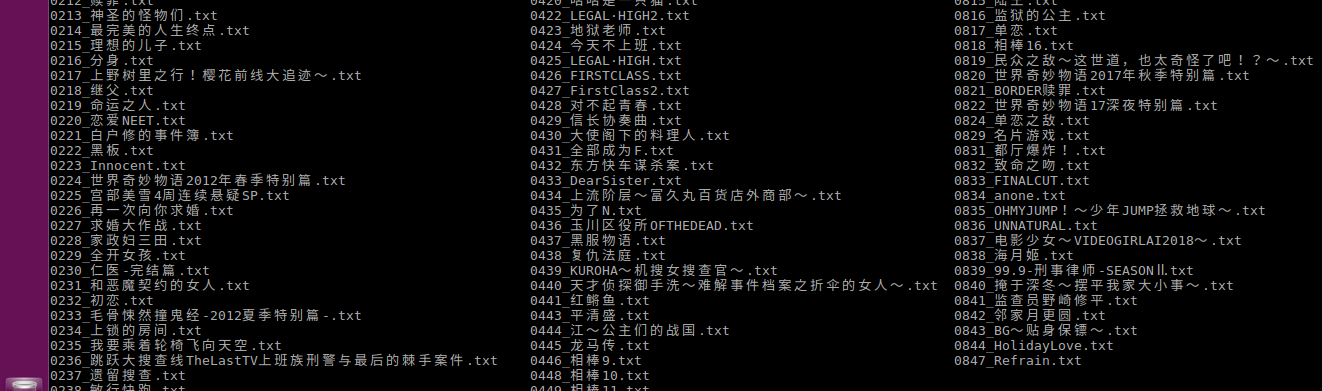
资源地图
爬取的资源地图如下:
在linux系统上通过 ls | grep keywords 可以轻松找到想要的资源(windows直接搜索就行啦)
爬取脚本开发
1. 确定爬取策略
进入多个日剧,可以查看到每个剧的网址都是如下形式:

可以看出,每个日剧网页都对应一个编号。
因此我们可以通过遍历编号来爬取。
2. 获取日剧的名字
打开其中一个日剧的网页,查看标题的源代码如下:
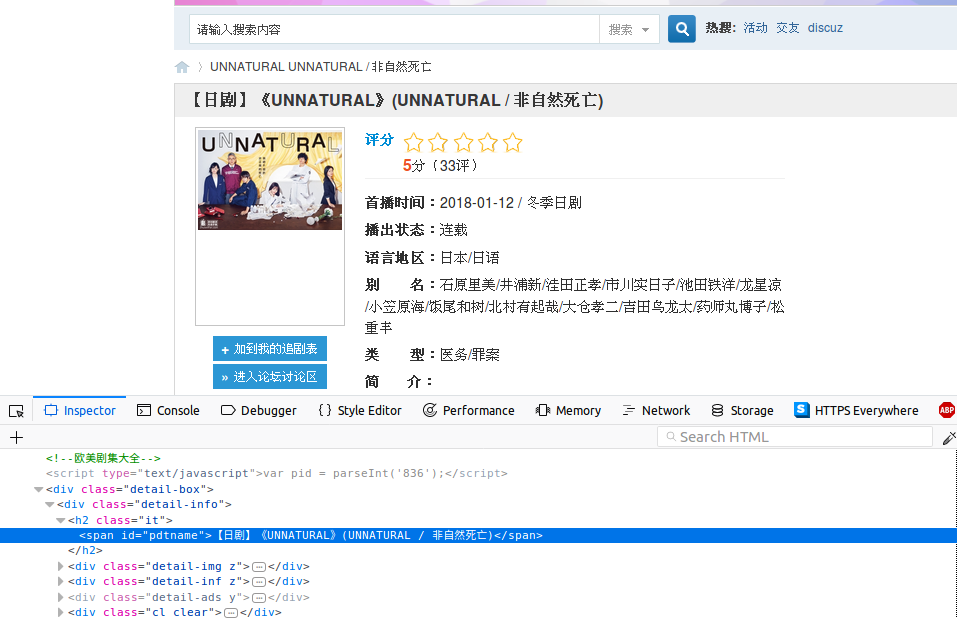
可以看到,标题的标签ID为"pdtname", 我们只要获取该标签的文本即可获取日剧名字
通过beautifulSoup的接口,获取该标签内容(去除了名字中多余东西)
# try get tv name
tag_name = soup.find(id='pdtname')
if None == tag_name:
print('tv_{:0>4d}: not exist.'.format(num))
return None
# remove signs not need
name = tag_name.get_text().replace(' ', '')
try:
name = name.replace(re.search('【.*】', name).group(0), '')
name = name.replace(re.search('\(.*\)', name).group(0), '')
name = name.replace('《', '')
name = name.replace('》', '')
name = name.replace('/', '')
except :
pass
3. 获取资源链接
在每个日剧页面中同时也包含了资源链接的地址,查看源代码如下:
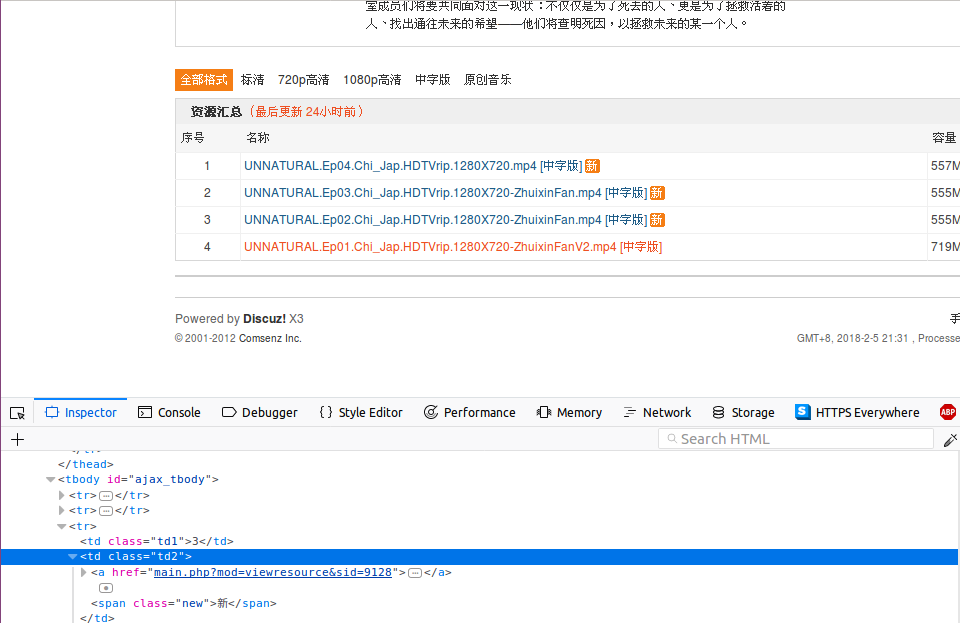
可以看到资源链接使用了一个表块,并且表块的ID为"ajax_tbody"
其中每一集都是表的行元素,每一行又包含了几列来显示资源的各个信息
我们通过遍历表的元素来获取每一集的资源链接
# try get tv resources list
tag_resources = soup.find(id='ajax_tbody')
if None == tag_resources:
print('tv_{:0>4d}: has no resources.'.format(num))
return None
# walk resources
for res in tag_resources.find_all('tr'):
# get link tag
tag_a = res.find('a')
info = res.find_all('td')
print('resource: ', tag_a.get_text())
# get download link
downlink = get_resources_link(session, tag_a.get('href'))
# record resouces
tv.resources.append([tag_a.get_text(), info[2].get_text(), downlink, ''])
delay(1)
4. 获取下载链接
点击其中一个资源,进入下载链接页面,查看源代码如下
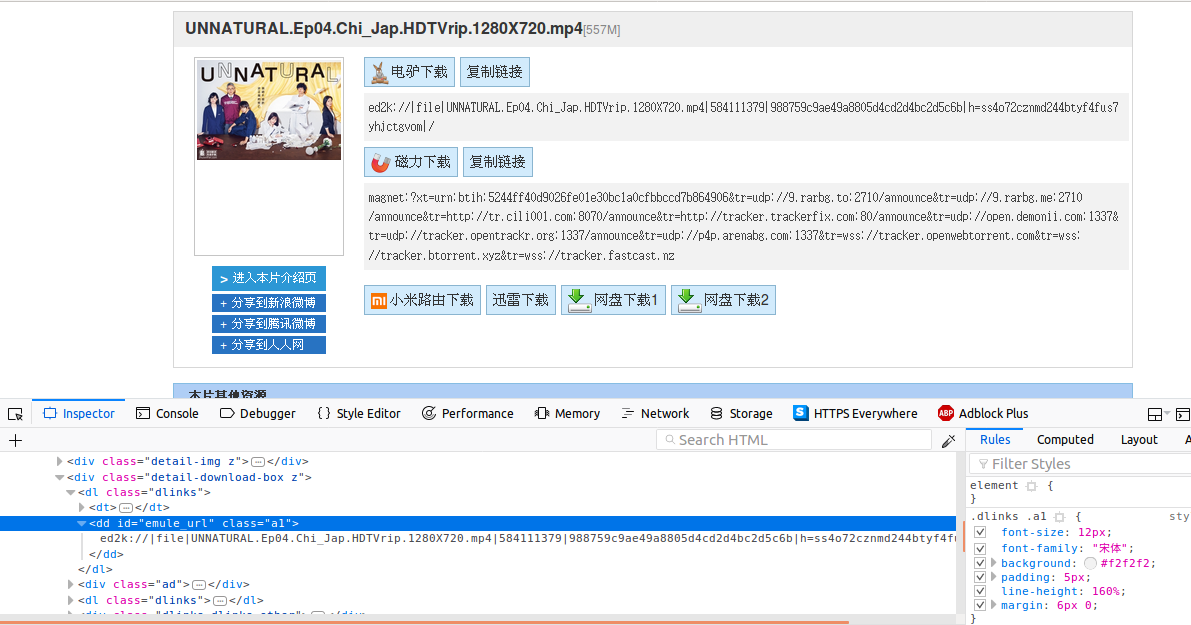
可以看到电驴的下载链接标签ID为"emule_url",因此我们只需要获取该标签的文本就可以了(磁力链接类似)
不过首先我们还需要先获取该下载页面,整体操作代码如下
def get_resources_link(session, url):
''' get tv resources download link '''
global domain
res_url = domain + url
# open resources page
resp = session.get(res_url, timeout = 10)
resp.raise_for_status()
soup = page_decode(resp.content, resp.encoding)
tag_emule = soup.find(id='emule_url')
return tag_emule.get_text() if tag_emule != None else ''
5. 将资源下载链接保存到本地
其中,由于爬取所有日剧的下载链接比较耗时,前面做了判断可以只爬取标题,日后根据序号再爬取下载链接
def save_tv(tv):
''' save tv infomation on disk '''
filename = os.path.join(os.path.abspath(save_dir), '{:0>4d}_{}.txt'.format(tv.num, tv.name))
global only_catalog
if only_catalog == True:
with open(filename, 'a+') as f:
pass
else:
with open(filename, 'w') as f:
for info in tv.resources:
f.write(os.linesep.join(info))
f.write('========' + os.linesep)
以上,就是整个爬取脚本的开发过程。
欢迎关注我的代码仓库: https://gitee.com/github-18274965/Python-Spider
以后还会开发其余网站的爬取脚本。
附录
整体代码:
#!/usr/bin/python3
# -*- coding:utf-8 -*-
import os
import sys
import re
import requests
from bs4 import BeautifulSoup
from time import sleep
# website domain
domain = 'http://www.zhuixinfan.com/'
# spide infomation save directory
save_dir = './tvinfo/'
# only tv catalog
only_catalog = False
class TVInfo:
''' TV infomation class'''
def __init__(self, num, name):
self.num = num
self.name = name
self.resources = []
def delay(seconds):
''' sleep for secondes '''
while seconds > 0:
sleep(1)
seconds = seconds - 1
def page_decode(content, encoding):
''' decode page '''
# lxml may failed, then try html.parser
try:
soup = BeautifulSoup(content, 'lxml', from_encoding=encoding)
except:
soup = BeautifulSoup(content, 'html.parser', from_encoding=encoding)
return soup
def open_home_page(session):
''' open home page first as humain being '''
global domain
home_url = domain + 'main.php'
# open home page
resp = session.get(home_url, timeout = 10)
resp.raise_for_status()
# do nothing
def get_resources_link(session, url):
''' get tv resources download link '''
global domain
res_url = domain + url
# open resources page
resp = session.get(res_url, timeout = 10)
resp.raise_for_status()
soup = page_decode(resp.content, resp.encoding)
tag_emule = soup.find(id='emule_url')
return tag_emule.get_text() if tag_emule != None else ''
def spider_tv(session, num):
''' fetch tv infomaion '''
global domain
tv_url = domain + 'viewtvplay-{}.html'.format(num)
# open tv infomation page
resp = session.get(tv_url, timeout = 10)
resp.raise_for_status()
soup = page_decode(resp.content, resp.encoding)
# try get tv name
tag_name = soup.find(id='pdtname')
if None == tag_name:
print('tv_{:0>4d}: not exist.'.format(num))
return None
# try get tv resources list
tag_resources = soup.find(id='ajax_tbody')
if None == tag_resources:
print('tv_{:0>4d}: has no resources.'.format(num))
return None
# remove signs not need
name = tag_name.get_text().replace(' ', '')
try:
name = name.replace(re.search('【.*】', name).group(0), '')
name = name.replace(re.search('\(.*\)', name).group(0), '')
name = name.replace('《', '')
name = name.replace('》', '')
name = name.replace('/', '')
except :
pass
print('tv_{:0>4d}: {}'.format(num, name))
tv = TVInfo(num, name)
global only_catalog
if only_catalog == True:
return tv
# walk resources
for res in tag_resources.find_all('tr'):
# get link tag
tag_a = res.find('a')
info = res.find_all('td')
print('resource: ', tag_a.get_text())
# get download link
downlink = get_resources_link(session, tag_a.get('href'))
# record resouces
tv.resources.append([tag_a.get_text(), info[2].get_text(), downlink, ''])
delay(1)
return tv
def save_tv(tv):
''' save tv infomation on disk '''
filename = os.path.join(os.path.abspath(save_dir), '{:0>4d}_{}.txt'.format(tv.num, tv.name))
global only_catalog
if only_catalog == True:
with open(filename, 'a+') as f:
pass
else:
with open(filename, 'w') as f:
for info in tv.resources:
f.write(os.linesep.join(info))
f.write('========' + os.linesep)
def main():
start = 1
end = 999
if len(sys.argv) > 1:
start = int(sys.argv[1])
if len(sys.argv) > 2:
end = int(sys.argv[2])
global only_catalog
s = input("Only catalog ?[y/N] ")
if s == 'y' or s == 'Y':
only_catalog = True
# headers: firefox_58 on ubuntu
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:58.0)'
+ ' Gecko/20100101 Firefox/58.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
}
# create spider session
with requests.Session() as s:
try:
s.headers.update(headers)
open_home_page(s)
for num in range(start, end+1):
delay(3)
tv = spider_tv(s, num)
if tv != None:
save_tv(tv)
except Exception as err:
print(err)
exit(-1)
if __name__ == '__main__':
main()
Python爬虫: "追新番"网站资源链接爬取的更多相关文章
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
Python爬虫教程-12-爬虫使用cookie(上) 爬虫关于cookie和session,由于http协议无记忆性,比如说登录淘宝网站的浏览记录,下次打开是不能直接记忆下来的,后来就有了cooki ...
- Python爬虫入门教程: 27270图片爬取
今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位,大家重点学习思路,有啥建议可以在评论的 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python爬虫小白入门(六)爬取披头士乐队历年专辑封面-网易云音乐
一.前言 前文说过我的设计师小伙伴的设计需求,他想做一个披头士乐队历年专辑的瀑布图. 通过搜索,发现网易云音乐上有比较全的历年专辑信息加配图,图片质量还可以,虽然有大有小. 我的例子怎么都是爬取图片? ...
- Python爬虫入门教程 6-100 蜂鸟网图片爬取之一
1. 蜂鸟网图片--简介 国庆假日结束了,新的工作又开始了,今天我们继续爬取一个网站,这个网站为 http://image.fengniao.com/ ,蜂鸟一个摄影大牛聚集的地方,本教程请用来学习, ...
- Python爬虫入门教程 5-100 27270图片爬取
27270图片----获取待爬取页面 今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位, ...
随机推荐
- html5-2 html实体和颜色有哪些
html5-2 html实体和颜色有哪些 一.总结 一句话总结:网站配色用安全色. 1.颜色用什么类型的颜色(安全色)? 直接百度搜 安全色 即可 2.html实体常用哪6个,头尾符号是什么? 头是取 ...
- Android 设置图片 Bitmap任意透明度
两种思路,第一种思路是通过对Bitmap进行操作,将Bitmap的像素值get到一个int[]数组里,因为在android里Bitmap通常是ARGB8888格式,所以最高位就是A通道的值,对齐进行改 ...
- Android 三种方式实现自定义圆形进度条ProgressBar
一.通过动画实现 定义res/anim/loading.xml如下: <?xml version="1.0" encoding="UTF-8"?> ...
- 【codeforces 546E】Soldier and Traveling
time limit per test1 second memory limit per test256 megabytes inputstandard input outputstandard ou ...
- activity-alias详解及应用
activity-alias标签元素众所周知,AndroidManifest是一个xml文件,它包含很多标签元素,如application.activity.receiver等,其中有一个叫做acti ...
- Cocos2d-x 脚本语言Lua基本语法
Cocos2d-x 脚本语言Lua基本语法 前面一篇博客对Lua这门小巧的语言进行了简单的介绍.本篇博客来给大家略微讲一下Lua的语法.不会长篇累牍得把Lua的全部语法都讲一遍,这里通过下面几点来讲L ...
- mysql5.6+主从集的版本号(mysql5.5主机和从机载带后,5.5在设置有一定的差距)
怎么安装mysql数据库.这里不说了,仅仅说它的主从复制,过程例如以下 在进行主从设置之前 首先确保mysql主从server之间的数据库port防火墙互相打开, 尽量确保主从数据库账户一致性(主从切 ...
- Lucene分词报错:”TokenStream contract violation: close() call missing”
Lucene使用IKAnalyzer分词时报错:”TokenStream contract violation: close() call missing” 解决办法是每次完成后必须调用关闭方法. ...
- VS2017 Linux 上.NET Core调试
调试Linux 上.NET Core Visual Studio 2017 通过SSH 调试Linux 上.NET Core 应用程序. 本文环境 开发环境:Win10 x64 Visual Stud ...
- less循环写css工具类
//margin-right=================.mr(100); .mr(@n, @i: 1) when (@i =< @n) { .mr-@{i} { margin-right ...