使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地
上
篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy
目标:
爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地

好了不多说,让我们实现下效果
我们仍用scrapy框架来编写我们的项目:
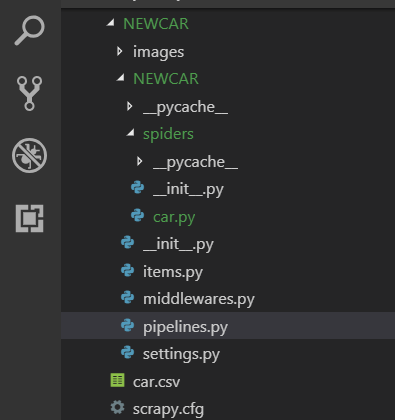
1.首先用命令创建一个爬虫项目(结合上篇博客),并到你的项目里如图所示
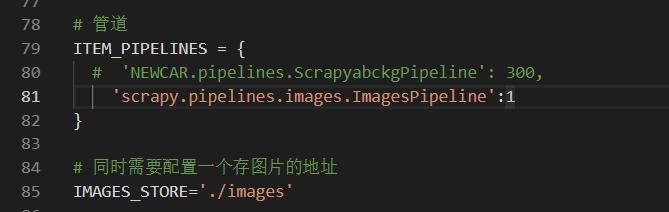
2.先到你的settings.py中配置 ,这里需要注意要 爬图(配置一个爬图管道 ImagesPipeline 为系统中下载图片的管道),
同时还有存图地址(在项目中创建一个为images的文件夹),
存图有多种方式,本人只是列举其中一种,大家可采取不同的方法
3.然后打开你的爬虫文件(即:car.py)开始编写你要爬取的数据,这里需要注意,要将start_urls[] 改为我们要爬取的Url 地址,然后根据xpath爬取图片
(这里代码得自己写,不要复制)

4.爬取的字段要跟 items.py里的一致

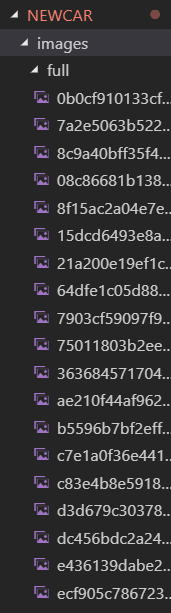
5.在命令行输入启动爬虫命令 scrapy crawl car 运行就能看到爬到图片存放在本地如下
6.最后入库,看你要入那个库,这里可入mysql和mongdb
mysql: 需提前创好库以及表,表中字段
import pymysql
# class NewcarPipeline(object):
# 连接mysql改为你的用户密码以及自己的库
# def __init__(self):
# self.conn = pymysql.connect(host='127.0.0.1',user='root', password='123456', db='zou')
# 建立cursor对象
# self.cursor = self.conn.cursor()
#
# 传值
# def process_item(self, item, spider):
# name = item['name']
# content = item['content']
# price = item['price']
# image = item['image_urls']
#
# insert into 你的表名,括号里面是你的字段要一一对应 # sql = "insert into zou(name,content,price) values(%s,%s,%s)"
# self.cursor.execute(sql, (name,content,price))
# self.conn.commit()
# return item
#关闭爬虫
# def close_spider(self, spider):
# self.conn.close()
mongdb: 不用提前建好库,表
from pymongo import MongoClient
# class NewcarPipeline(object):
# def open_spider(self, spider):
# # 连端口 ip
# self.con = MongoClient(host='127.0.0.1', port=27017)
# # 库
# db = self.con['p1']
# # 授权
# self.con = db.authenticate(name='wumeng', password='123456', source='admin')
# # 集合
# self.coll = db[spider.name] # def process_item(self, item, spider):
# # 添加数据
# self.coll.insert_one(dict(item))
# return item # def close_spider(self):
# # 关闭
# self.con.close()
7.运行 启动爬虫命令 scrapy crawl car 就可在库中看到数据.
至此爬虫项目做完了,这只是一个简单的爬虫,仅供参考,如遇其他方面的问题,可参考本人博客!尽情期待!
使用Scrapy爬取图片入库,并保存在本地的更多相关文章
- scrapy 爬取图片
scrapy 爬取图片 1.scrapy 有下载图片的自带接口,不用我们在去实现 setting.py设置 # 保存log信息的文件名 LOG_LEVEL = "INFO" # L ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
- python实现scrapy爬取图片到本地时的sha1摘要算法文件名
2017-03-29 Scrapy爬图片到本地应该会给图片自动生成sha1摘要算法文件名,我第一次用scrapy也不清楚太多,就在程序里自己写了一段实现这一功能的代码.需import hashlib ...
- 【Python】- scrapy 爬取图片保存到本地、且返回保存路径
https://blog.csdn.net/xueba8/article/details/81843534
- scrapy爬取图片并自定义图片名字
1 前言 Scrapy使用ImagesPipeline类中函数get_media_requests下载到图片后,默认的图片命名为图片下载链接的哈希值,例如:它的下载链接是http://img.iv ...
- python爬取网站视频保存到本地
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Woo_home PS:如有需要Python学习资料的小伙伴可以加点 ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
随机推荐
- SQL server添加链接服务器脚本
---恢复内容开始--- exec sp_addlinkedserver 'ZZSJK','','SQLOLEDB','192.168.10.22' --链接服务器名称 ‘’ ip地址exec s ...
- MongoDB 可视化管理工具
MongoDB 可视化管理工具 (2011年10月-至今) 正文 该项目从2011年10月开始开发,知道现在已经有整整5年了.MongoDB也从一开始的大红大紫到现在趋于平淡.MongoCola这 ...
- 简明Python3教程 7.运算符和表达式
简介 你写的大多数逻辑行都包含表达式.表达式的一个简单例子是2 + 3.一个表达式可分为操作符和操作数两部分. 操作符的功能是执行一项任务:操作符可由一个符号或关键字代表,如+ .操作符需要数据以供执 ...
- c#调api串口通讯
原文:c#调api串口通讯 在调试ICU通信设备的时候,由于串口通信老出现故障,所以就怀疑CF实现的SerialPort类是否有问题,所以最后决定用纯API函数实现串口读写. 先从网上搜索相关代码(关 ...
- 受限玻尔兹曼机(RBM)以及对比散度(CD)
1. RBM 的提出 BM 的缺点: 计算时间漫长,尤其是无约束自由迭代的负向阶段: 对抽样噪音敏感: 流行软件的不支持: 受限玻尔兹曼机(Restricted Boltzmann Machine,简 ...
- cocos2dx 2.2.3 xcode5.0,新mac项目错误
cocos2dx 2.2.3 xcode5.0,新建mac项目报错 Undefined symbols for architecture x86_64: "cocos2d::extens ...
- 怎么给罗技K480 增加Home、End键
最近看张大妈上很多人分享了我的桌面,有感于整天低头码字不利健康,隧鼓捣起自己的电脑桌了. 此处省略N字... 进入正文,我码字用的是罗技的K480蓝牙键盘 码了几行代码,发现没有Home.End键,这 ...
- C#正则表达式的完全匹配、部分匹配及忽略大小写的问题
原文:C#正则表达式的完全匹配.部分匹配及忽略大小写的问题 问题的提出 根据用户给定表达式,里面含有各种数学函数,如求绝对值,三角函数,平方.开方等,分别以类似ABS(表达式),Sin(表达式),AS ...
- Visual C++ 编译器自动假定带 .C 扩展名的文件是 C 文件而不是 C++ 文件,并且拒绝 C++ 语法和关键字(c语言只能在大括号最前面申明变量)
今天在编译OpenGL红宝书附带源码中的light.c文件时遇到一个诡异的问题: 如图light .c,在不做任何修改的情况编译OK.然而只要在某些地方写了可执行代码,则会无法通过编译器编译! (这几 ...
- 【图文教程】de4dot实战字符串解密(演示:hishop微分销系统)
原文:[图文教程]de4dot实战字符串解密(演示:hishop微分销系统) 前些日子,公司需求开发一个微分销系统,于是找来hishop微分销系统想借鉴一下,没想到里面各种加密,就连字符串也都加密了. ...