2019-03-22 Python Scrapy 入门教程 笔记
Python Scrapy 入门教程
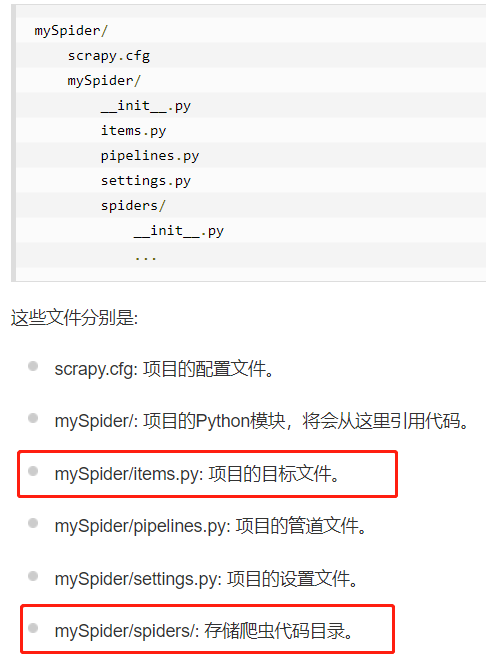
入门教程笔记:
# 创建mySpider
scrapy startproject mySpider # 创建itcast.py
cd C:\Users\theDataDiggers\mySpider\mySpider\spiders
scrapy genspider itcast "itcast.cn" # itcast(itcast.py name)---ItcastSpider(类名)
#该类有3个强制的属性,和一个解析的方法(属性为name allowed_domains start_urls) # 执行itcast.py
scrapy crawl itcast
scrapy crawl itcast -o teachers.csv #在没有学习scrapy时,我们是先请求数据,然后返回数据的
response=request.get(url)
soup=BeautifulSoup(response.text,'lxml')
soup.select() #学习了Scrapy后,发现
def parse(self,response):
#自带response,你可以进行以下操作
response.body()
response.xpath() #顺便还复习了一下类的继承
class ItcastSpider(scrapy.Spider):
class ItcastItem(scrapy.Item):
class MyspiderPipeline(object): #还有引用其它Python文件的类
from mySpider.items import ItcastItem
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
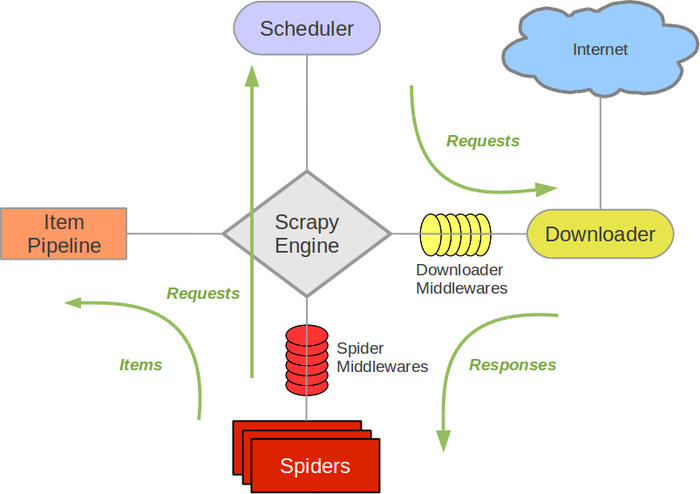
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2019-03-22 Python Scrapy 入门教程 笔记的更多相关文章
- [转]Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider 作者:http://www.cnblogs.com/txw1958/ 出处:http://www.cnblogs.com/txw1958/archi ...
- Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider作者:http://www.cnblogs.com/txw1958/出处:http://www.cnblogs.com/txw1958/archive ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Scrapy入门教程(转)
关键字:scrapy 入门教程 爬虫 Spider作者:http://www.cnblogs.com/txw1958/出处:http://www.cnblogs.com/txw1958/archive ...
- Python基础入门教程
Python基础入门教程 Python基础教程 Python 简介 Python环境搭建 Python 基础语法 Python 变量类型 Python 运算符 Python 条件语句 Python 循 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- 无废话MVC入门教程笔记
自学mvc,看了园子里李林峰写的李林峰写的无废话MVC入门教程笔记,现在有的平时忽略的或是不太清楚的点记下来 1,Html.DropDownList //服务端写法 @{ //下拉列表的值 List& ...
- python之scrapy入门教程
看这篇文章的人,我假设你们都已经学会了python(派森),然后下面的知识都是python的扩展(框架). 在这篇入门教程中,我们假定你已经安装了Scrapy.如果你还没有安装,那么请参考安装指南. ...
- Python爬虫入门教程 37-100 云沃客项目外包网数据爬虫 scrapy
爬前叨叨 2019年开始了,今年计划写一整年的博客呢~,第一篇博客写一下 一个外包网站的爬虫,万一你从这个外包网站弄点外快呢,呵呵哒 数据分析 官方网址为 https://www.clouderwor ...
随机推荐
- vncserve安装与使用
vncserver安装与配置 1.1.Centos安装 yum install tigervnc-server yum groupinstall "X Window System" ...
- redis 参数配置总结
redis.conf 配置项说明如下 1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程 daemonize no 2. 当Redis以守护进程方式运行时, ...
- 基于【SpringBoot】的微服务【Jenkins】自动化部署
最近,也是抽空整理了一些在工作中积累的经验,通过博客记录下来分享给大家,希望能对大家有所帮助: 一.关于自动化部署 关于自动化部署的优点,我就不在这里赘述了:只要想想手工打包.上传.部署.重启的种种, ...
- apache 与 nginx的区别
Nginx 轻量级,采用 C 进行编写,同样的 web 服务,会占用更少的内存及资源 抗并发,nginx 以 epoll and kqueue 作为开发模型,处理请求是异步非阻塞的,负载能力比 apa ...
- BA-siemens-PXC模块调试
PXC24模块写地址步骤: 1.制作一根HMI线: 2.通过HMI+232转USB转接卡连接模块: 3.根据已经做好的系统架构表来配置模块: 写模块之前不要忘了格式化模块,主要命令如下: 视频教程:h ...
- Python Study (06)内存管理GC
对象在内存的存储,我们可以求助于Python的内置函数id().它用于返回对象的身份(identity).其实,这里所谓的身份,就是该对象的内存地址. a = 1 print(id(a)) #1124 ...
- SSM框架——具体整合教程(Spring+SpringMVC+MyBatis)
使用SSM(Spring.SpringMVC和Mybatis)已经有三个多月了.项目在技术上已经没有什么难点了,基于现有的技术就能够实现想要的功能.当然肯定有非常多能够改进的地方.之前没有记录SSM整 ...
- 最全Pycharm教程(38)——Pycharm版本号控制之远程共享
1.主题 介绍怎样通过GitHub共享你的本地Git版本号库 2.准备工作 (1)Pycharm版本号为2.7或者更高 (2)Git以及GitHub可用 (3)有GitHub storage的读写权限 ...
- do while 循环和while循环的差别
do while 循环和while循环的差别 1.do while循环是先运行循环体,然后推断循环条件,假设为真,则运行下一步循环,否则终止循环. while循环是先推断循环条件,假设条件为真则 ...
- awesome-free-software
Free software is distributed under terms that allow users to run the program for any purpose, study ...