大数据hadoop分布式系统
1》hadoop简介:
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行 分布式计算.Hadoop框架中最核心设计就是:HDFS和MapReduce,HDFS提供了海量数据的存储,MapReduce提供了对数据的计算;HDFS:Hadoop Distributed File System,Hadoop的分布式文件系统.大文件被分成默认64M一块的数据块分布存储在集群机器中;MapReduce:Hadoop为每一个input split创建一个task调用 Map计算,在此task中依次处理此split中的一个个记录(record),map会将结果以key--value的形式输出,hadoop负责按key值将map的输出整理后作为Reduce的输 入,Reduce Task的输出为整个job的输出,保存在HDFS上.
Hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker组成.
NameNode中记录了文件是如何被拆分成block以及这些block都存储到了哪些DateNode节点.
NameNode同时保存了文件系统运行的状态信息.
DataNode中存储的是被拆分的blocks.
Secondary NameNode帮助NameNode收集文件系统运行的状态信息.
JobTracker当有任务提交到Hadoop集群的时候负责Job的运行,负责调度多个TaskTracker.
TaskTracker负责某一个map或者reduce任务.
1>hdfs分布式文件系统
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。 但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访 问,非常适合大规模数据集上的应用。
HDFS的优点:
· 1)高容错性
数据自动保存多个副本;
副本丢失后,自动恢复;
· 2)适合批处理
移动计算而非数据;
数据位置暴露给计算框架 ;
· 3)适合大数据处理
GB、TB、甚至PB级数据 ;
百万规模以上的文件数量 ;
10K+节点规模;
· 4)流式文件访问
一次性写入,多次读取;
保证数据一致性 ;
· 5)可构建在廉价机器上
通过多副本提高可靠性 ;
提供了容错和恢复机制;
2>mapreduce大规模数据集的并行运算
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函 数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统 上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的 键值对中的每一个共享相同的键组。
2》安装环境
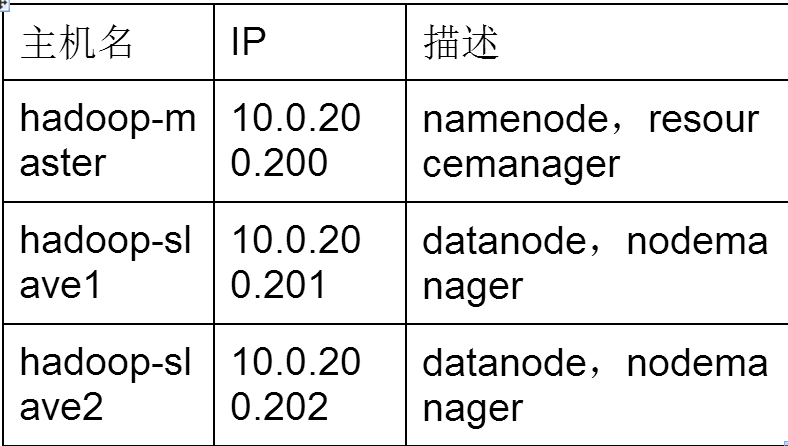
实验需要3台虚拟机,一主两从式,一台主机master当协调节点处理多个slave节点,用户能访问master节点来管理整个hadoop集群
硬件:3台虚拟机
内存:至少512MB
硬盘:至少20G
操作系统:rhel6.4 64位 最小化安装
1>安装openssh
在每台虚拟机上安装openssh,最小化虚拟机默认没有安装,自行配置yum安装openssh。3台虚拟机之间需要相互ssh登录
[root@master ~]#yum install openssh* -y
2>配置主机名和IP
为了方便管理,规范性命名,使用连续网段的IP的静态IP
[root@master ~]#vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop-master
[root@master ~]#vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="System eth0"
HWADDR=B8:97:5A:00:4E:54
IPADDR=10.0.200.200
NETMASK=255.255.0.0
GATEWAY=10.0.2.253
DNS1=114.114.114.114
配置/etc/hosts,把/etc/hosts的IP信息分发到所有主机上
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.200.200 hadoop-master
10.0.200.201 hadoop-slave1
10.0.200.202 hadoop-slave2
3>安装JDK
安装JDK参考百度,本实验使用 jdk1.8.0_31版本,由于hadoop使用java语言编写,所有运行hadoop的机器都要安装jdk安装JDK如下效果:
解压之后在/etc/profile文件中添加如下内容:
export JAVA_HOME=/usr/local/src/jdk1.8.0_31
export HADOOP_INSTALL=/home/hadoop/hadoop.2.6.0
export PATH=$PATH:$HADOOP_INSTALL/bin
更新文件:source /etc/profile
[root@master ~]# java -version
java version "1.8.0_31"
Java(TM) SE Runtime Environment (build 1.8.0_31-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.31-b07, mixed mode)
4>ssh无密登录;
在所有机器上创建hadoop用户,统一密码hadoop,在master上创建hadoop用户的公钥,改名authorized_keys分发到所有机器上,授予600权限
[root@master ~]#useradd hadoop
[root@master ~]#passwd hadoop
[root@master ~]#su - hadoop
[hadoop@master ~]$ssh-keygen -t rsa
[hadoop@master ~]$ cd .ssh
[hadoop@master .ssh]$ mv id_rsa.pub authorized_keys
[hadoop@master .shh]$ chmod 600 authorized_keys
[hadoop@master .ssh]$ scp authorized_keys hadoop-slave1:~/.ssh/
[hadoop@master .ssh]$ scp authorized_keys hadoop-slave2:~/.ssh/
可以看到在master上可以无密登录到slave1上,在后面数百台机器上运行hadoop集群;
注意:在客户端创建的.ssh的权限必须是700,否则不会成功;
5>hadoop安装和配置
在主节点上操作,解压hadoop-2.6.0.tar.gz到hadoop用户家目录,编辑hadoop的配置文件,用hadoop用户操作(编辑文件没有权限时记得用root用户给予 权限);
hadoop官网下载: http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.0/
[hadoop@master ~]# su - hadoop
[hadoop@master ~]$ tar zxvf hadoop-2.6.0.tar.gz
[hadoop@master ~]$ cd hadoop-2.6.0/etc/hadoop/
修改hadoop-env.sh和yarn-env.sh文件的JAVA_HOME来指定JDK的路径
[hadoop@master ~]$ vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_31
[hadoop@master ~]$ vi yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_31
编辑从节点列表文件slaves
[hadoop@master ~]$vi slaves
hadoop-slvae1
hadoop-slave2
编辑core-site.xml,指定主节点的地址和端口
[hadoop@master ~]$ vi core-site.xml
<configuration>
<property>
<name>fs.default.FS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
</configuration>
复制mapred-site.xml.template为mapred-site.xml,指定mapreduce工作方式
[hadoop@master ~]$vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑yarn-site.xml,指定yran的主节点和端口
[hadoop@master ~]$vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master:9001</value>
</property>
</configuration>
将hadoop-2.6.0文件夹分发到其他2台虚拟机上
[hadoop@master ~]$scp -r hadoop-2.6.0 hadoop-slave1:~
[hadoop@master ~]$scp -r hadoop-2.6.0 hadoop-slave2:~
3》运行测试
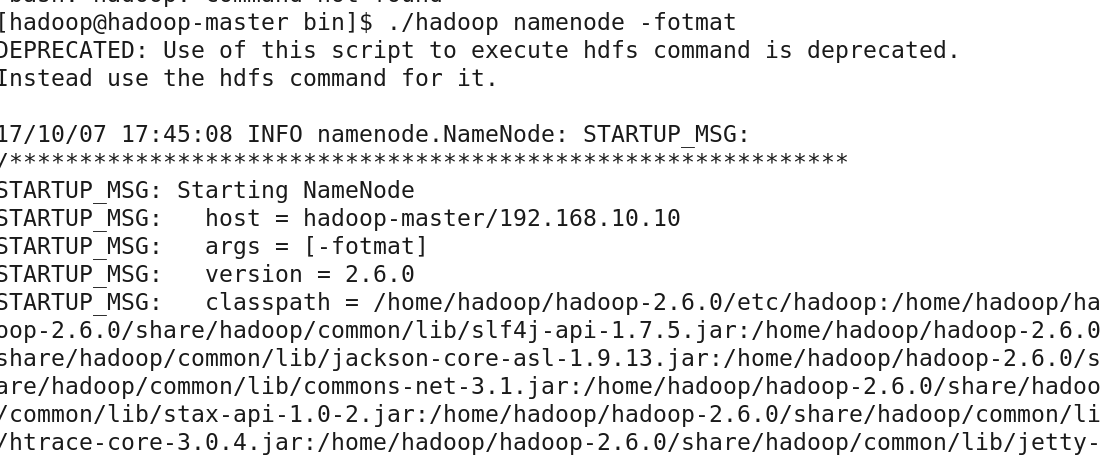
格式化分布式文件系统
[hadoop@master ~]$ hadoop-2.6.0/bin/hadoop namenode -fotmat
[hadoop@master ~]$ hadoop-2.6.0/sbin/start-all.sh
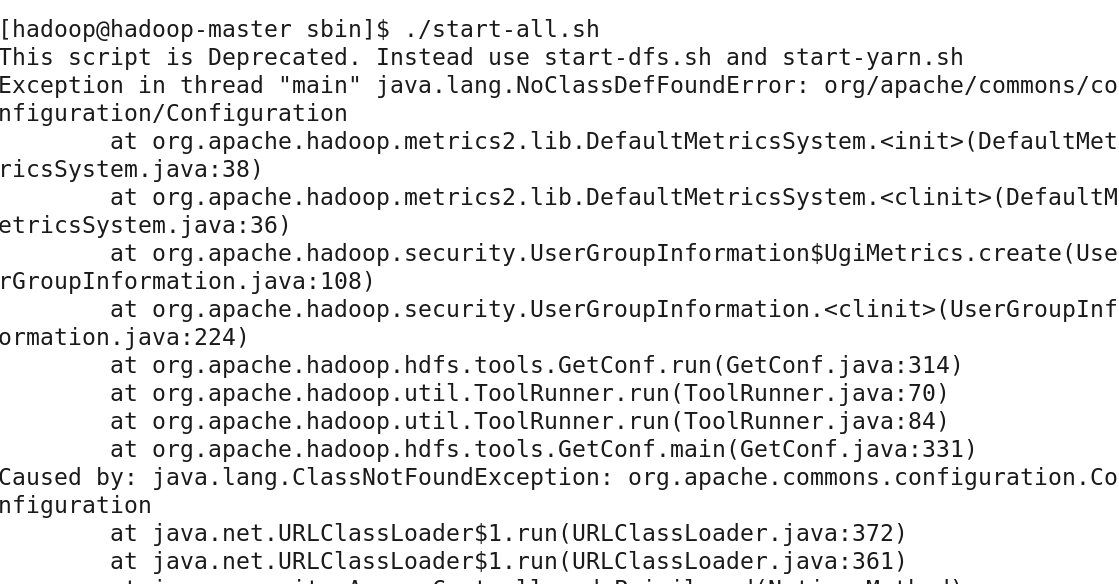
打开浏览器http://10.0.200.200:8088进行查看;
运行mapreduce测试
[hadoop@hadoop-master ~]$ hadoop jar hadoop-2.6.0/share/hadoop/mapreduce/hadoop- mapreduce-examples-2.6.0.jar pi 1 1000000000
Number of Maps = 1
Samples per Map = 1000000000
16/08/20 22:59:09 WARN util.NativeCodeLoader: Unable to load native-hadoop librar y for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Starting Job
16/08/20 22:59:13 INFO client.RMProxy: Connecting to ResourceManager at hadoop-ma ster/192.168.100.50:8032
16/08/20 22:59:15 INFO input.FileInputFormat: Total input paths to process : 1
16/08/20 22:59:16 INFO mapreduce.JobSubmitter: number of splits:1
16/08/20 22:59:17 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_147 1704622640_0001
16/08/20 22:59:19 INFO impl.YarnClientImpl: Submitted application application_147 1704622640_0001
16/08/20 22:59:20 INFO mapreduce.Job: The url to track the job: http://hadoop-mas ter:8088/proxy/application_1471704622640_0001/
16/08/20 22:59:20 INFO mapreduce.Job: Running job: job_1471704622640_0001
16/08/20 22:59:42 INFO mapreduce.Job: Job job_1471704622640_0001 running in uber mode : false
16/08/20 22:59:42 INFO mapreduce.Job: map 0% reduce 0%
16/08/20 23:00:07 INFO mapreduce.Job: map 67% reduce 0%
16/08/20 23:00:46 INFO mapreduce.Job: map 100% reduce 0%
16/08/20 23:01:20 INFO mapreduce.Job: map 100% reduce 100%
16/08/20 23:01:24 INFO mapreduce.Job: Job job_1471704622640_0001 completed successfully
16/08/20 23:01:24 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=28
FILE: Number of bytes written=211893
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=270
HDFS: Number of bytes written=215
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=58521
Total time spent by all reduces in occupied slots (ms)=31620
Total time spent by all map tasks (ms)=58521
Total time spent by all reduce tasks (ms)=31620
Total vcore-seconds taken by all map tasks=58521
Total vcore-seconds taken by all reduce tasks=31620
Total megabyte-seconds taken by all map tasks=59925504
Total megabyte-seconds taken by all reduce tasks=32378880
Map-Reduce Framework
Map input records=1
Map output records=2
Map output bytes=18
Map output materialized bytes=28
Input split bytes=152
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=28
Reduce input records=2
Reduce output records=0
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=519
CPU time spent (ms)=50240
Physical memory (bytes) snapshot=263278592
Virtual memory (bytes) snapshot=4123402240
Total committed heap usage (bytes)=132087808
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=118
File Output Format Counters
Bytes Written=97
Job Finished in 131.664 seconds
Estimated value of Pi is 3.14159272000000000000
大数据hadoop分布式系统的更多相关文章
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 14周事情总结-机器人-大数据hadoop
14周随着考试的进行,其他该准备的事情也在并行的处理着,考试内容这里不赘述了 首先说下,关于机器人大赛的事情,受益颇多,机器人的制作需要机械和电控两方面 昨天参与舵机的测试,遇到的问题:舵机不动 排查 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 大数据hadoop面试题2018年最新版(美团)
还在用着以前的大数据Hadoop面试题去美团面试吗?互联网发展迅速的今天,如果不及时更新自己的技术库那如何才能在众多的竞争者中脱颖而出呢? 奉行着"吃喝玩乐全都有"和"美 ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
随机推荐
- Android APP压力测试实战
环境准备: Android SDK Python 压测实战步骤 1.在手机开发者工具中,将USB调试选上 2.确认手机,电脑成功连接(通过adb devices) 3.安装测试app(adb in ...
- HTTP接口开发专题一(四种常见的 POST 提交数据方式对应的content-type取值)
application/x-www-form-urlencoded 这应该是最常见的 POST 提交数据的方式了.浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 app ...
- UNIX网络编程——socket的keep-alive(转)
第一部分 [需求] 不影响服务器处理的前提下,检测客户端程序是否被强制终了. [现状] 服务器端和客户端的Socket都设定了keepalive属性. 服务器端设定了探测次数等参数,客户端.服务器只是 ...
- LeetCode之数组处理题java
342. Power of Four Total Accepted: 7302 Total Submissions: 21876 Difficulty: Easy Given an integer ( ...
- 使用myeclipse开发java,解决java中继承JFrame类出现The type JFrame is not accessible due to restriction的问题
在java中创建窗体,导入了java中的JFrame类,之后会出现错误: Access restriction: The type QName is not accessible due to res ...
- Docker常用命令和Dockerfile语法
Linux安装Docker: sudo wget -qO- https://get.docker.com/ | sh 安装后只能用root管理,要给其他用户权限,使用命令: sudo usermod ...
- cardBattle游戏启动场景设计
- Spark 性能相关参数配置详解-shuffle篇
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 在Spark的官方文档http://spark.apache.org/docs/latest/configuration. ...
- Nginx源码完全注释(7)ngx_palloc.h/ngx_palloc.c
ngx_palloc.h /* * NGX_MAX_ALLOC_FROM_POOL should be (ngx_pagesize - 1), i.e. 4095 on x86. * On Windo ...
- devcloud 基础架构