Oracle 中运用rollup和cube实现汇总运算
前言、看了很多的随笔博文内容都是关于rollup和cube的用法,发现一个问题,很多都是一样或者转载的,但这都不是重点,重点是,他们写的都太专业化了,直接给一个结论,并没有给出整个推理出这个结论的过程,个人感觉不太适合新手学习并使用这两个函数,下面我这篇随笔个人觉得比较适合新手学习和使用rollup和cube,里面没有什么"纬度"之类的关键字。下面开始!!!!!
一、group by rollup函数解析
1、对于数据的汇总,是数据库经常用到的任务之一,本文讲的就是其中的一种rollup和cube实现数据汇总
2、实例讲解
CREATE TABLE TEST8
(
"ID" NUMBER,
"ORDERID" NUMBER,
"PRODUCTID" NUMBER,
"PRICE" NUMBER(10,2),
"QUANTITY" NUMBER
)
insert into TEST8 (ID, ORDERID, PRODUCTID, PRICE, QUANTITY) values (1, 1, 1, 3, 10);
insert into TEST8 (ID, ORDERID, PRODUCTID, PRICE, QUANTITY) values (2, 1, 2, 4, 5);
insert into TEST8 (ID, ORDERID, PRODUCTID, PRICE, QUANTITY) values (3, 1, 3, 10, 2);
insert into TEST8 (ID, ORDERID, PRODUCTID, PRICE, QUANTITY) values (4, 2, 1, 3, 6);
insert into TEST8 (ID, ORDERID, PRODUCTID, PRICE, QUANTITY) values (5, 2, 2, 4, 6);
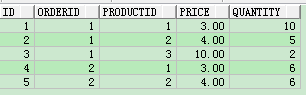
以上是基础数据
i、现在我们有个需求,需要统计出每个订单的产品数量
(1)用group by的解决方法如下
select ORDERID,count(ID) as ordercount from test8 group by ORDERID;

(2)用rollup的解决方案如下:
select ORDERID,count(ID) as ordercount from test8 group by rollup(ORDERID);

总结分析:我们来看使用rollup的结果集相较于group by多出了哪些结果
a、
 发现使用rollup多做了一步select count(*) from test8的操作
发现使用rollup多做了一步select count(*) from test8的操作
ii、需求改变,现在需要求出每个订单下每个产品的订单数
(1)group by解决方法:
select ORDERID,productid,count(ID) as ordercount from test8 group by ORDERID,productid order by orderid;
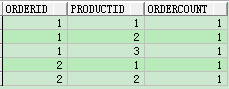
(2)rollup解决方案:
select nvl(TO_CHAR(ORDERID),'null') ORDERID,nvl(TO_CHAR(productid),'null') productid,count(id) as ordercount from test8 group by rollup(ORDERID,productid) order by orderid;
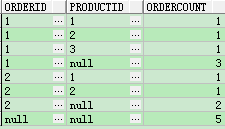
总结分析:和i中的一样分析,我们来看使用rollup的结果集相较于group by多出了哪些结果
a、
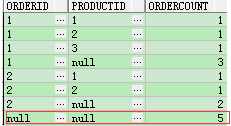 和i一样,使用rollup对整个表进行了count(*)操作
和i一样,使用rollup对整个表进行了count(*)操作
b、
 和i不同的是:通过和group by比较发现使用rollup语句,其多做了一步group by(orderid)的操作
和i不同的是:通过和group by比较发现使用rollup语句,其多做了一步group by(orderid)的操作
iii、需求改变,又变复杂了,我们需要统计出不同价格产品的订单情况,这里问题有点抽象,实在不理解可以看下面的代码:
(1)group by解决方案
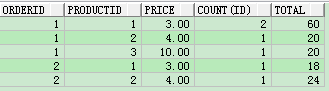
select orderid,productid,price,count(ID),sum(price*quantity) as total from test8
group by orderid,productid,price order by ORDERID
(2)rollup解决方案
select orderid,nvl(TO_CHAR(productid),'null') productid,nvl(TO_CHAR(price),'null') price ,count(ID),sum(price*quantity) as total from test8
group by rollup(orderid,productid,price) order by ORDERID;
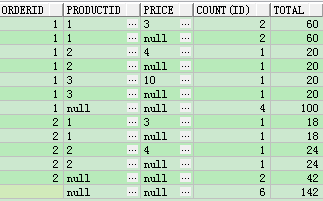
结果分析:观察这次的结果,相比上面的结果多出了什么结果记录
a、
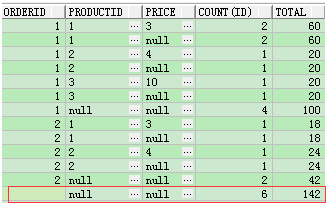 和上面的一样,多出了select count(*) from test8
和上面的一样,多出了select count(*) from test8
b、
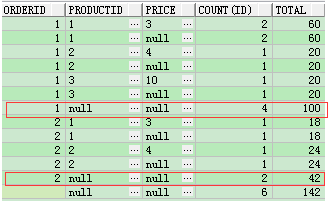 和ii,使用rollup多做了一步group by(orderid)
和ii,使用rollup多做了一步group by(orderid)
c、
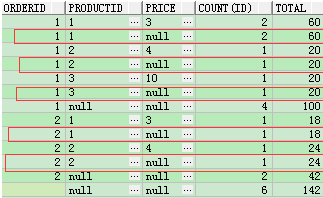 使用rollup,其多做了一步group by(orderid,productid)
使用rollup,其多做了一步group by(orderid,productid)
做到这一步,有了个怎样的猜想,于试之,代码如下:
select null orderid,null productid,null price,count(*),sum(price*quantity) from test8
UNION
select orderid,null productid,null price,count(id),sum(price*quantity) from test8 group by(orderid)
UNION
select orderid,productid,null price,count(id),sum(price*quantity) from test8 group by(orderid,productid)
UNION
select orderid,productid,price,count(id),sum(price*quantity) from test8 group by(orderid,productid,price)

发现和上面使用rollup的语句所实现的结果集一模一样!
3、使用rollup的总结
通过3的实例,大致可以得出以下的结论
select orderId,productID,price,count(*) from Test8 group by rollup(orderId,productID,price)
等同于
select null orderId,null productID,null price,count(*) from Test8
UNION
select orderId,null productID,null price,count(*) from Test8 group by(orderId)
UNION
select orderId,productID,null price,count(*) from Test8 group by(orderId,productID)
UNION
select orderId,productID,price,count(*) from Test8 group by(orderId,productID,price)
优点:减少代码量,目前我只知道这个!!!哈哈
二、group by cube 函数解析 group by cube也是一样的分析方法,分析使用group by cube的数据和group by之间的差别.
i、现在我们有个需求,需要统计出每个订单的产品数量
(1)group by处理
select orderid,count(orderid) ordercount from test8 group by orderid order by orderid
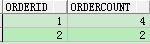
(2)group by cube
select orderid,count(orderid) ordercount from test8 group by cube(orderid) order by orderid;

结果分析:观察这次的结果,相比group by和group by cube间的结果差异
a、
 和group by相比group by cube多了一次select count(*)操作
和group by相比group by cube多了一次select count(*)操作
ii、需求改变,现在需要求出每个订单下每个产品的订单数
(1)group by处理
select orderid,productid,count(orderid) ordercount from test8 group by orderid,productid order by orderid;
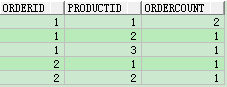
(2)group by cube
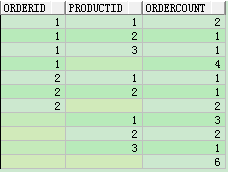
结果分析:观察这次的结果,相比group by和group by cube间的结果差异
a、
 group by cube 多了一次count(*) 操作
group by cube 多了一次count(*) 操作
b、
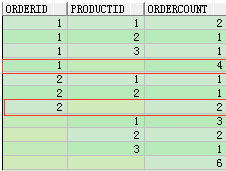 group by cube 多了一次select orderid,count(orderid) from test8 group by orderid
group by cube 多了一次select orderid,count(orderid) from test8 group by orderid
c、
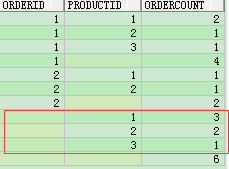 group by cube多了一次select null orderid,productid,count(productid) productcount from test8 group by productid order by productid;
group by cube多了一次select null orderid,productid,count(productid) productcount from test8 group by productid order by productid;
iii、需求改变,又变复杂了,我们需要统计出不同价格产品的订单情况,这里问题有点抽象,实在不理解可以看下面的代码:
select orderid,productid,price,count(orderid) ordercount from test8 group by orderid,productid,price order by orderid;
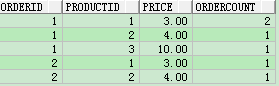
根据上面的总结分析,下面来推测结果
a、推测结果
select orderid,productid,CAST(price AS NUMBER (10, 2)) from
(select null orderid,null productid,null price,count(*) from test8 --1、做一次总定订单数的统计
UNION
select orderid,null productid,null price,count(orderid) from test8 group by orderid --2、按照订单id进行分组统计
UNION
select null orderid,productid,null price,count(orderid) from test8 group by productid --3、按照产品id进行分组统计
UNION
select null orderid,null productid,price,count(orderid) from test8 group by price --4、按照产品价格进行分组统计
UNION
select orderid,productid,null price,count(orderid) from test8 group by orderid,productid --5、按照订单id和产品id进行统计
UNION
select orderid,null productid,price,count(orderid) from test8 group by orderid,price --6、按照订单id和产品价格进行统计
UNION
select null orderid,productid,price,count(orderid) from test8 group by productid,price --7、按照产品id和产品价格进行统计
UNION
select orderid,productid,price,count(orderid) from test8 group by orderid,productid,price) --8、按照订单id和产品id和产品价格进行统计

b、使用group by cube
select orderid,productid,price,count(orderid) ordercount from test8 group by cube(orderid,productid,price) order by orderid;
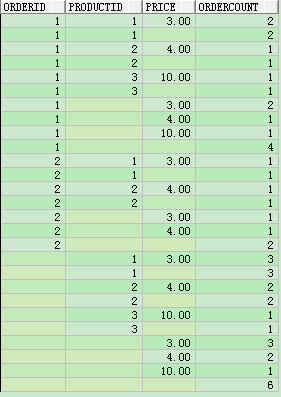
ok、推论正确
三、终极总结
1、关于group by rollup和group by cube这两个方法玩到现在,下面是个人觉得的优点:
a、减少代码量 这点毋庸置疑,完成同样的报表统计使用UNION要多太多代码了,如果报表足够大,使用UNION的话,我反正无法想象得些多少代码
b、适合进行报表分析
暂时就知道这两个!!!智商有限!!!
2、关于这两个方法的不同点
a、
GROUP BY ROLLUP(A,B,C),看这条语句怎么做的group by(a) union group by(a,b) union group by(a,b,c) 也就是a----a,b-------a,b,c
b、
在看GROUP BY CUBE(A,B,C),在看这条语句是怎么做的group by(a) union group by(b) union group by(c) union group by(a,b) union group by(a,c) union group by(b,c)
union group by(a,b,c) 这个很强大,它会对cube()内部的字段的每一种情况都进行group by统计,有点类似选择排序,但是rollup只会进行线性的比较
3、相同点
都会进行select count(*)的操作,也就是全表的数量检索
Oracle 中运用rollup和cube实现汇总运算的更多相关文章
- oracle中分组中的ROLLUP和CUBE选项
在进行多列分组统计时,如果直接使用GROUP BY子句指定分组列,则只能生成基于所有分组列的统计结果.如果在GROUP BY子句中使用ROLLUP语句或CUBE语句,除了生成基于所有指定列的分组统计外 ...
- 解析数仓OLAP函数:ROLLUP、CUBE、GROUPING SETS
摘要:GaussDB(DWS) ROLLUP,CUBE,GROUPING SETS等OLAP函数的原理解析. 本文分享自华为云社区<GaussDB(DWS) OLAP函数浅析>,作者: D ...
- Oracle中有关数学表达式的语法
Oracle中有关数学表达式的语法 三角函数 SIN ASIN SINHCOS ACOS COSHTA ...
- Oracle中group by 的扩展函数rollup、cube、grouping sets
Oracle的group by除了基本使用方法以外,还有3种扩展使用方法,各自是rollup.cube.grouping sets.分别介绍例如以下: 1.rollup 对数据库表emp.如果当中两个 ...
- [SQL]详解CUBE和ROLLUP区别<使用rollup或cube通过交叉列可产生高级汇总结果集>
要使用CUBE,首先要了解GROUP BY. 其实CUBE和ROLLUP区别不太大,只是在基于GROUP BY 子句创建和汇总分组的可能的组合上有一定差别,CUBE将返回的更多的可能组合.如果在GRO ...
- Oracle的rollup、cube、grouping sets函数
转载自:https://blog.csdn.net/huang_xw/article/details/6402396 Oracle的group by除了基本用法以外,还有3种扩展用法,分别是rollu ...
- (2.4)DDL增强功能-数据汇总grouping、rollup、cube
参考:https://www.cnblogs.com/nikyxxx/archive/2012/11/27/2791001.html 1.rollup (1)rollup在group by 子句中使用 ...
- 转:SQLServer中的GROUPING,ROLLUP和CUBE
转自:https://www.cnblogs.com/nikyxxx/archive/2012/11/27/2791001.html 聚集函数:GROUPING 用于汇总数据用的运算符: ROLLUP ...
- Oracle分析函数 — sum, rollup, cube, grouping用法
本文通过例子展示sum, rollup, cube, grouping的用法. //首先建score表 create table score( class nvarchar2(20), course ...
随机推荐
- IOCP~~
下载源代码 原文网址:http://www.codeproject.com/KB/IP/iocp_server_client.aspx 源码使用了高级的完成端口(IOCP)技术,该技术可以有效地服务于 ...
- C++-结构体,联合体,枚举,的区别
结构体: struct NUM { int number; }a; 结构体是声明只是一个模型,没有分配内存空间.当进行定义结构体变量后才分配内存空间 联合体: union data { int a ...
- Linq特取操作之ElementAt,Single,Last,First源码分析
Linq特取操作之ElementAt,Single,Last,First源码分析 一:linq的特取操作 First/FirstOrDefault, Last/LastOrDefault, Eleme ...
- centos 6.5下安装mysql
1.检测系统是否已经安装过mysql或其依赖,若已装过要先将其删除,否则第4步使用yum安装时会报错: 1 # yum list installed | grep mysql 2 mysql-libs ...
- 一些参考网站 - Reference Documentation - Website Address
Reference Documentation - Website Address MSDN Visual Studio 2015官方文档 https://msdn.microsoft.com/zh- ...
- Magicodes.NET框架之路[转]
插件式框架 响应式布局以及前后端对移动设备的支持 便捷的业务代码生成,比如CRUD生成,并且表单支持根据不同数据类型或特性生成相应的展示组件. 从框架到插件包括代码生成模板均走开源路线,便于理解和定制 ...
- HTML5中本地储存概念是什么,什么优点 ,与cookie有什么区别?
html5中的Web Storage 包括了两种存储方式: sessionStorage 和 localStorage. seessionStorage 用于本地存储一个会话(session)中的 ...
- CentOS 下安装 SNMP 服务
CentOS 中搭建 SNMP 服务 0.前言 首先这个服务我不知道有什么用,学习CCNA的也许有了解.所以这里仅仅只是教做题,下面还有一些搜到的配置文件希望会大家有所帮助. 简单网络管理协议(SNM ...
- 关于<ul> 下的 <li> 里面的<a> 标签字体颜色不能控制
1.元展示 <ul class="ul"> <li><a href="#">菜单一</a></li> ...
- P2540 斗地主增强版
P2540斗地主增强版 参考大佬题解 思路:顺子暴力搜,剩下的牌我不会贪心所以用记忆化搜索(或者dp): 注意:双王不能当对,二不算顺子 代码 #include <cstdio> #inc ...