SVM 支持向量机算法介绍
转自:https://zhuanlan.zhihu.com/p/21932911?refer=baina
参考:http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html
http://blog.csdn.net/v_july_v/article/details/7624837
SVM(支持向量机)主要用于分类问题,主要的应用场景有字符识别、面部识别、行人检测、文本分类等领域。
通常SVM用于二元分类问题,对于多元分类通常将其分解为多个二元分类问题,再进行分类。下面我们首先讨论一下二元分类问题。
- 线性可分数据集与线性不可分数据集
对于二元分类问题,如果存在一个分隔超平面能够将不同类别的数据完美的分隔开(即两类数据正好完全落在超平面的两侧),则称其为线性可分。反之,如果不存在这样的超平面,则称其为线性不可分。
所谓超平面,是指能够将n维空间划分为两部分的分隔面,其形如。简单来说,对于二维空间(指数据集有两个特征),对应的超平面就是一条直线;对于三维空间(指数据集拥有三个特征),对应的超平面就是一个平面。可以依次类推到n维空间。
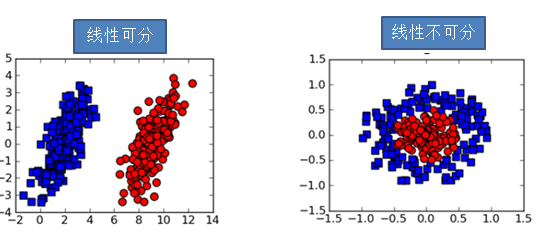
在下面的图片中,左边的图表示二维空间的一个线性可分数据集,右图表示的是二维空间的一个线性不可分数据集。可以直观的看到,对于左图,我们很容易找到这样一条直线将红色点和蓝色点完全分隔开。但是对于右图,我们无法找到这样的直线。
<img src="https://pic3.zhimg.com/b6a3fa2731b6679da247ea1cee2aee02_b.png" data-rawwidth="541" data-rawheight="238" class="origin_image zh-lightbox-thumb" width="541" data-original="https://pic3.zhimg.com/b6a3fa2731b6679da247ea1cee2aee02_r.png">
线性不可分出现的原因:
(1)数据集本身就是线性不可分隔的。上图中右图就是数据集本身线性不可分的情况。这一点没有什么疑问,主要是第二点。
(2)由于数据集中存在噪声,或者人工对数据赋予分类标签出错等情况的原因导致数据集线性不可分。下图展示的就是由于噪声或者分错出错导致线性不可分的情况。
现在,只关注图中的实心点、空心点,以及绿色线段。可以看到实心点和空心点大致分布在绿色线段的两侧,但是在实心点的一侧混杂了两个空心点,在空心点的一侧混杂了一个实心点,即此时绿色直线并没有完全将数据分为两类,即该数据集是线性不可分的。在后面我们会提到通过修正线性可分模型以使得模型能够“包容”数据集中的噪点,以使得SVM能够处理这种类型的线性不可分情况。
<img src="https://pic2.zhimg.com/f7050c1a1445a36d4eb5b6524da5ee8d_b.png" data-rawwidth="436" data-rawheight="386" class="origin_image zh-lightbox-thumb" width="436" data-original="https://pic2.zhimg.com/f7050c1a1445a36d4eb5b6524da5ee8d_r.png">
SVM的目标就是找到这样的一个超平面(对于上图来说,就是找到一条直线),使得不同类别的数据能够落在超平面的两侧。
2. 分类效果好坏
对于线性可分数据集,有时我们可以找到无数多条直线进行分隔,那么如何判断哪一个超平面是最佳的呢?
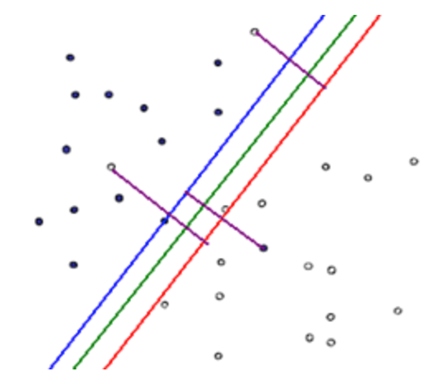
我们先来看一个简单的例子。图中‘x’和‘o’分别代表数据的两种不同类型。可以看到存在图中这样一条直线将数据划分成两类。对于图中的A、B、C三点,虽然它们都被划分在了‘x’类,但是我们A、B、C真正属于‘x’类的把握却是不一样的,直觉上我们认为有足够大的把握A点确实属于'x'类,但是对于C点我们却没有足够的把握,因为图中分隔直线的稍稍偏离,C点有可能就被划分到了直线的另一侧。
<img src="https://pic1.zhimg.com/93695a259ffce22ccf80b925624bbd68_b.png" data-rawwidth="383" data-rawheight="338" class="content_image" width="383">

所以,SVM的目标是使得训练集中的所有数据点都距离分隔平面足够远,更确切地说是,使距离分隔平面最近的点的距离最大。
3. 距离衡量标准
上面提到了SVM的中心思想,即,使距离分隔平面最近的点的距离最大。那么这个距离如何衡量呢?
通常采用几何间隔作为距离度量的方式。简单来说,就是点到超平面的几何距离。
<img src="https://pic3.zhimg.com/1c9a8a6be8fe0037a5e2036c9973bc7a_b.png" data-rawwidth="380" data-rawheight="325" class="content_image" width="380">例如,在上图的二维空间中,点A到分隔超平面(直线)的距离即为线段AB的长度。
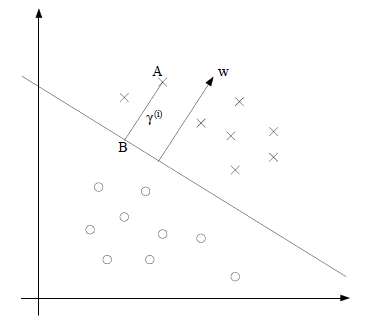
例如,在上图的二维空间中,点A到分隔超平面(直线)的距离即为线段AB的长度。
几何间隔的计算公式如下:
<img src="https://pic2.zhimg.com/a7f7d415274417933da6489eed6eb575_b.png" data-rawwidth="423" data-rawheight="104" class="origin_image zh-lightbox-thumb" width="423" data-original="https://pic2.zhimg.com/a7f7d415274417933da6489eed6eb575_r.png">其中,y表示数据点的类别标签,w和b分别是超平面
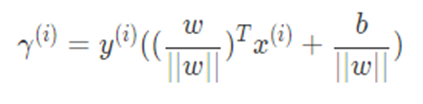
其中,y表示数据点的类别标签,w和b分别是超平面的参数。
注:
(1)在SVM的二元分类中,通常将数据分为“1”类(也称为正类或正例)和“-1”类(也称为负类负例)。通常对于数据点,如果
,则其被分为正类,反之,如果
则被分为负类。那么通过在几何间隔的计算中加入乘法因子y,即可保证只要数据点被分在了正确的类别,那么其几何间隔一定是一个正值。
(2)其中通常也称为函数间隔。当w的模||w||等于1时,函数间隔和几何间隔相等。函数间隔存在的一个问题是:等比放大w和b,函数间隔也会等比增大,而分隔超平面却不会发生变化。几何间隔可以看做是函数间隔的“正规化”。几何间隔不会随着w和b的等比缩放而变化。
4. 支持向量的概念和最优间隔分类器
所谓SVM,即支持向量机,那么到底什么是支持向量呢?
如下图所示,实心点和空心点分别代表数据的两种类别,他们被黄色区域中间的直线分隔成两部分。被蓝色和红色圆圈圈出的点即为支持向量。所谓支持向量,就是指距离分隔超平面最近的点。
<img src="https://pic1.zhimg.com/2b95db3701cf744d226913abfed2fbf0_b.png" data-rawwidth="221" data-rawheight="228" class="content_image" width="221">

那么:要最大化最近的点到分隔超平面的距离,就是最大化支持向量到超平面的距离。
则我们要优化的目标就是:
<img src="https://pic4.zhimg.com/e926f06894088f492fa27315dba31d27_b.png" data-rawwidth="469" data-rawheight="140" class="origin_image zh-lightbox-thumb" width="469" data-original="https://pic4.zhimg.com/e926f06894088f492fa27315dba31d27_r.png">
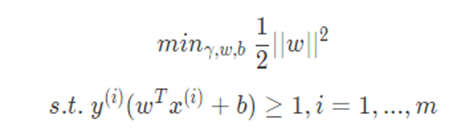
这就是最大间隔分类器的模型,也是SVM的雏形,其可以利用二次优化软件(QP)直接求解。但是计算效率不高(甚至可以说非常低)。
5.通过拉格朗日对偶法优化最优间隔分类器模型
为了提高计算效率以及方便使用核函数,采用拉格朗日对偶,将原始优化模型变成了如下对偶形式:
<img src="https://pic4.zhimg.com/149f83f632103db7341badaeb416d84f_b.png" data-rawwidth="622" data-rawheight="217" class="origin_image zh-lightbox-thumb" width="622" data-original="https://pic4.zhimg.com/149f83f632103db7341badaeb416d84f_r.png">
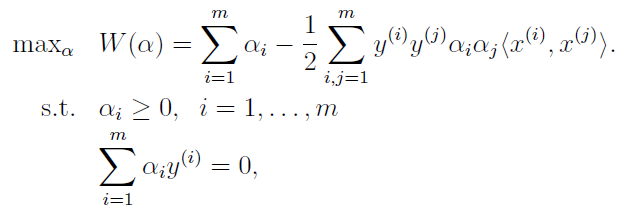
公式的推导非常复杂,这里也不再赘述,详细参考后面给出的资料。
这里只需要知道,alpha仅在支持向量处为非零值。也就是说实际计算时,公式右边有大量零值,非常节省计算量。
6. 模型修正和线性不可分的处理
在第二部分,我们提到:在分类问题中,并不是训练集的分类函数越“完美”越好,因为数据集中本来就存在噪声,且可能存在人工添加分类标签出错的情况。过于“完美”反而会导致过拟合,使得模型失去一般性(可推广性)。
<img src="https://pic2.zhimg.com/f7050c1a1445a36d4eb5b6524da5ee8d_b.png" data-rawwidth="436" data-rawheight="386" class="origin_image zh-lightbox-thumb" width="436" data-original="https://pic2.zhimg.com/f7050c1a1445a36d4eb5b6524da5ee8d_r.png">
为了修正这些分类错误的情况,需要修正模型,加上惩罚系数C。其中表示错误分类的点到正确边界的距离。(即图中的紫色线段长度)
<img src="https://pic4.zhimg.com/3942f21e8988ad7da82fe36a8dcfd847_b.png" data-rawwidth="480" data-rawheight="75" class="origin_image zh-lightbox-thumb" width="480" data-original="https://pic4.zhimg.com/3942f21e8988ad7da82fe36a8dcfd847_r.png">修正后的模型,可以“容忍”模型错误分类的情况,并且通过惩罚系数的约束,使得模型错误分类的情况尽可能合理。
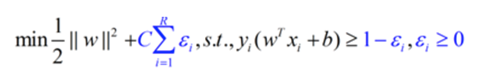
修正后的模型,可以“容忍”模型错误分类的情况,并且通过惩罚系数的约束,使得模型错误分类的情况尽可能合理。
7.核函数
在线性不可分的情况下的另一种处理方式是使用核函数,其基本思想是:将原本的低维特征空间映射到一个更高维的特征空间,从而使得数据集线性可分。
<img src="https://pic4.zhimg.com/177cc99803cbc7fe259dad3b0af2aff3_b.png" data-rawwidth="446" data-rawheight="216" class="origin_image zh-lightbox-thumb" width="446" data-original="https://pic4.zhimg.com/177cc99803cbc7fe259dad3b0af2aff3_r.png">
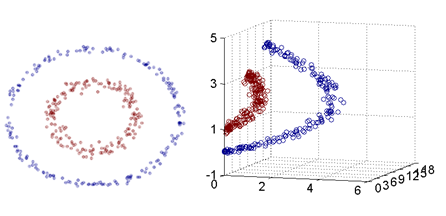
在上面的图中,左侧的图是一个二维特征空间中的线性不可分数据集,其具有两个特征(x1,x2)。
通过特征映射:
<img src="https://pic1.zhimg.com/16e3db5aaeec9d5ab933aafde1dd9f74_b.png" data-rawwidth="280" data-rawheight="225" class="content_image" width="280">我们可以得到右侧的图,其是一个三维特征空间中的线性可分数据集,具有三个特征(z1,z2,z3)。
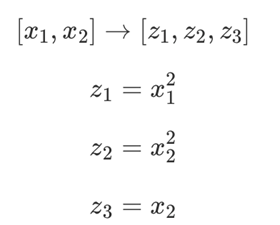
我们可以得到右侧的图,其是一个三维特征空间中的线性可分数据集,具有三个特征(z1,z2,z3)。
即:我们通过特征映射,将一个二维的线性不可分数据集成功映射到了三维空间的线性可分数据集。
关于核函数有一个形象的解释:世界上本来没有两个完全一样的物体,对于所有的两个物体,我们可以通过增加维度来让他们最终有所区别,比如说两本书,从(颜色,内容)两个维度来说,可能是一样的,我们可以加上作者这个维度,是在不行我们还可以加入页码,可以加入 拥有者,可以加入 购买地点,可以加入 笔记内容等等。当维度增加到无限维的时候,一定可以让任意的两个物体可分了。
这与核函数将低维特征映射到高维特征的思想基本类似。
常用的核函数有:
(1)多项式核函数
<img src="https://pic2.zhimg.com/523a6125abc4806416ad62202a186af9_b.png" data-rawwidth="308" data-rawheight="63" class="content_image" width="308">(2)高斯核函数
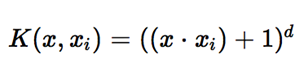
(2)高斯核函数
<img src="https://pic2.zhimg.com/826fa7c2702cdf94442e3855db4c93fd_b.png" data-rawwidth="300" data-rawheight="62" class="content_image" width="300">那么
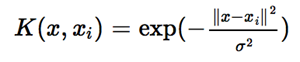
那么如何应用核函数呢?
回顾上面我们构建的模型:
<img src="https://pic1.zhimg.com/b3fdfaf3810a6cef1cd78def816b1b14_b.png" data-rawwidth="359" data-rawheight="186" class="content_image" width="359">注意到公式红色部分,表示两个
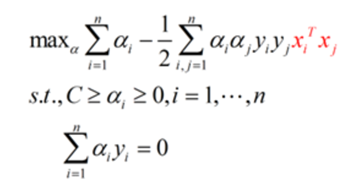
注意到公式红色部分,表示两个和
做内积,要应用核函数,我们只需要将这个部分替换为对应的核函数即可。
<img src="https://pic4.zhimg.com/20ee16aa7169d64047abfd81e024215b_b.png" data-rawwidth="249" data-rawheight="66" class="content_image" width="249">
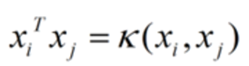
核函数的本质
- 实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(如上文2.2节最开始的那幅图所示,映射到高维空间后,相关特征便被分开了,也就达到了分类的目的);
- 但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的(如上文中19维乃至无穷维的例子)。那咋办呢?
- 此时,核函数就隆重登场了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
8. SMO算法
SMO算法就是为了高效计算上述优化模型而提出的。其是由坐标上升算法衍生而来。
所谓坐标上升算法,就是指:对于含有多个变量的优化问题:每次只调整一个变量,而保证其他变量不变,来对模型进行优化,直到收敛。
举一个最简单的例子,对于如下优化问题:
<img src="https://pic3.zhimg.com/8f76d6cfa231032b81abe4f88390ab26_b.png" data-rawwidth="424" data-rawheight="91" class="origin_image zh-lightbox-thumb" width="424" data-original="https://pic3.zhimg.com/8f76d6cfa231032b81abe4f88390ab26_r.png">
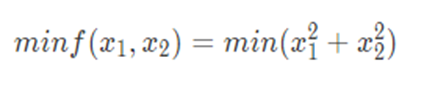
从任意点开始应用坐标上升算法,结果都会收敛到(0,0)。
不妨假设我们选择初始点(5,8),首先我们只调整x1的值,而保证x2的值不变,得到解(0,8);然后我们只调整x2的值,而保证x1的值不变,得到解(0,0);进一步,我们再次只调整x1的值,而保证x2的值不变,发现结果仍然是(0,0),说明收敛,算法结束,最终结果为(0,0)。
SMO的思想类似,由于约束条件 的存在,如果按照坐标上升算法,每次只修改一个
的值,是不可行的(因为
的值完全取决于剩下的m-1个
值)。所以每次至少改变一对a的值。
因而,类似坐标上升,SMO算法每次选择一对可以进行优化的a值进行优化,直到收敛。
支持向量机高斯核调参
在支持向量机(以下简称SVM)的核函数中,高斯核(以下简称RBF)是最常用的,从理论上讲, RBF一定不比线性核函数差,但是在实际应用中,却面临着几个重要的超参数的调优问题。如果调的不好,可能比线性核函数还要差。所以我们实际应用中,能用线性核函数得到较好效果的都会选择线性核函数。如果线性核不好,我们就需要使用RBF,在享受RBF对非线性数据的良好分类效果前,我们需要对主要的超参数进行选取。
如果是SVM分类模型,这两个超参数分别是惩罚系数C C和RBF核函数的系数 γ。当然如果是nu-SVC的话,惩罚系数C 代替为分类错误率上限nu, 由于惩罚系数C 和分类错误率上限nu起的作用等价,因此本文只讨论带惩罚系数C的分类SVM。
惩罚系数C 即我们在之前原理篇里讲到的松弛变量的系数。它在优化函数里主要是平衡支持向量的复杂度和误分类率这两者之间的关系,可以理解为正则化系数。当C 比较大时,我们的损失函数也会越大,这意味着我们不愿意放弃比较远的离群点。这样我们会有更加多的支持向量,也就是说支持向量和超平面的模型也会变得越复杂,也容易过拟合。反之,当C 比较小时,意味我们不想理那些离群点,会选择较少的样本来做支持向量,最终的支持向量和超平面的模型也会简单。scikit-learn中默认值是1。
另一个超参数是RBF核函数的参数 γ。回忆下RBF 核函数  , γ主要定义了单个样本对整个分类超平面的影响,当γ 比较小时,单个样本对整个分类超平面的影响比较大,更容易被选择为支持向量,反之,当 γ比较大时,单个样本对整个分类超平面的影响比较小,不容易被选择为支持向量,或者说整个模型的支持向量也会少。scikit-learn中默认值是
, γ主要定义了单个样本对整个分类超平面的影响,当γ 比较小时,单个样本对整个分类超平面的影响比较大,更容易被选择为支持向量,反之,当 γ比较大时,单个样本对整个分类超平面的影响比较小,不容易被选择为支持向量,或者说整个模型的支持向量也会少。scikit-learn中默认值是 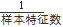 。
。
如果把惩罚系数C 和RBF核函数的系数 γ一起看,当C 比较大, γ比较小时,我们会有更多的支持向量,我们的模型会比较复杂,容易过拟合一些。如果C 比较小 , γ比较大时,模型会变得简单,支持向量的个数会少。
SVM 支持向量机算法介绍的更多相关文章
- SVM 支持向量机算法-实战篇
公号:码农充电站pro 主页:https://codeshellme.github.io 上一篇介绍了 SVM 的原理和一些基本概念,本篇来介绍如何用 SVM 处理实际问题. 1,SVM 的实现 SV ...
- SVM 支持向量机算法-原理篇
公号:码农充电站pro 主页:https://codeshellme.github.io 本篇来介绍SVM 算法,它的英文全称是 Support Vector Machine,中文翻译为支持向量机. ...
- SVM(支持向量机)算法
第一步.初步了解SVM 1.0.什么是支持向量机SVM 要明白什么是SVM,便得从分类说起. 分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器),而支持向 ...
- SVM支持向量机算法
支持向量机(SVM)是另一类的学习系统,其众多的优点使得他成为最流行的算法之一.其不仅有扎实的理论基础,而且在许多应用领域比大多数其他算法更准确. 1.线性支持向量机:可分情况 根据公式(1)< ...
- 跟我学算法-svm支持向量机算法推导
Svm算法又称为支持向量机,是一种有监督的学习分类算法,目的是为了找到两个支持点,用来使得平面到达这两个支持点的距离最近. 通俗的说:找到一条直线,使得离该线最近的点与该线的距离最远. 我使用手写进行 ...
- 深入浅出理解SVM支持向量机算法
支持向量机是Vapnik等人于1995年首先提出的,它是基于VC维理论和结构风险最小化原则的学习机器.它在解决小样本.非线性和高维模式识别问题中表现出许多特有的优势,并在一定程度上克服了" ...
- [分类算法] :SVM支持向量机
Support vector machines 支持向量机,简称SVM 分类算法的目的是学会一个分类函数或者分类模型(分类器),能够把数据库中的数据项映射给定类别中的某一个,从而可以预测未知类别. S ...
- 机器学习--支持向量机 (SVM)算法的原理及优缺点
一.支持向量机 (SVM)算法的原理 支持向量机(Support Vector Machine,常简称为SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析.它是将向量映射到一个更高维的 ...
- SVM较全面介绍,干货!(转载)
很不错的一篇介绍SVM的文章,证明通俗易懂! 转自:https://blog.csdn.net/v_july_v/article/details/7624837 前言 动笔写这个支持向量机(suppo ...
随机推荐
- 牛客小白月赛13 E(图、矩阵幂)
AC通道 如果建立第一天某点到某点有几条路的矩阵,做k次矩阵乘就是第k天某点到某点有几条路.统计即可. #include <bits/stdc++.h> using namespace s ...
- linux下svn服务器搭建步骤
安装步骤如下: 1.yum install subversion 2.输入rpm -ql subversion查看安装位置,如下图: 我们知道svn在bin目录下生成了几个二进制文件. 输入 sv ...
- python入门之递归
表现形式: 函数体里包含执行本身 def f1(): r = f1() f1() 实例: 斐波那契数 (a1+a2=a3 a2+a3=a4 a3+a4=a5 ......) def f1( ...
- 084 Largest Rectangle in Histogram 柱状图中最大的矩形
给出 n 个非负整数来表示柱状图的各个柱子的高度,每个柱子紧挨彼此,且宽度为 1 .您的函数要能够求出该柱状图中,能勾勒出来的最大矩形的面积. 详见:https://leetcode.com/prob ...
- 使用Yeoman 创建 angular应用
一.安装 Yeoman npm install yo -g 如果提示当前nodejs版本和npm版本太低,先升级下再安装yeoman. 安装成功后,默认只有webapp和Mocha这两个生成器. 二. ...
- 解决win64无法添加curl扩展的问题
网上试了很多方法都无效,最后直接用phpstudy集成安装包中对应版本的php_curl.dll替换即可
- 关于js对象中的,属性的增删改查问题
删除主要是delet方法: 1 function Person(){}; 2 var person = new Person(); 3 person.name = 'yy'; 4 person.gen ...
- Jenkins默认工作空间及更改默认工作空间
1.Jenkins安装到tomcat 需2步: ①官网下载Jenkins(一个war包) ②安装 所谓安装,也有两种形式: 一是在安装了jdk的情况下直接运行:java -jar jenkins.wa ...
- MyEclipse中把java项目打包——含有第三方jar包【转】
也适用于eclipse导出jar. 在将项目打包为jar包时一直出现“ClassNotDefFound”错误,百度了很多解决办法都没有解决.最终找到一个很好的解决办法. 1.打包步骤 (1)右键单击j ...
- 立个单调栈flag
http://bestcoder.hdu.edu.cn/contests/contest_chineseproblem.php?cid=687&pid=1002