强化学习_PolicyGradient(策略梯度)_代码解析
使用策略梯度解决离散action space问题。
一、导入包,定义hyper parameter
import gym
import tensorflow as tf
import numpy as np
from collections import deque #################hyper parameters################、
#discount factor
GAMMA = 0.95
LEARNING_RATE = 0.01
二、PolicyGradient Agent的构造函数:
1、设置问题的状态空间维度,动作空间维度;
2、序列采样的存储结构;
3、调用创建用于策略函数近似的神经网络的函数,tensorflow的session;初始或神经网络的weights和bias。
def __init__(self, env):
#self.time_step = 0
#state dimension
self.state_dim = env.observation_space.shape[0]
#action dimension
self.action_dim = env.action_space.n
#sample list
self.ep_obs, self.ep_as, self.ep_rs = [],[],[]
#create policy network
self.create_softmax_network() self.session = tf.InteractiveSession()
self.session.run(tf.global_variables_initializer())
三、创建神经网络:
这里使用交叉熵误差函数,使用神经网络计算损失函数的梯度。softmax输出层输出每个动作的概率。
tf.nn.sparse_softmax_cross_entropy_with_logits函数先对 logits 进行 softmax 处理得到归一化的概率,将lables向量进行one-hot处理,然后求logits和labels的交叉熵:
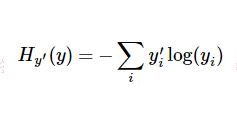
其中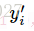
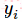
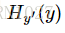
因此,在这里可以得到很好的理解(我自己的理解):当在time-step-i时刻,策略网络输出概率向量若与采样到的time-step-i时刻的动作越相似,那么交叉熵会越小。最小化这个交叉熵误差也就能够使策略网络的决策越接近我们采样的动作。最后用交叉熵乘上对应time-step的reward,就将reward的大小引入损失函数,entropy*reward越大,神经网络调整参数时计算得到的梯度就会越偏向该方向。
def create_softmax_network(self):
W1 = self.weight_variable([self.state_dim, 20])
b1 = self.bias_variable([20])
W2 = self.weight_variable([20, self.action_dim])
b2 = self.bias_variable([self.action_dim]) #input layer
self.state_input = tf.placeholder(tf.float32, [None, self.state_dim])
self.tf_acts = tf.placeholder(tf.int32, [None, ], name='actions_num')
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
#hidden layer
h_layer = tf.nn.relu(tf.matmul(self.state_input,W1) + b1)
#softmax layer
self.softmax_input = tf.matmul(h_layer, W2) + b2
#softmax output
self.all_act_prob = tf.nn.softmax(self.softmax_input, name='act_prob')
#cross entropy loss function
self.neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.softmax_input,labels=self.tf_acts)
self.loss = tf.reduce_mean(self.neg_log_prob * self.tf_vt) # reward guided loss
self.train_op = tf.train.AdamOptimizer(LEARNING_RATE).minimize(self.loss) def weight_variable(self, shape):
initial = tf.truncated_normal(shape) #truncated normal distribution
return tf.Variable(initial) def bias_variable(self, shape):
initial = tf.constant(0.01, shape=shape)
return tf.Variable(initial)
四、序列采样:
def store_transition(self, s, a, r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
五、模型学习:
通过蒙特卡洛完整序列采样,对神经网络进行调整。
def learn(self):
#evaluate the value of all states in present episode
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * GAMMA + self.ep_rs[t]
discounted_ep_rs[t] = running_add
#normalization
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs) # train on episode
self.session.run(self.train_op, feed_dict={
self.state_input: np.vstack(self.ep_obs),
self.tf_acts: np.array(self.ep_as),
self.tf_vt: discounted_ep_rs,
}) self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
六、训练:
# Hyper Parameters
ENV_NAME = 'CartPole-v0'
EPISODE = 3000 # Episode limitation
STEP = 3000 # Step limitation in an episode
TEST = 10 # The number of experiment test every 100 episode def main():
# initialize OpenAI Gym env and dqn agent
env = gym.make(ENV_NAME)
agent = Policy_Gradient(env) for episode in range(EPISODE):
# initialize task
state = env.reset()
# Train
for step in range(STEP):
action = agent.choose_action(state) # e-greedy action for train
#take action
next_state,reward,done,_ = env.step(action)
#sample
agent.store_transition(state, action, reward)
state = next_state
if done:
#print("stick for ",step, " steps")
#model learning after a complete sample
agent.learn()
break # Test every 100 episodes
if episode % 100 == 0:
total_reward = 0
for i in range(TEST):
state = env.reset()
for j in range(STEP):
env.render()
action = agent.choose_action(state) # direct action for test
state,reward,done,_ = env.step(action)
total_reward += reward
if done:
break
ave_reward = total_reward/TEST
print ('episode: ',episode,'Evaluation Average Reward:',ave_reward) if __name__ == '__main__':
main()
reference:
https://www.cnblogs.com/pinard/p/10137696.html
https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/policy_gradient.py
强化学习_PolicyGradient(策略梯度)_代码解析的更多相关文章
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- java自定义注解学习(三)_注解解析及应用
上篇文章已经介绍了注解的基本构成信息.这篇文章,主要介绍注解的解析.毕竟你只声明了注解,是没有用的.需要进行解析.主要就是利用反射机制在运行时进行查看和利用这些信息 常用方法汇总 在Class.Fie ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
- 【论文笔记】AutoML for MCA on Mobile Devices——论文解读与代码解析
理论部分 方法介绍 本节将详细介绍AMC的算法流程.AMC旨在自动地找出每层的冗余参数. AMC训练一个强化学习的策略,对每个卷积层会给出其action(即压缩率),然后根据压缩率进行裁枝.裁枝后,A ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
随机推荐
- Python 之Event
线程间互相等状态. import threading import time import logging logging.basicConfig(level=logging.DEBUG, forma ...
- 微信小程序开发之页面数据绑定
js:Page( { data:{ parmer:"", //字符串参数 userinfo:{ userphone:"", ...
- bzoj 2055: 80人环游世界【有上下界有源汇最小费用最大流】
连有上下界的边(ss,i,(0,m),0),(i',t,(0,m),0),表示从任意点开始和结束 连(i,j,(0,m),d[i][j]),表示可以买票飞过去 连(i,i',(v[i],v[i]),0 ...
- [HNOI2010] 物品调度 fsk
标签:链表+数论知识. 题解: 对于这道题,其实就是两个问题的拼凑,我们分开来看. 首先要求xi与yi.这个可以发现,x每增加1,则pos增加d:y每增加1,则pos增加1.然后,我们把x与y分别写在 ...
- PAT甲级——1134 Vertex Cover (25 分)
1134 Vertex Cover (考察散列查找,比较水~) 我先在CSDN上发布的该文章,排版稍好https://blog.csdn.net/weixin_44385565/article/det ...
- gns3 拖出设备显示一个红色的s,无法启动虚拟设备
通过view-docks-调出console窗口,显示错误信息: Error while creating project: Can't connect to server http://172.0. ...
- 获取元素属性 和 获取元素的CSS属性
- mongodb-Configuration
命令行和配制后文件接口为Mongodb的管理者提供了大量的控制选项.在这篇文章中提供了对于一般应用场景的最佳实践配置. mongod --config /etc/mongod.conf mongod ...
- Zynq7000开发系列-7(在Zybo上运行Linaro桌面系统)
目标板:Zybo(7Z010) 主机操作系统:Ubuntu 14.04.5 LTS 64bit 交叉编译链: arm-xilinx-linux-gnueabi- [gcc version ...
- Day2课后作业:sed替换程序
#!/usr/bin/env python #_*_conding:utf-8_*_ import sys,os old_file = sys.argv[1] new_file = sys.argv[ ...