f-VAEGAN-D2:VAE+GAN处理零样本学习问题
虽然f-VAEGAN-D2在题目中说“适用任意样本”,但对比的Few-shot相关的实验较少,这里仅讨论零样本学习的情况。
1. 背景介绍
由于为每个对象收集足够数量的高质量带标签样本难以实现,使用有限的标签进行训练学习一直是一个重要的研究方向。零样本学习(Zero-Shot Learning, ZSL)最初被称为计算机视觉中的零数据学习,目标是在标签受到极大限制的设置下,完成训练。在传统的ZSL中(或称为归纳零样本学习),没有为目标类提供训练示例,因此这些类被称为未见类。对于训练示例,是有着标签配对的大量训练样本,这些样本的类被称为可见类。传统零样本学习的核心挑战是:对于存在的相关知识,使分类器能够从可见类中提取的知识转移到未见类中。类别相关的信息一般以辅助信息的形式给出,作为可见类与未见类知识迁移的桥梁,辅助信息被编码为嵌入向量后使用,辅助信息可以是由人工标注的属性信息、文本描述、知识图谱或本体(Ontology)等。
对于未见类,仅使用辅助信息学习会导致未见类真实分布与建模分布之间存在差异,这被称为域转移问题。为了简化零样本学习,提出了转导零样本学习(Transductive Zero-Shot Learning, TZSL),它允许在训练中额外包含未见类的未标记样本。
在足够的数据样本示例支持下,使用生成模型学习数据点的概率分布,以便从中采样并合成示例,实现数据增强,帮助TZSL学习未见类的数据分布。
2. 方法
f-VAEGAN-D2
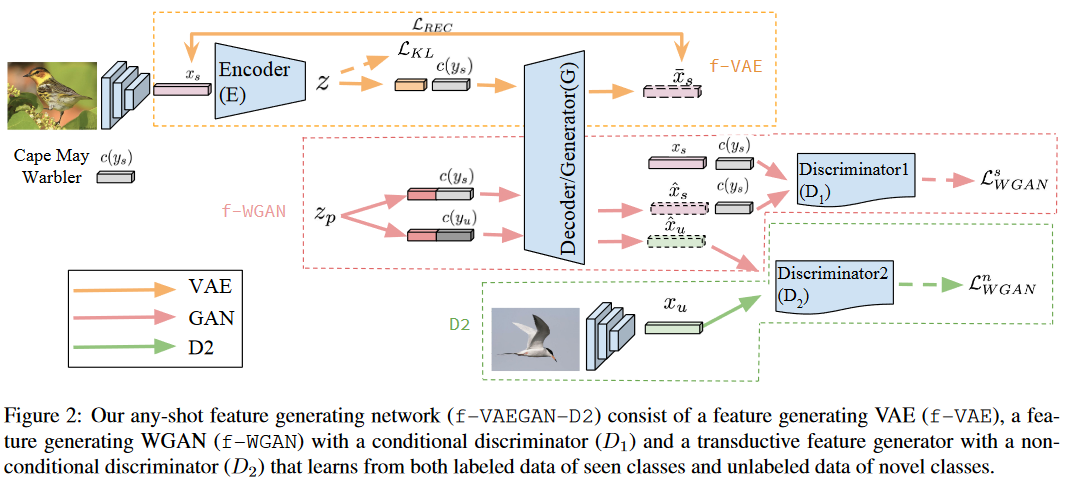
f-VAEGAN-D2作者通过消融实验证明将VAE与GAN结合能更好地生成图像特征。
设置
- 对于一组图像\(X={x_1,\ldots,x_l}\cup{x_{l+1},\ldots,x_t}\),编码在图像特征空间\(\mathcal{X}\)中。
- 一个已见类别标签集\(Y^s\),一个新类的标签集\(Y^n\)(也就是零样本学习中的未见类别标签集\(Y^u\))。
- 类别嵌入集合\(C=\{c(y)|\forall y\in Y^s\cup Y^n\}\)(也就是描述图像的信息)编码在语义嵌入空间\(\mathcal{C}\)中。
- 前\(l\)个样本\(x_s\ (s\le l)\)标记为已见类别\(y_s\in Y^s\),其余点\(x_{\boldsymbol{n}}(l+1\leq n\leq t)\)是未标记的,可能是已见或新类。
在归纳设置中,训练集仅包含已见类别图像的标记样本,即\(X=\{x_1,\ldots,x_l\}\)。在转导设置中,训练集包含标记和未标记样本,即\(X=\{x_1,\ldots,x_l,x_{l+1},\ldots,x_t\}\)。
在零样本学习中,任务是预测属于新颖类别的那些未标记点的标签,即\(f_{zsl}:\mathcal{X}\rightarrow\mathcal{Y}^n\)。而在广义零样本学习中,目标既可以是已见类别也可以来自新类的未标记数据并进行分类,即\(f_{gzsl}:\mathcal{X}\rightarrow\mathcal{Y}^s\cup\mathcal{Y}^n\)。
VAE与WGAN的损失函数
生成器\(G(z,c)\)接受随机噪声\(z_p\)(文中假设\(z_p\sim\mathcal{N}(0,1)\))和条件\(c\),生成特征空间\(\mathcal{X}\)上的CNN特征\(\hat{x}\)。判别器D(x,c)判断一对特征和类别嵌入是真实的还是生成的。GAN的优化目标(实际上就是WGAN的损失函数:'Earth-Mover'距离+梯度惩罚项)为:
\]
\(\tilde{x}=G(z,c)\)为生成的特征,\(\hat{x}=\alpha x+(1-\alpha x),\alpha\sim U(0,1)\),\(\lambda\)为惩罚系数。
编码器\(E(x,c)\)将一对特征\(x\)和作为条件的类别嵌入\(c\)编码为潜在向量\(z\)(但从图中可以看到\(c\)并没有被处理)。VAE的优化目标为:
\]
\(q(z|x,c)\)即为\(E(x,c)\),表示建模的条件分布;\(p(z|c)\)被假设为\(\mathcal{N}(0,1)\);\(p(x|z,c)\)等同于解码器\(Dec(z,x)\)。
优化目标设置
图中的编码器\(E(x,c):\mathcal{X}\times\mathcal{C}\rightarrow\mathcal{Z}\)将一对特征和类别嵌入编码为潜在向量。判别器\(D_{1}:\mathcal{X}\times\mathcal{C}\rightarrow\mathbb{R}\)判断一对特征和类别嵌入是真实的还是生成的。整个VAE-GAN的优化目标为:
\]
VAE的Decoder与GAN的Generator共享参数(也就是同一个模块两个名字,就像图中画出的);上标\(s\)表示该损失仅用于可见类;\(\gamma\)为超参数控制VAE和WGAN损失的权重。
而对于未见类,使用了无条件判别器\(D_2\mathcal{X}\to\mathbb{R}\)区分是真实的还是合成的未见类特征,优化目标为一个WGAN的损失函数:
\]
其中\(\tilde{x}_n=G(z,y_n), y_n\in Y^n,\hat{x}_n=\alpha x_n+(1-\alpha x_n),\alpha\sim U(0,1)\)。
\(\mathcal{L}^s_{WGAN}\)的训练依赖语义嵌入的质量并存在域转移问题(缓解域转移问题也是归纳ZSL发展至转导ZSL的重要原因)。于是通过\(\mathcal{L}^n_{WGAN}\)学习CNN特征的边缘分布,为新类提供可转移的CNN特征。因此整个f-VAEGAN-D2优化函数为:
\]
其他
图中的随机噪声\(z\sim \mathcal{N}(0,1)\)与类嵌入\(c(y)\),经过串联后进入生成器,它们的维度相同时,即\(d_z=d_c\)效果较好(没有解释,也许是测试发现的?)。同样,视觉特征和类嵌入串联后进入判别器。\(\mathcal{L}_{REC}\)为二元交叉熵损失函数,表示重构损失。
3. 实验
论文中,对于合成的特征进行解释。图像特征通过上采样生成图片;文本解释通过训练的LSTM生成,LSTM根据图像的平均隐藏层生成类嵌入,得到合成特征的解释。

对于每一块,顶部是原始图像,中部是原始图像真实特征(R)重构结果,底部同一类的合成特征(S)重构结果。
图展示了从真实特征和合成特征获得的解释。我们观察到该模型为可见类和未见类的合成特征生成图像相关和类特定的解释。例如,“King Protea”特征包含有关“红色花瓣和尖尖”的信息,而“Purple Coneflower”特征包含有关“粉红色和向下下垂的花瓣”的信息,这些特征是这种花在视觉上最显着的特征。
另一方面,如图底部所示,对于图像特征缺乏一定细节水平的类,生成的解释存在一些问题,例如重复,例如“喇叭形”和“星形”在同一个句子中和未知单词,例如参见“气球花(Balloon Flower)”的解释。
参考文献
- Xian, Yongqin, et al. "f-vaegan-d2: A feature generating framework for any-shot learning." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
f-VAEGAN-D2:VAE+GAN处理零样本学习问题的更多相关文章
- Zero-shot learning(零样本学习)
一.介绍 在传统的分类模型中,为了解决多分类问题(例如三个类别:猫.狗和猪),就需要提供大量的猫.狗和猪的图片用以模型训练,然后给定一张新的图片,就能判定属于猫.狗或猪的其中哪一类.但是对于之前训练图 ...
- 零样本学习 - (Zero shot learning,ZSL)
https://zhuanlan.zhihu.com/p/41846072 https://zhuanlan.zhihu.com/p/38418698 https://zhuanlan.zhihu.c ...
- 【论文解读】NIPS 2021-HSWA: Hierarchical Semantic-Visual Adaption for Zero-Shot Learning.(基于层次适应的零样本学习)
作者:陈使明 华中科技大学
- 零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程. 1.通用文本分类技术UTC介绍 本项目提供基于通用文本分类 UTC(Universal Text C ...
- Yaf零基础学习总结3-Hello Yaf
Yaf零基础学习总结3-Hello Yaf 上一次我们已经学习了如何安装yaf了,准备工作做好了之后我们来开始实际的编码了,码农都知道一个经典的语句就是“Hello World”了,今天我们开始入手Y ...
- 零基础学习Linux(二)网页乱码问题
上次的博文零基础学习Linux(一)环境搭建中我们已经将Linux环境搭建完毕了,接下来我们就可以进行相关的操作了,在进行操作之前,我们先来看一下大家可能遇到的中文网页乱码问题. 1.问题演示 a)输 ...
- 基于PU-Learning的恶意URL检测——半监督学习的思路来进行正例和无标记样本学习
PU learning问题描述 给定一个正例文档集合P和一个无标注文档集U(混合文档集),在无标注文档集中同时含有正例文档和反例文档.通过使用P和U建立一个分类器能够辨别U或测试集中的正例文档 [即想 ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning(从几个例子总结经验:少样本学习综述)
摘要:人工智能在数据密集型应用中取得了成功,但它缺乏从有限的示例中学习的能力.为了解决这一问题,提出了少镜头学习(FSL).利用先验知识,可以快速地从有限监督经验的新任务中归纳出来.为了全面了解FSL ...
- salesforce 零基础学习(五十二)Trigger使用篇(二)
第十七篇的Trigger用法为通过Handler方式实现Trigger的封装,此种好处是一个Handler对应一个sObject,使本该在Trigger中写的代码分到Handler中,代码更加清晰. ...
- 如何从零基础学习VR
转载请声明转载地址:http://www.cnblogs.com/Rodolfo/,违者必究. 近期很多搞技术的朋友问我,如何步入VR的圈子?如何从零基础系统性的学习VR技术? 本人将于2017年1月 ...
随机推荐
- Redis和Memcache区别,优缺点对比(转)
转自 https://www.cnblogs.com/JavaBlackHole/p/7726195.html 1. Redis和Memcache都是将数据存放在内存中,都是内存数据库.不过memca ...
- RedisStack部署/持久化/安全/与C#项目集成
前言 Redis可好用了,速度快,支持的数据类型又多,最主要的是现在可以用来向量搜索了. 本文记录一下官方提供的 redis-stack 部署和配置过程. 关于 redis-stack redis-s ...
- 其它——MyCat实现分库分表
文章目录 MyCat实现分库分表 一 开源数据库中间件-MyCat 二 MyCat简介 三 MyCat下载及安装 3.1 MySQL安装与启动 3.2使用docker启动多个数据库 3.3 MyCat ...
- Java算法之动态规划
①动态规划 动态规划(Dynamic Programming,DP)是运筹学的一个分支,是求解决策过程最优化的过程.20世纪50年代初,美国数学家贝尔曼(R.Bellman)等人在研究多阶段决策过程的 ...
- slice简介
简介 Go语言中的切片(slice)是一种灵活的数据结构,它构建在数组之上并提供了方便的方式来操作数组的一部分.切片的底层实现涉及到数组和一些元数据.以下是Golang切片的底层实现的详细介绍: 底层 ...
- 2023-10-25:用go语言,假如某公司目前推出了N个在售的金融产品(1<=N<=100) 对于张三,用ai表示他购买了ai(0<=ai<=10^4)份额的第i个产品(1<=i<=N) 现给出K(
2023-10-25:用go语言,假如某公司目前推出了N个在售的金融产品(1<=N<=100) 对于张三,用ai表示他购买了ai(0<=ai<=10^4)份额的第i个产品(1& ...
- js前端操作,c#后端下发xml文件
前端: var xmlLanguageDoc; $.ajax({ url: "/GiveMeXML",//此处可随意定义,不一定是路径.在c# ,请求被捕获后,由c ...
- 线段树(nb)
今天刚学习了线段树,赶紧趁热打了两遍模版 下面都是线段树的基本操作,这个板子是维护的区间中的最大值,当然修改change和build包括线段树中的data可以维护区间上的不同信息. 首先介绍一下线段树 ...
- [学习笔记]TypeScript查缺补漏(二):类型与控制流分析
@ 目录 类型约束 基本类型 联合类型 控制流分析 instanceof和typeof 类型守卫和窄化 typeof判断 instanceof判断 in判断 内建函数,或自定义函数 赋值 布尔运算 保 ...
- Python 正则表达式(RegEx)指南
正则表达式(RegEx)是一系列字符,形成了一个搜索模式.RegEx 可用于检查字符串是否包含指定的搜索模式. RegEx 模块 Python 中有一个内置的包叫做 re,它可以用于处理正则表达式.导 ...