使用Python进行描述性统计
目录
1 描述性统计是什么?
2 使用NumPy和SciPy进行数值分析
2.1 基本概念
2.2 中心位置(均值、中位数、众数)
2.3 发散程度(极差,方差、标准差、变异系数)
2.4 偏差程度(z-分数)
2.5 相关程度(协方差,相关系数)
2.6 回顾
3 使用Matplotlib进行图分析
3.1 基本概念
3.2 频数分析
3.2.1 定性分析(柱状图、饼形图)
3.2.2 定量分析(直方图、累积曲线)
3.3 关系分析(散点图)
3.4 探索分析(箱形图)
3.5 回顾
4 总结
5 参考资料
1 描述性统计是什么?
描述性统计是借助图表或者总结性的数值来描述数据的统计手段。数据挖掘工作的数据分析阶段,我们可借助描述性统计来描绘或总结数据的基本情况,一来可以梳理自己的思维,二来可以更好地向他人展示数据分析结果。数值分析的过程中,我们往往要计算出数据的统计特征,用来做科学计算的NumPy和SciPy工具可以满足我们的需求。Matpotlob工具可用来绘制图,满足图分析的需求。
2 使用NumPy和SciPy进行数值分析
2.1 基本概念
与Python中原生的List类型不同,Numpy中用ndarray类型来描述一组数据:
from numpy import array
from numpy.random import normal, randint
#使用List来创造一组数据
data = [1, 2, 3]
#使用ndarray来创造一组数据
data = array([1, 2, 3])
#创造一组服从正态分布的定量数据
data = normal(0, 10, size=10)
#创造一组服从均匀分布的定性数据
data = randint(0, 10, size=10)
2.2 中心位置(均值、中位数、众数)
数据的中心位置是我们最容易想到的数据特征。借由中心位置,我们可以知道数据的一个平均情况,如果要对新数据进行预测,那么平均情况是非常直观地选择。数据的中心位置可分为均值(Mean),中位数(Median),众数(Mode)。其中均值和中位数用于定量的数据,众数用于定性的数据。
对于定量数据(Data)来说,均值是总和除以总量(N),中位数是数值大小位于中间(奇偶总量处理不同)的值:

均值相对中位数来说,包含的信息量更大,但是容易受异常的影响。使用NumPy计算均值与中位数:
from numpy import mean, median #计算均值
mean(data)
#计算中位数
median(data)
对于定性数据来说,众数是出现次数最多的值,使用SciPy计算众数:
from scipy.stats import mode #计算众数
mode(data)
2.3 发散程度(极差、方差、标准差、变异系数)
对数据的中心位置有所了解以后,一般我们会想要知道数据以中心位置为标准有多发散。如果以中心位置来预测新数据,那么发散程度决定了预测的准确性。数据的发散程度可用极差(PTP)、方差(Variance)、标准差(STD)、变异系数(CV)来衡量,它们的计算方法如下:

极差是只考虑了最大值和最小值的发散程度指标,相对来说,方差包含了更多的信息,标准差基于方差但是与原始数据同量级,变异系数基于标准差但是进行了无量纲处理。使用NumPy计算极差、方差、标准差和变异系数:
from numpy import mean, ptp, var, std #极差
ptp(data)
#方差
var(data)
#标准差
std(data)
#变异系数
mean(data) / std(data)
2.4 偏差程度(z-分数)
之前提到均值容易受异常值影响,那么如何衡量偏差,偏差到多少算异常是两个必须要解决的问题。定义z-分数(Z-Score)为测量值距均值相差的标准差数目:
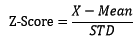
当标准差不为0且不为较接近于0的数时,z-分数是有意义的,使用NumPy计算z-分数:
from numpy import mean, std #计算第一个值的z-分数
(data[0]-mean(data)) / std(data)
通常来说,z-分数的绝对值大于3将视为异常。
2.5 相关程度
有两组数据时,我们关心这两组数据是否相关,相关程度有多少。用协方差(COV)和相关系数(CORRCOEF)来衡量相关程度:
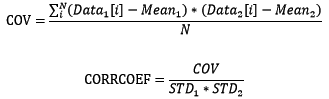
协方差的绝对值越大表示相关程度越大,协方差为正值表示正相关,负值为负相关,0为不相关。相关系数是基于协方差但进行了无量纲处理。使用NumPy计算协方差和相关系数:
from numpy import array, cov, corrcoef data = array([data1, data2]) #计算两组数的协方差
#参数bias=1表示结果需要除以N,否则只计算了分子部分
#返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的协方差。对角线为方差
cov(data, bias=1) #计算两组数的相关系数
#返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的相关系数。对角线为1
corrcoef(data)
2.6 回顾
| 包 | 方法 | 说明 |
| numpy | array | 创造一组数 |
| numpy.random | normal | 创造一组服从正态分布的定量数 |
| numpy.random | randint | 创造一组服从均匀分布的定性数 |
| numpy | mean | 计算均值 |
| numpy | median | 计算中位数 |
| scipy.stats | mode | 计算众数 |
| numpy | ptp | 计算极差 |
| numpy | var | 计算方差 |
| numpy | std | 计算标准差 |
| numpy | cov | 计算协方差 |
| numpy | corrcoef | 计算相关系数 |
3 使用Matplotlib进行图分析
3.1 基本概念
使用图分析可以更加直观地展示数据的分布(频数分析)和关系(关系分析)。柱状图和饼形图是对定性数据进行频数分析的常用工具,使用前需将每一类的频数计算出来。直方图和累积曲线是对定量数据进行频数分析的常用工具,直方图对应密度函数而累积曲线对应分布函数。散点图可用来对两组数据的关系进行描述。在没有分析目标时,需要对数据进行探索性的分析,箱形图将帮助我们完成这一任务。
在此,我们使用一组容量为10000的男学生身高,体重,成绩数据来讲解如何使用Matplotlib绘制以上图形,创建数据的代码如下:
from numpy import array
from numpy.random import normal def genData():
heights = []
weights = []
grades = []
N = 10000 for i in range(N):
while True:
#身高服从均值172,标准差为6的正态分布
height = normal(172, 6)
if 0 < height: break
while True:
#体重由身高作为自变量的线性回归模型产生,误差服从标准正态分布
weight = (height - 80) * 0.7 + normal(0, 1)
if 0 < weight: break
while True:
#分数服从均值为70,标准差为15的正态分布
score = normal(70, 15)
if 0 <= score and score <= 100:
grade = 'E' if score < 60 else ('D' if score < 70 else ('C' if score < 80 else ('B' if score < 90 else 'A')))
break
heights.append(height)
weights.append(weight)
grades.append(grade)
return array(heights), array(weights), array(grades) heights, weights, grades = genData()
3.2 频数分析
3.2.1 定性分析(柱状图、饼形图)
柱状图是以柱的高度来指代某种类型的频数,使用Matplotlib对成绩这一定性变量绘制柱状图的代码如下:
from matplotlib import pyplot #绘制柱状图
def drawBar(grades):
xticks = ['A', 'B', 'C', 'D', 'E']
gradeGroup = {}
#对每一类成绩进行频数统计
for grade in grades:
gradeGroup[grade] = gradeGroup.get(grade, 0) + 1
#创建柱状图
#第一个参数为柱的横坐标
#第二个参数为柱的高度
#参数align为柱的对齐方式,以第一个参数为参考标准
pyplot.bar(range(5), [gradeGroup.get(xtick, 0) for xtick in xticks], align='center') #设置柱的文字说明
#第一个参数为文字说明的横坐标
#第二个参数为文字说明的内容
pyplot.xticks(range(5), xticks) #设置横坐标的文字说明
pyplot.xlabel('Grade')
#设置纵坐标的文字说明
pyplot.ylabel('Frequency')
#设置标题
pyplot.title('Grades Of Male Students')
#绘图
pyplot.show() drawBar(grades)
绘制出来的柱状图的效果如下:
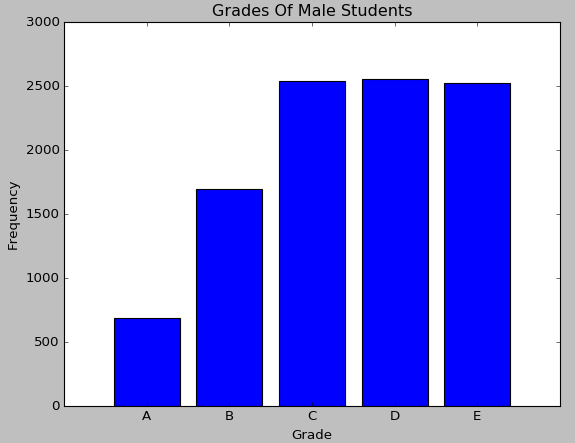
而饼形图是以扇形的面积来指代某种类型的频率,使用Matplotlib对成绩这一定性变量绘制饼形图的代码如下:
from matplotlib import pyplot #绘制饼形图
def drawPie(grades):
labels = ['A', 'B', 'C', 'D', 'E']
gradeGroup = {}
for grade in grades:
gradeGroup[grade] = gradeGroup.get(grade, 0) + 1
#创建饼形图
#第一个参数为扇形的面积
#labels参数为扇形的说明文字
#autopct参数为扇形占比的显示格式
pyplot.pie([gradeGroup.get(label, 0) for label in labels], labels=labels, autopct='%1.1f%%')
pyplot.title('Grades Of Male Students')
pyplot.show() drawPie(grades)
绘制出来的饼形图效果如下:

3.2.2 定量分析(直方图、累积曲线)
直方图类似于柱状图,是用柱的高度来指代频数,不同的是其将定量数据划分为若干连续的区间,在这些连续的区间上绘制柱。使用Matplotlib对身高这一定量变量绘制直方图的代码如下:
from matplotlib import pyplot #绘制直方图
def drawHist(heights):
#创建直方图
#第一个参数为待绘制的定量数据,不同于定性数据,这里并没有事先进行频数统计
#第二个参数为划分的区间个数
pyplot.hist(heights, 100)
pyplot.xlabel('Heights')
pyplot.ylabel('Frequency')
pyplot.title('Heights Of Male Students')
pyplot.show() drawHist(heights)
直方图对应数据的密度函数,由于身高变量是属于服从正态分布的,从绘制出来的直方图上也可以直观地看出来:
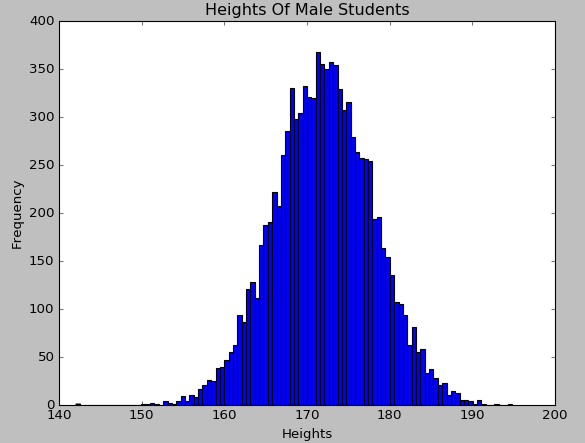
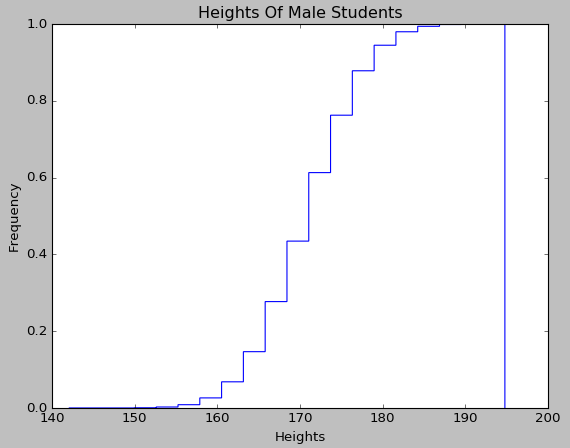
使用Matplotlib对身高这一定量变量绘制累积曲线的代码如下:
from matplotlib import pyplot #绘制累积曲线
def drawCumulativeHist(heights):
#创建累积曲线
#第一个参数为待绘制的定量数据
#第二个参数为划分的区间个数
#normed参数为是否无量纲化
#histtype参数为'step',绘制阶梯状的曲线
#cumulative参数为是否累积
pyplot.hist(heights, 20, normed=True, histtype='step', cumulative=True)
pyplot.xlabel('Heights')
pyplot.ylabel('Frequency')
pyplot.title('Heights Of Male Students')
pyplot.show() drawCumulativeHist(heights)
累积曲线对应数据的分布函数,由于身高变量是属于服从正态分布的,从绘制出来的累积曲线图上也可以直观地看出来:
3.3 关系分析(散点图)
在散点图中,分别以自变量和因变量作为横纵坐标。当自变量与因变量线性相关时,在散点图中,点近似分布在一条直线上。我们以身高作为自变量,体重作为因变量,讨论身高对体重的影响。使用Matplotlib绘制散点图的代码如下:
from matplotlib import pyplot #绘制散点图
def drawScatter(heights, weights):
#创建散点图
#第一个参数为点的横坐标
#第二个参数为点的纵坐标
pyplot.scatter(heights, weights)
pyplot.xlabel('Heights')
pyplot.ylabel('Weights')
pyplot.title('Heights & Weights Of Male Students')
pyplot.show() drawScatter(heights, weights)
我们在创建数据时,体重这一变量的确是由身高变量通过线性回归产生,绘制出来的散点图如下:

3.4 探索分析(箱形图)
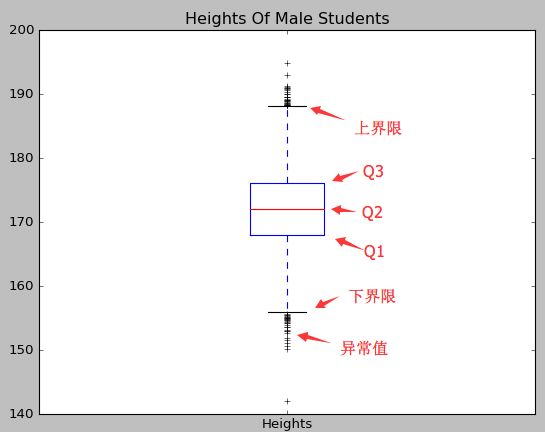
在不明确数据分析的目标时,我们对数据进行一些探索性的分析,通过我们可以知道数据的中心位置,发散程度以及偏差程度。使用Matplotlib绘制关于身高的箱形图的代码如下:
from matplotlib import pyplot #绘制箱形图
def drawBox(heights):
#创建箱形图
#第一个参数为待绘制的定量数据
#第二个参数为数据的文字说明
pyplot.boxplot([heights], labels=['Heights'])
pyplot.title('Heights Of Male Students')
pyplot.show() drawBox(heights)
绘制出来的箱形图中,包含3种信息:
- Q2所指的红线为中位数
- Q1所指的蓝框下侧为下四分位数,Q3所指的蓝框上侧为上四分位数,Q3-Q1为四分为差。四分位差也是衡量数据的发散程度的指标之一。
- 上界线和下界线是距离中位数1.5倍四分位差的线,高于上界线或者低于下界线的数据为异常值。
3.5 回顾
| 方法 | 说明 |
| bar | 柱状图 |
| pie | 饼形图 |
| hist | 直方图&累积曲线 |
| scatter | 散点图 |
| boxplot | 箱形图 |
| xticks | 设置柱的文字说明 |
| xlabel | 横坐标的文字说明 |
| ylabel | 纵坐标的文字说明 |
| title | 标题 |
| show | 绘图 |
4 总结
描述性统计是容易操作,直观简洁的数据分析手段。但是由于简单,对多元变量的关系难以描述。现实生活中,自变量通常是多元的:决定体重不仅有身高,还有饮食习惯,肥胖基因等等因素。通过一些高级的数据处理手段,我们可以对多元变量进行处理,例如特征工程中,可以使用互信息方法来选择多个对因变量有较强相关性的自变量作为特征,还可以使用主成分分析法来消除一些冗余的自变量来降低运算复杂度。
5 参考资料
使用Python进行描述性统计的更多相关文章
- Python实现描述性统计
该篇笔记由木东居士提供学习小组.资料 描述性统计的概念很好理解,在日常工作中我们也经常会遇到需要使用描述性统计来表述的问题.以下,我们将使用Python实现一系列的描述性统计内容. 有关python环 ...
- Pandas描述性统计
有很多方法用来集体计算DataFrame的描述性统计信息和其他相关操作. 其中大多数是sum(),mean()等聚合函数,但其中一些,如sumsum(),产生一个相同大小的对象. 一般来说,这些方法采 ...
- Pandas | 06 描述性统计
有很多方法用来集体计算DataFrame的描述性统计信息和其他相关操作. 其中大多数是sum(),mean()等聚合函数. 一般来说,这些方法采用轴参数,就像ndarray.{sum,std,...} ...
- Pandas 之 描述性统计案例
认识 jupyter地址: https://nbviewer.jupyter.org/github/chenjieyouge/jupyter_share/blob/master/share/panda ...
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
https://www.zhihu.com/topic/19582125/top-answershttps://wenku.baidu.com/search?word=spss&ie=utf- ...
- \(\S1\) 描述性统计
在认识客观世界的过程中,统计学的思想和方法经常起着不可替代的作用.在许多工程及自然科学的专业领域中,包括可靠性分析.质量控制.生物信息.脑科学.心理分析.经济分析.金融风险管理.社会科学推断.行为科学 ...
- Python获得百度统计API的数据并发送邮件
Python获得百度统计API的数据并发送邮件 小工具 本来这么晚是不准备写博客的,当是想到了那个狗子绝对会在开学的时候跟我逼逼这个事情,所以,还是老老实实地写一下吧. Baidu统计API的使 ...
- python编写文件统计脚本
python编写文件统计脚本 思路:用os模块中的一些函数(os.listdir().os.path.isdir().os.path.join().os.path.abspath()等) 实现功能:显 ...
- Python实现代码统计工具——终极加速篇
Python实现代码统计工具--终极加速篇 声明 本文对于先前系列文章中实现的C/Python代码统计工具(CPLineCounter),通过C扩展接口重写核心算法加以优化,并与网上常见的统计工具做对 ...
随机推荐
- 关于安卓APP的启动界面
刚学安卓App开发的朋友们,可能会遇到一个问题,就是人家的App刚进入会有一个页面出现一会儿后消失, 这个页面可以用来打广告,也可以声明App的主题,所以说这个启动页面至关重要,接下来,我把我的代 ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- 解决Jenkins 2.0 初始化界面卡住的问题
***************************************** *原创博客转载请注明出处,谢谢!* **************************************** ...
- 准备CLR源码阅读环境
微软发布了CLR 2.0的源码,这个源码是可以直接在freebsd和windows环境下编译及运行的,请在微软shared source cli(http://www.microsoft.com/en ...
- ORACLE NUMBER类型Scale为0引发的问题
今天遇到了一个很有意思的NUMBER类型Scale引发的问题,我用一个简单的测试用例来展示一下这个案例.假如有个TEST的表,有个字段类型为NUMBER,我插入下面两条数据 CREATE TABLE ...
- PHP中require和include路径问题总结
1 绝对路径.相对路径和未确定路径 相对路径 相对路径指以.开头的路径,例如 ./a/a.php (相对当前目录) ../common.inc.php (相对上级目录), 绝对路径 绝对路径是以 / ...
- WinForm常用属性
Text: 字符串,窗体标题 MaximizeBox: 布尔, 窗体能否最大化 MinimizeBox: 布尔,窗体能否最小化 ShowIcon: 布尔,左上角图标 ShowInTaskbar: 布尔 ...
- SQL Server 2008 R2——根据数据查找表名和字段名 根据脏数据定位表和字段
=================================版权声明================================= 版权声明:原创文章 谢绝转载 请通过右侧公告中的“联系邮 ...
- 常见博客API
新浪博客 http://upload.move.blog.sina.com.cn/blog_rebuild/blog/xmlrpc.php 网易博客 http://os.blog.163.com/ap ...
- 基于GPUImage的多滤镜rtmp直播推流
之前做过开源videocore的推流改进:1)加入了美颜滤镜; 2) 加入了librtmp替换原来过于简单的rtmpclient: 后来听朋友说,在videocore上面进行opengl修改,加入新的 ...