可观测|时序数据降采样在Prometheus实践复盘
简介: 基于 Prometheus 的监控实践中,尤其是在规模较大时,时序数据的存储与查询是其中非常关键,而且问题点较多的一环。如何应对大数据量下的长周期查询,原生的 Prometheus 体系并未能给出一个令人满意的答案。对此,ARMS Prometheus 近期上线了降采样功能,为解决这个问题做出了新的尝试。
作者:智真
基于 Prometheus 的监控实践中,尤其是在规模较大时,时序数据的存储与查询是其中非常关键,而且问题点较多的一环。如何应对大数据量下的长周期查询,原生的 Prometheus 体系并未能给出一个令人满意的答案。对此,ARMS Prometheus 近期上线了降采样功能,为解决这个问题做出了新的尝试。
前言
问题背景
Prometheus 与 K8s 作为云原生时代的一对黄金搭档,是目前许多企业运行环境的标准配置。然而,为了适应业务规模和微服务的发展演进,被监控对象的数量会一路增长;为了更完整的体现系统或应用的状态细节,指标粒度划分越来越细致,指标数量越来越多;为了发现更长周期的趋势变化,指标数据的保留周期势必也要更长。所有这些变化最终都会导致监控数据量的爆炸性增长,给观测产品的存储、查询、计算带来非常大的压力。
我们可以通过一个简单的场景,来更直观的感受下这种数据爆炸的后果。假如我们需要查询近一个月中我的集群各个节点上 CPU 用量的变化情况,而我的集群是一个 30 个物理节点的小规模集群,每个节点上平均运行了 50 个需要采集指标的 POD,按照默认的 30 秒采集间隔,我们需要处理的采集 target 共有 30*50 = 1500 个,而每个采样点每天会被抓取 60*60*24/30 = 2880 次,在一个月的周期里,共有 1500 * 2880 * 30 = 1.3 亿次指标抓取,以 Node exporter 为例,一台裸机一次抓取吐出的 sample 数量约为500,那么一个月内这个集群产生的采样点约有 1.3 亿 * 500 = 650 亿个!而在现实的业务系统中,情况往往不会这么理想,实际的采样点数量往往会超过千亿。
面对这种情况,我们必须要有一些技术手段,在尽可能保证数据准确性的前提下,对存储/查询/计算的成本和效率做优化提升。降采样(DownSampling)就是其中一种代表性的思路。
什么是降采样
降采样基于这样一个前提:数据的处理符合结合律,多个采样点的值的合并,并不会影响最终计算结果,正巧 Prometheus 的时序数据就符合这样的特点。降采样换句话说就是降低数据的分辨率,其思路非常直接,如果将一定时间间隔内的数据点,基于一定规则,聚合为一个或一组值,从而达到降低采样点数,减少数据量,减轻存储查询计算的压力。所以我们需要两个输入项:时间间隔,聚合规则。
对于降采样的时间间隔,基于经验分析,我们划定了两种不同的降采样时间间隔:五分钟和一小时,再加上原始数据,会得到三种不同 resolution 的数据,根据查询条件自动将查询请求路由到不同 resolution 的数据。随着后续 ARMS Prometheus 提供更长的存储时长选择,我们可能还会增加新的时间间隔选项。
对于聚合规则,通过对 Prometheus 的算子函数的分析,各种算子函数最终都可以归纳到六种类型的数值计算上:
- max,用于计算 vector 内最大值,典型算子如 max_over_time;
- min,用于计算 vector 内的最小值,典型算子如 min_over_time;
- sum,用于计算 vector 内的和值,典型算子如 sum_over_time;
- count,用于统计 ventor 内的点数,典型算子如 count_over_time;
- counter,用于计算变化率,典型算子如 rate,increase 等;
- avg,取时间间隔内的各个点的平均值;
由此可见,对于时间区间内的一系列采样点,我们只需要计算出如上六种类型的聚合特征值,在查询时返回相应时间区间聚合值即可。如果默认的 scrape interval 为 30 秒,五分钟的降采样会将十个点聚合成一个点;一小时的降采样,会将 120 个点聚合成一个点,同样查询涉及到的采样点数,会有数量级的下降,如果 scrape interval 更小,那么采样点缩减的效果会更显著。采样点数的缩减一方面减轻了 TSDB 读取压力,另一方面查询引擎的计算压力也将同步减小,进而有效减少查询耗时。
如何实现降采样
他山之石
其他开源/商业的时序数据存储实现上,有一些也通过降采样功能,对长时间跨度查询做了优化提升,我们也一起了解一下。
- Prometheus
开源 Prometheus 的存储能力,一直是比较让人诟病的一点,开源的 Prometheus 本身并未直接提供降采样的能力,但提供了 Recording Rule 能力,用户可以使用 Recording Rule 来自行实现 DownSampling,但这样会产生新的时间线,在高基数场景下,反而进一步加剧了存储压力。
- Thanos
作为知名的 Prometheus 高可用存储方案,Thanos 提供了较为完善的降采样方案。Thanos 中执行 downsmpling 功能的组件是 compactor,他会:
- 定期从 ojbect storage 中拉取 block(原始的 Prometheus Block,2 小时时间跨度),进行 compaction和downsampling,downsampling 的状态会记录到 block metadata。
- 压缩和降采样的结果,生成新的 block,写入到 object storage。
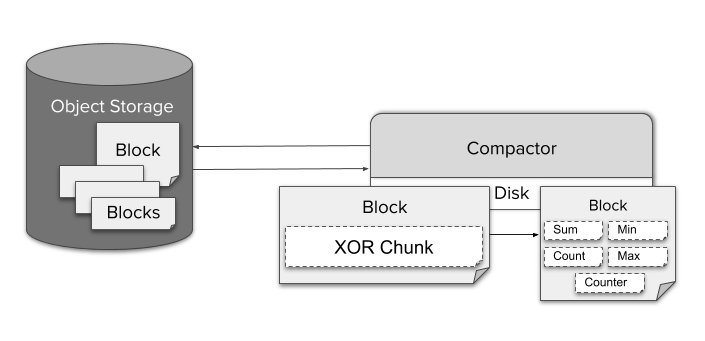
Downsampling 之后的特征值包括 sum/count/max/min/counter,写到特殊的 aggrChunks 数据块里。在做查询时:
- 原始的聚合算子和函数会转换成特殊的 AggrFunc,对应用于读取 aggrChunks 数据块数据
- 读取的 block 按照时间排序,优先读取最大 Resolution 的 block
- M3
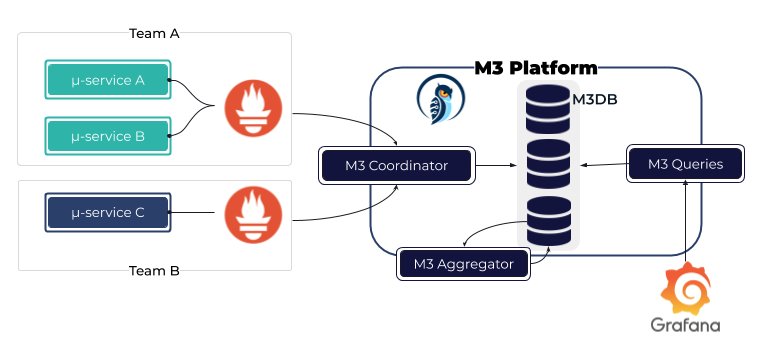
M3 Aggregator 负责在指标存储到 M3DB 前,流式聚合指标,并且根据 storagePolicy 指定指标存储时长和计算窗口的采样间隔。
M3 支持的数据间隔更加灵活,特征值更多,包括 histogram quantile 函数。
- InfluxDB/Victoria Metric/Context
Victoria Metrics 目前只在商业版本上线了降采样功能,开源版本并未透出。InfluxDB 的开源版本(v2.0 之前)通过类似 Recording Rule 的方式,对已经落盘了的原始数据在存储介质外执行 continuous query 来实现降采样。Context 目前尚不支持降采样。
我们怎么做
市面上的降采样方案各有千秋,我们简单总结了他们的使用成本等用户比较关注的点,比对如下:
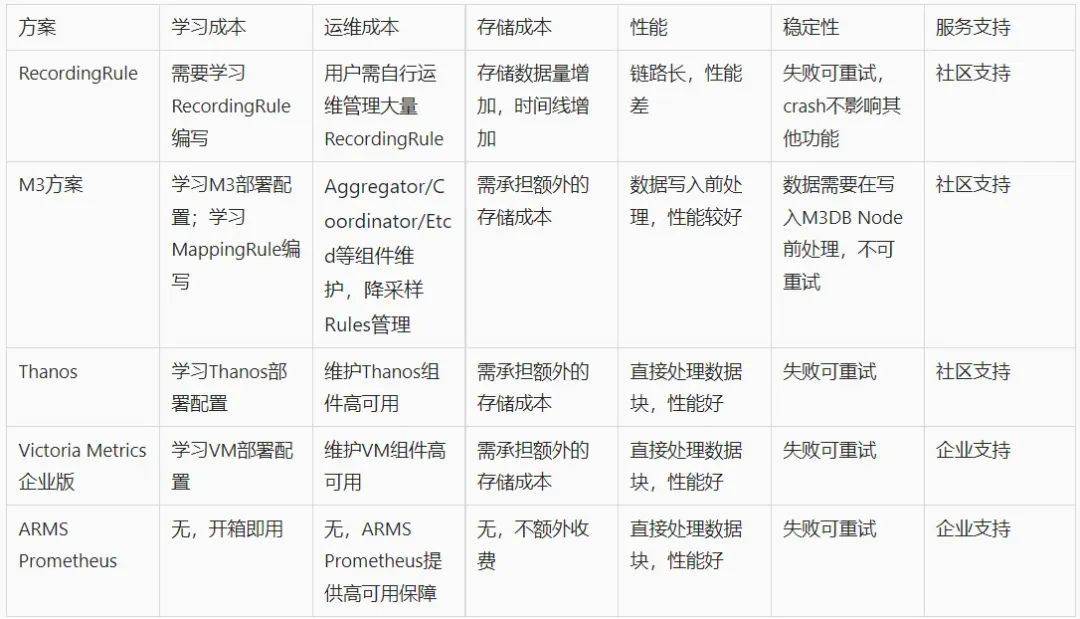
ARMS Prometheus 采用了处理 TSDB 存储块的方式,由后台自动将原始数据块处理为降采样数据块,一方面能取得一个较好的处理性能,另一方面对于终端用户来说,不需要关心参数配置规则维护等等,尽可能的减轻用户运维负担。
此功能已经在阿里云部分 region 上线,并开始定向邀请体验。在即将推出的 ARMS Prometheus 高级版中,将默认集成并提供此功能。
降采样对查询的影响
在我们完成了采样点层面的降采样之后,长时间跨度的查询问题就迎刃而解了么?显然不是的,TSDB 中保存的只是最原始的物料,而用户看到的曲线,还需要经过查询引擎的计算处理,而在计算处理的过程中,我们至少面临这么两个问题:
- Q1:什么情况下读取降采样数据?是不是降采样后就无法使用原始数据了?
- Q2:降采样后数据点密度更小,数据更“稀疏”,其查询表现会和原始数据一致么?需要用户调整 PromQL 么?
对于第一个问题,ARMS Prometheus 会根据用户的查询语句及过滤条件,智能选择适合的时间颗粒度,在数据细节和查询性能之间做出恰当的均衡。
对于第二个问题,首先可以说结论:采集点的密度对结果计算有很大影响,但 ARMS Prometheus 在查询引擎层面屏蔽了差异,用户无需调整 PromQL。这个影响主要体现在三个方面:与查询语句 duration 间的影响,与查询请求的 step 间的影响,以及对算子本身的影响,下面我们将详细说明这三方面的影响,以及 ARMS Prometheus 在这三方面做的工作。
duration 与降采样计算结果
我们知道,PromQL 中区间向量(Range Vector)查询时,都会带上一个时间区间参数(time duration),用于框定一个时间范围,用于计算结果。比如查询语句http_requests_total{job="prometheus"}[2m]中,指定的 duration 即为两分钟,计算结果时,会将查询到的 time series 以两分钟为单位,分割成若干个 vector,传递给 function 做计算,并分别返回结果。duration 直接决定了 function 计算时能拿到的入参长度,对结果的影响显而易见。
一般情况下,采集点的间隔是 30s 或者更短,只要 time duration 大于这个值,我们就可以确定每个分割出来的 vector 中,都会有若干 samples,用于计算结果。当降采样处理之后,数据点间隔会变大(五分钟甚至一小时),这时候可能就会出现 vector 中没有值的情形,这就导致 function 计算结果出现断断续续的情况。对于这种情况 ARMS Prometheus 会自动调整算子的 time duration 参数来应对,保证 duration 不小于降采样的 resolution,即保证每个 ventor 中都会有采样点,保证计算结果的准确性。
step 与降采样计算结果
duration 参数决定了 PromQL 计算时的 vector 的”长度“,而 step 参数决定了 vector 的”步进“。如果用户是在 grafana 上查询,step 参数实际上是由 grafana 根据页面宽度和查询时间跨度来计算的,以我个人电脑为例,时间跨度 15 天时默认的 step 是 10 分钟。对于某些算子,因为采样点密度下降,step 也可能引起计算结果的跳变,下面以 increase 为例简单分析一下。
正常情况下(采样点均匀,无 counter 重置),increase 的计算公式可以简化为(尾值 - 首值)x duration /(尾时间戳 - 首时间戳),对于一般的场景来说,首/尾点与起/止时间的间隔,不会超过 scrape interval,如果 duration 比 scrape interval 大很多,结果约等于(尾值 - 首值)。假设有一组降采样后的 counter 数据点,如下:
sample1: t = 00:00:01 v=1
sample2: t = 00:59:31 v=1
sample3: t = 01:00:01 v=30
sample4: t = 01:59:31 v=31
sample5: t = 02:00:01 v=31
sample6: t = 02:59:31 v=32
...
假设查询 duration 为两小时,step 为 10 分钟,那么我们将会得到分割后的 vector,如下:
slice 1: 起止时间 00:00:00 / 02:00:00 [sample1 ... sample4]
slice 2: 起止时间 00:10:00 / 02:10:00 [sample2 ... sample5]
slice 3: 起止时间 00:20:00 / 02:20:00 [sample2 ... sample5]
...
原始数据中,首尾点与起止时间的间隔,不会超过 scrape interval,而降采样之后的数据,首尾点与起止时间的间隔最大可以达到(duration - step)。如果采样点值变化比较平缓,那么降采样后的计算结果与原始数据计算结果不会有较大差别,但是如果某个 slice 区间中值的变化比较剧烈,那么按照上述计算公式(尾值 - 首值)x duration /(尾时间戳 - 首时间戳),会将这种变动等比放大,让最终展示的曲线起伏更剧烈。这种结果我们认为是正常情况,同时在指标变动剧烈(fast-moving counter)的场景下,irate 会更适用一些,这也和官方文档的建议是一致的。
算子与降采样计算结果
有些算子的计算结果与 samples 数量直接相关,最典型的是 count_over_time ,统计时间区间内 samples 数量,而降采样本身就是要缩减时间区间内的点数,所以这种情况需要在 Prometheus engine 中做特殊处理,当发现取用的是降采样数据时,走新的计算逻辑来保证结果的正确。
降采样效果对比
对于用户来说,最终感受到的就是查询速度的提升,但这个提升幅度有多大,我们也通过两个查询实地验证对比下。
测试集群有 55 个 node,共有 pod 6000+,每天上报采样点总数约 100 亿,数据存储周期 15 天。
第一轮比对:查询效率
查询语句:
sum(irate(node_network_receive_bytes_total{}[5m])*8) by (instance)
即查询集群内各个 node 接收到的网络流量情况,查询周期为 15 天。
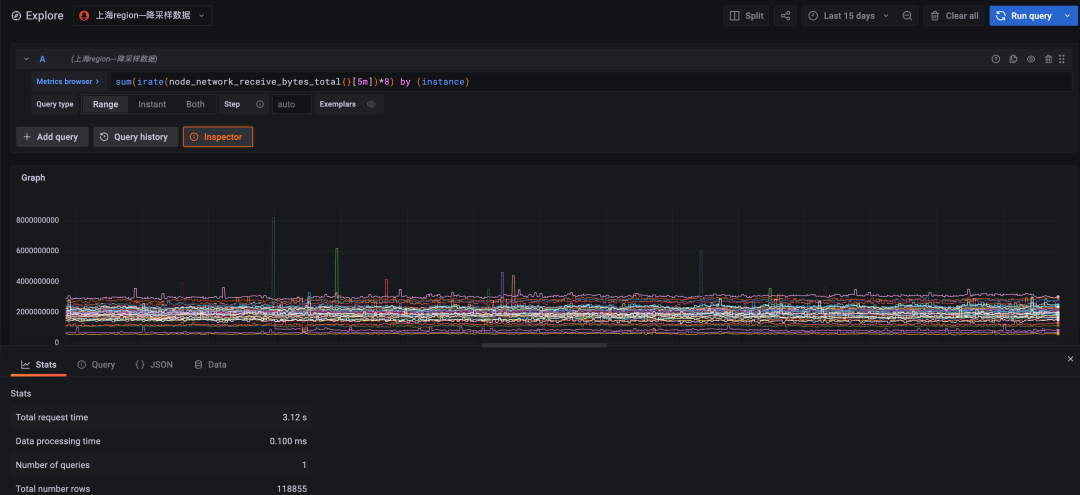
图 1:降采样数据查询,时间跨度十五天,查询耗时 3.12 秒
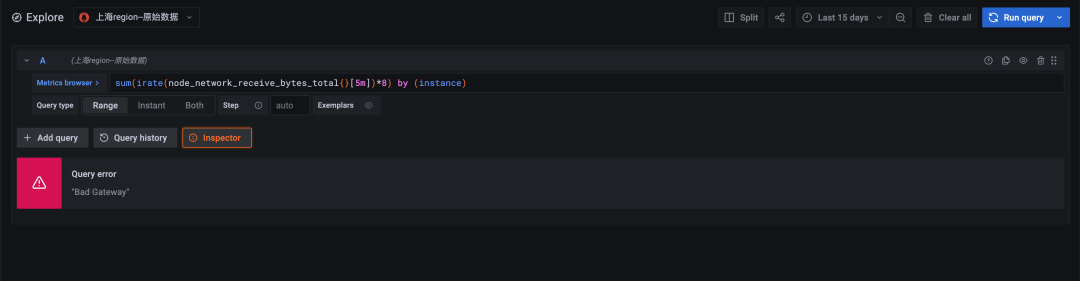
图 2:原始数据查询,时间跨度十五天,查询超时(超时时间 30 秒)
原始数据因为数据量过大计算超时,未能返回。降采样查询在效率上至少是原始查询的十倍以上。
第二轮比对:结果准确性
查询语句:
max(irate(node_network_receive_bytes_total{}[5m])*8) by (instance)
即查询各 node 上,接收数据量最大的网卡的流量数据。
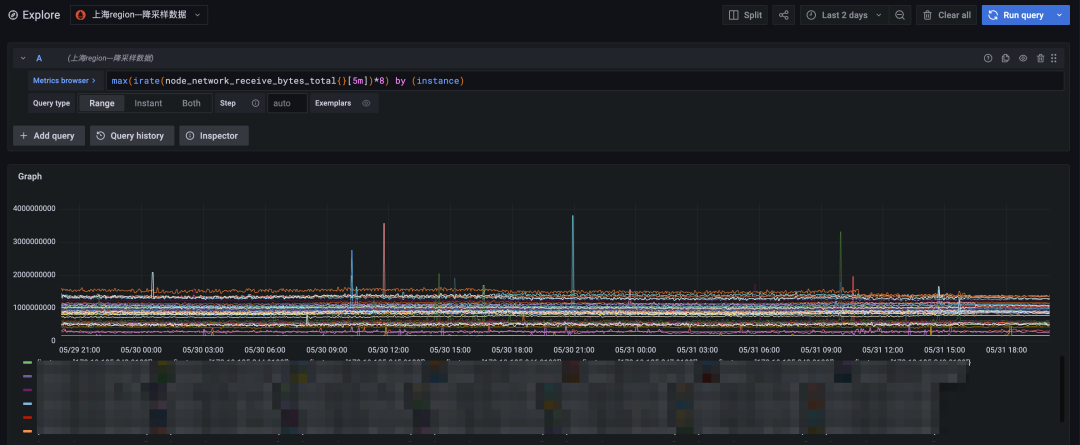
图 3:降采样查询,时间跨度两天
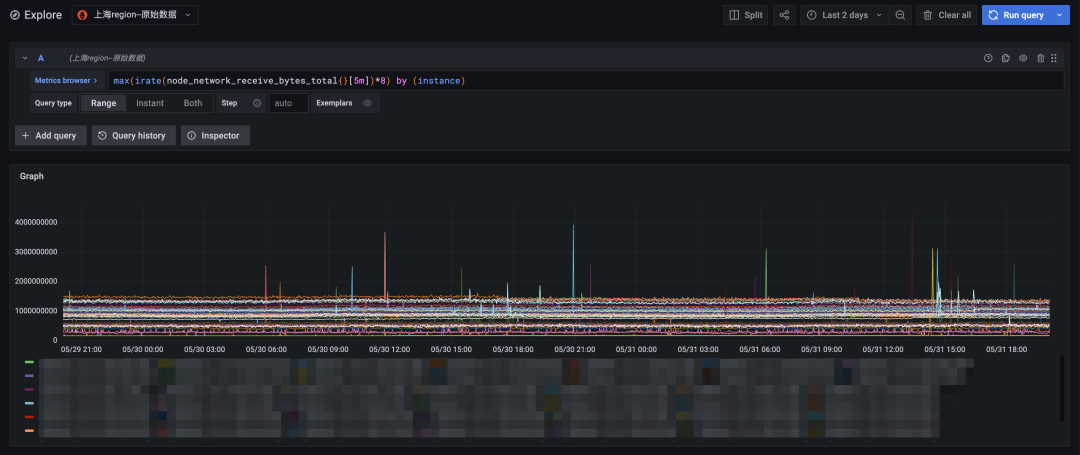
图 4:原始数据查询,时间跨度两天
最终我们将查询时间跨度缩短到两天,原始数据查询也能较快的返回。对比降采样查询结果(上图)和原始数据查询结果(下图)可见,二者时间线数量和总体趋势完全一致,数据变动比较剧烈的点也能很好的契合上,完全能够满足长时间周期查询的需求。
结语
阿里云于 6 月 22 日正式发布阿里云可观测套件(Alibaba Cloud Observability Suite,ACOS)。阿里云可观测套件围绕 Prometheus 服务、Grafana 服务和链路追踪服务, 形成指标存储分析、链路存储分析、异构构数据源集成的可观测数据层,同时通过标准的 PromQL 和 SQL,提供数据大盘展示,告警和数据探索能力。为IT成本管理、企业风险治理、智能运维、业务连续性保障等不同场景赋予数据价值,让可观测数据真正做到不止于观测。
其中,阿里云 Prometheus 监控针对多实例、大数据量、高时间线基数、长时间跨度、复杂查询等极端场景,逐步推出了全局聚合查询,流式查询,降采样,预聚合等多种针对性措施。
目前提供 15 天免费试用、Prometheus 监控容器集群基础指标费用减免等促销活动!
点击此处,开通服务~
可观测|时序数据降采样在Prometheus实践复盘的更多相关文章
- (数据科学学习手札99)掌握pandas中的时序数据分组运算
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在使用pandas分析处理时间序列数据 ...
- matlab读取多幅图片,并对读取的图片降采样和双三次插值
clear all clc im = {}; %%创建字典im以保存读取的图片 dis = dir('C:\Users\KCl\Documents\MATLAB\SRCNN\Set5\*.bmp'); ...
- Twitter基于R语言的时序数据突变检测(BreakoutDetection)
Twitter开源的时序数据突变检测(BreakoutDetection),基于无参的E-Divisive with Medians (EDM)算法,比传统的E-Divisive算法快3.5倍以上,并 ...
- 使用PostgreSQL存储时序数据
操作系统 :CentOS7.3.1611_x64 PostgreSQL版本 :9.6 问题描述 在InfluxDB中存储时序数据时,当tag值和时间戳都相同时会执行覆盖操作.在PostgreSQL中能 ...
- 应用层级时空记忆模型(HTM)实现对实时异常流时序数据检测
应用层级时空记忆模型(HTM)实现对实时异常流时序数据检测 Real-Time Anomaly Detection for Streaming Analytics Subutai Ahmad SAHM ...
- 机器学习入门-数据过采样(上采样)1. SMOTE
from imblearn.over_sampling import SMOTE # 导入 overstamp = SMOTE(random_state=0) # 对训练集的数据进行上采样,测试集的 ...
- 图像的降采样与升采样(二维插值)----转自LOFTER-gengjiwen
图像的降采样与升采样(二维插值) 1.先说说这两个词的概念: 降采样,即是采样点数减少.对于一幅N*M的图像来说,如果降采样系数为k,则即是在原图中 每行每列每隔k个点取一个点组成一幅图像.降采样很容 ...
- 【代码备份】原图降采样后进行NLM滤波
文件路径: 滤波算法main.m: %% 测试函数 %NLM滤波及滤波与 clc,clear all,close all; ima_ori=double(imread('F:\Users\****n\ ...
- upsampling(上采样)& downsampled(降采样)
缩小图像 缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的是两个: 使得图像符合显示区域的大小: 生成对应图像的缩略图: 下采样的原理: 对于一幅图像尺寸为 ...
- 图像上采样(图像插值)增取样(Upsampling)或内插(Interpolating)下采样(降采样),
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1.使得图像符合显示区域的大小:2.生成对应图像的缩略图.放大图像(或称为上采样(upsamplin ...
随机推荐
- 基于BES2500芯片的低功耗蓝牙BLE游戏手柄解决方案源码解析
一 往事 寒冬腊月,在一个寂静的天空飘着碎银雪花的夜晚.我接到这么一个电话:"朋友,能否帮忙开发一个游戏手柄的案子?我们遇到了一些问题,迟迟无法解决.",喔,这边我陷入了沉思 ...
- display标签简介
下面是网友总结的display标签的优缺点: 1. 分页 如果想对代码分页,只需在display:table标签中添加一项pagesize="每页显示行数" 2. 对列排序 dis ...
- demo介绍:uni-app统合--各类大转盘demo介绍
这里给大家介绍下我做的一个uni-app的demo:抽奖系统 废话不多说直接上效果图: 线上案例: 首页: 大转盘抽奖页面: 轮播机抽奖页面: 九宫格抽奖页面: 翻牌抽奖页面: 奖品列表页面: 抽奖的 ...
- 使用vott对车牌位置进行标注
1.软件安装 vott 下载地址 https://github.com/microsoft/VoTT/releases 双击vott-2.2.0-win32.exe安装标注软件,安装成功后桌面会生成应 ...
- 攻防世界 gametime 使用IDA pro+OD动调
自学犟种琢磨动调的一个记录,算是第一次动调的新手向,大佬请飘过 题目 准备工作--IDA pro(32X) 下载得到一个exe文件,首先丢到PE里面--无壳,32bit 丢到IDA pro(x32)里 ...
- 存储过程 RETURN语句
1.RETURN 如果没有使用表达式,RETURN 命令用于告诉这个函数已经完成执行了,如示例2. 如果返回标量类型,那么可以使用任何表达式. 示例1: 带有表达式return CREATE OR R ...
- 微服务集成Spring Cloud Alibaba Seata (二) 客户端连接
通过上篇文章后我们的Seata服务就部署成功了,如果还不清楚怎么部署或者还没有部署Seata服务的朋友可以看我写的上篇文章进行服务部署.Seata部署步骤:https://www.cnblogs.co ...
- 20 JavaScript和HTML交互
20 JavaScript和HTML交互 在HTML中可以直接在标签上给出一些事件的触发. 例如, 页面上的一个按钮. <input type="button" value= ...
- #虚树,树形dp#洛谷 3233 [HNOI2014]世界树
题目 分析 考虑建一棵虚树,倍增找到虚树上相邻两个点的中间点统计答案 记录每个虚树点最近的距离以及编号最小的点,主要是细节问题 代码 #include <cstdio> #include ...
- 天气数据爬取+pyechart可视化
数据爬取/处理 爬取深圳2021年全年的天气历史数据. 网址链接:https://lishi.tianqi.com/shenzhen/ 代码: import requests from lxml im ...