阿里巴巴大规模应用Flink的踩坑经验:如何大幅降低 HDFS 压力?
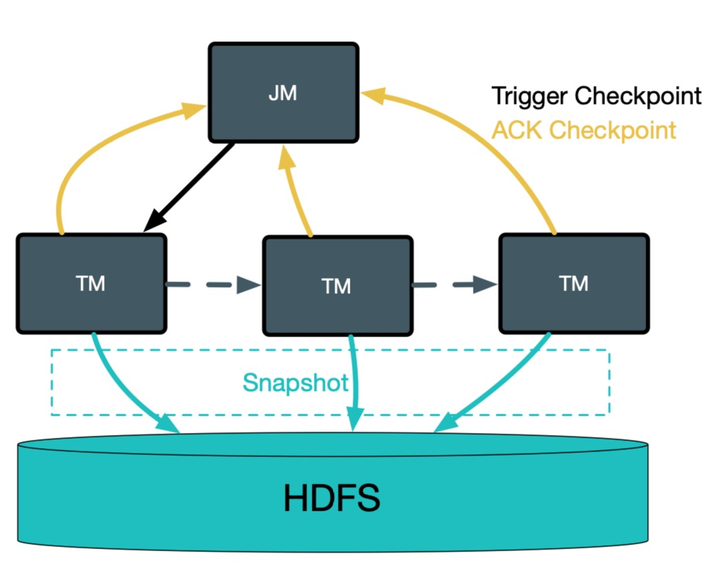
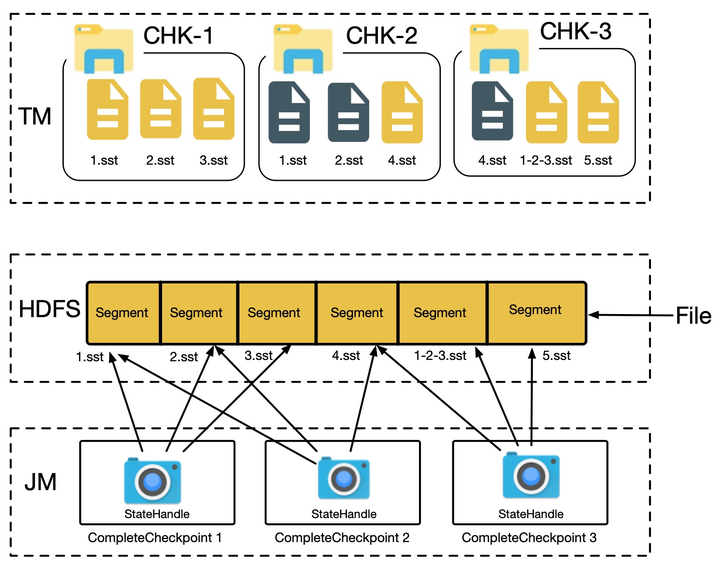
- 并发 checkpoint 的支持 Flink 天生支持并发 checkpoint,小文件合并方案则会将多个文件写往同一个分布式存储文件中,如果考虑不当,数据会写串或者损坏,因此我们需要有一种机制保证该方案的正确性,详细描述参考 2.1 节
- 防止误删文件 我们使用引用计数来记录文件的使用情况,仅通过文件引用计数是否降为 0 进行判断删除,则可能误删文件,如何保证文件不会被错误删除,我们将会在 2.2 节进行阐述
- 降低空间放大 使用小文件合并之后,只要文件中还有一个 statehandle 被使用,整个分布式文件就不能被删除,因此会占用更多的空间,我们在 2.3 节描述了解决该问题的详细方案
- 异常处理 我们将在 2.4 节阐述如何处理异常情况,包括 JM 异常和 TM 异常的情况
- 2.5 节中会详细描述在 Checkpoint 被取消或者失败后,如何取消 TM 端的 Snapshot,如果不取消 TM 端的 Snapshot,则会导致 TM 端实际运行的 Snapshot 比正常的多
- TM 端 barrier 对齐
- TM Snapshot 同步操作
- TM Snapshot 异步操作
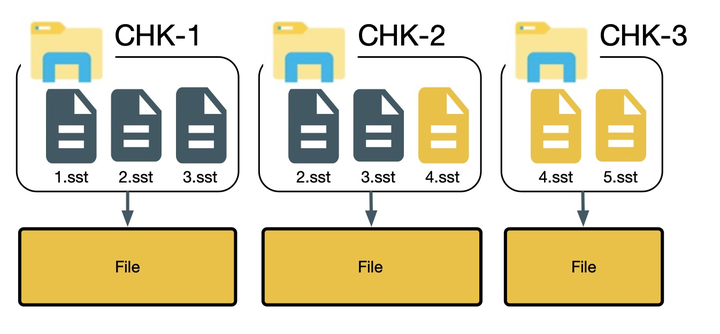
- 计算每个文件的放大率
- 如果放大率较小则直接跳到步骤 7
- 如果文件 A 的放大率超过阈值,则生成一个对应的新文件 A‘(如果这个过程中创建文件失败,则由 TM 负责清理工作)
- 记录 A 与 A’ 的映射关系
- 在下一次 checkpoint X 往 JM 发送落在文件 A 中的 StateHandle 时,则使用 A` 中的信息生成一个新的 StateHandle 发送给 JM
- checkpoint X 完成后,我们增加 A‘ 的引用计数,减少 A 的引用计数,在引用计数降为 0 后将文件 A 删除(如果 JM 增加了 A’ 的引用,然后出现异常,则会从上次成功的 checkpoint 重新构建整个引用计数器)
- 文件压缩完成
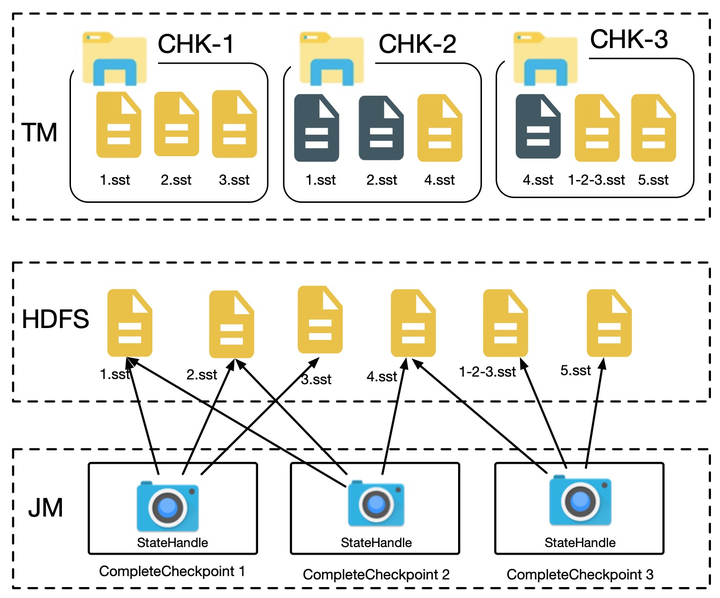
- 文件已经汇报过给 JM 文件汇报过给 JM,因此在 JM 端有文件的引用计数,文件的删除由 JM 控制,当文件的引用计数变为 0 之后,JM 将删除该文件。
- 文件尚未汇报给 JM 该文件暂时尚未汇报过给 JM,该文件不再被使用,也不会被 JM 感知,成为孤儿文件。这种情况暂时有外围工具统一进行清理。
- 每个 TM 分到自己需要 restore 的 state handle
- TM 从远程下载 state handle 对应的数据
- 从本地进行恢复
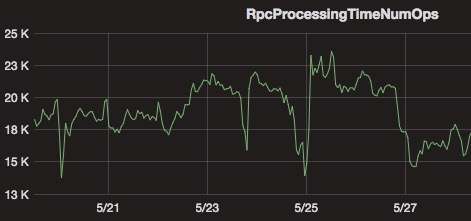
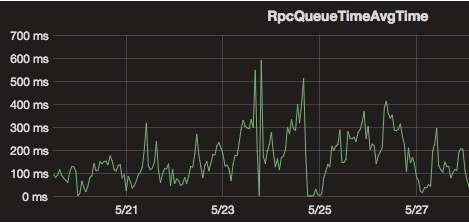
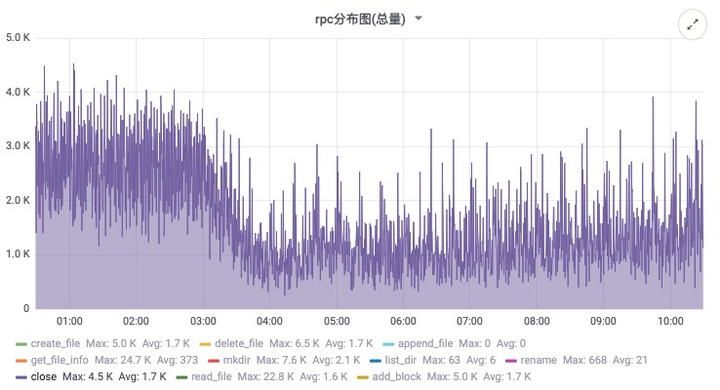
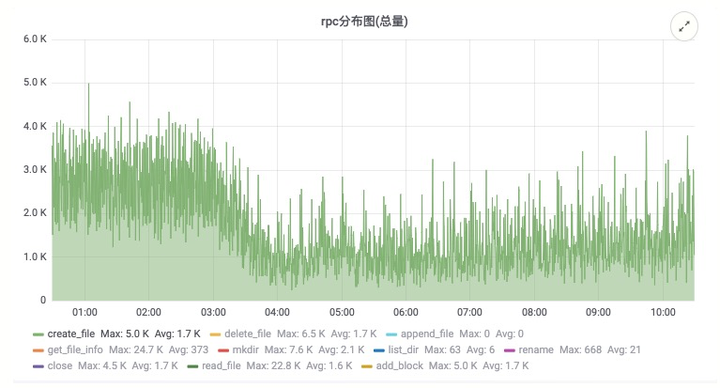
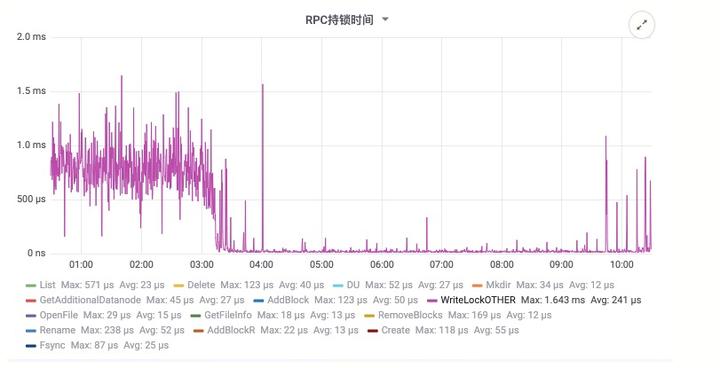
- 优势:大幅度降低 HDFS 的压力:包括 RPC 压力以及 NameNode 内存的压力
- 不足:不支持 State 多线程上传的功能(State 上传暂时不是 checkpoint 的瓶颈)
阿里巴巴大规模应用Flink的踩坑经验:如何大幅降低 HDFS 压力?的更多相关文章
- 程序员的踩坑经验总结(一):如何把Bug的偶现变必现
程序员的踩过的坑也是可以分类的,很常见又很难解决的一类是偶然的现象,表现起来比较怪异. 而把一个问题Bug的偶现变成必现,是开发人员的一种能力.我认为也应该是测试人员的一种能力,但是各个公司要求不一样 ...
- 微信jssdk批量添加卡券接口(踩坑经验)
1)首先是官方接口文档: 1.批量添加卡券接口:https://mp.weixin.qq.com/wiki?action=doc&id=mp1421141115&t=0.0861973 ...
- SpringCloud整合过程中jar依赖踩坑经验
今天在搭建SpringCloud Eureka过程中,一直在报pom依赖错误,排查问题总结如下经验. 1.SpringBoot整合SpringCloud两者版本是有严格约束的,详细见SpringBoo ...
- TensorFlow保存、加载模型参数 | 原理描述及踩坑经验总结
写在前面 我之前使用的LSTM计算单元是根据其前向传播的计算公式手动实现的,这两天想要和TensorFlow自带的tf.nn.rnn_cell.BasicLSTMCell()比较一下,看看哪个训练速度 ...
- 踩坑经验总结之go web开源库第一次编译构建
前言:记录一个go新手第一次构建复杂开源库的经历.go虽然是新手,但是编程上还是有多年的经验,除了c/c++,用过IDEA能进行简单的java编程.甚至scala编程.所以最开始还是有点信心的.所以也 ...
- 攻城记:Thinkphp框架的项目规划总结和踩坑经验
一.项目模块规划 1.项目分为PC端.移动端.和PC管理端,分为对应目录为 /Application/Home,/Application/Mobile,/Application/Admin: 对应入口 ...
- Nodejs 8.0 踩坑经验汇总
.Linq:Linq to sql 类 高度集成化的数据库访问技术 使用Linq是应该注意的问题: 1.创建Linq连接后生成的dbml文件不要变动,生成的表不要碰,拖动表也会造成数据库连接发生变动, ...
- 【转】Thinkphp框架的项目规划总结和踩坑经验
http://www.360doc.com/content/16/1206/22/466494_612576533.shtml
- html2canvas以及domtoimage的使用踩坑总结
前言 首先做个自我介绍,我是成都某企业的一名刚刚入行约一年的前端,在之前的开发过程中,遇到了问题,也解决了问题,但是在下一次解决相同问题的时候,只对这个问题有一丝丝的印象,还需要从新去查找,于是,我注 ...
- Abp vnext EFCore 实现动态上下文DbSet踩坑记
背景 我们在用EFCore框架操作数据库的时候,我们会遇到在 xxDbContext 中要写大量的上下文 DbSet<>; 那我们表少还可以接受,表多的时候每张表都要写一个DbSet, 大 ...
随机推荐
- AOSP源码编译—交换空间扩容
编译AOSP源码的时候会出现提示如下: 意思是需要16G左右的内存(实际上编译会超过16G),而我们之前安装Ubuntu的时候只分配了8G,编 译一定会失败!此时需要添加虚拟内存(swap交换空间) ...
- slf4j 和 log4j2 架构设计
1.日志框架背景 2.为什么会有 slf4j 和 log4j2 搭配一说? 3.log4j2 3.1.背景及应用场景 3.2.功能模块 4.slf4j 4.1.背景及应用场景 4.2.功能模块 5.s ...
- [pyplot]在同一画面上绘制不同大小的多个图像
一.背景 做计算机应用数学作业时要求使用matplotlib库在同一张图上绘制两个图像,但是这两个图像的大小不同,百度之后发现大部分只是转载的同一篇博客,而且只能实现部分子图比例排版,并不能随意设置各 ...
- FreeRTOS教程6 互斥量
1.准备材料 正点原子stm32f407探索者开发板V2.4 STM32CubeMX软件(Version 6.10.0) Keil µVision5 IDE(MDK-Arm) 野火DAP仿真器 XCO ...
- MySQL(表相关操作)
一 存储引擎 日常生活中文件格式有很多,并且针对不同的文件格式会有对应不同存储方式 和处理机制(txt.word) 针对不同的数据应该有对应的不同的处理机制来存储 存储引擎就是不同的处理机制 MySQ ...
- 介绍几款WPF应用的UI库
在WPF中对于前端页面的书写,我们有现成的UI类库,不需要我们自己再去写 我这里介绍几款 1.MahApps 官网 https://mahapps.com/ 使用,在App.xaml中添加 <A ...
- 美团一面:说一说Java中的四种引用类型?
引言 在JDK1.2之前Java并没有提供软引用.弱引用和虚引用这些高级的引用类型.而是提供了一种基本的引用类型,称为Reference.并且当时Java中的对象只有两种状态:被引用和未被引用.当一个 ...
- ssm整合简单配置
最近由于系统重装,之前已经写好了的框架都被我删的一干二净,于是自己动手重新搭了个简单的ssm(spring springmvc mybatis) 运行环境 (java1.8,Tomcat8.5,mav ...
- 马文·柯林斯的教育之道 「Marva Collins' Way」 阅读笔记
<马文·柯林斯的教育之道> 是 哈佛幸福课(积极心理学) 中强列推荐的一本书 这本书主写的是 马文·柯林斯 的成长经历已经和教育理念,仅看介绍,会误认为这本书只是在说鼓励式的教学理念,看完 ...
- Oracle查询表空间信息
记录一下 SELECT UPPER(F.TABLESPACE_NAME) "表空间名", D.TOT_GROOTTE_MB "表空间大小(M)", D.TOT_ ...