云小课 | 大数据融合分析:GaussDW(DWS)轻松导入MRS-Hive数据源
摘要:通过建立GaussDB(DWS)与MRS的连接,支持数据仓库服务SQL on Hadoop,以外表方式实现Hive数据的快捷导入,满足大数据融合分析的应用场景。
本文分享自华为云社区《【云小课】EI第17课 大数据融合分析:GaussDB(DWS)轻松导入MRS-Hive数据源》,原文作者:Hi,EI 。

大数据融合分析时代,GaussDB(DWS)如需访问MRS数据源,该如何实现?本期云小课带您开启MRS数据源之门,通过远程读取MRS集群Hive上的ORC数据表完成数据导入DWS。
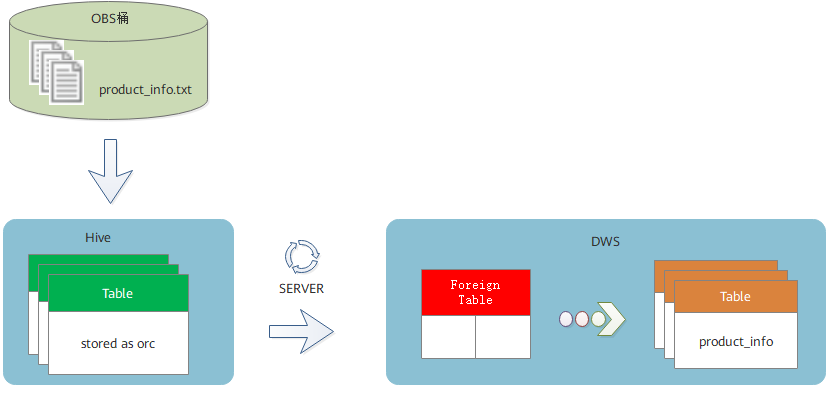
准备环境
已创建DWS集群,需确保MRS和DWS集群在同一个区域、可用区、同一VPC子网内,确保集群网络互通。
基本流程
本实践预计时长:1小时,基本流程如下:
1、创建MRS分析集群(选择Hive、Spark、Tez组件)。
2、通过将本地txt数据文件上传至OBS桶,再通过OBS桶导入Hive,并由txt存储表导入ORC存储表。
3、创建MRS数据源连接。
4、创建外部服务器。
5、创建外表。
6、通过外表导入DWS本地表。
一、创建MRS分析集群
1、登录华为云控制台,选择“EI企业智能 > MapReduce服务”,单击“购买集群”,选择“自定义购买”,填写软件配置参数,单击“下一步”。

2、填写硬件配置参数,单击“下一步”。
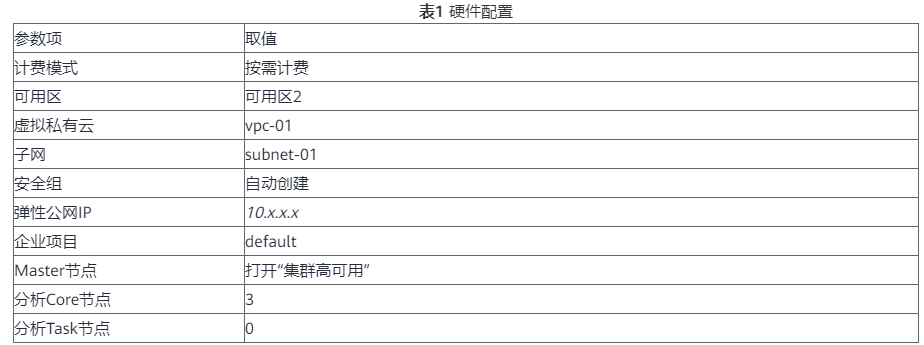
3、填写高级配置参数如下表,单击“立即购买”,等待约15分钟,集群创建成功。

二、准备MRS的ORC表数据源
1、本地PC新建一个product_info.txt,并拷贝以下数据,保存到本地。
100,XHDK-A-1293-#fJ3,2017-09-01,A,2017 Autumn New Shirt Women,red,M,328,2017-09-04,715,good
205,KDKE-B-9947-#kL5,2017-09-01,A,2017 Autumn New Knitwear Women,pink,L,584,2017-09-05,406,very good!
300,JODL-X-1937-#pV7,2017-09-01,A,2017 autumn new T-shirt men,red,XL,1245,2017-09-03,502,Bad.
310,QQPX-R-3956-#aD8,2017-09-02,B,2017 autumn new jacket women,red,L,411,2017-09-05,436,It's really super nice
150,ABEF-C-1820-#mC6,2017-09-03,B,2017 Autumn New Jeans Women,blue,M,1223,2017-09-06,1200,The seller's packaging is exquisite
200,BCQP-E-2365-#qE4,2017-09-04,B,2017 autumn new casual pants men,black,L,997,2017-09-10,301,The clothes are of good quality.
250,EABE-D-1476-#oB1,2017-09-10,A,2017 autumn new dress women,black,S,841,2017-09-15,299,Follow the store for a long time.
108,CDXK-F-1527-#pL2,2017-09-11,A,2017 autumn new dress women,red,M,85,2017-09-14,22,It's really amazing to buy
450,MMCE-H-4728-#nP9,2017-09-11,A,2017 autumn new jacket women,white,M,114,2017-09-14,22,Open the package and the clothes have no odor
260,OCDA-G-2817-#bD3,2017-09-12,B,2017 autumn new woolen coat women,red,L,2004,2017-09-15,826,Very favorite clothes
980,ZKDS-J-5490-#cW4,2017-09-13,B,2017 Autumn New Women's Cotton Clothing,red,M,112,2017-09-16,219,The clothes are small
98,FKQB-I-2564-#dA5,2017-09-15,B,2017 autumn new shoes men,green,M,4345,2017-09-18,5473,The clothes are thick and it's better this winter.
150,DMQY-K-6579-#eS6,2017-09-21,A,2017 autumn new underwear men,yellow,37,2840,2017-09-25,5831,This price is very cost effective
200,GKLW-l-2897-#wQ7,2017-09-22,A,2017 Autumn New Jeans Men,blue,39,5879,2017-09-25,7200,The clothes are very comfortable to wear
300,HWEC-L-2531-#xP8,2017-09-23,A,2017 autumn new shoes women,brown,M,403,2017-09-26,607,good
100,IQPD-M-3214-#yQ1,2017-09-24,B,2017 Autumn New Wide Leg Pants Women,black,M,3045,2017-09-27,5021,very good.
350,LPEC-N-4572-#zX2,2017-09-25,B,2017 Autumn New Underwear Women,red,M,239,2017-09-28,407,The seller's service is very good
110,NQAB-O-3768-#sM3,2017-09-26,B,2017 autumn new underwear women,red,S,6089,2017-09-29,7021,The color is very good
210,HWNB-P-7879-#tN4,2017-09-27,B,2017 autumn new underwear women,red,L,3201,2017-09-30,4059,I like it very much and the quality is good.
230,JKHU-Q-8865-#uO5,2017-09-29,C,2017 Autumn New Clothes with Chiffon Shirt,black,M,2056,2017-10-02,3842,very good
2、登录OBS控制台,单击“创建桶”,填写以下参数,单击“立即创建”。

3、等待桶创建好,单击桶名称,选择“对象 > 上传对象”,将product_info.txt上传至OBS桶。
4、切换回MRS控制台,单击创建好的MRS集群名称,进入“概览”,单击“IAM用户同步”所在行的“单击同步”,等待约5分钟同步完成。
5、回到MRS集群页面,单击“节点管理”,单击任意一台master节点,进入该节点页面,切换到“弹性公网IP”,单击“绑定弹性公网IP”,勾选已有弹性IP并单击“确定”,如果没有,请创建。记录此公网IP。
6、确认主master节点。
- 使用SSH工具以root用户登录以上节点,root密码为Huawei_12345,切换到omm用户。
- su - omm
- 执行以下命令查询主master节点,回显信息中“HAActive”参数值为“active”的节点为主master节点。
- sh ${BIGDATA_HOME}/om-0.0.1/sbin/status-oms.sh
7、使用root用户登录主master节点,切换到omm用户,并进入Hive客户端所在目录。
- su - omm
- cd /opt/client
8、在Hive上创建存储类型为TEXTFILE的表product_info。
- 在/opt/client路径下,导入环境变量。
- source bigdata_env
- 登录Hive客户端。
- beeline
- 依次执行以下SQL语句创建demo数据库及表product_info。
CREATE DATABASE demo;
USE demo;
DROP TABLE product_info;
CREATE TABLE product_info
(
product_price int not null,
product_id char(30) not null,
product_time date ,
product_level char(10) ,
product_name varchar(200) ,
product_type1 varchar(20) ,
product_type2 char(10) ,
product_monthly_sales_cnt int ,
product_comment_time date ,
product_comment_num int ,
product_comment_content varchar(200)
)
row format delimited fields terminated by ','
stored as TEXTFILE
9、将product_info.txt数据文件导入Hive。
- 切回到MRS集群,单击“文件管理”,单击“导入数据”。
- OBS路径:选择上面创建好的OBS桶名,找到product_info.txt文件,单击“是”。
- HDFS路径:选择/user/hive/warehouse/demo.db/product_info/,单击“是”。
- 单击“确定”,等待导入成功,此时product_info的表数据已导入成功。
10、创建ORC表,并将数据导入ORC表。
- 执行以下SQL语句创建ORC表。
DROP TABLE product_info_orc;
CREATE TABLE product_info_orc
(
product_price int not null,
product_id char(30) not null,
product_time date ,
product_level char(10) ,
product_name varchar(200) ,
product_type1 varchar(20) ,
product_type2 char(10) ,
product_monthly_sales_cnt int ,
product_comment_time date ,
product_comment_num int ,
product_comment_content varchar(200)
)
row format delimited fields terminated by ','
stored as orc;
- 将product_info表的数据插入到Hive ORC表product_info_orc中。
insert into product_info_orc select * from product_info;
- 查询ORC表数据导入成功。
select * from product_info_orc;
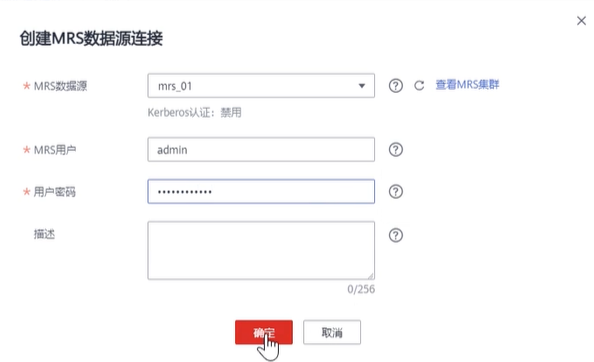
三、创建MRS数据源连接
- 登录DWS管理控制台,单击已创建好的DWS集群,确保DWS集群与MRS在同一个区域、可用分区,并且在同一VPC子网下。
- 切换到“MRS数据源”,单击“创建MRS数据源连接”。
- 选择前序步骤创建名为的“MRS01”数据源,用户名:admin,密码:Huawei@12345,单击“确定”,创建成功。
四、创建外部服务器
- (1)使用Data Studio连接已创建好的DWS集群。
- (2)新建一个具有创建数据库权限的用户dbuser:
CREATE USER dbuser WITH CREATEDB PASSWORD "Bigdata@123";
- (3)切换为新建的dbuser用户:
SET ROLE dbuser PASSWORD "Bigdata@123";
- (4)创建新的mydatabase数据库:
CREATE DATABASE mydatabase;
- (5)执行以下步骤切换为连接新建的mydatabase数据库。
- 在Data Studio客户端的“对象浏览器”窗口,右键单击数据库连接名称,在弹出菜单中单击“刷新”,刷新后就可以看到新建的数据库。
- 右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开连接”。
- 右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开新的终端”,即可打开连接到指定数据库的SQL命令窗口,后面的步骤,请全部在该命令窗口中执行。
- (6)为dbuser用户授予创建外部服务器的权限:
GRANT ALL ON FOREIGN DATA WRAPPER hdfs_fdw TO dbuser;
其中FOREIGN DATA WRAPPER的名字只能是hdfs_fdw,dbuser为创建SERVER的用户名。
- (7)执行以下命令赋予用户使用外表的权限。
ALTER USER dbuser USEFT;
- (8)切换回Postgres系统数据库,查询创建MRS数据源后系统自动创建的外部服务器。
SELECT * FROM pg_foreign_server;
返回结果如:
srvname | srvowner | srvfdw | srvtype | srvversion | srvacl | srvoptions
--------------------------------------------------+----------+--------+---------+------------+--------+---------------------------------------------------------------------------------------------------------------------
gsmpp_server | 10 | 13673 | | | |
gsmpp_errorinfo_server | 10 | 13678 | | | |
hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:9820",hdfscfgpath=/MRS/8f79ada0-d998-4026-9020-80d6de2692ca,type=hdfs}
(3 rows)
- (9)切换到mydatabase数据库,并切换到dbuser用户。
SET ROLE dbuser PASSWORD "Bigdata@123";
- (10)创建外部服务器。
SERVER名字、地址、配置路径保持与8一致即可。
CREATE SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca FOREIGN DATA WRAPPER HDFS_FDW
OPTIONS
(
address '192.168.1.245:9820,192.168.1.218:9820', //MRS管理面的Master主备节点的内网IP,可与DWS通讯。
hdfscfgpath '/MRS/8f79ada0-d998-4026-9020-80d6de2692ca',
type 'hdfs'
);
- (11)查看外部服务器。
SELECT * FROM pg_foreign_server WHERE srvname='hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca';
返回结果如下所示,表示已经创建成功:
srvname | srvowner | srvfdw | srvtype | srvversion | srvacl | srvoptions
--------------------------------------------------+----------+--------+---------+------------+--------+---------------------------------------------------------------------------------------------------------------------
hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:29820",hdfscfgpath=/MRS/8f79ada0-d998-4026-9020-80d6de2692ca,type=hdfs}
(1 row)
五、创建外表
1、获取Hive的product_info_orc的文件路径。
- 登录MRS管理控制台。
- 选择“集群列表 > 现有集群”,单击要查看的集群名称,进入集群基本信息页面。
- 单击“文件管理”,选择“HDFS文件列表”。
- 进入您要导入到GaussDB(DWS)集群的数据的存储目录,并记录其路径。
图1 在MRS上查看数据存储路径

2、创建外表。 SERVER名字填写10创建的外部服务器名称,foldername填写1查到的路径。
DROP FOREIGN TABLE IF EXISTS foreign_product_info;
CREATE FOREIGN TABLE foreign_product_info
(
product_price integer not null,
product_id char(30) not null,
product_time date ,
product_level char(10) ,
product_name varchar(200) ,
product_type1 varchar(20) ,
product_type2 char(10) ,
product_monthly_sales_cnt integer ,
product_comment_time date ,
product_comment_num integer ,
product_comment_content varchar(200)
) SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca
OPTIONS (
format 'orc',
encoding 'utf8',
foldername '/user/hive/warehouse/demo.db/product_info_orc/'
)
DISTRIBUTE BY ROUNDROBIN;
六、执行数据导入
1、创建本地目标表。
DROP TABLE IF EXISTS product_info;
CREATE TABLE product_info
(
product_price integer not null,
product_id char(30) not null,
product_time date ,
product_level char(10) ,
product_name varchar(200) ,
product_type1 varchar(20) ,
product_type2 char(10) ,
product_monthly_sales_cnt integer ,
product_comment_time date ,
product_comment_num integer ,
product_comment_content varchar(200)
)
with (
orientation = column,
compression=middle
)
DISTRIBUTE BY HASH (product_id);
2、从外表导入目标表。
INSERT INTO product_info SELECT * FROM foreign_product_info;
3、查询导入结果。
SELECT * FROM product_info;
那么,实践一下,教您快速上手数据仓库服务~
详情请戳这里了解。
云小课 | 大数据融合分析:GaussDW(DWS)轻松导入MRS-Hive数据源的更多相关文章
- 云小课|DGC数据开发之基础入门篇
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:欢迎来到DGC数据 ...
- 云小课|MRS数据分析-通过Spark Streaming作业消费Kafka数据
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:Spark Str ...
- 云小课|MRS基础原理之MapReduce介绍
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:MapReduce ...
- 云小课|云小课教您如何选择Redis实例类型
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:购买Redis实例 ...
- 阿里云资深DBA专家罗龙九:云数据库十大经典案例分析【转载】
阿里云资深DBA专家罗龙九:云数据库十大经典案例分析 2016-07-21 06:33 本文已获阿里云授权发布,转载具体要求见文末 摘要:本文根据阿里云资深DBA专家罗龙九在首届阿里巴巴在线峰会的&l ...
- 在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析
在HDInsight中从Hadoop的兼容BLOB存储查询大数据的分析 低成本的Blob存储是一个强大的.通用的Hadoop兼容Azure存储解决方式无缝集成HDInsight.通过Hadoop分布式 ...
- 云小课 | 搬迁本地数据至OBS,多种方式任你选
摘要:搬迁本地数据至OBS,包括OBS工具方式.CDM方式.DES磁盘方式.DES Teleport方式和云专线方式,每种方式特点不同,本节课我们就一起看看有什么区别. 已有的业务数据可能保存在本地的 ...
- 华为云BigData Pro解读: 鲲鹏云容器助力大数据破茧成蝶
华为云鲲鹏云容器 见证BigData Pro蝶变之旅大数据之路顺应人类科技的进步而诞生,一直顺风顺水,不到20年时间,已渗透到社会生产和人们生活的方方面面,.然而,伴随着信息量的指数级增长,大数据也开 ...
- 第二篇:智能电网(Smart Grid)中的数据工程与大数据案例分析
前言 上篇文章中讲到,在智能电网的控制与管理侧中,数据的分析和挖掘.可视化等工作属于核心环节.除此之外,二次侧中需要对数据进行采集,数据共享平台的搭建显然也涉及到数据的管理.那么在智能电网领域中,数据 ...
- 技术期刊 · 天光台高未百尺 | Uber 工程师的 JS 算法课;大数据时代的个人隐私;设计师的 Github;告别 PPT 工程师;从零开始实现的像素画
蒲公英 · JELLY技术期刊 Vol.42 这是一个最好的时代,多样化的平台给了所有人成长发展的机会,各种需求和解决需求的人让人大开眼界:但这也并不是完美的时代,"前端还需要懂什么算法?& ...
随机推荐
- Vue之自定义过滤器
使用Vue.filter('过滤器名称',方法); 1. <!DOCTYPE html> <html lang="en"> <head> < ...
- 如何通过Python代码旋转PDF页面
前言 日常处理 PDF 文档时,我们时常会遇到页面颠倒.很难正常阅读或打印的情况. 在这种情况下,我们可以通过旋转页面来调整文档的方向.旋转时,也可以根据具体情况,选择顺时针或逆时针旋转特定的角度,以 ...
- JAVA类的加载(2) ——按需加载(延迟加载)
1.例1: 1 /* 2 按需加载:当你不去实例化Cat时,Cat相关类都不会被加载,即按需加载(需要时加载) 3 1.先加载父类 4 2.初始化类 5 3.类只加载一次(暂且这么认为)--缓存 6 ...
- Keepalived+Nginx高可用案例(抢占式与非抢占式)
(1)下载安装Keepalived源码包 Keepalived官网源码包下载地址 在服务器上解压 tar -xf keepalived-2.2.8.tar.gz 安装相关前置依赖 yum -y ins ...
- C语言已知单链表LA=(a1,a2,…,am)和LB=(b1,b2,…,bn),编写程序按以下规则将它们合并成一个单链表LC,
LC=(a1,b1,-,am,bm,bm+1,-,bn),m<=n 或者 LC=(a1,b1,-,bn,an,an+1,-,am),m>n /* 开发者:慢蜗牛 开发时间:2020.6.1 ...
- Spring配置文件的魔法炼金术:如何制造容器化时代的完美配方
前言 基于现代服务的云原生十二要素理论,我们在采用容器化部署时,要保证同一个镜像可以满足不同环境的部署要求,而不是不同环境打包不同的镜像.本文档主要介绍一种基于spring框架的满足不同环境配置的编译 ...
- python中的post请求
用python来验证接口正确性,主要流程有4步: 1 设置url 2 设置消息头 3 设置消息体 4 获取响应 5 解析相应 6 验证数据 Content-Type的格式有四种:分别是applicat ...
- 循环返回结果结果集(connect 函数使用)
--示例: SELECT 0 + ROWNUM sonID FROM DUAL /*区间范围*/ CONNECT BY ROWNUM <= 20;
- [python][图像切割]给定手写数字图片完成数字切割
import torch import torch.nn as nn from torchvision import transforms from PIL import Image, ImageOp ...
- [ABC274G] Security Camera 3
Problem Statement There is a grid with $H$ rows from top to bottom and $W$ columns from left to righ ...