Materialize MySQL引擎:MySQL到Click House的高速公路
摘要: MySQL到ClickHouse数据同步原理及实践
引言
熟悉MySQL的朋友应该都知道,MySQL集群主从间数据同步机制十分完善。令人惊喜的是,ClickHouse作为近年来炙手可热的大数据分析引擎也可以挂载为MySQL的从库,作为MySQL的 "协处理器" 面向OLAP场景提供高效数据分析能力。早先的方案比较直截了当,通过第三方插件将所有MySQL上执行的操作进行转化,然后在ClickHouse端逐一回放达到数据同步。终于在2020年下半年,Yandex 公司在 ClickHouse 社区发布了MaterializeMySQL引擎,支持从MySQL全量及增量实时数据同步。MaterializeMySQL引擎目前支持 MySQL 5.6/5.7/8.0 版本,兼容 Delete/Update 语句,及大部分常用的 DDL 操作。
基础概念
- MySQL & ClickHouse
MySQL一般特指完整的MySQL RDBMS,是开源的关系型数据库管理系统,目前属于Oracle公司。MySQL凭借不断完善的功能以及活跃的开源社区,吸引了越来越多的企业和个人用户。
ClickHouse是由Yandex公司开源的面向OLAP场景的分布式列式数据库。ClickHouse具有实时查询,完整的DBMS及高效数据压缩,支持批量更新及高可用。此外,ClickHouse还较好地兼容SQL语法并拥有开箱即用等诸多优点。
- Row Store & Column Store
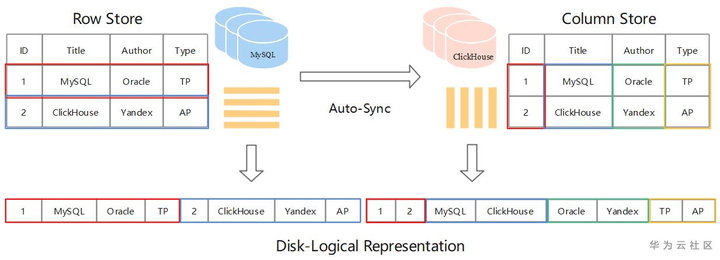
MySQL存储采用的是Row Store,表中数据按照 Row 为逻辑存储单元在存储介质中连续存储。这种存储方式适合随机的增删改查操作,对于按行查询较为友好。但如果选择查询的目标只涉及一行中少数几个属性,Row 存储方式也不得不将所有行全部遍历再筛选出目标属性,当表属性较多时查询效率通常较低。尽管索引以及缓存等优化方案在 OLTP 场景中能够提升一定的效率,但在面对海量数据背景的 OLAP 场景就显得有些力不从心了。
ClickHouse 则采用的是 Column Store,表中数据按照Column为逻辑存储单元在存储介质中连续存储。这种存储方式适合采用 SIMD (Single Instruction Multiple Data) 并发处理数据,尤其在表属性较多时查询效率明显提升。列存方式中物理相邻的数据类型通常相同,因此天然适合数据压缩从而达到极致的数据压缩比。
使用方法
- 部署Master-MySQL
开启BinLog功能:ROW模式
开启GTID模式:解决位点同步时MySQL主从切换问题(BinLog reset导致位点失效)
# my.cnf关键配置
gtid_mode=ON
enforce_gtid_consistency=1
binlog_format=ROW
- 部署Slave-ClickHouse
获取 ClickHouse/Master 代码编译安装
推荐使用GCC-10.2.0,CMake 3.15,ninja1.9.0及以上 - 创建Master-MySQL中database及table
creat databases master_db;
use master_db;
CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8; # 插入几条数据
INSERT INTO runoob_tbl (runoob_, runoob_author, submission_date) VALUES ("MySQL-learning", "Bob", NOW());
INSERT INTO runoob_tbl (runoob_, runoob_author, submission_date) VALUES ("MySQL-learning", "Tim", NOW());
- 创建 Slave-ClickHouse 中 MaterializeMySQL database
# 开启materialize同步功能
SET allow_experimental_database_materialize_mysql=1;
# 创建slave库,参数分别是("mysqld服务地址", "待同步库名", "授权账户", "密码")
CREATE DATABASE slave_db ENGINE = MaterializeMySQL('192.168.6.39:3306', 'master_db', 'root', '3306123456');
此时可以看到ClickHouse中已经有从MySQL中同步的数据了:
DESKTOP:) select * from runoob_tbl; SELECT *
FROM runoob_tbl Query id: 6e2b5f3b-0910-4d29-9192-1b985484d7e3 ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┐
│ 1 │ MySQL-learning │ Bob │ 2021-01-06 │
└───────────┴────────────────┴───────────────┴─────────────────┘
┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┐
│ 2 │ MySQL-learning │ Tim │ 2021-01-06 │
└───────────┴────────────────┴───────────────┴─────────────────┘
2 rows in set. Elapsed: 0.056 sec.
工作原理
- BinLog Event
MySQL中BinLog Event主要包含以下几类:
1. MYSQL_QUERY_EVENT -- DDL
2. MYSQL_WRITE_ROWS_EVENT -- insert
3. MYSQL_UPDATE_ROWS_EVENT -- update
4. MYSQL_DELETE_ROWS_EVENT -- delete
事务提交后,MySQL 将执行过的 SQL 处理 BinLog Event,并持久化到 BinLog 文件
ClickHouse通过消费BinLog达到数据同步,过程中主要考虑3个方面问题:
- DDL兼容:由于ClickHouse和MySQL的数据类型定义有区别,DDL语句需要做相应转换
- Delete/Update 支持:引入_version字段,控制版本信息
- Query 过滤:引入_sign字段,标记数据有效性
- DDL操作
对比一下MySQL的DDL语句以及在ClickHouse端执行的DDL语句:
mysql> show create table runoob_tbl\G;
*************************** 1. row ***************************
Table: runoob_tbl
Create Table: CREATE TABLE `runoob_tbl` (
`runoob_id` int unsigned NOT NULL AUTO_INCREMENT,
`runoob_` varchar(100) NOT NULL,
`runoob_author` varchar(40) NOT NULL,
`submission_date` date DEFAULT NULL,
PRIMARY KEY (`runoob_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
---------------------------------------------------------------
cat /metadata/slave_db/runoob_tbl.sql
ATTACH TABLE _ UUID '14dbff59-930e-4aa8-9f20-ccfddaf78077'
(
`runoob_id` UInt32,
`runoob_` String,
`runoob_author` String,
`submission_date` Nullable(Date),
`_sign` Int8 MATERIALIZED 1,
`_version` UInt64 MATERIALIZED 1
)
ENGINE = ReplacingMergeTree(_version)
PARTITION BY intDiv(runoob_id, 4294967)
ORDER BY tuple(runoob_id)
SETTINGS index_granularity = 8192
可以看到:
1、在DDL转化时默认增加了2个隐藏字段:_sign(-1删除, 1写入) 和 _version(数据版本)
2、默认将表引擎设置为 ReplacingMergeTree,以 _version 作为 column version
3、原DDL主键字段 runoob_id 作为ClickHouse排序键和分区键
此外还有许多DDL处理,比如增加列、索引等,相应代码在Parsers/MySQL 目录下。
- Delete/Update操作
Update:
# Mysql端:
UPDATE runoob_tbl set runoob_author='Mike' where runoob_id=2; mysql> select * from runoob_tbl;
+-----------+----------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+----------------+---------------+-----------------+
| 1 | MySQL-learning | Bob | 2021-01-06 |
| 2 | MySQL-learning | Mike | 2021-01-06 |
+-----------+----------------+---------------+-----------------+
2 rows in set (0.00 sec) ----------------------------------------------------------------
# ClickHouse端:
DESKTOP:) select *, _sign, _version from runoob_tbl order by runoob_id; SELECT
*,
_sign,
_version
FROM runoob_tbl
ORDER BY runoob_id ASC Query id: c5f4db0a-eff6-4b49-a429-b55230c26301 ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐
│ 1 │ MySQL-learning │ Bob │ 2021-01-06 │ 1 │ 2 │
│ 2 │ MySQL-learning │ Mike │ 2021-01-06 │ 1 │ 4 │
│ 2 │ MySQL-learning │ Tim │ 2021-01-06 │ 1 │ 3 │
└───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘
3 rows in set. Elapsed: 0.003 sec.
可以看到,ClickHouse数据也实时同步了更新操作。
- Delete:
# Mysql端
mysql> DELETE from runoob_tbl where runoob_id=2; mysql> select * from runoob_tbl;
+-----------+----------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+----------------+---------------+-----------------+
| 1 | MySQL-learning | Bob | 2021-01-06 |
+-----------+----------------+---------------+-----------------+
1 row in set (0.00 sec) ----------------------------------------------------------------
# ClickHouse端
DESKTOP:) select *, _sign, _version from runoob_tbl order by runoob_id; SELECT
*,
_sign,
_version
FROM runoob_tbl
ORDER BY runoob_id ASC Query id: e9cb0574-fcd5-4336-afa3-05f0eb035d97 ┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐
│ 1 │ MySQL-learning │ Bob │ 2021-01-06 │ 1 │ 2 │
└───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘
┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐
│ 2 │ MySQL-learning │ Mike │ 2021-01-06 │ -1 │ 5 │
└───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘
┌─runoob_id─┬─runoob_title───┬─runoob_author─┬─submission_date─┬─_sign─┬─_version─┐
│ 2 │ MySQL-learning │ Mike │ 2021-01-06 │ 1 │ 4 │
│ 2 │ MySQL-learning │ Tim │ 2021-01-06 │ 1 │ 3 │
└───────────┴────────────────┴───────────────┴─────────────────┴───────┴──────────┘
4 rows in set. Elapsed: 0.002 sec.
可以看到,删除id为2的行只是额外插入了_sign == -1的一行记录,并没有真正删掉。
- 日志回放
MySQL 主从间数据同步时Slave节点将 BinLog Event 转换成相应的SQL语句,Slave 模拟 Master 写入。类似地,传统第三方插件沿用了MySQL主从模式的BinLog消费方案,即将 Event 解析后转换成 ClickHouse 兼容的 SQL 语句,然后在 ClickHouse 上执行(回放),但整个执行链路较长,通常性能损耗较大。不同的是,MaterializeMySQL 引擎提供的内部数据解析以及回写方案隐去了三方插件的复杂链路。回放时将 BinLog Event 转换成底层 Block 结构,然后直接写入底层存储引擎,接近于物理复制。此方案可以类比于将 BinLog Event 直接回放到 InnoDB 的 Page 中。
同步策略
- 日志回放
v20.9.1版本前是基于位点同步的,ClickHouse每消费完一批 BinLog Event,就会记录 Event 的位点信息到 .metadata 文件:
[FavonianKong@Wsl[20:42:37]slave_db]
$ cat ./.metadata
Version: 2
Binlog File: mysql-bin.000003
Binlog Position:355005999
Data Version: 5
这样当 ClickHouse 再次启动时,它会把 {‘mysql-bin.000003’, 355005999} 二元组通过协议告知 MySQL Server,MySQL 从这个位点开始发送数据:
s1> ClickHouse 发送 {‘mysql-bin.000003’, 355005999} 位点信息给 MySQL
s2> MySQL 找到本地 mysql-bin.000003 文件并定位到 355005999 偏移位置,读取下一个 Event 发送给 ClickHouse
s3> ClickHouse 接收 binlog event 并完成同步操作
s4> ClickHouse 更新 .metadata位点
存在问题:
如果MySQL Server是一个集群,通过VIP对外服务,MaterializeMySQL创建 database 时 host 指向的是VIP,当集群主从发生切换后,{Binlog File, Binlog Position} 二元组不一定是准确的,因为BinLog可以做reset操作。
s1> ClickHouse 发送 {'mysql-bin.000003’, 355005999} 给集群新主 MySQL
s2> 新主 MySQL 发现本地没有 mysql-bin.000003 文件,因为它做过 reset master 操作,binlog 文件是 mysql-bin.000001
s3> 产生错误复制
为了解决这个问题,v20.9.1版本后上线了 GTID 同步模式,废弃了不安全的位点同步模式。
- GTID同步
GTID模式为每个 event 分配一个全局唯一ID和序号,直接告知 MySQL 这个 GTID 即可,于是.metadata变为:
[FavonianKong@Wsl[21:30:19]slave_db]
Version: 2
Binlog File: mysql-bin.000003
Executed GTID: 0857c24e-4755-11eb-888c-00155dfbdec7:1-783
Binlog Position:355005999
Data Version: 5
其中 0857c24e-4755-11eb-888c-00155dfbdec7 是生成 Event的主机UUID,1-783是已经同步的event区间
于是流程变为:
s1> ClickHouse 发送 GTID:0857c24e-4755-11eb-888c-00155dfbdec7:1-783 给 MySQL
s2> MySQL 根据 GTID 找到本地位点,读取下一个 Event 发送给 ClickHouse
s3> ClickHouse 接收 BinLog Event 并完成同步操作
s4> ClickHouse 更新 .metadata GTID信息
源码分析
- 概述
在最新源码 (v20.13.1.1) 中,ClickHouse 官方对 DatabaseMaterializeMySQL 引擎的相关源码进行了重构,并适配了 GTID 同步模式。ClickHouse 整个项目的入口 main 函数在 /ClickHouse/programs/main.cpp 文件中,主程序会根据接收指令将任务分发到 ClickHouse/programs 目录下的子程序中处理。本次分析主要关注 Server 端 MaterializeMySQL 引擎的工作流程。
- 源码目录
与 MaterializeMySQL 相关的主要源码路径:
ClickHouse/src/databases/MySQL //MaterializeMySQL存储引擎实现
ClickHouse/src/Storages/ //表引擎实现
ClickHouse/src/core/MySQL* //复制相关代码
ClickHouse/src/Interpreters/ //Interpreters实现,SQL的rewrite也在这里处理
ClickHouse/src/Parsers/MySQL //解析部分实现,DDL解析等相关处理在这里
- 服务端主要流程
ClickHouse 使用 POCO 网络库处理网络请求,Client连接的处理逻辑在 ClickHouse/src/Server/*Handler.cpp 的 hander方法里。以TCP为例,除去握手,初始化上下文以及异常处理等相关代码,主要逻辑可以抽象成:
// ClickHouse/src/Server/TCPHandler.cpp
TCPHandler.runImpl()
{
...
while(true) {
...
if (!receivePacket()) //line 184
continue
/// Processing Query //line 260
state.io = executeQuery(state.query, *query_context, ...);
...
}
- 数据同步预处理
Client发送的SQL在executeQuery函数处理,主要逻辑简化如下:
// ClickHouse/src/Interpreters/executeQuery.cpp
static std::tuple executeQueryImpl(...)
{
...
// line 354,解析器可配置
ast = parseQuery(...);
...
// line 503, 根据语法树生成interpreter
auto interpreter = InterpreterFactory::get(ast, context, ...);
...
// line 525, 执行器interpreter执行后返回结果
res = interpreter->execute();
...
}
主要有三点:
1、解析SQL语句并生成语法树 AST
2、InterpreterFactory 工厂类根据 AST 生成执行器
3、interpreter->execute()
跟进第三点,看看 InterpreterCreateQuery 的 excute() 做了什么:
// ClickHouse/src/Interpreters/InterpreterCreateQuery.cpp
BlockIO InterpreterCreateQuery::execute()
{
...
// CREATE | ATTACH DATABASE
if (!create.database.empty() && create.table.empty())
// line 1133, 当使用MaterializeMySQL时,会走到这里建库
return createDatabase(create);
}
这里注释很明显,主要执行 CREATE 或 ATTACH DATABASE,继续跟进 createDatabase() 函数:
// ClickHouse/src/Interpreters/InterpreterCreateQuery.cpp
BlockIO InterpreterCreateQuery::createDatabase(ASTCreateQuery & create)
{
...
// line 208, 这里会根据 ASTCreateQuery 参数,从 DatabaseFactory 工厂获取数据库对象
// 具体可以参考 DatabasePtr DatabaseFactory::getImpl() 函数
DatabasePtr database = DatabaseFactory::get(create, metadata_path, ...);
...
// line 253, 多态调用,在使用MaterializeMySQL时
// 上方get函数返回的是 DatabaseMaterializeMySQL
database->loadStoredObjects(context, ...);
}
到这里,相当于将任务分发给DatabaseMaterializeMySQL处理,接着跟踪 loadStoredObjects 函数:
//ClickHouse/src/Databases/MySQL/DatabaseMaterializeMySQL.cpp
template
void DatabaseMaterializeMySQL::loadStoredObjects(Context & context, ...)
{
Base::loadStoredObjects(context, has_force_restore_data_flag, force_attach);
try
{
// line87, 这里启动了materialize的同步线程
materialize_thread.startSynchronization();
started_up = true;
}
catch (...)
...
}
跟进startSynchronization() 绑定的执行函数:
// ClickHouse/src/Databases/MySQL/MaterializeMySQLSyncThread.cpp
void MaterializeMySQLSyncThread::synchronization()
{
...
// 全量同步在 repareSynchronized() 进行
if (std::optional metadata = prepareSynchronized())
{
while (!isCancelled())
{
UInt64 max_flush_time = settings->max_flush_data_time;
BinlogEventPtr binlog_event = client.readOneBinlogEvent(...);
{
//增量同步侦听binlog_envent
if (binlog_event)
onEvent(buffers, binlog_event, *metadata);
}
}
}
...
}
- 全量同步
MaterializeMySQLSyncThread::prepareSynchronized 负责DDL和全量同步,主要流程简化如下:
// ClickHouse/src/Databases/MySQL/MaterializeMySQLSyncThread.cpp
std::optional MaterializeMySQLSyncThread::prepareSynchronized()
{
while (!isCancelled())
{
...
try
{
//构造函数内会获取MySQL的状态、MySQL端的建表语句,
MaterializeMetadata metadata(connection, ...);
// line345, DDL相关转换
metadata.transaction(position, [&]()
{
cleanOutdatedTables(database_name, global_context);
dumpDataForTables(connection, metadata, global_context, ...);
}); return metadata;
}
...
}
}
ClickHouse作为MySQL从节点,在MaterializeMetadata构造函数中对MySQL端进行了一系列预处理:
1、将打开的表关闭,同时对表加上读锁并启动事务
2、TablesCreateQuery通过SHOW CREATE TABLE 语句获取MySQL端的建表语句
3、获取到建表语句后释放表锁
继续往下走,执行到 metadata.transaction() 函数,该调用传入了匿名函数作为参数,一直跟进该函数会发现最终会执行匿名函数,也就是cleanOutdatedTables以及dumpDataForTables函数,主要看一下 dumpDataForTables 函数:
// ClickHouse/src/Databases/MySQL/MaterializeMySQLSyncThread.cpp
static inline void dumpDataForTables(...)
{
...
//line293, 这里执行建表语句
tryToExecuteQuery(..., query_context, database_name, comment);
}
继续跟踪 tryToExecuteQuery 函数,会调用到 executeQueryImpl() 函数,上文提到过这个函数,但这次我们的上下文信息变了,生成的执行器发生变化,此时会进行 DDL 转化以及 dump table 等操作:
// ClickHouse/src/Interpreters/executeQuery.cpp
static std::tuple executeQueryImpl(...)
{
...
// line 354,解析器可配置
ast = parseQuery(...);
...
// line 503,这里跟之前上下文信息不同,生成interpreter也不同
auto interpreter = InterpreterFactory::get(ast,context, ...);
...
// line 525, 执行器interpreter执行后返回结果
res = interpreter->execute();
...
}
此时 InterpreterFactory 返回 InterpreterExternalDDLQuery,跟进去看 execute 函数做了什么:
// ClickHouse/src/Interpreters/InterpreterExternalDDLQuery.cpp
BlockIO InterpreterExternalDDLQuery::execute()
{
...
if (external_ddl_query.from->name == "MySQL")
{
#ifdef USE_MYSQL
...
// line61, 当全量复制执行DDL时,会执行到这里
else if (...->as())
return MySQLInterpreter::InterpreterMySQLCreateQuery(
external_ddl_query.external_ddl, cogetIdentifierName(arguments[0]),
getIdentifierName(arguments[1])).execute();
#endif
}
...
return BlockIO();
}
继续跟进去看看 getIdentifierName(arguments[1])).execute() 做了什么事情:
// ClickHouse/src/Interpreters/MySQL/InterpretersMySQLDDLQuery.h
class InterpreterMySQLDDLQuery : public IInterpreter
{
public:
...
BlockIO execute() override
{
...
// line68, 把从MySQL获取到的DDL语句进行转化
ASTs rewritten_queries = InterpreterImpl::getRewrittenQueries(
query, context, mapped_to_database, mysql_database); // line70, 这里执行转化后的DDL语句
for (const auto & rewritten_query : rewritten_queries)
executeQuery(..., queryToString(rewritten_query), ...); return BlockIO{};
}
...
}
进一步看 InterpreterImpl::getRewrittenQueries 是怎么转化 DDL 的:
// ClickHouse/src/Interpreters/MySQL/InterpretersMySQLDDLQuery.cpp
ASTs InterpreterCreateImpl::getRewrittenQueries(...)
{
...
// 检查是否存在primary_key, 没有直接报错
if (primary_keys.empty())
throw Exception("cannot be materialized, no primary keys.", ...);
...
// 添加 _sign 和 _version 列.
auto sign_column_name = getUniqueColumnName(columns_name_and_type, "_sign");
auto version_column_name = getUniqueColumnName(columns_name_and_type, "_version"); // 这里悄悄把建表引擎修改成了ReplacingMergeTree
storage->set(storage->engine, makeASTFunction("ReplacingMergeTree", ...));
...
return ASTs{rewritten_query};
}
完成DDL转换之后就会去执行新的DDL语句,完成建表操作,再回到 dumpDataForTables:
// ClickHouse/src/Databases/MySQL/MaterializeMySQLSyncThread.cpp
static inline void dumpDataForTables(...)
{
...
//line293, 这里执行建表语句
tryToExecuteQuery(..., query_context, database_name, comment);
...
// line29, 这里开始 dump 数据并存放到MySQLBlockInputStream
MySQLBlockInputStream input(connection, ...);
}
- 增量同步
还记得startSynchronization() 绑定的执行函数吗?全量同步分析都是在 prepareSynchronized()进行的,那增量更新呢?
// ClickHouse/src/Databases/MySQL/MaterializeMySQLSyncThread.cpp
void MaterializeMySQLSyncThread::synchronization()
{
...
// 全量同步在 repareSynchronized() 进行
if (std::optional metadata = prepareSynchronized())
{
while (!isCancelled())
{
UInt64 max_flush_time = settings->max_flush_data_time;
BinlogEventPtr binlog_event = client.readOneBinlogEvent(...);
{
//增量同步侦听binlog_envent
if (binlog_event)
onEvent(buffers, binlog_event, *metadata);
}
}
}
...
}
可以看到,while 语句里有一个 binlog_event 的侦听函数,用来侦听 MySQL 端 BinLog 日志变化,一旦 MySQL 端执行相关操作,其 BinLog 日志会更新并触发 binlog_event,增量更新主要在这里进行。
// ClickHouse/src/Databases/MySQL/MaterializeMySQLSyncThread.cpp
void MaterializeMySQLSyncThread::onEvent(Buffers & buffers, const BinlogEventPtr & receive_event, MaterializeMetadata & metadata)
{
// 增量同步通过监听binlog event实现,目前支持四种event:MYSQL_WRITE_ROWS_EVENT、
// MYSQL_UPDATE_ROWS_EVENT、MYSQL_DELETE_ROWS_EVENT 和 MYSQL_QUERY_EVENT
// 具体的流程可以查找对应的 onHandle 函数, 不在此详细分析
if (receive_event->type() == MYSQL_WRITE_ROWS_EVENT){...}
else if (receive_event->type() == MYSQL_UPDATE_ROWS_EVENT){...}
else if (receive_event->type() == MYSQL_DELETE_ROWS_EVENT){...}
else if (receive_event->type() == MYSQL_QUERY_EVENT){...}
else {/* MYSQL_UNHANDLED_EVENT*/}
}
小结
MaterializeMySQL 引擎是 ClickHouse 官方2020年主推的特性,由于该特性在生产环境中属于刚需且目前刚上线不久,整个模块处于高速迭代的状态,因此有许多待完善的功能。例如复制过程状态查看以及数据的一致性校验等。感兴趣的话可参考Github上的2021-Roadmap,里面会更新一些社区最近得计划。以上内容如有理解错误还请指正。
引用
本文分享自华为云社区《MySQL到ClickHouse的高速公路-MaterializeMySQL引擎》,原文作者:FavonianKong 。
Materialize MySQL引擎:MySQL到Click House的高速公路的更多相关文章
- 深入浅析mysql引擎
mysql引擎 mysql数据库引擎取决于mysql在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译mysql.在缺省情况下,mysql支持三个引擎:ISAM,MYISAM和HEAP.另 ...
- mySql引擎
摘自: http://www.cnblogs.com/sopc-mc/archive/2011/11/01/2232212.html MySql引擎很多,最常见的有InnoDB,MyISAM,NDM ...
- mysql引擎整理
MySQL数 据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL.在缺省情况下,MYSQL支持三个引 擎:ISAM.MYISAM和HEAP.另外两种类型I ...
- MySQL · 引擎特性 · InnoDB 崩溃恢复过程
MySQL · 引擎特性 · InnoDB 崩溃恢复过程 在前面两期月报中,我们详细介绍了 InnoDB redo log 和 undo log 的相关知识,本文将介绍 InnoDB 在崩溃恢复时的主 ...
- MySQL · 引擎特性 · InnoDB 事务子系统介绍
http://mysql.taobao.org/monthly/2015/12/01/ 前言 在前面几期关于 InnoDB Redo 和 Undo 实现的铺垫后,本节我们从上层的角度来阐述 InnoD ...
- MySQL引擎的相关知识
MySQL数 据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL.在缺省情况下,MYSQL支持三个引 擎:ISAM.MYISAM和HEAP.另外两种类型I ...
- MySQL引擎介绍ISAM,MyISAM,HEAP,InnoDB
MySQL数据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL. 在缺省情况下,MYSQL支持三个引擎:ISAM.MYISAM和HEAP.另外两种类型IN ...
- MySQL引擎简述
MySQL数 据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL.在缺省情况下,MYSQL支持三个引擎:ISAM.MYISAM和HEAP.另外两种类型IN ...
- Spring事务mysql不回滚:mysql引擎修改
若Spring中@Transactional 注解开启且配置没问题的话,很可能是mysql数据库引擎不支持. mysql引擎是MyISAM的话事务会不起作用,原因是MyISAM不支持事务和外键,改成支 ...
- windows 虚拟环境下 安装 mysql 引擎一系列错误处理
报错现象 运行django 报错. 很明显是缺少引擎 下载引擎 django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb m ...
随机推荐
- Chromium 通过IDL方式添加扩展API
基于chromium103版本 1. 自定义扩展API接口 chromium默认扩展api接口中有chrome.runtime.*,和chrome.send.*等,现在我们就仿照chrome.runt ...
- Spring Cloud OpenFeign系列:简介和使用
目录 一.简介 二.使用 1.创建父工程 2.创建order-service模块 3.创建order-client模块 三.效果 四.配置说明 1.超时配置 全局超时配置 局部超时配置 2.Gzip压 ...
- Python 利用pandas和mysql-connector获取Excel数据写入到MySQL数据库
如何将Excel数据插入到MySQL数据库中 在实际应用中,我们可能需要将Excel表格中的数据导入到MySQL数据库中,以便于进行进一步的数据分析和处理.本文将介绍如何使用Python将Excel表 ...
- 洛谷1451(BFS)
#include"bits/stdc++.h" using namespace std; int mp[110][110]; bool vis[110][110]; int dx[ ...
- QAction常用接口总结
目录 public (一)构造函数 (二)setShortcut (三)setStatusTip Signals (一)trigger() public (一)构造函数 1.QAction(const ...
- Python 利用pandas和matplotlib绘制双柱状图
在数据分析和可视化中,常用的一种图形类型是柱状图.柱状图能够清晰地展示不同分类变量的数值,并支持多组数据进行对比.本篇文章将介绍如何使用Python绘制双柱状图. 准备工作 在开始绘制柱状图之前,需要 ...
- 【pwn】[MoeCTF 2022]babyfmt --格式化字符串漏洞,got表劫持
拿到程序,先checksec一下 发现是Partial RELRO,got表可修改 当RELRO保护为NO RELRO的时候,init.array.fini.array.got.plt均可读可写:为P ...
- Vue源码学习(十六):diff算法(三)暴力比对
好家伙,这是diff的最后一节了 0.暴力比对的使用场景 没有可复用的节点:当新旧虚拟 DOM 的结构完全不同,或者某个节点不能被复用时,需要通过暴力比对来创建新的节点,并在真实 DOM 上进行相 ...
- answer_to_everything
题解,第一次遇到这种题目纪念一下 攻防世界逆向入门题之answer_to_everything_沐一 · 林的博客-CSDN博客
- nmap命令说明
目录 主机发现 扫描技术 端口规格和扫描顺序 服务/版本检测 脚本扫描 操作系统检测 时间和性能: 防火墙/IDS的逃避和欺骗 输出 杂项 平时看到别人的nmap命令都是一大串,根本看不懂为什么,自己 ...