神经网络基础篇:详解logistic 损失函数(Explanation of logistic regression cost function)
详解 logistic 损失函数
在本篇博客中,将给出一个简洁的证明来说明逻辑回归的损失函数为什么是这种形式。
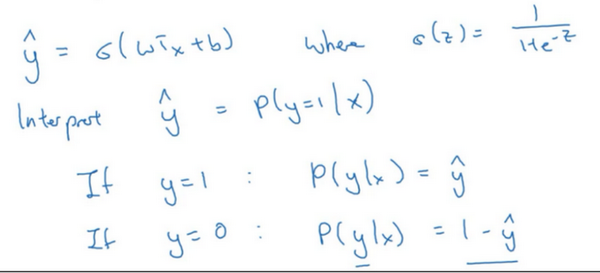
回想一下,在逻辑回归中,需要预测的结果\(\hat{y}\),可以表示为\(\hat{y}=\sigma(w^{T}x+b)\),\(\sigma\)是熟悉的\(S\)型函数 \(\sigma(z)=\sigma(w^{T}x+b)=\frac{1}{1+e^{-z}}\) 。约定 \(\hat{y}=p(y=1|x)\) ,即算法的输出\(\hat{y}\) 是给定训练样本 \(x\) 条件下 \(y\) 等于1的概率。换句话说,如果\(y=1\),在给定训练样本 \(x\) 条件下\(y=\hat{y}\);反过来说,如果\(y=0\),在给定训练样本\(x\)条件下 \(y\) 等于1减去\(\hat{y}(y=1-\hat{y})\),因此,如果 \(\hat{y}\) 代表 \(y=1\) 的概率,那么\(1-\hat{y}\)就是 \(y=0\)的概率。接下来,就来分析这两个条件概率公式。
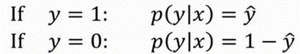
这两个条件概率公式定义形式为 \(p(y|x)\)并且代表了 \(y=0\) 或者 \(y=1\) 这两种情况,可以将这两个公式合并成一个公式。需要指出的是讨论的是二分类问题的损失函数,因此,\(y\)的取值只能是0或者1。上述的两个条件概率公式可以合并成如下公式:
\(p(y|x)={\hat{y}}^{y}{(1-\hat{y})}^{(1-y)}\)
接下来会解释为什么可以合并成这种形式的表达式:\((1-\hat{y})\)的\((1-y)\)次方这行表达式包含了上面的两个条件概率公式,现在来解释一下为什么。
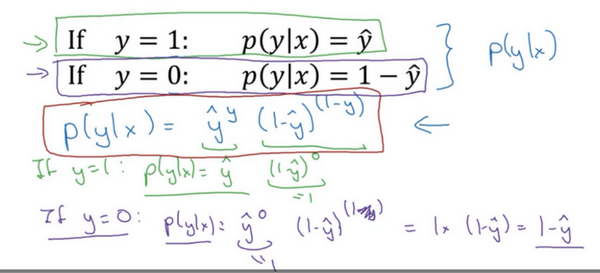
第一种情况,假设 \(y=1\),由于\(y=1\),那么\({(\hat{y})}^{y}=\hat{y}\),因为 \(\hat{y}\)的1次方等于\(\hat{y}\),\(1-{(1-\hat{y})}^{(1-y)}\)的指数项\((1-y)\)等于0,由于任何数的0次方都是1,\(\hat{y}\)乘以1等于\(\hat{y}\)。因此当\(y=1\)时 \(p(y|x)=\hat{y}\)(图中绿色部分)。
第二种情况,当 \(y=0\) 时 \(p(y|x)\) 等于多少呢?
假设\(y=0\),\(\hat{y}\)的\(y\)次方就是 $$\hat{y}$$ 的0次方,任何数的0次方都等于1,因此 \(p(y|x)=1×{(1-\hat{y})}^{1-y}\) ,前面假设 \(y=0\) 因此\((1-y)\)就等于1,因此 \(p(y|x)=1×(1-\hat{y})\)。因此在这里当\(y=0\)时,\(p(y|x)=1-\hat{y}\)。这就是这个公式(第二个公式,图中紫色字体部分)的结果。
因此,刚才的推导表明 \(p(y|x)={\hat{y}}^{(y)}{(1-\hat{y})}^{(1-y)}\),就是 \(p(y|x)\) 的完整定义。由于 log 函数是严格单调递增的函数,最大化 \(log(p(y|x))\) 等价于最大化 \(p(y|x)\) 并且地计算 \(p(y|x)\) 的 log对数,就是计算 \(log({\hat{y}}^{(y)}{(1-\hat{y})}^{(1-y)})\) (其实就是将 \(p(y|x)\) 代入),通过对数函数化简为:
\(ylog\hat{y}+(1-y)log(1-\hat{y})\)
而这就是前面提到的损失函数的负数 \((-L(\hat{y},y))\) ,前面有一个负号的原因是当训练学习算法时需要算法输出值的概率是最大的(以最大的概率预测这个值),然而在逻辑回归中需要最小化损失函数,因此最小化损失函数与最大化条件概率的对数 \(log(p(y|x))\) 关联起来了,因此这就是单个训练样本的损失函数表达式。
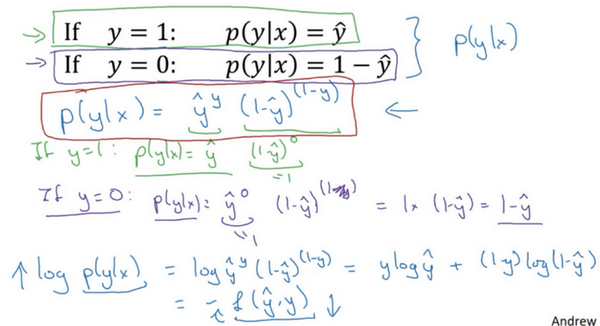
在 \(m\)个训练样本的整个训练集中又该如何表示呢。
整个训练集中标签的概率,更正式地来写一下。假设所有的训练样本服从同一分布且相互独立,也即独立同分布的,所有这些样本的联合概率就是每个样本概率的乘积:
\(P\left(\text{labels in training set} \right) = \prod_{i =1}^{m}{P(y^{(i)}|x^{(i)})}\)。
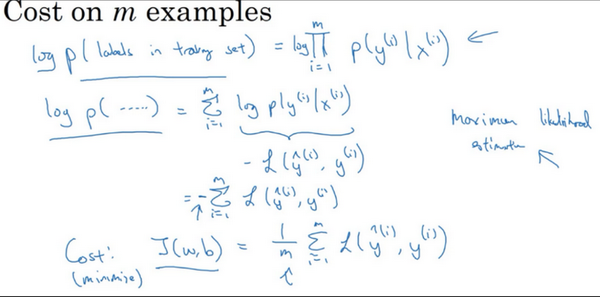
如果想做最大似然估计,需要寻找一组参数,使得给定样本的观测值概率最大,但令这个概率最大化等价于令其对数最大化,在等式两边取对数:
\(logp\left( \text{labels in training set} \right) = log\prod_{i =1}^{m}{P(y^{(i)}|x^{(i)})} = \sum_{i = 1}^{m}{logP(y^{(i)}|x^{(i)})} = \sum_{i =1}^{m}{- L(\hat y^{(i)},y^{(i)})}\)
在统计学里面,有一个方法叫做最大似然估计,即求出一组参数,使这个式子取最大值,也就是说,使得这个式子取最大值,\(\sum_{i= 1}^{m}{- L(\hat y^{(i)},y^{(i)})}\),可以将负号移到求和符号的外面,\(- \sum_{i =1}^{m}{L(\hat y^{(i)},y^{(i)})}\),这样就推导出了前面给出的logistic回归的成本函数\(J(w,b)= \sum_{i = 1}^{m}{L(\hat y^{(i)},y^{\hat( i)})}\)。
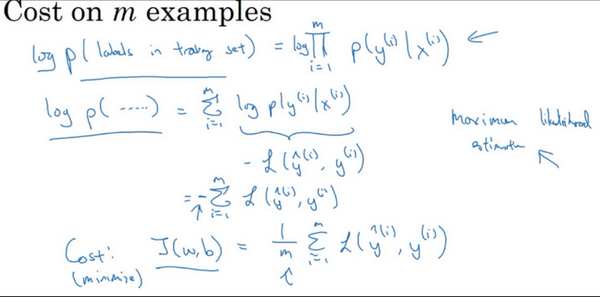
由于训练模型时,目标是让成本函数最小化,所以不是直接用最大似然概率,要去掉这里的负号,最后为了方便,可以对成本函数进行适当的缩放,就在前面加一个额外的常数因子\(\frac{1}{m}\),即:\(J(w,b)= \frac{1}{m}\sum_{i = 1}^{m}{L(\hat y^{(i)},y^{(i)})}\)。
总结一下,为了最小化成本函数\(J(w,b)\),从logistic回归模型的最大似然估计的角度出发,假设训练集中的样本都是独立同分布的条件下。
神经网络基础篇:详解logistic 损失函数(Explanation of logistic regression cost function)的更多相关文章
- JavaScript基础篇详解
全部的数据类型: 基本数据类型: undefined Number Boolean null String 复杂数据类型: object ①Undefined: >>>声明但未初始化 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Python基础知识详解 从入门到精通(七)类与对象
本篇主要是介绍python,内容可先看目录其他基础知识详解,欢迎查看本人的其他文章Python基础知识详解 从入门到精通(一)介绍Python基础知识详解 从入门到精通(二)基础Python基础知识详 ...
- I2C 基础原理详解
今天来学习下I2C通信~ I2C(Inter-Intergrated Circuit)指的是 IC(Intergrated Circuit)之间的(Inter) 通信方式.如上图所以有很多的周边设备都 ...
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- 【原创 深度学习与TensorFlow 动手实践系列 - 3】第三课:卷积神经网络 - 基础篇
[原创 深度学习与TensorFlow 动手实践系列 - 3]第三课:卷积神经网络 - 基础篇 提纲: 1. 链式反向梯度传到 2. 卷积神经网络 - 卷积层 3. 卷积神经网络 - 功能层 4. 实 ...
- RabbitMQ基础知识详解
什么是MQ? MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- Nmap扫描教程之基础扫描详解
Nmap扫描教程之基础扫描详解 Nmap扫描基础扫描 当用户对Nmap工具了解后,即可使用该工具实施扫描.通过上一章的介绍,用户可知Nmap工具可以分别对主机.端口.版本.操作系统等实施扫描.但是,在 ...
随机推荐
- How to start with Gradle?
How to start with Gradle? Download the latest Gradle release from http://www.gradle.org/downloads Se ...
- Go函数介绍与一等公民
Go函数介绍与一等公民 函数对应的英文单词是 Function,Function 这个单词原本是功能.职责的意思.编程语言使用 Function 这个单词,表示将一个大问题分解后而形成的.若干具有特定 ...
- 【XXE实战】——浅看两道CTF题
[XXE实战]--浅看两道CTF题 上一条帖子[XXE漏洞]原理及实践演示对XXE的一些原理进行了浅析,于是写了两道CTF题巩固一下,顺便也记录一下第一次写出来CTF.两道题都是在BUU上找的:[NC ...
- 揭秘计算机指令执行的神秘过程:CPU内部的绝密操作
计算机指令 从软件工程师的角度来看,CPU是执行计算机指令的逻辑机器.计算机指令可以看作是CPU能够理解的语言,也称为机器语言. 不同的CPU能理解的语言不同.例如,个人电脑使用Intel的CPU,苹 ...
- C#_TCPClient异步连接和接收消息
//c#不愧是全能型的语言,异步连线程都省了 class State { public byte[] bufferCache; public TcpClient tcpClient; } ... pr ...
- CSP2021游记
题外话 中午十二点半到了考场.没到时间不让进,恰巧发现 lhm 在对面饭店于是去讨论了一下上午 J 组的题,复习了线段树板子( 等到进考场坐好的时候已经两点半了,看考号本来以为我们同机房三个同学会坐一 ...
- 文心一言 VS 讯飞星火 VS chatgpt (122)-- 算法导论10.4 3题
三.用go语言,给定一个n结点的二叉树,写出一个 O(n)时间的非递归过程,将该树每个结点的关键字输出.可以使用一个栈作为辅助数据结构. 文心一言: 以下是一个使用 Go 语言编写的函数,该函数使用一 ...
- go基础-接口
一.概述 接口是面向对象编程的重要概念,接口是对行为的抽象和概括,在主流面向对象语言Java.C++,接口和类之间有明确关系,称为"实现接口".这种关系一般会以"类派生图 ...
- 神经网络入门篇:神经网络的梯度下降(Gradient descent for neural networks)
神经网络的梯度下降 在这篇博客中,讲的是实现反向传播或者说梯度下降算法的方程组 单隐层神经网络会有\(W^{[1]}\),\(b^{[1]}\),\(W^{[2]}\),\(b^{[2]}\)这些参数 ...
- python中四种方法提升数据处理的速度
在数据科学计算.机器学习.以及深度学习领域,Python 是最受欢迎的语言.Python 在数据科学领域,有非常丰富的包可以选择,numpy.scipy.pandas.scikit-learn.mat ...