详解NLP和时序预测的相似性【附赠AAAI21最佳论文INFORMER的详细解析】
摘要:本文主要分析自然语言处理和时序预测的相似性,并介绍Informer的创新点。
前言
时序预测模型无外乎RNN(LSTM, GRU)以及现在非常火的Transformer。这些时序神经网络模型的主要应用都集中在自然语言处理上面(transformer就是为了NLP设计的)。在近些年来,RNN和Transformer逐渐被应用于时序预测上面,并取得了很好的效果。2021年发表的Informer网络获得了AAAI best paper。本文主要分析自然语言处理和时序预测的相似性,并介绍Informer的创新点。
具体的本文介绍了
- 早期机器翻译模型RNN-AutoEncoder的原理
- RNN-AutoEncoder升级版Transformer的原理
- 时序预测与机器翻译的异同以及时序预测算法的分类
- AAAI21最佳论文,时序预测模型INFORMER的创新点分析
RNN AutoEncoder
早期自然语言处理:RNN autoencoder
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” arXiv preprint arXiv:1409.3215 (2014). (google citation 14048)
这里以机器翻译为例子,介绍RNN autoencoder的原理。
输入句子经过分词,编码成数字,然后embedding成神经网络可以接受的向量。
在训练过程中,可以使用teacher forcing,即decoder的输入使用真实值,迫使在训练过程中,误差不会累加
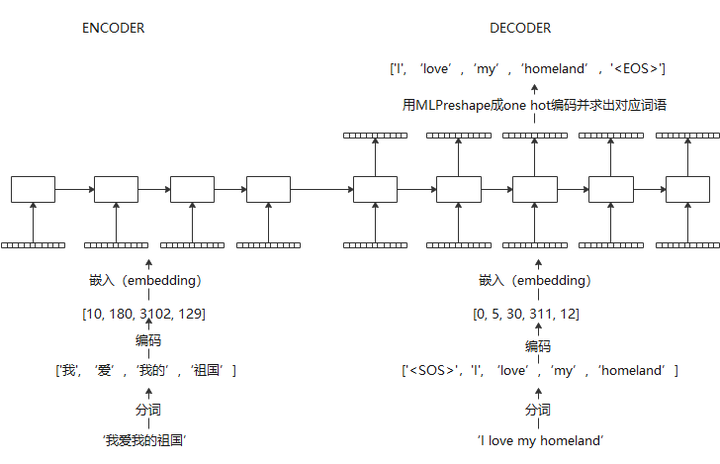
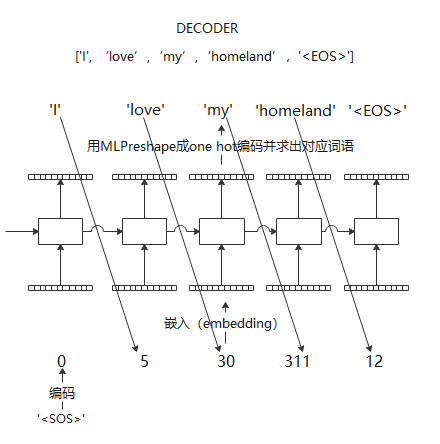
在在线翻译过程中,encoder部分流程相同,decoder部分,目标句子是一个单词一个单词生成的
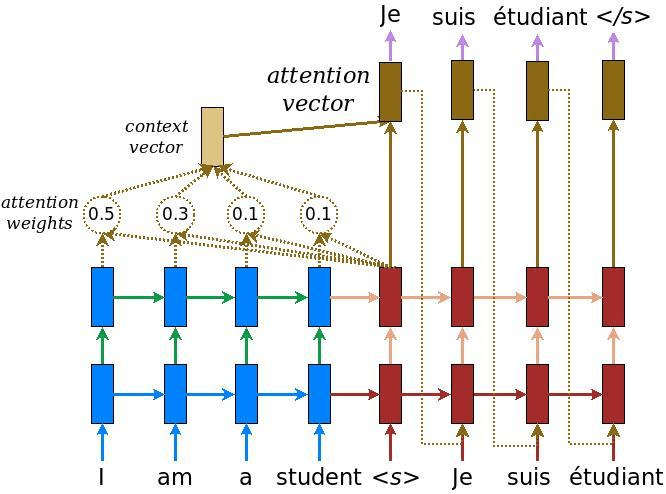
早期RNN auto encoder结构虽然相比于传统模型取得了巨大成功,但encoder,decoder之间的信息传播仅仅时由单一的一个隐层链接完成的,这样势必会造成信息丢失,因此,Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).(citation 16788)提出在输入和输出之间增加额外的attention链接,增加信息传递的鲁棒性以及体现输出句子中不同单词受输入句子单词影响的差异性。
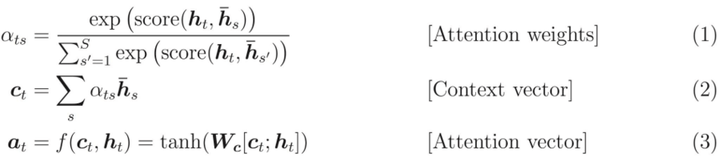
Transformer
2017-划时代:Transformer—LSTM autoencoder的延申。
既然attention效果如此的好,那么能否只保留attention而抛弃循环神经网络呢?
Google在17年年底提出了transformer网络,带来了nlp的技术革命。
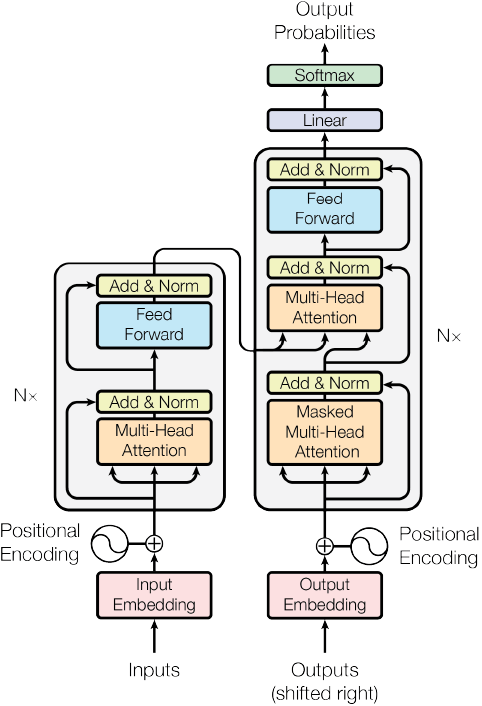
transformer本质上还是一个信息顺序传递的模型。主要包含了positional encoding(用于区分词语出现的先后顺序),self-attention, attention, 以及feed forward网络四大部分。与RNN不同的是,Transformer利用了attention机制进行信息传递,具体的,self-attention的信息传递机制如下:
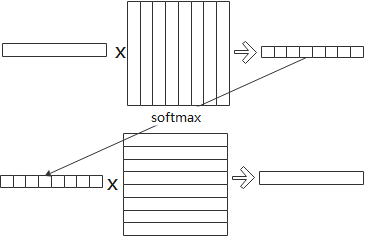
一个词向量和句子中所有词向量构成的矩阵做相关得到相关性向量,做softmax归一化后,求得所有词向量构成的加权和,得到新的词向量。
transformer同样用attention机制,代替了RNN-AE中用来传递句子之间信息的隐层链接。此外,在decoder阶段,为了保证矩阵中上一个下一个单词仅仅由他前面的单词决定,在self-attention中,还需要做一个上三角矩阵的masking。
在训练过程中,一般同样采取teacher forcing的方法,即decoder输入是完整的目标句子的embedding。而在在线翻译的时候,依然从采取了如RNN-AE一样的滚动输出的方式,即初始输入为<SOS>,余下向量全部用padding。得到输出后,一个一个加入到decoder输入中,直到遇到<EOS>。

在transformer提出以后,基于Transformer的BERT预言模型成为了NLP中统治级别的模型。
时序预测与机器翻译的异同
时序预测按照输入的区别可以分为两大类,即直接时序预测和滚动时序预测。
直接时序预测,的输入是被预测部分的时间戳,输出是被预测部分的值。在训练过程中直接时序预测算法首先把输出和时间戳的关系建立为y=f(x)函数,然后用训练集拟合这个函数。在预测阶段,直接输入被预测部分的时间戳即可获得目标值。典型的算法即为FB的PROPHET算法。
与直接时序预测算法不同的是,滚动时间序列预测算法绝大部分都不依靠时间戳信息。滚动时间序列预测把时间序列模型建立为x_{t+1,t+n}=f(x_{t−m,t})xt+1,t+n=f(xt−m,t),即被预测时间段的值由历史时间段的值决定。在训练阶段,把训练集切分为一个一个的输入输出对,用SGD迭代减少输出和目标真实值的误差,在预测阶段用被预测数据前一段的历史数据作为输入,得到预测输出。
现阶段,基于深度学习的预测算法绝大多数都属于滚动时间序列预测类别。
时序预测与机器翻译的相同点
• 数据输入都是一个时间序列矩阵
○ 时序预测的输入矩阵为(t, d_{feature})(t,dfeature), t为输入时间长度,d_{feature}dfeature为每个时间点的数据维度
○ nlp的输入矩阵为(t, d_{embed})(t,dembed),t为输入句子的最大长度,d_{embed}dembed为此嵌入向量长度
• 都是一个seq2seq的问题,可以用RNN-AE以及Transformer解决
时序预测与机器翻译的不同点
• nlp中,词语需要一系列预处理才能得到网络输入矩阵而时序预测中,输入矩阵是自然形成的。
• nlp中,在线翻译采取了滚动输出的方式,nlp输出先做softmax并匹配为单词后,重新做embedding才作为下一次预测的输入,这样的作法可以克服一部分误差累积。而在时序预测中,如果采取滚动输出的方式,上一个时间点的输出是直接被当作下一时间点的输入的。这样可能会带来过多的误差累积。
Informer论文分析
Transformer近些年来成为了时序预测的主流模型。在刚刚结束的AAAI 2021中,来自北航的论文
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting得到了BEST paper的荣誉。Informer论文的主体依然采取了transformer encoder-decoder的结构。在transformer的基础上,informer做出了诸多提高性能以及降低复杂度的改进。
1)Probsparse attention
a. transformer最大的特点就是利用了attention进行时序信息传递。传统transformer在信息传递时,需要进行两次矩阵乘,即(softmax(QK)^T/\sqrt{d})∗V(softmax(QK)T/d)∗V,则attention的计算复杂度为O(L_q L_k)O(LqLk),其中L_qLq 为query矩阵的时间长度,L_kLk 为key矩阵的时间长度。为了减少attention的计算复杂度,作者提出,attention的信息传递过程具有稀疏性。以t时间为例,并非所有t时间以前的时间点都和t时间点都有关联性。部分时间点和t时间点的关联性非常小,可以忽略。如果忽略掉这些时间点和t时间点的attention计算,则可以降低计算复杂度。
b. attention的数学表达式为
out_i=softmax(q_i K^T)V=\sum\limits_{j=1}^{L_k}\frac{\exp(q_ik_j^T/\sqrt{d})}{\sum\limits_{l=1}^{L_k}\exp(q_ik_j^T/\sqrt{d})}v_j=\sum\limits_{j=1}^{L_k}p(k_j|q_i)v_jouti=softmax(qiKT)V=j=1∑Lkl=1∑Lkexp(qikjT/d)exp(qikjT/d)vj=j=1∑Lkp(kj∣qi)vj
在计算attention的时候,若q_iqi 和key矩阵整体相关性较低,则p(k_j |q_i )p(kj∣qi)退化为均匀分布,这时,attention的output退化为了对value矩阵的行求均值。因此,可以用p(k_j |q_i )p(kj∣qi)和均匀分布的差别,即p(k_j |q_i )p(kj∣qi)和均匀分布的KL散度,来度量queryq_iqi 的稀疏度。如果KL散度高,则按照传统方法求attention,如果KL散度低,则用对V求行平均的方式代替attention。总的来说,INFORMER中提出了一种度量query稀疏度(和均匀分布的相似程度)并用value的行平均近似attention的方法。
c. 具体的令q为均匀分布,p为p(k_j |q_i )p(kj∣qi),则KL散度经过计算为M(q_i,K)=\ln\sum\limits_{j=1}^{L_k}e^{\frac{q_ik_j^T}{\sqrt{d}}}-\frac{1}{L_k}\sum\limits_{j=1}^{L_k}\frac{q_ik_j^T}{\sqrt{d}}M(qi,K)=lnj=1∑LkedqikjT−Lk1j=1∑LkdqikjT
按照INFORMER的思想,即可对每一个query计算KL散度,然后取topk的query进行attention,其余的query对应的行直接用V的行平均进行填充。
d. 根据以上的思想,在attention的时候确实可以降低复杂度,然而,在排序的时候,复杂度依然是O(L_k L_q)O(LkLq)。因此,作者又提出了一种对M(q_i,K)M(qi,K)排序进行近似计算的方式。在这里,由于证明涉及到我的一些陌生领域,例如随机微分,我并没有深入取细嚼慢咽。这里就直接呈现结论。
i. M(q_i,K)=\ln\sum\limits_{j=1}^{L_k}e^{q_i k_j^T/\sqrt{d}} −\frac{1}{L_k}\sum\limits_{j=1}^{L_k}{q_i k_j^T}/\sqrt{d}M(qi,K)=lnj=1∑LkeqikjT/d−Lk1j=1∑LkqikjT/d 可以用其上界\bar{M}(q_i,K)=\max\limits_j({q_i k_j^T/\sqrt{d}}) −\frac{1}{L_k}\sum\limits_{j=1}^{L_k}{q_i k_j^T}/\sqrt{d}Mˉ(qi,K)=jmax(qikjT/d)−Lk1j=1∑LkqikjT/d代替,作者证明近似后大概率不影响排序。
ii. 上界在计算的时候可以只随机采样一部分k_jkj,减少k_jkj 也就减少了乘法的次数,降低了复杂度。作者在附录中证明这样的随机采样近似大概率对排序没有影响。
e.
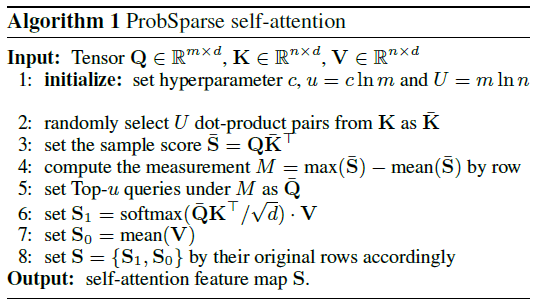
i. 作者在附录中,给出了probsparse self-attention的具体实施过程
ii. 在第2行,对K进行采样,使得sparse 排序过程得以简化复杂度
iii. 在第5行,只选出top-u作为query,使得attention做了简化
f. 关于probsparse,需要注意的问题有以下几点:
i. 这个机制只用在了self-attention中。在文中,作者把提出的方法称为了prob-sparse self-attention,在源代码中,也只用在了self-attention中。至于为什么不能用于cross-attention,现在不太清楚。
ii. 这个机制在有三角矩阵masking的情况下也不能用,因为在有masking的情况下,query和key的乘法数量本来就减少了。
iii. 因此,probsparse只能用于encoder的self-attention中
iv. 虽然论文中提出probsparse可以减少复杂度,但由于增加了排序的过程,不一定能减少计算时间,在一些数据长度本来就较少的情况下,可能会增加计算时间。
2)Attention distilling
a. 与普通transformer不同的是,由于probsparse self-attention中,一些信息是冗余的,因此在后面采取了convolution+maxpooling的方法,减少冗余信息。这种方法也只能在encoder中使用。
3)CNN feed forward network
a. 在17年的transformer中,feedforward网络是用全连接网络构成的,在informer中,全连接网络由CNN代替。
4)Time stamp embedding
a. Time stamp embedding也是Informer的一个特色。在普通的transformer中,由于qkv的乘法并不区分矩阵行的先后顺序,因此要加一个positional encoding。在INFORMER中,作者把每个时间点时间戳的年,月,日等信息,也加入作为encoding的一部分,让transformer能更好的学习到数据的周期性。
5)Generative decoding
a. 在NLP中,decoding部分是迭代输出的。这样的作法如果在时序预测中应用的化,在长序列预测中会引起较长的计算复杂度。其次,由于NLP中有词语匹配的过程,会较少噪声累积,而时序预测中,这种噪声累积则会因为单步滚动预测而变得越发明显。
b. 因此,在decoding时,作者采取了一次输出多部预测的方式,decoder输入是encoder输入的后面部分的截取+与预测目标形状相同的0矩阵。
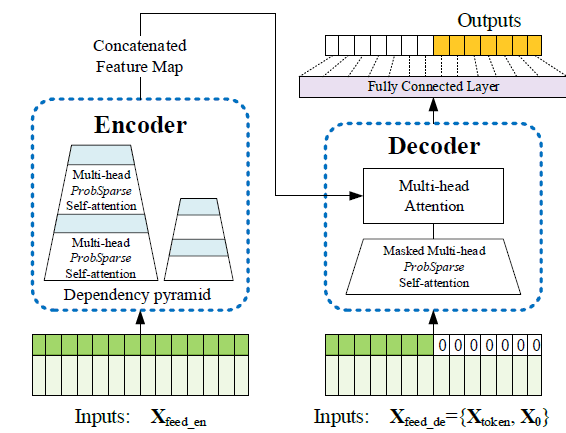
其中,X_{token}Xtoken 由X_{feed\_en}Xfeed_en 后半部分截取而成。
6)Informer代码:https://github.com/zhouhaoyi/Informer2020
详解NLP和时序预测的相似性【附赠AAAI21最佳论文INFORMER的详细解析】的更多相关文章
- 【转】IOS AutoLayout详解(三)用代码实现(附Demo下载)
转载自:blog.csdn.net/hello_hwc IOS SDK详解 前言: 在开发的过程中,有时候创建View没办法通过Storyboard来进行,又需要AutoLayout,这时候用代码创建 ...
- 苹果搜索广告后台大揭秘,最全最细致详解,手把手设置教程「后附官方视频」-b
WWDC2016 搜索广告分会视频和 PPT 发布了,ASO100 带开发者第一时间了解 Search Ads 后台设置(文末有原声视频). 首先介绍一下搜索广告的模式和竞价规则 广告模式为 CPT( ...
- 详解Pytorch中的网络构造,模型save和load,.pth权重文件解析
转载:https://zhuanlan.zhihu.com/p/53927068 https://blog.csdn.net/wangdongwei0/article/details/88956527 ...
- Protocol Buffers编码详解,例子,图解
Protocol Buffers编码详解,例子,图解 本文不是让你掌握protobuf的使用,而是以超级细致的例子的方式分析protobuf的编码设计.通过此文你可以了解protobuf的数据压缩能力 ...
- 决策树--CART树详解
1.CART简介 CART是一棵二叉树,每一次分裂会产生两个子节点.CART树分为分类树和回归树. 分类树主要针对目标标量为分类变量,比如预测一个动物是否是哺乳动物. 回归树针对目标变量为连续值的情况 ...
- 详解Kalman Filter
中心思想 现有: 已知上一刻状态,预测下一刻状态的方法,能得到一个"预测值".(当然这个估计值是有误差的) 某种测量方法,可以测量出系统状态的"测量值".(当然 ...
- Android Design Support Library使用详解
Android Design Support Library使用详解 Google在2015的IO大会上,给我们带来了更加详细的Material Design设计规范,同时,也给我们带来了全新的And ...
- 热烈祝贺华清远见《ARM处理器开发详解》第2版正式出版
2014年6月,由华清远见研发中心组织多名业 内顶尖讲师编写的<ARM处理器开发详解>一书正式出版.本书以S5PV210处理器为平台,详细介绍了嵌入式系统开发的各个主要环节,并注重实践,辅 ...
- android Json解析详解
JSON的定义: 一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性.业内主流技术为其提供了完整的解决方案(有点类似于正则表达式 ,获得了当今大部分语 言的支持),从而可以在不同平台间进行数 ...
- 过滤ASCII码中的不可见字符, ASCII三部分, 各控制字符详解, 去^@,^M
今天产品部同事报告了一个BUG,经过调试发现,由于用户输入的字符串中,包含字符0x1E, 也就是”记录分隔符”(Record Separator, Notepad++ 显示为[RS]),导致JavaS ...
随机推荐
- 文心一言 VS 讯飞星火 VS chatgpt (114)-- 算法导论10.2 7题
七.用go语言,给出一个 O(n)时间的非递归过程,实现对一个含 n个元素的单链表的逆转.要求除存储链表本身所需的空间外,该过程只能使用固定大小的存储空间. 文心一言: 在Go语言中,你可以使用迭代方 ...
- Go 函数多返回值错误处理与error 类型介绍
Go 函数多返回值错误处理与error 类型介绍 目录 Go 函数多返回值错误处理与error 类型介绍 一.error 类型与错误值构造 1.1 Error 接口介绍 1.2 构造错误值的方法 1. ...
- redis主从同步及redis哨兵机制
1.主从和哨兵的作用: 角色 作用 主从 1.(提供)数据副本:多一份数据副本,保证redis高可用 2. 扩展(读)性能:如容量.QPS等 哨兵 1.监控: 监控redis主库及从库运行状态: 2 ...
- Python 继承和子类示例:从 Person 到 Student 的演示
继承允许我们定义一个类,该类继承另一个类的所有方法和属性.父类是被继承的类,也叫做基类.子类是从另一个类继承的类,也叫做派生类. 创建一个父类 任何类都可以成为父类,因此语法与创建任何其他类相同: 示 ...
- 【Spring】AOP实现原理
注册AOP代理创建器 在平时开发过程中,如果想开启AOP,一般会使用@EnableAspectJAutoProxy注解,这样在启动时,它会向Spring容器注册一个代理创建器用于创建代理对象,AOP使 ...
- 再见,Spring!你好,Solon!
Solon 是什么框架? Java 生态级应用开发框架.从零开始构建,有自己的标准规范与开放生态(历时五年,具备全球第二级别的生态规模).与其他框架相比,解决了两个重要的痛点:启动慢,费内存. 解决痛 ...
- 关于.net4.0使用WhenAny实现Task超时机制
.net4.0想要使用await/async语法糖必须要引用: Microsoft.Bcl Microsoft.Bcl.Async Microsoft.Bcl.Build 可以从nuget引用此三个包 ...
- 在centos7上使用 docker安装mongodb挂载宿主机以及创建其数据库的用户名和密码(最新版本)
前言 因为博主在使用docker安装mongodb并挂载时,发现在网上搜了好多都是以前版本的mongodb,并且按照他们操作总是在进入mongodb出问题,博主搞了好久终于弄好了,故写下博客,供有需要 ...
- 基于springboot+vue开发的教师工作量管理系
教师工作量管理系 springboot31 摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟.本文介绍了教师工作量管理系统的开发全过程.通过分析教师工作量管理系统 ...
- 在RT-thread studio 中生成 Doxgen文档
转载自RTT论坛 实测可以使用