redis 简单整理——内存的优化[二十七]
前言
简单介绍一下内存的优化。
正文
Redis所有的数据都在内存中,而内存又是非常宝贵的资源。如何优化内存的使用一直是Redis用户非常关注的问题。本节深入到Redis细节中,探索内存优化的技巧。
redisObject对象
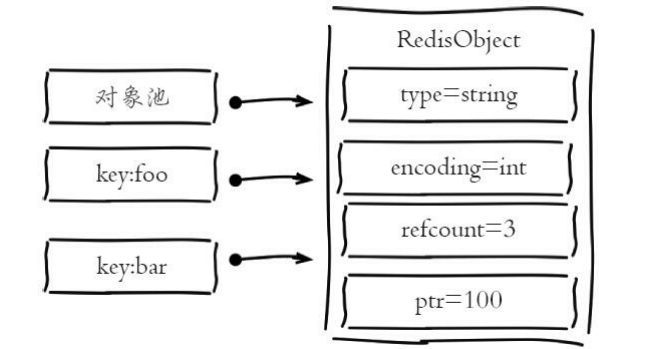
Redis存储的所有值对象在内部定义为redisObject结构体,内部结构如图:

Redis存储的数据都使用redisObject来封装,包括string、hash、list、 set、zset在内的所有数据类型。理解redisObject对内存优化非常有帮助,下 面针对每个字段做详细说明:
·type字段:表示当前对象使用的数据类型,Redis主要支持5种数据类型:string、hash、list、set、zset。可以使用type{key}命令查看对象所属类 型,type命令返回的是值对象类型,键都是string类型。
encoding字段:表示Redis内部编码类型,encoding在Redis内部使用, 代表当前对象内部采用哪种数据结构实现。理解Redis内部编码方式对于优 化内存非常重要,同一个对象采用不同的编码实现内存占用存在明显差异。
lru字段:记录对象最后一次被访问的时间,当配置了maxmemory和 maxmemory-policy=volatile-lru或者allkeys-lru时,用于辅助LRU算法删除键数 据。可以使用object idletime{key}命令在不更新lru字段情况下查看当前键的 空闲时间。
开发提示:
可以使用scan+object idletime命令批量查询哪些键长时间未被访问,找 出长时间不访问的键进行清理,可降低内存占用。
refcount字段:记录当前对象被引用的次数,用于通过引用次数回收内 存,当refcount=0时,可以安全回收当前对象空间。使用object refcount{key} 获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享 对象的方式来节省内存。
*ptr字段:与对象的数据内容相关,如果是整数,直接存储数据;否则 表示指向数据的指针。Redis在3.0之后对值对象是字符串且长度<=39字节的 数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要 一次内存操作即可。
高并发写入场景中,在条件允许的情况下,建议字符串长度控制在39字 节以内,减少创建redisObject内存分配次数,从而提高性能。
缩减键值对象
降低Redis内存使用最直接的方式就是缩减键(key)和值(value)的长 度。
·key长度:如在设计键时,在完整描述业务情况下,键值越短越好。如 user:{uid}:friends:notify:{fid}可以简化为u:{uid}:fs:nt:{fid}。
·value长度:值对象缩减比较复杂,常见需求是把业务对象序列化成二 进制数组放入Redis。
首先应该在业务上精简业务对象,去掉不必要的属性 避免存储无效数据。其次在序列化工具选择上,应该选择更高效的序列化工 具来降低字节数组大小。
以Java为例,内置的序列化方式无论从速度还是压 缩比都不尽如人意,这时可以选择更高效的序列化工具,如:protostuff、 kryo等,图8-7是Java常见序列化工具空间压缩对比。
值对象除了存储二进制数据之外,通常还会使用通用格式存储数据比 如:json、xml等作为字符串存储在Redis中。
这种方式优点是方便调试和跨语言,但是同样的数据相比字节数组所需的空间更大,在内存紧张的情况 下,可以使用通用压缩算法压缩json、xml后再存入Redis,从而降低内存占 用,例如使用GZIP压缩后的json可降低约60%的空间
开发提示:
当频繁压缩解压json等文本数据时,开发人员需要考虑压缩速度和计算 开销成本,这里推荐使用Google的Snappy压缩工具,在特定的压缩率情况下 效率远远高于GZIP等传统压缩工具,且支持所有主流语言环境
共享对象池
共享对象池是指Redis内部维护[0-9999]的整数对象池。
创建大量的整数 类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚 至超过了整数自身空间消耗。
所以Redis内存维护一个[0-9999]的整数对象 池,用于节约内存。
除了整数值对象,其他类型如list、hash、set、zset内部 元素也可以使用整数对象池。因此开发中在满足需求的前提下,尽量使用整 数对象以节省内存。
整数对象池在Redis中通过变量REDIS_SHARED_INTEGERS定义,不能 通过配置修改。可以通过object refcount命令查看对象引用数验证是否启用整 数对象池技术,如下:

设置键foo等于100时,直接使用共享池内整数对象,因此引用数是2, 再设置键bar等于100时,引用数又变为3

使用共享对象池后,相同的数据内存使用降低30%以上。可见当数据大 量使用[0-9999]的整数时,共享对象池可以节约大量内存。
需要注意的是对 象池并不是只要存储[0-9999]的整数就可以工作。当设置maxmemory并启用 LRU相关淘汰策略如:volatile-lru,allkeys-lru时,Redis禁止使用共享对象 池,测试命令如下:
为什么开启maxmemory和LRU淘汰策略后对象池无效?
RU算法需要获取对象最后被访问时间,以便淘汰最长未访问数据,每 个对象最后访问时间存储在redisObject对象的lru字段。
对象共享意味着多个 引用共享同一个redisObject,这时lru字段也会被共享,导致无法获取每个对 象的最后访问时间。如果没有设置maxmemory,直到内存被用尽Redis也不 会触发内存回收,所以共享对象池可以正常工作。
综上所述,共享对象池与maxmemory+LRU策略冲突,使用时需要注 意。对于ziplist编码的值对象,即使内部数据为整数也无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本过高,ziplist 编码细节后面内容详细说明。
为什么只有整数对象池?
首先整数对象池复用的几率最大,其次对象共享的一个关键操作就是判断相等性,Redis之所以只有整数对象池,是因为整数比较算法时间复杂度 为O(1),只保留一万个整数为了防止对象池浪费。
如果是字符串判断相 等性,时间复杂度变为O(n),特别是长字符串更消耗性能(浮点数在 Redis内部使用字符串存储)。
对于更复杂的数据结构如hash、list等,相等 性判断需要O(n2)。
对于单线程的Redis来说,这样的开销显然不合理,因 此Redis只保留整数共享对象池。
字符串优化
字符串对象是Redis内部最常用的数据类型。所有的键都是字符串类 型,值对象数据除了整数之外都使用字符串存储。比如执行命令:lpush cache:type"redis""memcache""tair""levelDB",Redis首先创建"cache:type"键 字符串,然后创建链表对象,链表对象内再包含四个字符串对象,排除 Redis内部用到的字符串对象之外至少创建5个字符串对象。可见字符串对象 在Redis内部使用非常广泛,因此深刻理解Redis字符串对于内存优化非常有帮助。
1.字符串结构
Redis没有采用原生C语言的字符串类型而是自己实现了字符串结构,内 部简单动态字符串(simple dynamic string,SDS)。
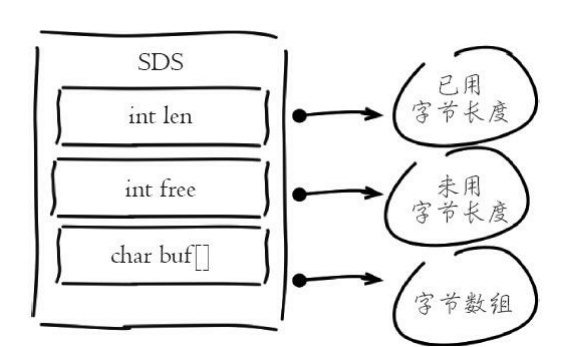
Redis自身实现的字符串结构有如下特点:
·O(1)时间复杂度获取:字符串长度、已用长度、未用长度。
·可用于保存字节数组,支持安全的二进制数据存储。
·内部实现空间预分配机制,降低内存再分配次数。
·惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。
预分配机制:
因为字符串(SDS)存在预分配机制,日常开发中要小心预分配带来的内存浪费。
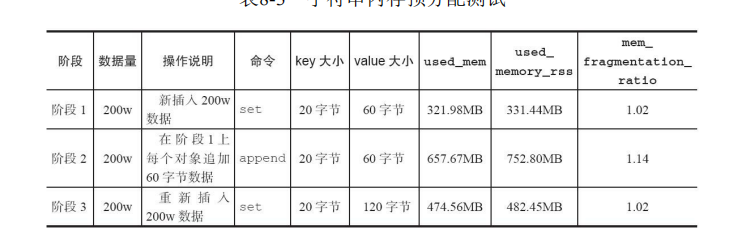
从测试数据可以看出,同样的数据追加后内存消耗非常严重,下面我们 结合图来分析这一现象。
尽量减少字符串频繁修改操作如append、setrange,改为直接使用set修 改字符串,降低预分配带来的内存浪费和内存碎片化。
字符串重构:指不一定把每份数据作为字符串整体存储,像json这样的 数据可以使用hash结构,使用二级结构存储也能帮我们节省内存。同时可以 使用hmget、hmset命令支持字段的部分读取修改,而不用每次整体存取。

根据测试结构,第一次默认配置下使用hash类型,内存消耗不但没有降 低反而比字符串存储多出2倍,而调整hash-max-ziplist-value=66之后内存降 低为535.60M。因为json的videoAlbumPic属性长度是65,而hash-max-ziplist- value默认值是64,Redis采用hashtable编码方式,反而消耗了大量内存。调 整配置后hash类型内部编码方式变为ziplist,相比字符串更省内存且支持属性的部分操作。下一节将具体介绍ziplist编码优化细节。
编码优化
Redis对外提供了string、list、hash、set、zet等类型,但是Redis内部针对 不同类型存在编码的概念,所谓编码就是具体使用哪种底层数据结构来实 现。编码不同将直接影响数据的内存占用和读写效率。使用object encoding{key}命令获取编码类型。
Redis针对每种数据类型(type)可以采用至少两种编码方式来实现。
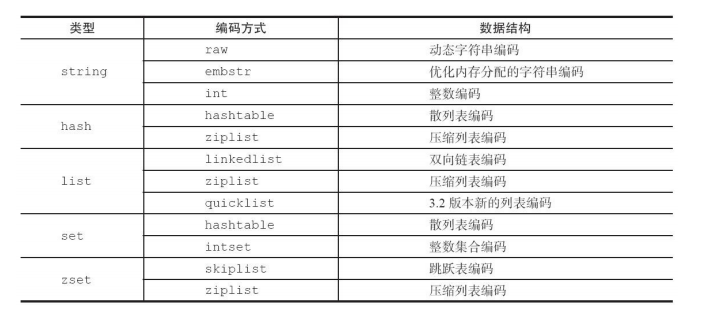
了解编码和类型对应关系之后,我们不禁疑惑Redis为什么对一种数据 结构实现多种编码方式?
------------恢复内容结束------------
------------恢复内容开始------------
前言
简单介绍一下内存的优化。
正文
Redis所有的数据都在内存中,而内存又是非常宝贵的资源。如何优化内存的使用一直是Redis用户非常关注的问题。本节深入到Redis细节中,探索内存优化的技巧。
redisObject对象
Redis存储的所有值对象在内部定义为redisObject结构体,内部结构如图:
Redis存储的数据都使用redisObject来封装,包括string、hash、list、 set、zset在内的所有数据类型。理解redisObject对内存优化非常有帮助,下 面针对每个字段做详细说明:
·type字段:表示当前对象使用的数据类型,Redis主要支持5种数据类型:string、hash、list、set、zset。可以使用type{key}命令查看对象所属类 型,type命令返回的是值对象类型,键都是string类型。
encoding字段:表示Redis内部编码类型,encoding在Redis内部使用, 代表当前对象内部采用哪种数据结构实现。理解Redis内部编码方式对于优 化内存非常重要,同一个对象采用不同的编码实现内存占用存在明显差异。
lru字段:记录对象最后一次被访问的时间,当配置了maxmemory和 maxmemory-policy=volatile-lru或者allkeys-lru时,用于辅助LRU算法删除键数 据。可以使用object idletime{key}命令在不更新lru字段情况下查看当前键的 空闲时间。
开发提示:
可以使用scan+object idletime命令批量查询哪些键长时间未被访问,找 出长时间不访问的键进行清理,可降低内存占用。
refcount字段:记录当前对象被引用的次数,用于通过引用次数回收内 存,当refcount=0时,可以安全回收当前对象空间。使用object refcount{key} 获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享 对象的方式来节省内存。
*ptr字段:与对象的数据内容相关,如果是整数,直接存储数据;否则 表示指向数据的指针。Redis在3.0之后对值对象是字符串且长度<=39字节的 数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要 一次内存操作即可。
高并发写入场景中,在条件允许的情况下,建议字符串长度控制在39字 节以内,减少创建redisObject内存分配次数,从而提高性能。
缩减键值对象
降低Redis内存使用最直接的方式就是缩减键(key)和值(value)的长 度。
·key长度:如在设计键时,在完整描述业务情况下,键值越短越好。如 user:{uid}:friends:notify:{fid}可以简化为u:{uid}:fs:nt:{fid}。
·value长度:值对象缩减比较复杂,常见需求是把业务对象序列化成二 进制数组放入Redis。
首先应该在业务上精简业务对象,去掉不必要的属性 避免存储无效数据。其次在序列化工具选择上,应该选择更高效的序列化工 具来降低字节数组大小。
以Java为例,内置的序列化方式无论从速度还是压 缩比都不尽如人意,这时可以选择更高效的序列化工具,如:protostuff、 kryo等,图8-7是Java常见序列化工具空间压缩对比。
值对象除了存储二进制数据之外,通常还会使用通用格式存储数据比 如:json、xml等作为字符串存储在Redis中。
这种方式优点是方便调试和跨语言,但是同样的数据相比字节数组所需的空间更大,在内存紧张的情况 下,可以使用通用压缩算法压缩json、xml后再存入Redis,从而降低内存占 用,例如使用GZIP压缩后的json可降低约60%的空间
开发提示:
当频繁压缩解压json等文本数据时,开发人员需要考虑压缩速度和计算 开销成本,这里推荐使用Google的Snappy压缩工具,在特定的压缩率情况下 效率远远高于GZIP等传统压缩工具,且支持所有主流语言环境
共享对象池
共享对象池是指Redis内部维护[0-9999]的整数对象池。
创建大量的整数 类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚 至超过了整数自身空间消耗。
所以Redis内存维护一个[0-9999]的整数对象 池,用于节约内存。
除了整数值对象,其他类型如list、hash、set、zset内部 元素也可以使用整数对象池。因此开发中在满足需求的前提下,尽量使用整 数对象以节省内存。
整数对象池在Redis中通过变量REDIS_SHARED_INTEGERS定义,不能 通过配置修改。可以通过object refcount命令查看对象引用数验证是否启用整 数对象池技术,如下:
设置键foo等于100时,直接使用共享池内整数对象,因此引用数是2, 再设置键bar等于100时,引用数又变为3
使用共享对象池后,相同的数据内存使用降低30%以上。可见当数据大 量使用[0-9999]的整数时,共享对象池可以节约大量内存。
需要注意的是对 象池并不是只要存储[0-9999]的整数就可以工作。当设置maxmemory并启用 LRU相关淘汰策略如:volatile-lru,allkeys-lru时,Redis禁止使用共享对象 池,测试命令如下:
为什么开启maxmemory和LRU淘汰策略后对象池无效?
RU算法需要获取对象最后被访问时间,以便淘汰最长未访问数据,每 个对象最后访问时间存储在redisObject对象的lru字段。
对象共享意味着多个 引用共享同一个redisObject,这时lru字段也会被共享,导致无法获取每个对 象的最后访问时间。如果没有设置maxmemory,直到内存被用尽Redis也不 会触发内存回收,所以共享对象池可以正常工作。
综上所述,共享对象池与maxmemory+LRU策略冲突,使用时需要注 意。对于ziplist编码的值对象,即使内部数据为整数也无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本过高,ziplist 编码细节后面内容详细说明。
为什么只有整数对象池?
首先整数对象池复用的几率最大,其次对象共享的一个关键操作就是判断相等性,Redis之所以只有整数对象池,是因为整数比较算法时间复杂度 为O(1),只保留一万个整数为了防止对象池浪费。
如果是字符串判断相 等性,时间复杂度变为O(n),特别是长字符串更消耗性能(浮点数在 Redis内部使用字符串存储)。
对于更复杂的数据结构如hash、list等,相等 性判断需要O(n2)。
对于单线程的Redis来说,这样的开销显然不合理,因 此Redis只保留整数共享对象池。
字符串优化
字符串对象是Redis内部最常用的数据类型。所有的键都是字符串类 型,值对象数据除了整数之外都使用字符串存储。比如执行命令:lpush cache:type"redis""memcache""tair""levelDB",Redis首先创建"cache:type"键 字符串,然后创建链表对象,链表对象内再包含四个字符串对象,排除 Redis内部用到的字符串对象之外至少创建5个字符串对象。可见字符串对象 在Redis内部使用非常广泛,因此深刻理解Redis字符串对于内存优化非常有帮助。
1.字符串结构
Redis没有采用原生C语言的字符串类型而是自己实现了字符串结构,内 部简单动态字符串(simple dynamic string,SDS)。
Redis自身实现的字符串结构有如下特点:
·O(1)时间复杂度获取:字符串长度、已用长度、未用长度。
·可用于保存字节数组,支持安全的二进制数据存储。
·内部实现空间预分配机制,降低内存再分配次数。
·惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。
预分配机制:
因为字符串(SDS)存在预分配机制,日常开发中要小心预分配带来的内存浪费。
从测试数据可以看出,同样的数据追加后内存消耗非常严重,下面我们 结合图来分析这一现象。
尽量减少字符串频繁修改操作如append、setrange,改为直接使用set修 改字符串,降低预分配带来的内存浪费和内存碎片化。
字符串重构:指不一定把每份数据作为字符串整体存储,像json这样的 数据可以使用hash结构,使用二级结构存储也能帮我们节省内存。同时可以 使用hmget、hmset命令支持字段的部分读取修改,而不用每次整体存取。
根据测试结构,第一次默认配置下使用hash类型,内存消耗不但没有降 低反而比字符串存储多出2倍,而调整hash-max-ziplist-value=66之后内存降 低为535.60M。因为json的videoAlbumPic属性长度是65,而hash-max-ziplist- value默认值是64,Redis采用hashtable编码方式,反而消耗了大量内存。调 整配置后hash类型内部编码方式变为ziplist,相比字符串更省内存且支持属性的部分操作。下一节将具体介绍ziplist编码优化细节。
编码优化
Redis对外提供了string、list、hash、set、zet等类型,但是Redis内部针对 不同类型存在编码的概念,所谓编码就是具体使用哪种底层数据结构来实 现。编码不同将直接影响数据的内存占用和读写效率。使用object encoding{key}命令获取编码类型。
Redis针对每种数据类型(type)可以采用至少两种编码方式来实现。
了解编码和类型对应关系之后,我们不禁疑惑Redis为什么对一种数据 结构实现多种编码方式?
了解编码和类型对应关系之后,我们不禁疑惑Redis为什么对一种数据 结构实现多种编码方式? 主要原因是Redis作者想通过不同编码实现效率和空间的平衡。
比如当 我们的存储只有10个元素的列表,当使用双向链表数据结构时,必然需要维 护大量的内部字段如每个元素需要:前置指针,后置指针,数据指针等,造 成空间浪费,如果采用连续内存结构的压缩列表(ziplist),将会节省大量 内存,而由于数据长度较小,存取操作时间复杂度即使为O(n2)性能也可 满足需求。
编码类型转换在Redis写入数据时自动完成,这个转换过程是不可逆 的,转换规则只能从小内存编码向大内存编码转换。

以上命令体现了list类型编码的转换过程,其中Redis之所以不支持编码 回退,主要是数据增删频繁时,数据向压缩编码转换非常消耗CPU,得不偿 失。以上示例用到了list-max-ziplist-entries参数,这个参数用来决定列表长度 在多少范围内使用ziplist编码。

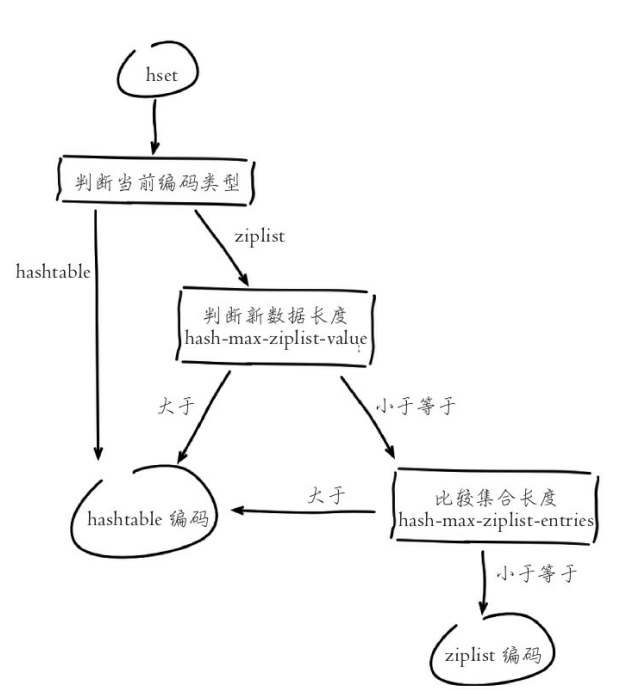
理解编码转换流程和相关配置之后,可以使用config set命令设置编码相 关参数来满足使用压缩编码的条件。对于已经采用非压缩编码类型的数据如 hashtable、linkedlist等,设置参数后即使数据满足压缩编码条件,Redis也不 会做转换,需要重启Redis重新加载数据才能完成转换。
ziplist编码主要目的是为了节约内存,因此所有数据都是采用线性连续 的内存结构。ziplist编码是应用范围最广的一种,可以分别作为hash、list、 zset类型的底层数据结构实现。首先从ziplist编码结构开始分析,它的内部结 构类似这样:<....> 。一个ziplist可以包含多个entry(元素),每个entry保存具体的数据 (整数或者字节数组)。
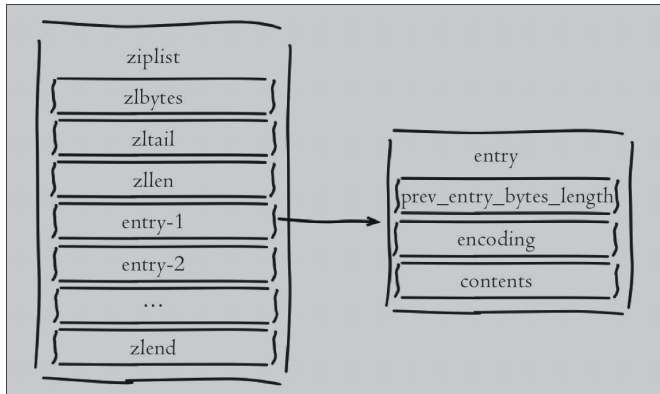
1)zlbytes:记录整个压缩列表所占字节长度,方便重新调整ziplist空 间。类型是int-32,长度为4字节。
2)zltail:记录距离尾节点的偏移量,方便尾节点弹出操作。类型是int- 32,长度为4字节。
3)zllen:记录压缩链表节点数量,当长度超过216-2时需要遍历整个列 表获取长度,一般很少见。类型是int-16,长度为2字节。
4)entry:记录具体的节点,长度根据实际存储的数据而定。
a)prev_entry_bytes_length:记录前一个节点所占空间,用于快速定位 上一个节点,可实现列表反向迭代。
b)encoding:标示当前节点编码和长度,前两位表示编码类型:字符 串/整数,其余位表示数据长度。
c)contents:保存节点的值,针对实际数据长度做内存占用优化。
5)zlend:记录列表结尾,占用一个字节。 根据以上对ziplist字段说明,可以分析出该数据结构特点如下: ·内部表现为数据紧凑排列的一块连续内存数组。 ·可以模拟双向链表结构,以O(1)时间复杂度入队和出队。
·新增删除操作涉及内存重新分配或释放,加大了操作的复杂性。
·读写操作涉及复杂的指针移动,最坏时间复杂度为O(n2)
·适合存储小对象和长度有限的数据。

测试数据采用100W个36字节数据,划分为1000个键,每个类型长度统 一为1000。从测试结果可以看出:
1)使用ziplist可以分别作为hash、list、zset数据类型实现。
2)使用ziplist编码类型可以大幅降低内存占用。
3)ziplist实现的数据类型相比原生结构,命令操作更加耗时,不同类型 耗时排序:list<hash<zset。
ziplist压缩编码的性能表现跟值长度和元素个数密切相关,正因为如此 Redis提供了{type}-max-ziplist-value和{type}-max-ziplist-entries相关参数来做 控制ziplist编码转换。
最后再次强调使用ziplist压缩编码的原则:追求空间和 时间的平衡。
开发技巧:
针对性能要求较高的场景使用ziplist,建议长度不要超过1000,每个元 素大小控制在512字节以内。 命令平均耗时使用info Commandstats命令获取,包含每个命令调用次 数、总耗时、平均耗时,单位为微秒
intset编码:
intset编码是集合(set)类型编码的一种,内部表现为存储有序、不重 复的整数集。当集合只包含整数且长度不超过set-max-intset-entries配置时被 启用。

以上命令可以看出intset对写入整数进行排序,通过O(log(n))时间 复杂度实现查找和去重操作.
intset的字段结构含义:
1)encoding:整数表示类型,根据集合内最长整数值确定类型,整数 类型划分为三种:int-16、int-32、int-64。
2)length:表示集合元素个数。
3)contents:整数数组,按从小到大顺序保存。
intset保存的整数类型根据长度划分,当保存的整数超出当前类型时, 将会触发自动升级操作且升级后不再做回退。升级操作将会导致重新申请内 存空间,把原有数据按转换类型后拷贝到新数组。
使用intset编码的集合时,尽量保持整数范围一致,如都在int-16范围 内。防止个别大整数触发集合升级操作,产生内存浪费。
下面通过测试查看ziplist编码的集合内存和速度表现:

根据以上测试结果发现intset表现非常好,同样的数据内存占用只有不 到hashtable编码的十分之一。
intset数据结构插入命令复杂度为O(n),查询 命令为O(log(n)),由于整数占用空间非常小,所以在集合长度可控的 基础上,写入命令执行速度也会非常快,因此当使用整数集合时尽量使用 intset编码。
第三行把ziplist-hash类型也放入其中,主要因为intset 编码必须存储整数,当集合内保存非整数数据时,无法使用intset实现内存 优化。这时可以使用ziplist-hash类型对象模拟集合类型,hash的field当作集 合中的元素,value设置为1字节占位符即可。使用ziplist编码的hash类型依然 比使用hashtable编码的集合节省大量内存。
控制键的数量
当使用Redis存储大量数据时,通常会存在大量键,过多的键同样会消 耗大量内存。
Redis本质是一个数据结构服务器,它为我们提供多种数据结 构,如hash、list、set、zset等。使用Redis时不要进入一个误区,大量使用 get/set这样的API,把Redis当成Memcached使用。
对于存储相同的数据内容 利用Redis的数据结构降低外层键的数量,也可以节省大量内存。
通过在客户端预估键规模,把大量键分组映射到多个hash结构中降低 键的数量.
hash结构降低键数量分析:
根据键规模在客户端通过分组映射到一组hash对象中,如存在100万个 键,可以映射到1000个hash中,每个hash保存1000个元素。
·hash的field可用于记录原始key字符串,方便哈希查找。
.hash的value保存原始值对象,确保不要超过hash-max-ziplist-value限制。
下面测试这种优化技巧的内存表现:
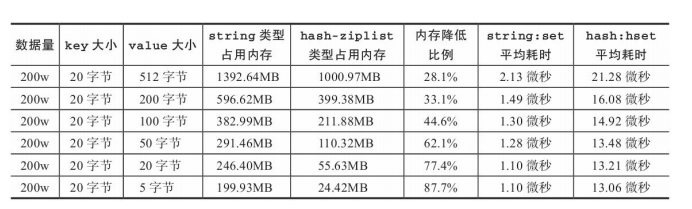
·同样的数据使用ziplist编码的hash类型存储比string类型节约内存。
·节省内存量随着value空间的减少越来越明显。
·hash-ziplist类型比string类型写入耗时,但随着value空间的减少,耗时 逐渐降低。
使用hash重构后节省内存量效果非常明显,特别对于存储小对象的场 景,内存只有不到原来的1/5。下面分析这种内存优化技巧的关键点:
1)hash类型节省内存的原理是使用ziplist编码,如果使用hashtable编码 方式反而会增加内存消耗。
2)ziplist长度需要控制在1000以内,否则由于存取操作时间复杂度在 O(n)到O(n2)之间,长列表会导致CPU消耗严重,得不偿失。
3)ziplist适合存储小对象,对于大对象不但内存优化效果不明显还会增 加命令操作耗时。
4)需要预估键的规模,从而确定每个hash结构需要存储的元素数量。
5)根据hash长度和元素大小,调整hash-max-ziplist-entries和hash-max- ziplist-value参数,确保hash类型使用ziplist编码。
关于hash键和field键的设计:
1)当键离散度较高时,可以按字符串位截取,把后三位作为哈希的 field,之前部分作为哈希的键。如:key=1948480哈希key=group:hash: 1948,哈希field=480
2)当键离散度较低时,可以使用哈希算法打散键,如:使用 crc32(key)&10000函数把所有的键映射到“0-9999”整数范围内,哈希field 存储键的原始值。
3)尽量减少hash键和field的长度,如使用部分键内容。
使用hash结构控制键的规模虽然可以大幅降低内存,但同样会带来问 题,需要提前做好规避处理。如下所示:
·客户端需要预估键的规模并设计hash分组规则,加重客户端开发成 本。
·hash重构后所有的键无法再使用超时(expire)和LRU淘汰机制自动删 除,需要手动维护删除。
·对于大对象,如1KB以上的对象,使用hash-ziplist结构控制键数量反而 得不偿失。
不过瑕不掩瑜,对于大量小对象的存储场景,非常适合使用ziplist编码 的hash类型控制键的规模来降低内存。
开发提示:
使用ziplist+hash优化keys后,如果想使用超时删除功能,开发人员可以 存储每个对象写入的时间,再通过定时任务使用hscan命令扫描数据,找出 hash内超时的数据项删除即可。
本节主要讲解Redis内存优化技巧,Redis的数据特性是“all in memory”, 优化内存将变得非常重要。
对于内存优化建议读者先要掌握Redis内存存储的特性比如字符串、压缩编码、整数集合等,再根据数据规模和所用命令需求去调整,从而达到空间和效率的最佳平衡。
建议使用Redis存储大量数据时,把内存优化环节加入到前期设计阶段,否则数据大幅增长后,开发人员需要面对重新优化内存所带来开发和数据迁移的双重成本。
当Redis内存不足时,首先考虑的问题不是加机器做水平扩展,应该先尝试做内存优化,当 遇到瓶颈时,再去考虑水平扩展。即使对于集群化方案,垂直层面优化也同 样重要,避免不必要的资源浪费和集群化后的管理成本。
总结
1)Redis实际内存消耗主要包括:键值对象、缓冲区内存、内存碎片。
2)通过调整maxmemory控制Redis最大可用内存。当内存使用超出时, 根据maxmemory-policy控制内存回收策略。
3)内存是相对宝贵的资源,通过合理的优化可以有效地降低内存的使 用量,内存优化的思路包括
·精简键值对大小,键值字面量精简,使用高效二进制序列化工具。
·使用对象共享池优化小整数对象。
·数据优先使用整数,比字符串类型更节省空间。
·优化字符串使用,避免预分配造成的内存浪费。
·使用ziplist压缩编码优化hash、list等结构,注重效率和空间的平衡。
·使用intset编码优化整数集合。
.使用ziplist编码的hash结构降低小对象链规模。
结
下一节哨兵模式。
redis 简单整理——内存的优化[二十七]的更多相关文章
- Redis内存使用优化与存储
抄自http://www.infoq.com/cn/articles/tq-redis-memory-usage-optimization-storage 本文将对Redis的常见数据类型的使用场景以 ...
- Redis内存使用优化与存储(转)
Redis常用数据类型 Redis最为常用的数据类型主要有以下五种: String Hash List Set Sorted set 在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部 ...
- Redis 内存使用优化与存储
Redis 常用数据类型 Redis 最为常用的数据类型主要有以下五种: • String • Hash • List • Set • Sorted set 在具体描述这几种数据类型之前,我们先通过一 ...
- 面试简单整理之Redis
179.redis 是什么?都有哪些使用场景? Redis是一个key-value存储系统. 缓存,消息队列,排行榜/计数器,分布式架构,做session共享 180.redis 有哪些功能? 181 ...
- NoSQL数据库:Redis内存使用优化与存储
Redis常用数据类型 Redis最为常用的数据类型主要有以下五种: ●String ●Hash ●List ●Set ●Sorted set 在具体描述这几种数据类型之前,我们先通过一张图了解下Re ...
- [转帖]美团在Redis上踩过的一些坑-4.redis内存使用优化
美团在Redis上踩过的一些坑-4.redis内存使用优化 博客分类: 运维 redis redisstringhash优化segment-hash 转载请注明出处哈:http://carlosfu ...
- 分布式缓存技术redis学习系列(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- 分布式缓存技术redis学习(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- 重新整理 .net core 实践篇—————仓储层的具体实现[二十七]
前言 简单整理一下仓储层. 正文 在共享层的基础建设类库中: /// <summary> /// 泛型仓储接口 /// </summary> /// <typeparam ...
- Chrome V8系列--浅析Chrome V8引擎中的垃圾回收机制和内存泄露优化策略
V8 实现了准确式 GC,GC 算法采用了分代式垃圾回收机制.因此,V8 将内存(堆)分为新生代和老生代两部分. 一.前言 V8的垃圾回收机制:JavaScript使用垃圾回收机制来自动管理内存.垃圾 ...
随机推荐
- $help console 里面的入口帮助文档
$help console 里面的入口帮助文档 Object.defineProperty(window, '$help', { get: function() { // 这里面this是window ...
- Dreamweaver基础教程:学习CSS
目录 CSS 简介 CSS 语法 Id 和 Class id 选择器 class 选择器 CSS 创建 外部样式表 内部样式表 内联样式 多重样式 多重样式优先级 背景(background) 背景颜 ...
- Markdown表情参考
emoji-github 文章内容来源 https://github.com/hoangdqvn/emoji-github/blob/master/README.md ️ Emoji-GIT Peop ...
- KTL 最新版
K,K线,Candle蜡烛图. T,技术分析,工具平台 L,公式Language语言使用c++14,Lite小巧简易. 项目仓库:https://github.com/bbqz007/KTL Core ...
- Clang RecursiveASTVisitor & ASTFrontendActions based on it
RecursiveASTVisitor Basics 类声明 template<typename Derived> class clang::RecursiveASTVisitor< ...
- 补充--关于nginx服务器多个网站如何设置404的问题?
补充--关于nginx服务器多个网站如何设置404的问题? 需求1 :设置多个网站404页面为一个 都需配置网站的nginx.conf,以上面的多网站为例,404发布目录下,每个的nginx.conf ...
- Linux安装Oracle12C及一些参考
目录 安装 系统配置 安装前装备 安装依赖包 创建用户和组 修改内核参数 修改系统资源限制 创建安装目录及设置权限 设置oracle环境变量 安装Oracle 一些参考 compat-libstdc+ ...
- KingbaseES V8R6 集群运维系列--sys_monitor.sh stop关闭集群分析
案例说明: 对于KingbaseES V8R6集群关闭整个集群通过执行'sys_monitor.sh stop'命令完成,本案例解析了在执行'sys_monitor.sh stop'后,数据库的关闭方 ...
- python---nltk工具包安装
先在pycharm里安装nltk cmd进入Python输入 import nltk nltk.download()如果下载失败在github上下载语料库:https://github.com/nlt ...
- 在Ubuntu上安装MySQL
在Ubuntu上安装MySQL sudo apt update sudo apt install mysql-server 安装完成后,MySQL服务将自动启动.要验证MySQL服务器正在运行,请输入 ...