架构设计|基于 raft-listener 实现实时同步的主备集群
背景以及需求
- 线上业务对数据库可用性可靠性要求较高,要求需要有双 AZ 的主备容灾机制。
- 主备集群要求数据和 schema 信息实时同步,数据同步平均时延要求在 1s 之内,p99 要求在 2s 之内。
- 主备集群数据要求一致
- 要求能够在主集群故障时高效自动主备倒换或者手动主备倒换,主备倒换期间丢失的数据可找回。
为什么使用 Listener
Listener:这是一种特殊的 Raft 角色,并不参与投票,也不能用于多副本的数据一致性。
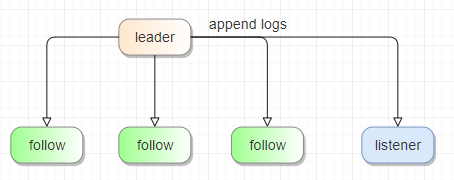
原本的 NebulaGraph 中的 Listener 是一个 Raft 监听器,它的作用是将数据异步写入外部的 Elasticsearch 集群,并在查询时去查找 ES 以实现全文索引的功能。
这里我们需要的是 Listener 的监听能力,用于快速同步数据到其他集群,并且是异步的执行,不影响主集群的正常读写。
这里我们需要定义两个新的 Listener 类型:
- Meta Listener:用于同步表结构以及其他元数据信息
- Storage Listener:用于同步 storaged 服务的数据
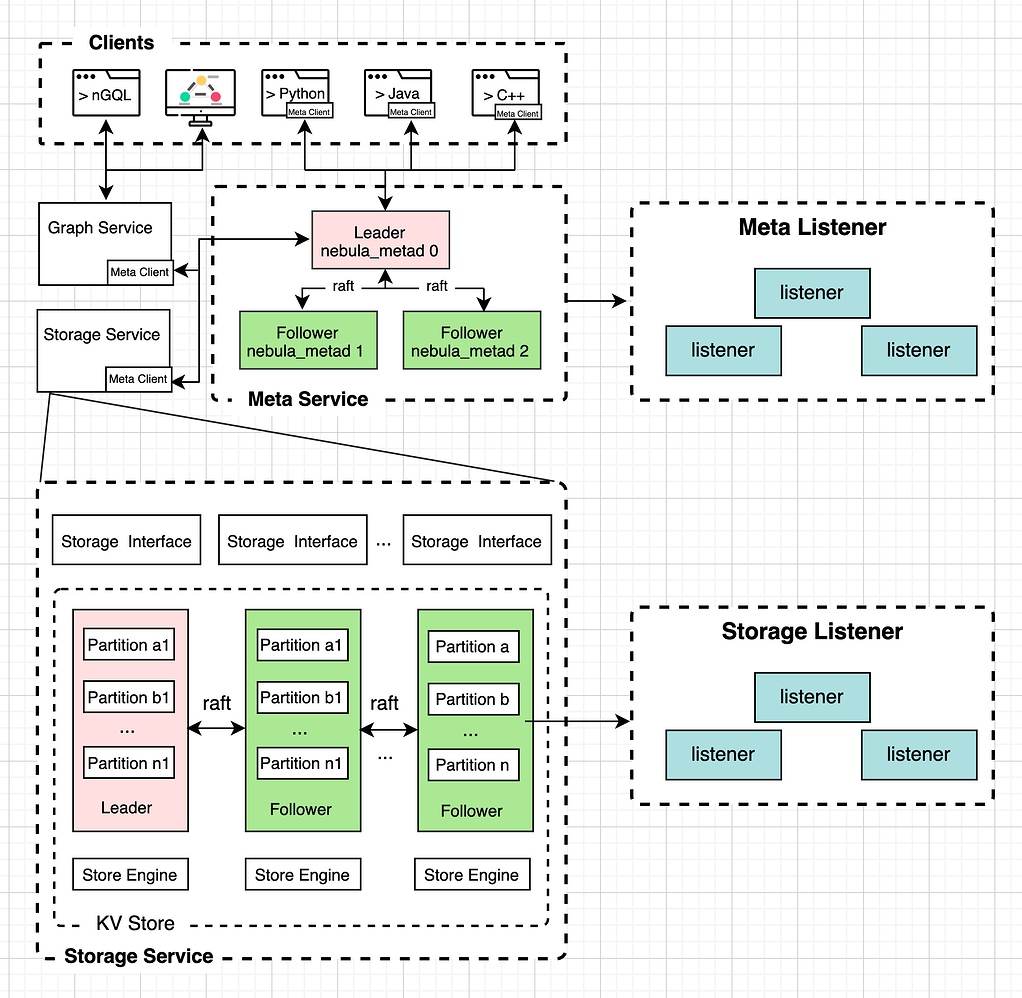
这样 storaged 服务和 metad 服务的 part leader 节点接受到写请求时,除了同步一份数据给 follower 节点,也会同步一份给各自的 listener 节点。
备集群如何接受数据?
现在我们面临几个问题:
- 两个新增 Listener 在接收到 leader 同步的日志后,应该如何再同步给备集群?
- 我们需要匹配和解析不同的数据操作,例如添加点、删除点、删除边、删除带索引的数据等等操作;
- 我们需要将解析到的不同操作的数据重新组装成一个请求发送给备集群的 storaged 服务和 metad 服务;
通过走读 nebula-storaged 的内核代码我们可以看到,无论是 metad 还是 storaged 的各种创建删除表结构以及各种类型数据的插入,最后都会序列化成一个 wal 的 log 发送给 follower 以及 listener 节点,最后存储在 RocksDB 中。
因此,我们的 listener 节点需要具备从 log 日志中解析并识别操作类型的能力,和封装成原请求的能力,因为我们需要将操作同步给备集群的 metad 以及 storaged 服务。
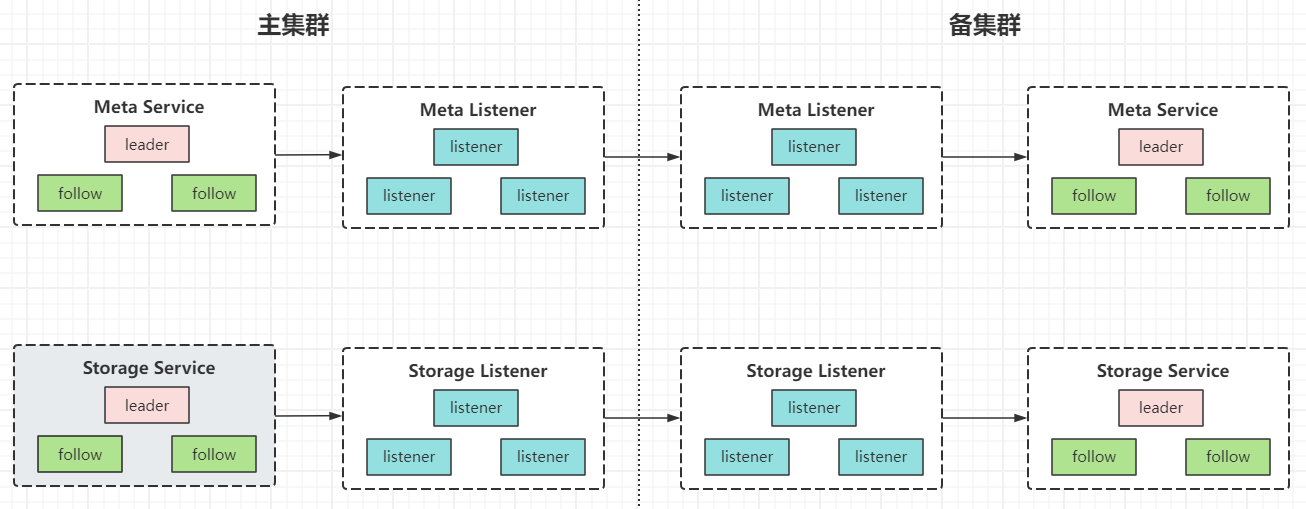
这里涉及到一个问题,主集群的 listener 需要如何感知备集群?备集群 metad 服务的信息以及 storaged 服务的信息?从架构设计上来看,两个集群之间应该有一个接口通道互相连接,但又不干涉,如果由 listener 节点直接发送请求给备集群的 nebula 进程,两个集群的边界就不是很明显了。所以这里我们再引入一个备集群的服务 listener 服务,它用于接收来自主集群的 listener 服务的请求,并将请求转发给自己集群的 metad 以及 storaged 服务。
这样做的好处。两边集群的服务模块是对称的,方便我们后面快速地做主备切换。
Listener 节点的管理和可靠性
为了保证双 AZ 环境的可靠性,很显然 Listener 节点也是需要多节点多活的,在 nebula 内核源码中是有对于 listener 的管理逻辑,但是比较简单,我们还需要设计一个 ListenerManager 实现以下几点能力:
- listener 节点注册以及删除命令
- listener 节点动态负载均衡(尽量每个 space 各个 part 分布的 listener 要均匀)
- listener 故障切换
节点注册管理以及负载均衡都比较简单好设计,比较重要的一点是故障切换应该怎么做?
listener 故障切换的设计
listener 节点故障切换的需求可以拆分为以下几个部分:
- listener 同步 wal 日志数据时周期性记录同步的进度(commitId && appendLogId);
- ListenerManager 感知到 listener 故障后,触发动态负载均衡机制,将故障 listener 的 part 分配给其他在运行的 listener;
- 分配到新 part 的 listener 们获取原先故障 listener 记录的同步进度,并以该进度为起始开始同步数据;
至于 listener 同步 wal 日志数据时周期性记录同步的进度应该记录到哪里?可以是存储到 metad 服务中,也可以存储到 storaged 服务对应的 part 中。
nebula 主备切换设计
在聊主备切换之前,我们还需要考虑一件事,那就是双 AZ 环境中,应该只能有主集群是可读可写的,而其他备集群应该是只读不能写。这样是为了保证两边数据的最终一致性,备集群的写入只能是由主集群的 listener 请求来写入的,而不能被 graphd 服务的请求写入。
所以我们需要对集群状态增加一种“只读模式”,在这种只读模式下,表明当前集群状态是处于备集群的状态,拒绝来自 graphd 服务的写操作。同样的,备集群的 listener 节点处在只读状态时,也只能接收来自主集群的请求并转发给备集群的进程,拒绝来自备集群的 wal 日志同步。
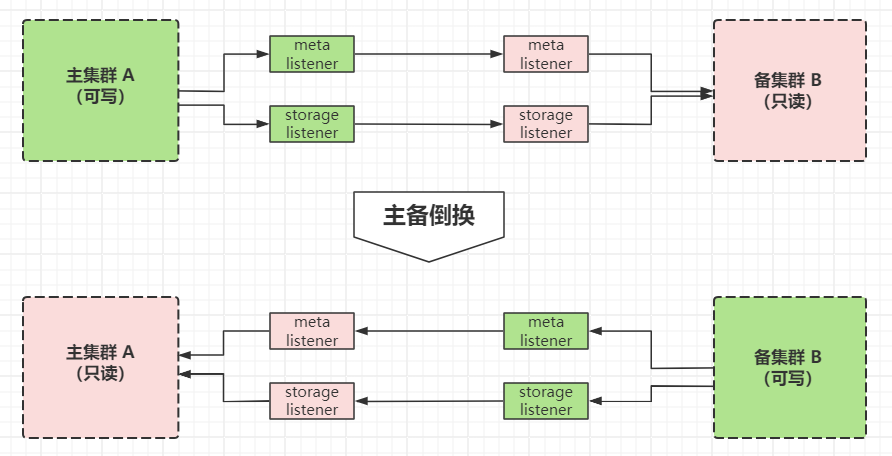
主备倒换发生时,需要有以下几个动作:
- 主集群的每个 listener 记录自己所负责的 part 的同步进度(commitId && appendLogId);
- 备集群的 nebula 服务转换为可写;
- 备集群的 listener 节点转换为可写,并且开始接收来自自己集群的 metad 和 storaged 进程的 wal 日志;
- 主集群的 listener 以及各个服务转换为只读状态,开始接收来自新的主集群的数据同步请求;
这几个动作细分下来,最主要的内容就是状态转换以及上下文信息保存和同步,原主集群需要保存自己主备切换前的上文信息(比如同步进度),新的主集群需要加载自己的数据同步起始进度(从当前最新的 commitLog 开始)
主备切换过程中的数据丢失问题
很明显,在上面的设计中,当主备切换发生时,会有一段时间的“双主”的阶段,在这个阶段内,原主集群的剩余日志已经不能再同步给备集群了,这就是会被丢失的数据。如何恢复这些被丢失的数据,可能的方案有很多,因为原主集群的同步进度是有记录的,有哪些数据还没同步完也是可以查询到的,所以可以手动或者自动去单独地同步那一段缺失数据。
当然这种方案也会引入新的问题,这段丢失地数据同步给主集群后,主集群会再次同步一遍回现在的备集群,一段 wal 数据的两次重复操作,不知道为引起什么其他的问题。
所以关于主备切换数据丢失的问题,我们还没有很好的处理方案,感兴趣的伙伴欢迎在评论区讨论。
感谢你的阅读 (///▽///)
对图数据库 NebulaGraph 感兴趣?欢迎前往 GitHub 查看源码:https://github.com/vesoft-inc/nebula;
想和其他图技术爱好者一起交流心得?和 NebulaGraph 星云小姐姐 交个朋友再进个交流群;
{kind=link}
架构设计|基于 raft-listener 实现实时同步的主备集群的更多相关文章
- 基于uReplicator复制的kafka主备集群间的切换策略
一.概述 目前基于中间件uReplicator实现了kafka集群间的迁移复制,可以实现跨区.跨云的kafka集群间复制同步,也可以实现kafka集群的冷热互备架构:在实现集群间同步以后,需要解决一个 ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
- 基于 Clusternet 与 OCM 打造新一代开放的多集群管理平台
背景 随着 5G.物联网设备的爆炸性增长以及智能终端不断增强的计算能力,带来了前所未有的数据量,传统的中心集中式计算捉襟见肘."新基建"战略的实施,工业互联网.车联网/自动驾驶.智 ...
- 基于RHCS的web双机热备集群搭建
基于RHCS的web双机热备集群搭建 RHCS集群执行原理及功能介绍 1. 分布式集群管理器(CMAN) Cluster Manager.简称CMAN.是一个分布式集群管理工具.它执行在集群的各个节 ...
- Spark运行模式_基于YARN的Resource Manager的Custer模式(集群)
使用如下命令执行应用程序: 和"基于YARN的Resource Manager的Client模式(集群)"运行模式,区别如下: 在Resource Manager端提交应用程序,会 ...
- 架构设计 | 基于电商交易流程,图解TCC事务分段提交
本文源码:GitHub·点这里 || GitEE·点这里 一.场景案例简介 1.场景描述 分布式事务在业务系统中是十分常见的,最经典的场景就是电商架构中的交易业务,如图: 客户端通过请求订单服务,执行 ...
- 架构设计 | 基于Seata中间件,微服务模式下事务管理
源码地址:GitHub·点这里 || GitEE·点这里 一.Seata简介 1.Seata组件 Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务.Seata将为用 ...
- 基于sersync海量文件实时同步
项目需求:最近涉及到数百万张图片从本地存储迁移到云存储,为了使完成图片迁移,并保证图片无缺失,业务不中断,决定采用实时同步,同步完后再做流量切换.在实时同步方案中进行了几种尝试. 方案1:rsync+ ...
- 16套java架构师,高并发,高可用,高性能,集群,大型分布式电商项目实战视频教程
16套Java架构师,集群,高可用,高可扩展,高性能,高并发,性能优化,设计模式,数据结构,虚拟机,微服务架构,日志分析,工作流,Jvm,Dubbo ,Spring boot,Spring cloud ...
- MHA-结合MySQL半同步复制高可用集群(Centos7)
目录 一.理论概述 本案例部署思路 二.环境 三.部署 部署MHA 部署二进制包MySQL及部署主从复制 部署半同步复制 配置MHA MHA测试 部署lvs+keepalived(lvs1,lvs2) ...
随机推荐
- 离线部署-docker
离线部署---docker 关键词:docker离线部署,images离线安装,docker compose,shell,minio docker离线安装 docker install offline ...
- notion database 必知必会
notion database 必知必会 用过 mysql 的同学一定很容易上手 notion .在 notion 中,掌握好 database,基本上就掌握了 notion 最核心的概念. noti ...
- ida使用入门指北
静态分析 快捷键 操作 作用 空格键 在反汇编窗口中,进行列表视图与图形视图之间的切换 TAB 在反汇编窗口中,进行汇编指令与伪代码之间的切换 Esc 和 Ctrl+Enter 翻页,返回前一页面 G ...
- C++红黑树的实现
最近闲来无事,一直没有研究过红黑树,B树,B+树之类的,打算自己用C语言实现一下它们. 红黑树的性质定义: 节点只能是黑色或者红色. 根节点必须是黑色. 每个叶子节点是黑色节点(称之为NIL节点,又被 ...
- 重塑元宇宙体验!3DCAT元宇宙实时云渲染解决方案来了
元宇宙作为人工智能.云计算和数字孪生等前沿技术的结合体,近年来越发受到各大企业重视. 元宇宙的应用场景层出不穷,不仅包括营销推广场景,还有品牌活动和电商销售,能有效提升品宣和商业转化效果. 元宇宙也具 ...
- 使用Java给图片添加水印
什么是水印呢?比如使用手机拍摄一张照片的时候,照片右下角的位置显示得有日期和时间信息,那就表示一个水印. 项目开发中给图片添加水印的操作很常见,比如给图片添加日期和时间,给图片添加公司的logo之类的 ...
- 记一次 .NET某施工建模软件 卡死分析
一:背景 1. 讲故事 前几天有位朋友在微信上找到我,说他的软件卡死了,分析了下也不知道是咋回事,让我帮忙看一下,很多朋友都知道,我分析dump是免费的,当然也不是所有的dump我都能搞定,也只能尽自 ...
- 说说你对vue的mixin的理解,有什么应用场景?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一.mixin是什么 Mixin是面向对象程序设计语言中的类,提供了方法的实现.其他类可以访问mixin类的方法而不必成为其子类 Mixi ...
- C# 使用AForge调用摄像头
AForge官网地址:http://www.aforgenet.com/framework/ using System; using System.Collections.Generic; using ...
- mybatis xml 文件 sql include 的用法
mybatis xml 文件中对于重复出现的sql 片段可以使用标签提取出来,在使用的地方使用标签引用即可具体用法如下: <sql id="Base_Column_List" ...