基本的算法,如排序或哈希,在任何一天都被使用数万亿次。随着对计算需求的增长,这些算法的性能变得至关重要。尽管在过去的2年中已经取得了显著的进展,但进一步改进这些现有的算法路线的有效性对人类科学家和计算方法都是一个挑战。在这里,论文展示了人工智能是如何通过发现迄今为止未知的算法路线来超越目前的最先进的方法。为了实现这一点,论文将一个更好的排序程序制定为单人游戏的任务。然后,论文训练了一个新的深度强化学习代理AlphaDev来玩这个游戏。AlphaDev从零开始发现了一些小型排序算法,它优于以前已知的人类基准测试。这些算法已经集成到LLVM标准C++排序库中。对排序库的这一部分的更改表示用使用强化学习自动发现的算法替换组件。论文还在额外的领域中提出了结果,展示了该方法的通用性。
人类的直觉和专业知识对改进算法至关重要。然而,许多算法已经达到了人类专家无法进一步优化它们的阶段,这导致了不断增长的计算瓶颈。在经典的程序合成文献中的工作,跨越了几十年,旨在生成正确的程序和/或优化程序使用代理的延迟。这些技术包括枚举搜索技术和随机搜索,以及最近在程序合成中使用深度学习来生成正确的程序的趋势。使用深度强化学习(DRL),论文可以通过优化CPU指令级别的实际测量延迟,通过比以前的工作更有效地搜索和考虑正确和快速的程序空间来生成正确和性能的算法。
计算机科学中的一个基本问题是如何对一个序列进行排序。这是在世界各地的基础计算机科学课程中教授的,并被应用程序广泛使用。几十年的计算机科学研究都集中在发现和优化排序算法上。实际解决方案的一个关键组成部分是对短元素序列的小排序;当对使用分治方法的大数组进行排序时,该算法被重复调用。在这项工作中,论文主要关注于两种类型的小排序算法:(1)固定排序和(2)变量排序。固定排序算法对固定长度的序列进行排序(例如,排序3只能对长度为3的序列进行排序),而变量排序算法可以对不同大小的序列进行排序(例如,变量排序5可以对1到5个元素的序列进行排序)。
论文将发现新的、有效的排序算法的问题表述为一个单人游戏,论文称之为集合游戏。在这个游戏中,玩家选择一系列低级的CPU指令, 论文称之为汇编指令,来组合产生一个新的和高效的排序算法。这是具有挑战性的,因为玩家需要考虑汇编指令的组合空间,以产生一个既可证明正确又快速的算法。集合游戏的难度不仅来自于搜索空间的大小,这类似于国际象棋和围棋等极具挑战性的游戏,也来自于反馈功能的性质。在汇编游戏中,一个错误的指令可能会使整个算法失效,这使得在这个游戏空间中的探索变得非常具有挑战性。
为了玩这个游戏,论文引入了AlphaDev,一种学习代理,它被训练来寻找正确和有效的算法。该代理由两个核心组件组成,即(1)学习算法和(2)表示函数。AlphaDev学习算法可以结合DRL和随机搜索优化算法来进行组装游戏。AlphaDev中的主要学习算法是AlphaZero的扩展,这是一种著名的DRL算法,其中训练一个神经网络来引导搜索来解决集合游戏。
使用AlphaDev,论文从头开始发现了固定和可变排序算法,它们比最先进的人类基准测试更有效。由AlphaDev发现的针对排序3、排序4和排序5的固定排序解决方案已经集成到LLVM标准C++库3中的标准排序函数中。这个库被数百万用户使用,包括大学和许多国际公司。此外,论文分析了新算法的发现,比较了AlphaDev与随机搜索优化方法,并将AlphaDev应用于进一步的领域,以展示该方法的通用性。
当从C++等高级语言编译算法到机器代码时(例如,图1a中的排序函数)时,首先将算法编译成汇编语言(图1b)。然后,汇编语言将汇编程序转换为可执行的机器代码。在这项工作中,论文在汇编级别上优化算法。在典型的汇编程序中,值从内存复制到寄存器,在寄存器之间进行操作,然后写回内存。所支持的汇编指令集取决于处理器的体系结构。为了这项工作的目的,论文重点关注使用AT&T语法的x86处理器架构支持的汇编指令子集。每条指令的格式为Opcode(OperandA, OperandB)。一个示例指令是mov<A,B>,它被定义为将一个值从源(A)移动到目标(B).进一步的指令定义,如比较(cmp<A,B>)、条件移动(cmovX<A,B>)和跳转(jX<A>),可以在扩展数据表1中找到。在图1b中的示例中,%eax、%ecx、%edx、%edi对应四个不同的寄存器位置,(%rsi)、4(%rsi)对应两个不同的内存位置。符号$2是一个常量值的占位符,它对应于本例中的向量的长度。在本工作中,论文交替使用术语汇编程序和汇编算法。这是因为AlphaDev从一开始的无序指令集,从头构建一个汇编程序,定义一个新的和有效的算法。
用来发现更快的算法的DRL
在本节中,论文将在CPU指令级别上的优化算法制定为一个强化学习(RL)问题,其中环境被建模为一个单人游戏,论文称之为汇编游戏。这个游戏中的每个状态都被定义为一个向量St=<Pt,Zt>,其中Pt是到目前为止在游戏中生成的算法的表示,Zt表示在一组预定义的输入上执行当前算法后的内存和寄存器的状态。如图2a所示,在时间步t,玩家接收到当前状态St并执行一个动作。这涉及到为目前生成的算法附加一个合法的汇编指令(例如,mov<A,B>)。收到的反馈rt包含算法正确性和延迟的度量。算法的正确性(图2b)涉及到输入一组N个测试序列,生成N个输出。然后将这些输出与预期输出进行比较,并计算出正确性反馈rt。延迟反馈可以通过以下两种方式产生:(1)惩罚增加算法长度的agent(当长度和延迟高度相关时),论文称之为算法长度反馈,或者(2)测量算法的实际延迟。游戏被执行有限的步骤,之后游戏被终止。赢得这个游戏对应于使用汇编指令生成一个正确的、低延迟的算法。输掉游戏对应于生成一个不正确的算法或一个正确但低效的算法。
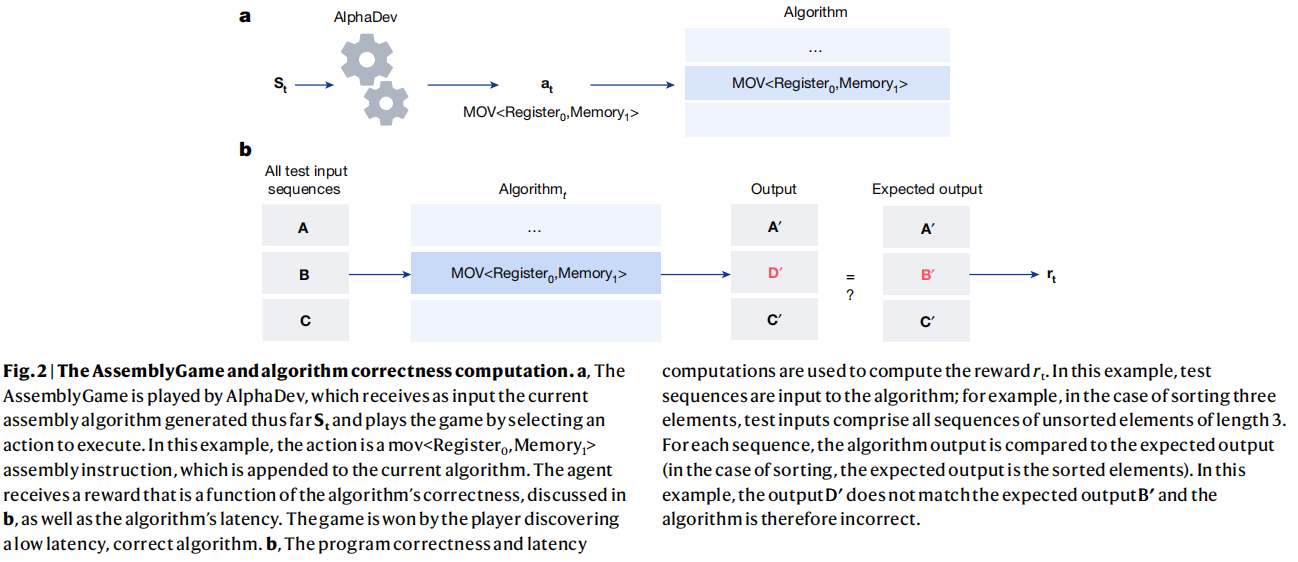
论文将玩这个单人游戏的代理称为AlphaDev。该代理的主要学习算法是对AlphaZero代理的扩展,并使用深度神经网络指导蒙特卡罗树搜索(MCTS)规划程序。神经网络的输入是状态St,输出是一个策略和值预测。策略预测是动作的分布,值函数是代理期望从当前状态St接收到的累积回报R的预测。然后,代理会执行一个MCTS过程,并使用它来选择下一个要执行的操作。然后,生成的游戏被用来更新网络的参数,使代理能够学习。
AlphaDev必须有一个表示方法,它必须能够表示复杂的算法结构,从而有效地探索指令的空间。为了实现这一点,论文引入了AlphaDev表示网络(扩展数据图1a)。该网络包括两个组成部分,即(1)transformer编码器网络,为代理提供算法结构的表示;(2)CPU状态编码器网络,帮助代理预测算法如何影响内存和寄存器的动态。CPU状态编码器网络包括多层感知器,该感知器接收给定输入集的每个寄存器和存储器位置的状态作为输入。这些网络每个输出嵌入,并结合起来生成AlphaDev状态表示。
Transformer是自然文本编码器,最近在语言模型上取得了的成功。因此,这促使论文调整标准transformer的模型汇编指令。论文开发并合并了一个transformer编码器,论文适应的多查询transformer编码器,到AlphaDev表示网络来表示汇编指令。每个汇编指令的操作码和相应的操作符被转换为一个热编码,并连接起来形成原始的输入序列。这是通过一个多层transformer编码器提供的,该编码器将其映射到相应的嵌入向量(插图见扩展数据图1b)。
延迟是一个重要的反馈信号,被用来指导代理发现性能算法。为了更好地估计延迟,论文实现了一个对偶值函数设置,其中AlphaDev有两个值函数头:一个是预测算法的正确性,第二个是预测算法的延迟。延迟头用于直接预测给定程序的延迟,通过利用程序的实际计算延迟作为训练期间的蒙特卡罗目标来预测给定程序的延迟。在优化实际延迟时,这种双头方法比普通的单头值函数设置取得了明显更好的结果。
论文从头开始训练AlphaDev代理来生成一系列固定排序和可变排序算法,这些算法既能正确,又能实现比最先进的人类基准测试更低的延迟。
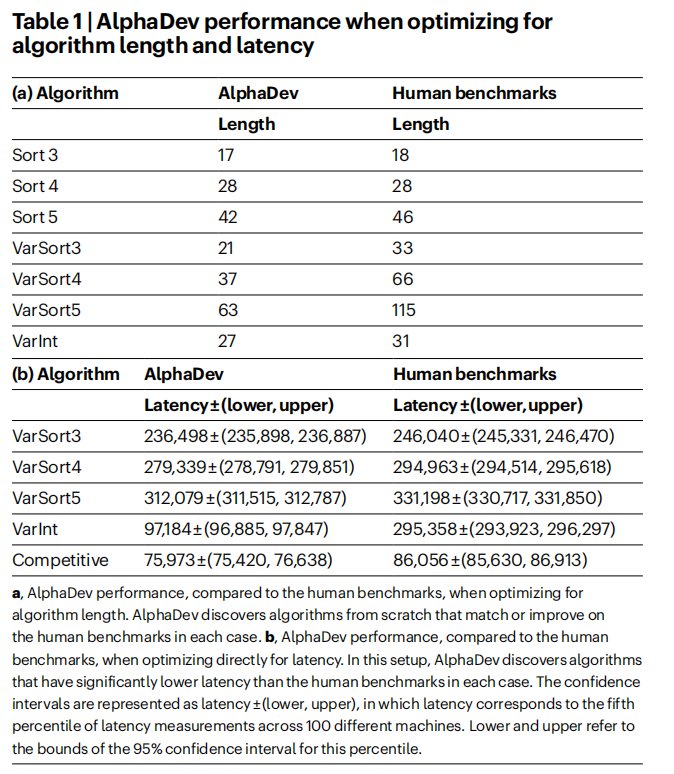
论文考虑了三种基本算法:排序3,排序4和排序5。这些算法的最先进的人类基准是对网络进行排序,因为它们生成高效的、有条件的无分支汇编代码。这意味着所有的指令都是按顺序执行的,并且不涉及任何分支。改进这些算法具有挑战性,因为它们已经被高度优化了。如表1a所示,AlphaDev能够找到比排序3和排序5的人类基准测试中的指令更少的算法,并匹配排序4的最新性能。这些较短的算法确实导致了更低的延迟,因为算法的长度和延迟在条件无分支的情况下是相关的;更多细节请参见补充信息中的附录B。论文还探索了使用AlphaDev的一个变体来扩展到稍大的排序。论文成功地保存了排序6的3条指令,排序7的两条指令和排序8的一条指令,这为未来的工作提供了一个很有前途的基础。关于该方法的概述,请见补充信息中的附录C。
论文考虑了三种变量排序算法: VarSort3、VarSort4和VarSort5。在每种情况下,人工基准被定义为一种算法,对于给定的输入长度,调用相应的排序网络。在这种情况下,分支是必需的,这大大增加了问题的复杂性,因为代理需要(1)确定它需要构建多少个子算法,以及(2)并行构建主算法的主体。代理还可能需要从其他子算法中调用子算法。在这种情况下,与表1a所示的人类基准相比,长度优化导致明显更短的算法。然而,由于分支所带来的复杂性,延迟和长度并不总是相关的;更多信息请参见补充信息。优化延迟是一个重要的目标,而测量实际延迟并采取措施来优化它是很有效的。我们采用了一个程序来测量程序的实际延迟,该程序通过在100台不同的机器上进行延迟测量,并计算置信区间,从中选择延迟的第五个百分位数,并优化这个指标。这种方法可以帮助我们了解程序的性能表现,并且有助于确定需要进行哪些改进以减少延迟。。有关完整的基准测试设置,请参见方法。当优化延迟时,代理在每种情况下的人工基准上显著改进,如表1b所示。
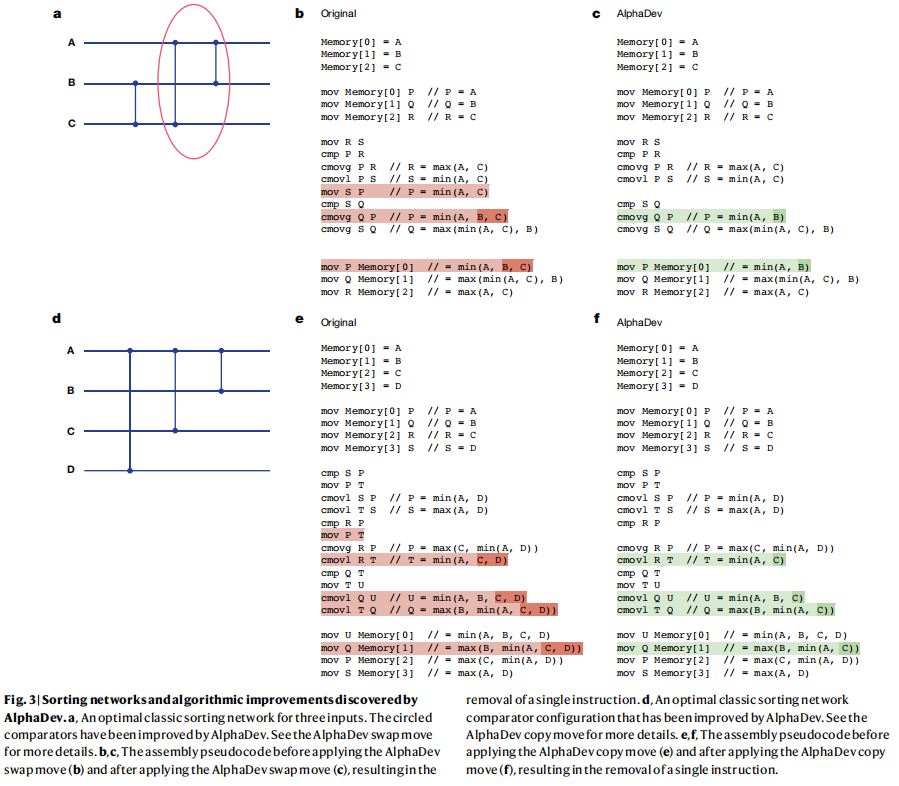
由AlphaDev发现的解决方案包括新的和令人兴奋的算法发现,从而导致更有效的性能。在固定排序设置中,论文发现AlphaDev发现了两个有趣的指令序列,当应用于排序网络算法时,每次将算法减少一个汇编指令。论文将每个指令序列分别称为(1)AlphaDev交换移动和(2)AlphaDev复制移动
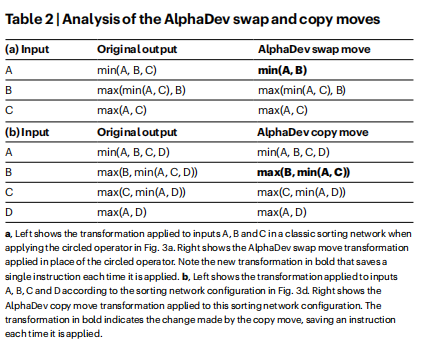
图3a给出了三个元素的最优排序网络(关于排序网络的概述,请参见方法)。论文将解释AlphaDev是如何改进被圈出的网络段的。在不同大小的排序网络中可以发现这种结构的许多变体,同样的论点也适用于每种情况。网络的圈状部分(最后两个比较器)可以看作是一系列指令序列,它接受一个输入序列A、B、C,并转换每个输入,如表2a(左)所示。然而,导线B和C上的比较器先于这个操作符,因此输入保证B≤C的序列。这意味着它足以计算min(A、B)作为第一个输出,而不是最小值(A、B、C),如表2a(右)所示。图3b,c之间的伪代码差异说明了AlphaDev交换移动如何在每次应用时保存一条指令。
图3d显示了一个排序网络配置,包括三个比较器,应用于四根线。该配置可以在排序8排序网络中找到,对应于一个操作符接受四个输入A、B、C、D,并将它们转换为四个输出,如表2b(左图)所示。论文可以证明,作为排序8的一部分,流入操作符的输入满足以下不等式:D≥min(A,C)。这意味着可以通过应用表2b(右图)中定义的AlphaDev复制移动来改进操作符,从而导致比原始操作符少一条指令。原始操作符与应用AlphaDev复制移动后的代码差异。
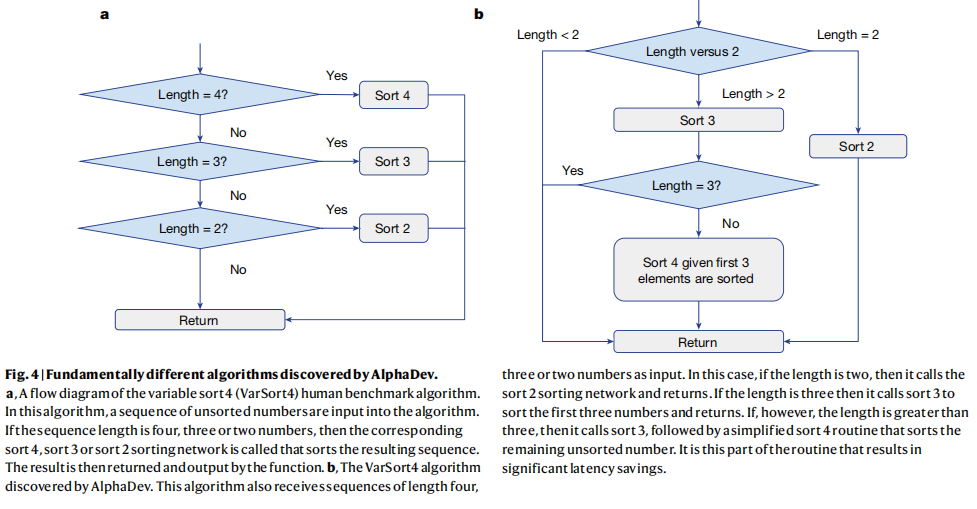
由AlphaDev发现的VarSort4算法特别有趣。人工基准算法和AlphaDev的流程图分别见图4a、b。人工基准测试算法确定输入向量的长度,然后调用相应的排序网络对元素进行排序。AlphaDev有一个完全不同的方法,如图4b所示。如果输入向量的长度严格大于2,则立即调用sort 3,导致前三个元素被排序。如果向量大于三个元素,则称为一个简化的排序4算法,该算法对输入向量中剩余的未排序元素进行排序。正是这个简化的程序部分,在算法长度和延迟方面产生了显著的收益。
与其他程序优化方法相比,了解RL的优点和局限性是很重要的。因此,论文实现了一种最先进的随机超优化方法,将其适应于排序设置,并将其用作AlphaDev中的学习算法。论文将这个变体称为AlphaDev-S(更多细节请参见方法)。论文使用与AlphaDev相同的资源和时间来运行这个算法。
AlphaDev-S需要大量的时间来直接优化延迟,因为延迟需要在每次突变后进行计算。因此,AlphaDev-S优化了一个延迟代理,即算法长度,然后,在训练结束时,论文搜索由AlphaDev-S生成的所有正确程序,并对每个程序进行基准测试,以找到最低的延迟解决方案。一般来说,论文发现在没有先验知识的情况下,AlphaDev的性能始终优于AlphaDev-S。此外,随着程序规模的增加,AlphaDev探索的项目(最坏情况为1200万个程序)比AlphaDev-S(最坏情况为31万亿个程序)少几个数量级。这可能是因为AlphaDev能够更好地探索算法的空间,而后者更容易陷入局部最优;有关这个探索假设的概述,请参阅方法。此外,AlphaDev在搜索过程中从不计算延迟,因为它使用了延迟值函数预测,因此,只需要在不到0.002%的生成程序上计算实际测量的延迟。当将以前的知识合并到AlphaDev-S中时,例如以接近最优的解热启动学习算法,AlphaDev-S对于排序3、排序4和排序5(无分支组装算法)的计算效率更高,并且在每种情况下生成与AlphaDev更有竞争力的低延迟算法。然而,对于require分支(if-else语句)的算法,其中算法长度和延迟没有很好地相关,AlphaDev发现的延迟比AlphaDev-S发现的解决方案低,即使在以接近最优解热启动该算法时。有关这些算法的深入分析,请参见方法。
为了测试AlphaDev的通用性,论文在一组额外的域上训练代理。这些问题包括一个名为VarInt的协议缓冲区反序列化子例程,以及一个竞争编码问题(更多细节请参见补充信息中的附录D)。竞争编码域延迟性能见表1b。
协议缓冲区是谷歌的开源数据格式,用于序列化结构化数据。这种格式通常用于主要考虑性能或网络负载的情况。VarInt算法是序列化和反序列化过程中的一个关键组成部分。论文训练AlphaDev代理作为变量排序,以根据正确性和测量的延迟来优化VarInt反序列化函数。为了保证正确性,论文反馈那些正确地反序列化每个输入的代理。论文使用了一组80个输入和相应的输出,它们涵盖了常见的protobuf用例。AlphaDev学习了一个优化的VarInt反序列化函数,并在单值输入方面显著优于人类的基准测试。论文的agent发现了一个无分支的解决方案,它更短(表1a),大约比人类基准(表1b)快三倍。在此过程中,代理还发现了一个新的VarInt分配移动,在这个移动中,AlphaDev学习将两个操作合并到一条指令中,从而节省了延迟。关于此举的完整概述,请见补充信息中的附录D.1。这有力地表明,AlphaDev能够泛化到优化非平凡的、现实世界的算法。
LLVM libc++标准排序库中的排序3、排序4和排序5算法被更大的排序算法多次调用,因此是该库的基本组成部分。论文将AlphaDev发现的用于排序3、排序4和排序5的低级汇编排序算法逆向工程到C++中,发现论文的排序实现对长度为5的序列提高了70%,对超过250,000个元素的序列提高了大约1.7%。这些改进适用于uint32、uint64和ARMv8、Intel Skylake和AMD Zen 2 CPU架构的浮动数据类型;有关完整的性能表,请参阅补充信息中的附录E。性能的改进是由于由AlphaDev生成的无分支条件组装以及新的AlphaDev交换移动。对于sort 5,论文使用了由AlphaDev发现的43个长度的算法,达到了更有效的C++实现。这些算法被发送去审查,并已正式包含在libc++标准排序库中。这是十多年来对这些子例行程序的第一次改变。这也是这个排序库中的任何组件第一次被使用强化学习自动发现的算法所取代。论文估计这些例程每天被调用数万亿次。
AlphaDev从新的角度发现了最先进的排序算法,这些算法已经被整合到LLVM C++库中,被全球数百万开发人员和应用程序使用。AlphaDev和随机搜索都是一种强大的算法。未来研究的一个有趣的方向是研究将这些算法结合起来,以实现这两种方法的互补优势。
需要注意的是,在理论上,AlphaDev可以推广到不需要对测试用例进行详尽验证的函数。例如,哈希函数以及加密哈希函数。通过哈希冲突的数量来定义函数的正确性。因此,在这种情况下,AlphaDev可以优化以最小化冲突和延迟。理论上,AlphaDev还可以在大型的、令人印象深刻的功能体中优化复杂的逻辑组件。论文希望AlphaDev能够提供有趣的见解,并在人工智能和程序合成社区中启发新的方法。
附录见原文,原文链接:https://www.nature.com/articles/s41586-023-06004-9
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- 《Stereo R-CNN based 3D Object Detection for Autonomous Driving》论文解读
论文链接:https://arxiv.org/pdf/1902.09738v2.pdf 这两个月忙着做实验 博客都有些荒废了,写篇用于3D检测的论文解读吧,有理解错误的地方,烦请有心人指正). 博客原 ...
- CVPR2019论文解读:单眼提升2D检测到6D姿势和度量形状
CVPR2019论文解读:单眼提升2D检测到6D姿势和度量形状 ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Sha ...
- CVPR2020 论文解读:少点目标检测
CVPR2020 论文解读:具有注意RPN和多关系检测器的少点目标检测 Few-Shot Object Detection with Attention-RPN and Multi-Relation ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 论文解读第三代GCN《 Deep Embedding for CUnsupervisedlustering Analysis》
Paper Information Titlel:<Semi-Supervised Classification with Graph Convolutional Networks>Aut ...
- 论文解读(MGAE)《MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs》
论文信息 论文标题:MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs论文作者:Qiaoyu Tan, Ninghao L ...
- 论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
论文信息 论文标题:Learning Graph Augmentations to Learn Graph Representations论文作者:Kaveh Hassani, Amir Hosein ...
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
论文信息 论文标题:Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering论文作者:Chaki ...
随机推荐
- BootstrapTable 行内编辑解决方案:bootstrap-table-editor
最近开发的一个业务平台,是一个低代码业务平台.其中用到的了bootstrap-table组件.但是bootstrap-table自身不带编辑功能. 通过搜索发现,网上大部分的解决方案都是使用x-edi ...
- 寒假训练——vj题解
B - B M 算日期 M 是一位数学高手,今天他迎来了 Kita 的挑战.Kita 想让 BM 算出这几年内有多少个闰年. BM 觉得这问题实在太简单了,于是 Kita 加大了难度. 他先给出第一个 ...
- 【Tutorial C】05 操作符 & 表达式
基本运算符 C使用运算符(operator)来代表算术运算.例如,+运算符可以使它两侧的值加在一起. 如果您觉得术语"运算符"听起来比较奇怪,那么请您记住那些东西总得有个名称. 与 ...
- 【DataBase】SQL50 Training 50题训练
原文地址: https://blog.csdn.net/xiushuiguande/article/details/79476964 实验数据 CREATE DATABASE IF NOT EXIST ...
- 人形机器人(humanoid)(双足机器人、四足机器人) —— 硬件测试的方法
硬件测试的方法: 硬件的稳定性.鲁棒性.为机器人设定好固有的执行策略,然后长时间的让机器人重复执行这些既定好的动作.该种测试方法主要测试硬件的设计是否合理,硬件在长时间的运行中是否可以稳定运行而不是出 ...
- java多线程之sleep 与 yield 区别
1.背景 面试中经常会被问到: sleep 与 yield 区别 2.代码 直接看代码吧! package com.ldp.demo01; import com.common.MyThreadUtil ...
- uview-ui toast 二次封装
开发用到uview 的toast 很常用的内容使用却很繁琐 所以做了简单封装方便使用 前后对比: this.$refs.uToast.show({ type: 'success', title: '成 ...
- Digest Auth 摘要认证
1.该代码展示了使用Apache HttpClient库进行HTTP请求,并处理基于MD5的HTTP Digest认证的过程. Digests类实现了MD5加密算法,HttpUtils类处理了GET. ...
- [nRF24L01+] 1. 硬件设计
nRF24L01pluss_REFERENCE_MODULES.pdf nrf24l01p_product_specification_1_0.pdf 1. 硬件设计 1.1. 实物图 [左边是PCB ...
- 瑞芯微-I2S | 音频驱动调试基本命令和工具-基于rk3568-2
基于Linux嵌入式设备常用调试方法很多,本文一口君把调试语音用到的工具和方法给大家做一个简单的介绍. 1. procfs.sysfs Linux系统上的/proc目录是一种文件系统,即proc文件系 ...