火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
关键技术
数据模型统一
- 类型(Type):描述一类元数据,由多个属性组成。例如,hive table是一类元数据,hive_db也是一类元数据。Type可具备继承关系。按面向对象的编程思想,可以理解type为一个Class。
- 实例(Entity):代表一个type的具体事例。一个entity可能作为一个属性存在于另一个entity中,例如hive_table中的db属性,db本身也是一个entity。在面向对象的编程思想中,一个entity可以认为是一个class的instance。
- 属性(Attribute):属性的集合组合而成为一个Type。属性本身的类型(typeName)可能是一个自定义的type,也可能是一种基础类型,包括date,string等。例如,db是hive_table的一个属性,column也是hive_table的一个属性。
- 关系(Relationship):一种特殊的Entity,用以描述两个Entity之间的关联模式。
- 继承与组合的广泛使用
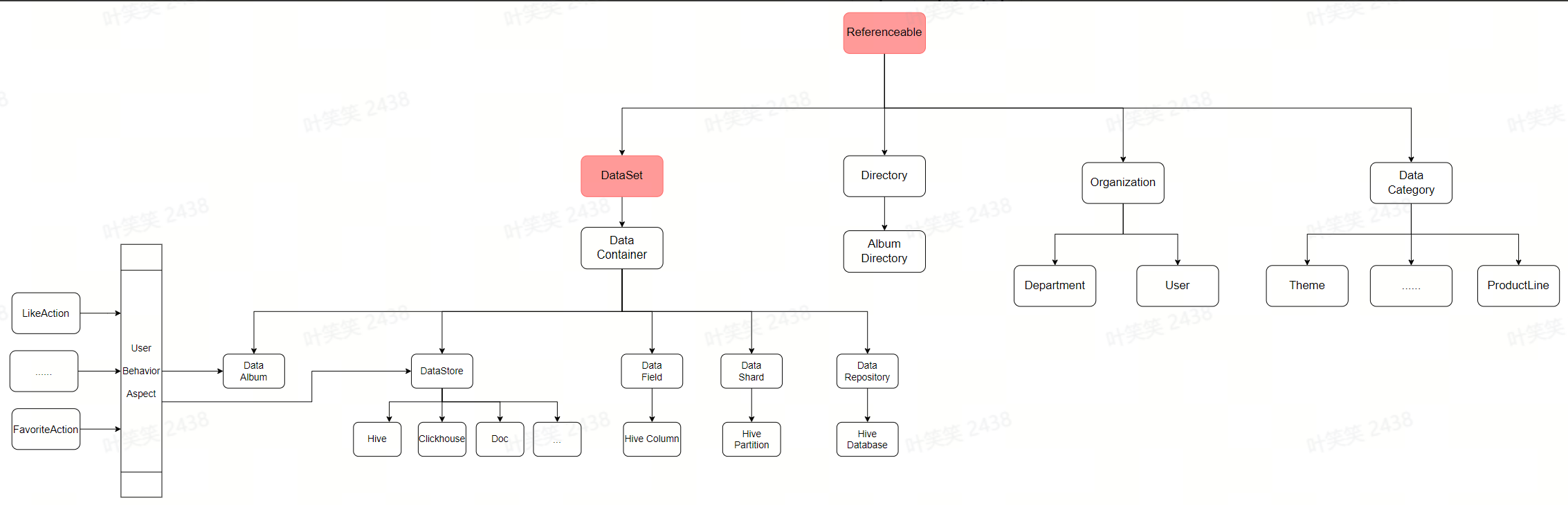
- 调整类型加载机制
数据接入标准化
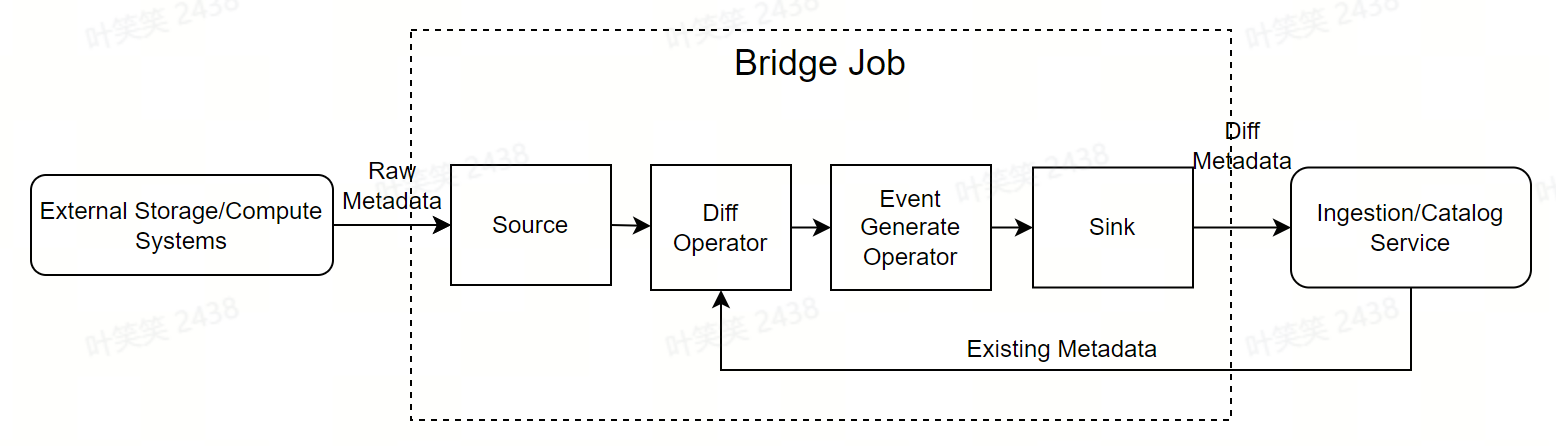
- Source:从外部存储计算系统等批量拉取最新的全量元数据。数据结构和字段通常由外部系统决定。概念上可对齐Flink的source operator。
- Diff Operator:接收source的输出,并从Catalog Service拉取当前系统中的全量元数据,做差异对比,产出差异的部分。概念上对齐Flink中的某一种自定义的ProcessFunction。
- Event Generate Operator:接收Diff Operator的输出,根据Catalog系统定义好的格式,将差异的metadata转化成event格式,比如对于新建的metadata,转换成CreateEvent。概念上对齐Flink中的某一种自定义的ProcessFunction。
- Sink:接收Event Generate Operator的输出,将差异的metadata写入Ingestion Service。概念上对齐Flink的sink operator。
- Bridge Job:组装pipeline,做运行时控制。概念上对齐Flink的Job。
搜索优化
- 搜索中存在部分很强的Pattern:用户搜索元数据时,有一些隐式的习惯,通过挖掘埋点中的固定pattern,给了我们针对性优化的机会。
- 行为数据规模有限:公司内部的元数据搜索用户,通常是千级别,而每天搜索的点击次数是万级别,这个规模远远小于对外的通用搜索引擎,也造成很多模型没法及时收敛,但也一定程度上给与我们简化问题的机会。
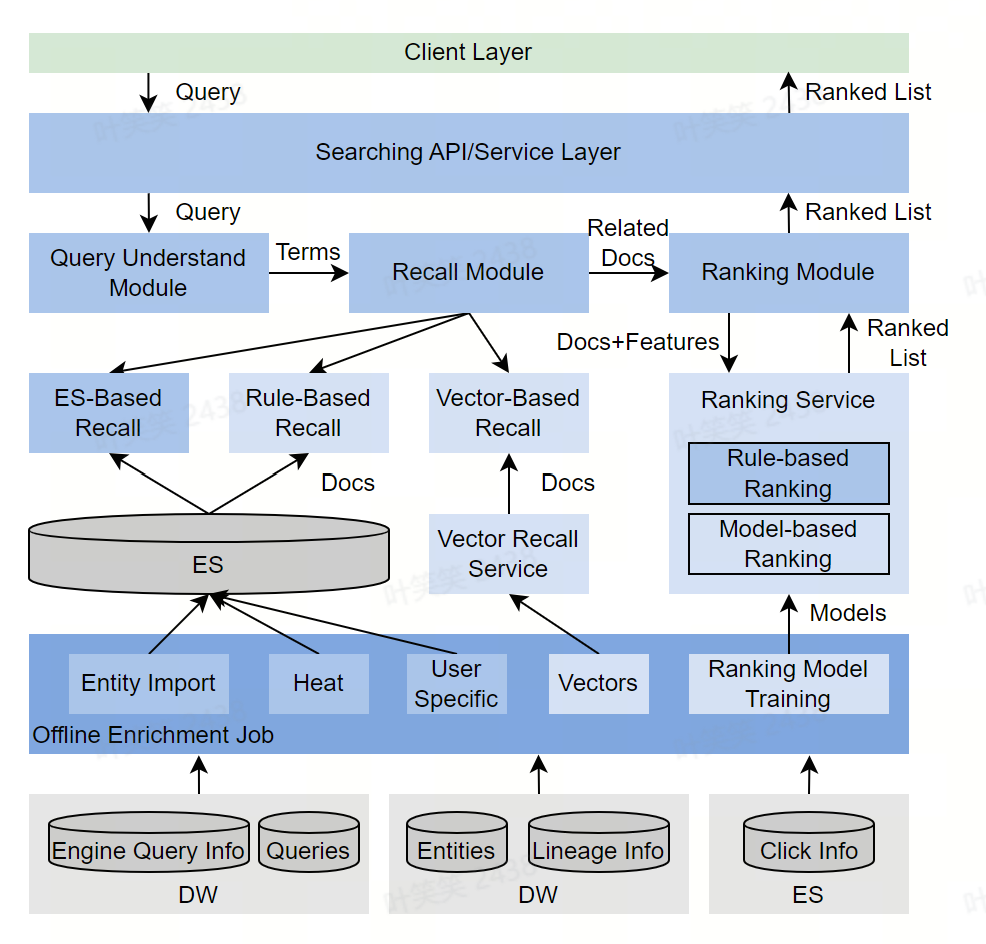
- 离线部分:负责汇集各类与搜索相关的数据,做数据清洗或者模型训练,根据不同的用途,写入不同的存储,供给在线搜索模块使用。
- 在线部分:分为搜索理解、召回、精排三个主要阶段,步骤和概念上与通用搜索引擎对齐。
- 对于强Pattern,广泛使用Rule-Based的优化手段:比如,火山引擎 DataLeap 研发人员发现很大一部分用户在搜索Hive时,会使用“库名.表名”的pattern,在识别到query语句中有“.”时,火山引擎 DataLeap 研发人员会优先尝试根据库名和表名检索
- 激进的个性化:因用户规模可控,且某位用户通常会频繁使用某个领域的元数据,火山引擎 DataLeap 研发人员记录了很多用户的历史行为细节,当query语句与过去浏览过元数据有一定文本相关性时,个性化相关的得分会有较大提升
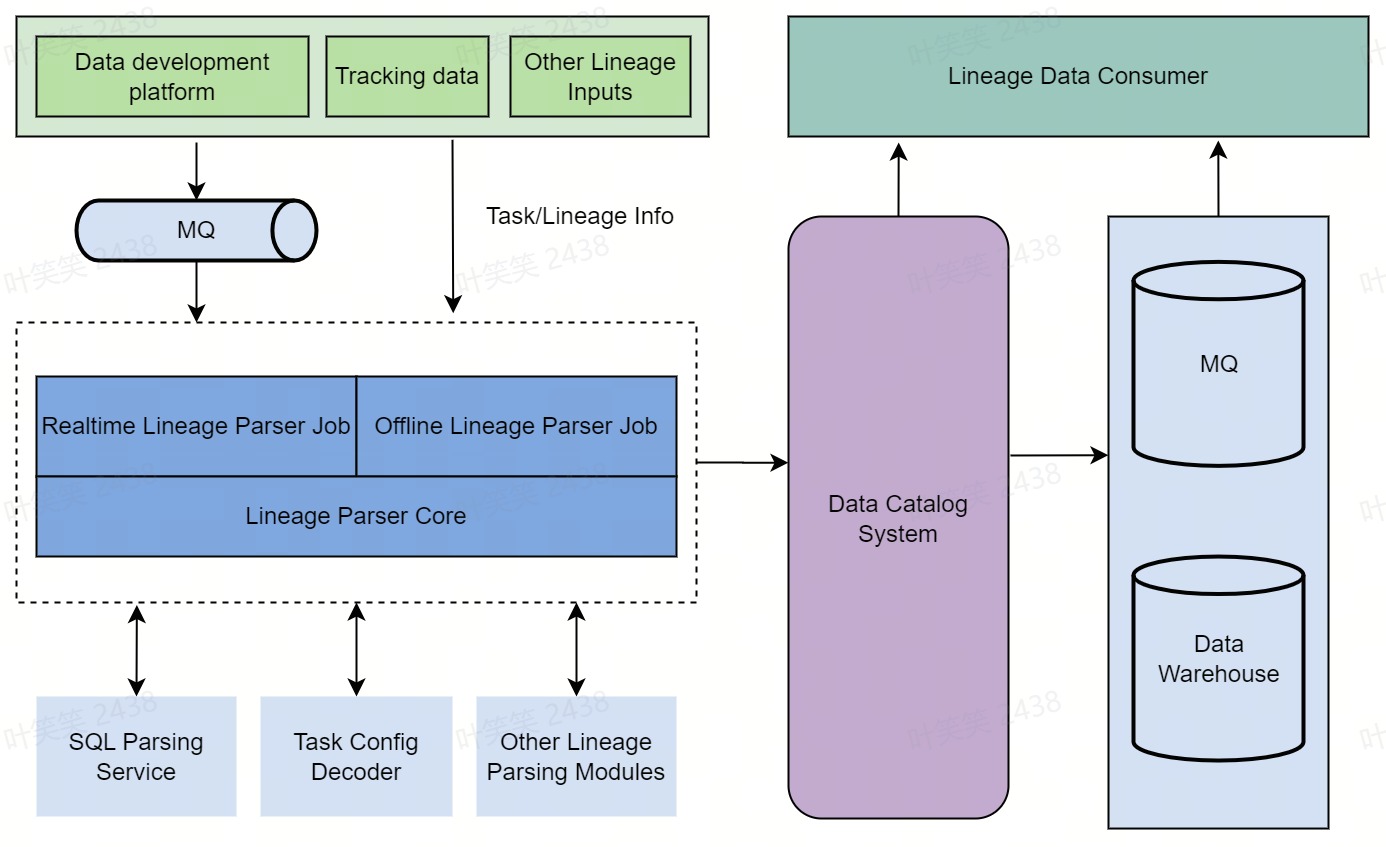
血缘能力
存储层优化
读优化:开启MutilPreFetch 能力
写优化:去除Guid全局唯一性检查
|
|
优化前
|
优化后
|
|
小表(10列以内)
|
1~2s
|
<100ms
|
|
中表(100-500列)
|
3-5min
|
2~5s
|
|
超大表(3000列以上)
|
15min以上,经常写入失败
|
0.5~1min,可写入
|
未来工作
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结的更多相关文章
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 字节跳动构建Data Catalog数据目录系统的实践(上)
作为数据目录产品,Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系.本文介绍了字节跳动 Data ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
背景 字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源.后续为了支持业务发展,做了很多修修补补的工作,系统 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 基于MRS-ClickHouse构建用户画像系统方案介绍
业务场景 用户画像是对用户信息的标签化.用户画像系统通过对收集的各维度数据,进行深度的分析和挖掘,给不同的用户打上不同的标签,从而刻画出客户的全貌.通过用户画像系统,可以对各个用户进行精准定位,从而将 ...
随机推荐
- 🔥🔥你以为你了解TCP协议?这些你可能不知道的细节才是关键!
引言 在之前的内容中,我们已经详细讲解了TCP面试中最常见的问题,如三次握手和四次挥手等.而今天,我们将继续深入探讨TCP协议的其他方面,比如序列号和TCP Fast Open(TFO)等重要细节问题 ...
- Semantic Kernel 将成为通向Assistants的门户
OpenAI 也推出了让开发者更容易使用 OpenAI API 的开发方式--Assistants API.Sam Altman 表示,市面上基于 API 构建 agent 的体验很棒.比如,Shop ...
- 小景的Dba之路--压力测试和Oracle数据库缓存
小景最近在做系统查询接口的压测相关的工作,其中涉及到了查询接口的数据库缓存相关的内容,在这里做一个汇总和思维发散,顺便简单说下自己的心得: 针对系统的查询接口,首次压测执行的时候TPS较低,平均响应时 ...
- Service Mesh:微服务架构的救世主还是多余的花招?
Service Mesh的前世今生 在前面,我们提出了一个问题:随着模块和节点的增多,微服务之间难免会遇到各种网络问题.为了解决这些问题,目前有一个解决方案,即使用Spring Cloud中的各个组件 ...
- JS判断点是否在线段上
本文利用向量的点积和叉积来判断点是否在线段上. 基础知识补充 从零开始的高中数学--向量.向量的点积.带你一次搞懂点积(内积).叉积(外积).Unity游戏开发--向量运算(点乘和叉乘 说明 点积可以 ...
- CDQ分治(初步入门)
CDQ分治 CDQ分治,传说中是一个神犇创造的算法. 在了解这种算法之前,我们有必要了解一下一种基本的思想:分治. 分治介绍 分而治之,将原问题不断划分成若干个子问题,直到子问题规模小到足以直接解决 ...
- 海康单筒红外相机SDK调用方法
目录 配置环境 1.准备文件 2.配置 3.路径 程序 1.错误警告 2.导入头文件: 3.修改SDK 配置环境 1.准备文件 通过VS创建空白项目后,将海康SDK文件夹: CH-HCNetSDKV6 ...
- C语言输入一个三位的正整数,按逆序打印出该数的各位数字。
#include <stdio.h> int main() { int n, a, b, c;//定义3位数,个位数,十位数,百位数变量 scanf_s("%d", & ...
- Java笔记——常用类
一.API概述 JDK中提供的各种功能的Java类 二.Object类 概述 类层次结构的根类 所有类都直接或间接的继承自该类 Class Object是类object结构的根.每个Class都有ob ...
- JAVA学习week2
这周:根据老师在群里面推荐的JAV学习路线,初步规划了一下学习方案 并找到了相关的视频,目前来说在学习SE.学习内容:环境变量的配置和简单的hello world程序书写的注意点 下周:打算进行简单的 ...