【LeetCode回溯算法#04】组合总和I与组合总和II(单层处理位置去重)
组合总和
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
- 所有数字(包括 target)都是正整数。
- 解集不能包含重复的组合。
示例 1:
- 输入:candidates = [2,3,6,7], target = 7,
- 所求解集为: [ [7], [2,2,3] ]
示例 2:
- 输入:candidates = [2,3,5], target = 8,
- 所求解集为: [ [2,2,2,2], [2,3,3], [3,5] ]
思路
和 组合总和III 不同的点在于:
- 单个组合内元素个数没有限制,只要不超过target即可
- 由于上述原因,本题中递归的层数也没有限制
基于此,我们就不能用组合的size()作为终止条件了,并且在单层处理逻辑中,还需要使用beginIndex来确定遍历起始位置
题外话:何时需要beginIndex
如果是一个集合来求组合的话,就需要beginIndex;(例如组合、组合总和III)
如果是多个集合取组合,各个集合之间相互不影响,那么就不用beginIndex;(电话号码)
回到正题
本题的基本框架与组合总和III完全一致,下面我就写的简略一些
1、确定回溯函数参数与返回值
仍然需要定义两个数组用于保存路径值与结果
class Solution {
private:
//定义结果变量
vector<int> path;
vector<vector<int>> res;
//确定回溯函数参数与返回值
void backtracking(vector<int>& candidates, int target, int beginIndex){
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
}
};
2、确定终止条件
前面的分析提到,本题无法再使用path的大小来作为终止条件
但我们仍可以分析出需要终止的情况:
- target为0,说明已经找到满足条件的组合
- target小于0,说明过了,需要停止(在深度层面来说)
class Solution {
private:
//定义结果变量
vector<int> path;
vector<vector<int>> res;
//确定回溯函数参数与返回值
void backtracking(vector<int>& candidates, int target, int beginIndex){
//确定终止条件
if(target < 0){//因为不限制单个组合中元素个数,因此递归深度也是不限的,当target < 0说明已经过了
return;
}
if(target == 0){//找到目标组合
res.push_back(path);
return;
}
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
}
};
3、确定单层处理逻辑
这里大部分与之前的题一样,但是有个关键点是:进入下一层递归时,不要跳过当前值(即使用 i 而不是 i+1 ),因为可以在组合中出现重复值
完整代码
class Solution {
private:
//定义结果变量
vector<int> path;
vector<vector<int>> res;
//确定回溯函数参数与返回值
void backtracking(vector<int>& candidates, int target, int beginIndex){
//确定终止条件
if(target < 0){//因为不限制单个组合中元素个数,因此递归深度也是不限的,当target < 0说明已经过了
return;
}
if(target == 0){//找到目标组合
res.push_back(path);
return;
}
//确定单层处理逻辑
for(int i = beginIndex; i < candidates.size(); ++i){
//累减,满足条件时为0
target -= candidates[i];
path.push_back(candidates[i]);//保存路径值
backtracking(candidates, target, i);//注意不要跳过当前值
target += candidates[i];//回溯
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
backtracking(candidates, target, 0);//从0开始
return res;
}
};
注意点
1、单层处理中,进入下一层递归时不要跳过当前值(并且别再的把beginIndex写到backtracking里了,应该写i才对)
2、主函数中,beginIndex应该初始化为0
组合总和II
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明: 所有数字(包括目标数)都是正整数。解集不能包含重复的组合。
- 示例 1:
- 输入: candidates = [10,1,2,7,6,1,5], target = 8,
- 所求解集为:
[
[1, 7],
[1, 2, 5],
[2, 6],
[1, 1, 6]
]
- 示例 2:
- 输入: candidates = [2,5,2,1,2], target = 5,
- 所求解集为:
[
[1,2,2],
[5]
]
思路
与 组合总和 和 组合总和III 不同
本题提供的输入数组中,元素是有重复值的。并且仍然要求我们搜索出的组合不能有重复的
区别总结如下:
- 本题candidates 中的每个数字在每个组合中只能使用一次。
- 本题数组candidates的元素是有重复的,而 组合总和 是无重复元素的数组candidates
重点和难点就在于如何去重
而且就算明白了需要去重,我们还要考虑在哪去重比较合适。这时候还是需要引入树结构
(因为比较复杂懒得画了,直接用卡哥的图)
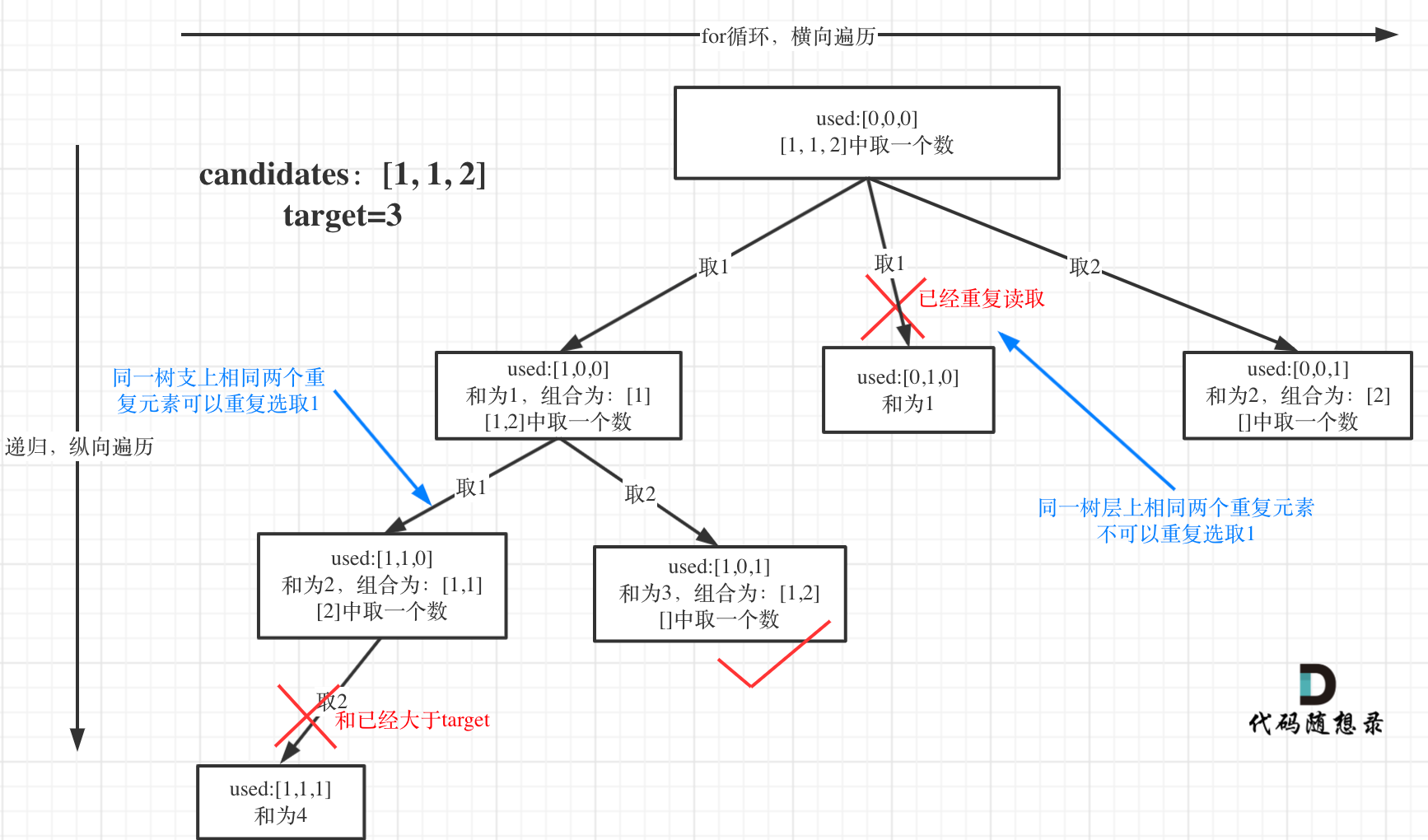
在整体结构上与之前的树基本一致
不同的是这次引入了一个used数组来标记使用过的元素
先以第一条线为例,从上往下看
第一层递归我们取[1,1,2]中的第一个1,标记used为[1,0,0],此时组合为[1],不满足条件
然后在第二层递归中,根据beginIndex的指向我们取[1,2]中的1,标记used为[1,1,0]。
此时组合为[1,1],不满足条件,且再往下取就非法了
因此在第二层我们可以取[1,2]中的2,标记used为[1,0,1]。
此时组合为[1,2],满足条件
再看第二条线,第一层递归我们取[1,1,2]中的第二个1,标记used为[0,1,0],有没有发现问题?
因为candidates在搜索前就已经排好序,所以取第一个1的情况下回包含第二个1的所有组合
因此如果我们从第一条线搜索完毕,然后回溯到开头再从第二个1再次进入递归的话,后面搜索得到的组合一定会有重复值(与第一条线中的搜索结果重复)
例如,以第二个1开启递归的话也会得到组合[1,2]
由此我们可以发现:我们需要去重的位置应该是在单层递归时,也就是所谓的“树层”中,而在一次递归搜索的不同深度中可以使用相同的元素
上述过程中还有两个很重要的点:
1、标记数组used的状态
通过used的状态可以判断是否在单层中使用了重复元素
(下面代码中再细说)
2、candidates需要提前排好序
排序之后,两个重复元素会变成相邻元素。靠前的那个相邻元素的搜索结果会包含靠后那个元素的所有搜索结果
代码分析
基本框架还是一样的,就只是单层处理逻辑那不同
1、确定回溯函数的参数和返回值
输入参数不用说:candidates数组(需要先排好序)、目标值target、used数组和beginIndex
返回值不需要
class Solution {
private:
vector<int> path;
vector<vector<int>> res;
void backtracking(vector<int>& candidates, int target, vector<bool>& used, int beginIndex){
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
}
};
2、确定终止条件
和之前一样,因为这里递归深度是不限的,并且组合元素个数也是不限的
所以不可以用path的大小作为终止条件(详见 组合总和 )
class Solution {
private:
vector<int> path;
vector<vector<int>> res;
void backtracking(vector<int>& candidates, int target, vector<bool>& used, int beginIndex){
//确定终止条件
if(target < 0){
return;
}
if(target == 0){
res.push_back(path);
return;
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
}
};
3、确定单层处理逻辑
在这里要去重了
首先我们要判断当前遍历的元素是否是相邻相同元素(因此candidates需要先被排序)
然后我们要判断used数组的状态
代码如下:
class Solution {
private:
vector<int> path;
vector<vector<int>> res;
void backtracking(vector<int>& candidates, int target, vector<bool>& used, int beginIndex){
//确定终止条件
if(target < 0){
return;
}
if(target == 0){
res.push_back(path);
return;
}
//确定单层处理逻辑
for(int i = beginIndex; i < candidates.size(); ++i){
// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
if(i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == 0){
continue;//相邻元素,且满足used[i - 1] == 0,那么之后会出现重复值,因此要跳过
}
target -= candidates[i];
path.push_back(candidates[i]);
backtracking(candidates, target, used, i);
//回溯
target += candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
}
};
解释:
关于used[i - 1] == 0
还是拿前面那张图为例
看第一条线,used的变化是:[0,0,0]->[1,0,0]->[1,1,0]/[1,0,1]
这个过程中,没有涉及到重复的组合
第一条线结束后,回溯至最开始的位置,然后开始走第二条线
因为[1,1,2]中,两个1是相邻重复元素,所以在第二条线中used为[0,1,0](即used[i - 1] == 0)就意味着之后会产生重复组合了(注意,必须同时满足当前元素是相邻重复元素且used[i - 1] == 0才符合可能出现重复组合的情况)
也就是说,在有两个相邻元素时(必须满足这个条件),如果used数组中出现元素1,那么1之前不能是0
例如这里第二条线还是取1,此时的i=1,并且used[i - 1] = used[0] = 0,并且确实两个相邻的1就是重复的,因此通过used可以判断出重复元素
再举一个例子,如果这里的candidates是[1,2,2],那么当i=1,也就是选取第一个2时,此时虽然也满足used[i - 1] == 0
但是第一个2的相邻元素是1,因此不构成重复元素条件,以此类推,到第二个2时,就满足了重复条件
此时,我们需要跳过满足上述情况的遍历值
代码
在使用回溯处理数组前,一定要先对数组进行排序
class Solution {
private:
vector<int> path;
vector<vector<int>> res;
void backtracking(vector<int>& candidates, int target, vector<bool>& used, int beginIndex){
//确定终止条件
if(target < 0){
return;
}
if(target == 0){
res.push_back(path);
return;
}
//确定单层处理逻辑
//注意,遍历条件还多了一个target >= 0
for(int i = beginIndex; i < candidates.size() && target >= 0; ++i){
// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == false,说明同一树层candidates[i - 1]使用过
if(i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == 0){
continue;//相邻元素,且满足used[i - 1] == 0,那么之后会出现重复值,因此要跳过
}
target -= candidates[i];
path.push_back(candidates[i]);
used[i] = true;//记录使用过当前值
backtracking(candidates, target, used, i + 1);//跳过当前值,因为每个数字在一个组合中只能用一次(相同值的算不同的数字)
//回溯
used[i] = false;
target += candidates[i];
path.pop_back();
}
}
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
//排序
sort(candidates.begin(), candidates.end());
//初始化use数组
vector<bool> used(candidates.size(), false);
backtracking(candidates, target, used, 0);
return res;
}
};
注意点
1、单层处理逻辑中的for循环条件
除了当前遍历的指针要在数组candidates大小范围内(i < candidates.size()),还要增加对于递归深度的约束条件,即target >= 0
因为我们是通过target自减来寻找满足条件的组合的,如果target都减到小于0了,那可能非法了,也就不需要再遍历当前非法的递归层了
2、是否跳过当前值
在单层处理逻辑调用递归时,如果允许在组合中出现重复元素,就不用跳过当前值
3、感觉解释得有点乱,如果再刷到有新的问题和理解再补充吧
TBD
【LeetCode回溯算法#04】组合总和I与组合总和II(单层处理位置去重)的更多相关文章
- 【LeetCode回溯算法#07】子集问题I+II,巩固解题模板并详解回溯算法中的去重问题
子集 力扣题目链接 给你一个整数数组 nums ,数组中的元素 互不相同 .返回该数组所有可能的子集(幂集). 解集 不能 包含重复的子集.你可以按 任意顺序 返回解集. 示例 1: 输入:nums ...
- 【LeetCode回溯算法#extra01】集合划分问题【火柴拼正方形、划分k个相等子集、公平发饼干】
火柴拼正方形 https://leetcode.cn/problems/matchsticks-to-square/ 你将得到一个整数数组 matchsticks ,其中 matchsticks[i] ...
- leetcode回溯算法--基础难度
都是直接dfs,算是巩固一下 电话号码的字母组合 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合. 给出数字到字母的映射如下(与电话按键相同).注意 1 不对应任何字母. 思路 一直 ...
- 【LeetCode回溯算法#06】复原IP地址详解(练习如何处理边界条件,判断IP合法性)
复原IP地址 力扣题目链接(opens new window) 给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式. 有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 ...
- 【LeetCode回溯算法#08】递增子序列,巩固回溯算法中的去重问题
递增子序列 力扣题目链接(opens new window) 给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2. 示例 1: 输入:nums = [4,6,7,7] ...
- 【LeetCode回溯算法#10】图解N皇后问题(即回溯算法在二维数组中的应用)
N皇后 力扣题目链接(opens new window) n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击. 给你一个整数 n ,返回所有不同的 n 皇 ...
- LeetCode通关:连刷十四题,回溯算法完全攻略
刷题路线:https://github.com/youngyangyang04/leetcode-master 大家好,我是被算法题虐到泪流满面的老三,只能靠发发文章给自己打气! 这一节,我们来看看回 ...
- LeetCode:回溯算法
回溯算法 这部分主要是学习了 labuladong 公众号中对于回溯算法的讲解 刷了些 leetcode 题,在此做一些记录,不然没几天就忘光光了 总结 概述 回溯是 DFS 中的一种技巧.回溯法采用 ...
- LeetCode刷题191203 --回溯算法
虽然不是每天都刷,但还是不想改标题,(手动狗头 题目及解法来自于力扣(LeetCode),传送门. 算法(78): 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明: ...
- C#LeetCode刷题-回溯算法
回溯算法篇 # 题名 刷题 通过率 难度 10 正则表达式匹配 18.8% 困难 17 电话号码的字母组合 43.8% 中等 22 括号生成 64.9% 中等 37 解数独 45.8% ...
随机推荐
- Hutool中那些常用的工具类和实用方法
背景 灵魂拷问1:还在为新项目工具类搬迁而烦恼? 灵魂拷问2:还在为项目中工具类维护而烦恼? 简述 **Hutool**它是一个Java工具集类库,包含了很多静态方法的封装:流处理.时间日期处理.正则 ...
- Dubbo架构设计与源码解析(一) 架构设计
作者:黄金 一.架构演变 单应用架构 ----> 垂直架构 ----> 分布式架构 ----> 微服务架构 ----> 云原生架构 二.Dubbo总体架构 1.角色职能 • C ...
- js 保留两位小数不进行四舍五入
保留两位小数不进行四舍五入 // 保留小数n位,不进行四舍五入 // num你传递过来的数字, // decimal你保留的几位,默认保留小数后两位 app.config.globalProperti ...
- 【笔记】macbook m2 芯片中使用 gcc docker 镜像来交叉编译
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 一个 c 程序,如何在 macbook m2 芯片的笔记本 ...
- kettle(docker版)系列文章01---docker部署
1.准备好kettle的镜像文件放在指定目录解压 docker image load -i /home/pdi/jztwebspoon.tar 2.起容器 docker run -d -p 7777: ...
- 离线生成双语字幕,一键生成中英双语字幕,基于AI大模型,ModelScope
制作双语字幕的方案网上有很多,林林总总,不一而足.制作双语字幕的原理也极其简单,无非就是人声背景音分离.语音转文字.文字翻译,最后就是字幕文件的合并,但美中不足之处这些环节中需要接口api的参与,比如 ...
- python快速入门【五】---- 面向对象编程、python类
python入门合集: python快速入门[一]-----基础语法 python快速入门[二]----常见的数据结构 python快速入门[三]-----For 循环.While 循环 python ...
- 阿里天池实验室简明教程以及Docker安装使用[一]
1.天池notebook简介和使用 天池实验室是基于PAI DSW探索版开发的,PAI DSW (Data Science Workshop)是为算法开发者量身打造的云天池实验室是基于PAI DSW探 ...
- 【5】Vscode Todo Tree插件使用和TODO、FIXME和XXX的注释使用说明以及自制自己的TODO图标样式!
相关文章: [一]tensorflow安装.常用python镜像源.tensorflow 深度学习强化学习教学 [二]tensorflow调试报错.tensorflow 深度学习强化学习教学 [三]t ...
- 将Windows系统设置为NTP服务器
环境 Windows 10,本机IP地址为:192.168.6.133 步骤 一.编辑注册表 win+r快捷键打开运行窗口,输入regedit打开注册表编辑器,找到以下几项并修改其值: 1.将type ...