DM数据库SQL分页案例
DM一哥们找我优化条分页的SQL语句,结果集很小返回99行数据,废话不说安排一下。
原始SQL语句如下,保密要求,给真实的表名换了别名:
SELECT count(*)
FROM (SELECT TMP.*,
ROWNUM ROW_ID
FROM (select *
from (select pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 name,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN '是'
WHEN jfw01.JFW01009 = '0' THEN '否'
else '' end) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (partition by jbt.task_oid order by jbti.UPDATED_DATE desc) as rn,
(case
when jbt.BIZ_STATUS_CODE = 'WU999' then ''
else
(SELECT bl.REMARK
FROM qqqqq bl
where bl.biz_Status_Code IN
('WU104', 'WU107', 'WM106', 'WM109', 'WM112', 'WU110', 'WM115', 'WU110',
'WM115')
AND bl.TASK_OID = jbt.TASK_OID
order by bl.CREATED_DATE DESC LIMIT 1) end) reCallOpinion,
to_char(rr.a15021, 'yyyy') as promoteYear,
rr.a15017 as reviewResultType
FROM aaaaa jbti,
bbbbb jbt
inner join ccccc pp
on
jbt.task_oid = pp.TASK_ID
left join ddddd jfw01
on
pp.biz_person_id = jfw01.biz_person_id
left join uuuuu jfa34
on
pp.biz_person_id = jfa34.biz_person_id
left join vvvvv bu
on
pp.UNIT_ID = bu.UNIT_ID
left join
(select ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark desc, id desc) AS num,
a15021,
a15017,
biz_person_id
from rrrrr) rr
on
pp.biz_person_id = rr.biz_person_id
and rr.num = '1'
WHERE jbt.task_oid = jbti.task_oid
and pp.UNIT_ID in
(select unit_oid
from sssss
where user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE in
(select jmn.FLOW_NODE_CODE
from jjjjj jmn
where jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC)
WHERE rn = 1) TMP
WHERE ROWNUM <= 100)
WHERE ROW_ID > 1;
执行时间:
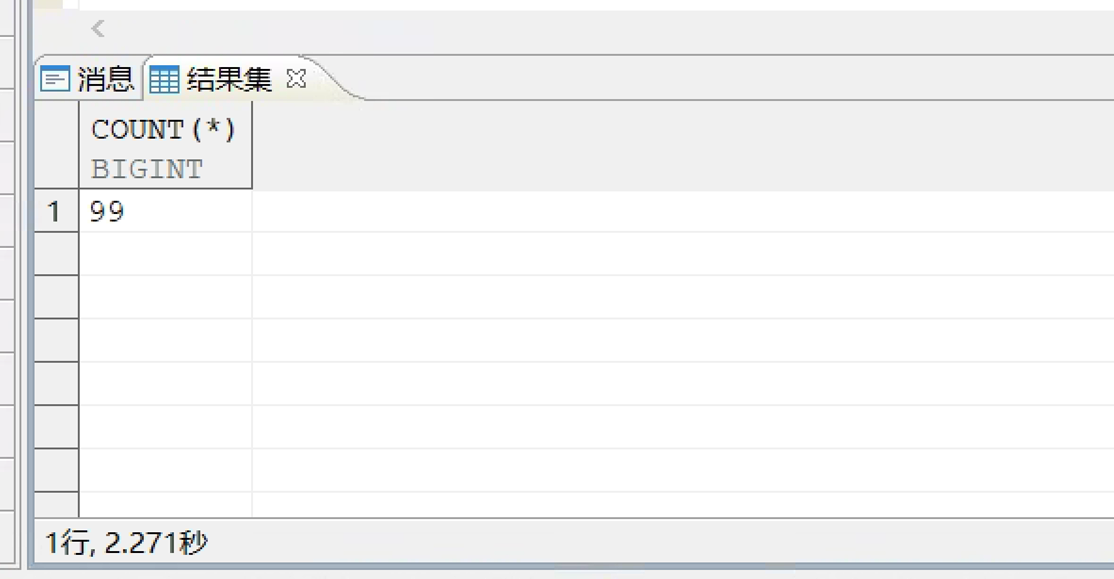
DM数据库的执行计划太难看了,直接忽略,用瞪眼大法观察下SQL大致看看是哪里慢的。
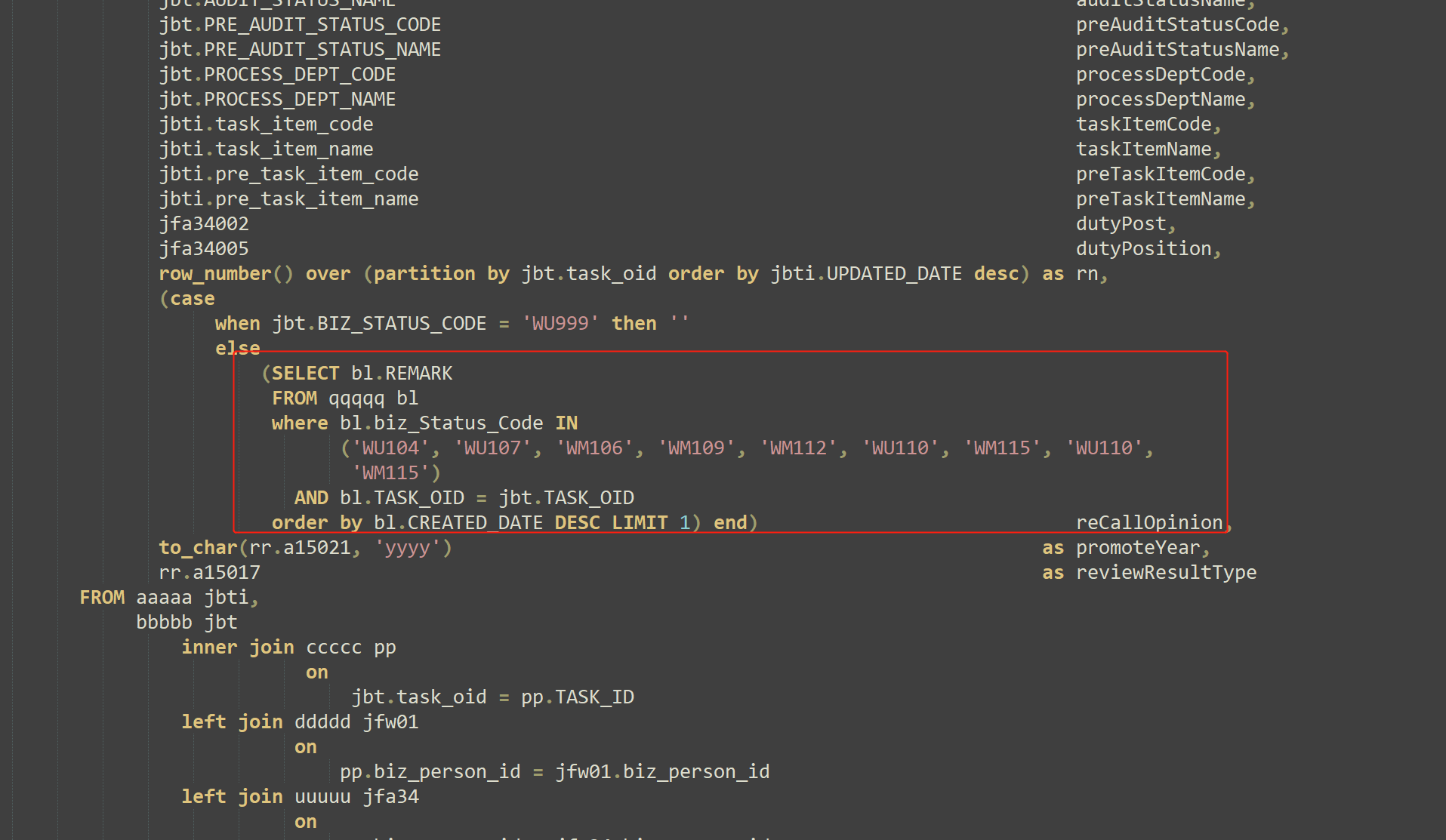
这段标量子查询去掉以后,单独把SQL拿出来跑,不加外层分页代码,0.1S能出结果,137条记录,大致判断是这里导致慢的因素。
select pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 name,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN '是'
WHEN jfw01.JFW01009 = '0' THEN '否'
else '' end) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (partition by jbt.task_oid order by jbti.UPDATED_DATE desc) as rn,
to_char(rr.a15021, 'yyyy') as promoteYear,
rr.a15017 as reviewResultType
FROM aaaaa jbti,
bbbbb jbt
inner join ccccc pp
on
jbt.task_oid = pp.TASK_ID
left join ddddd jfw01
on
pp.biz_person_id = jfw01.biz_person_id
left join uuuuu jfa34
on
pp.biz_person_id = jfa34.biz_person_id
left join vvvvv bu
on
pp.UNIT_ID = bu.UNIT_ID
left join
(select ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark desc, id desc) AS num,
a15021,
a15017,
biz_person_id
from rrrrr) rr
on
pp.biz_person_id = rr.biz_person_id
and rr.num = '1'
WHERE jbt.task_oid = jbti.task_oid
and pp.UNIT_ID in
(select unit_oid
from sssss
where user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE in
(select jmn.FLOW_NODE_CODE
from jjjjj jmn
where jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC
qqqqq 表加个联合索引再跑分页语句试试。
CREATE INDEX "IDX_TASK_BIZ" ON "qqqqq"("TASK_OID" ASC,"BIZ_STATUS_CODE" ASC) STORAGE(ON "hzgz_xcuatdb", CLUSTERBTR);
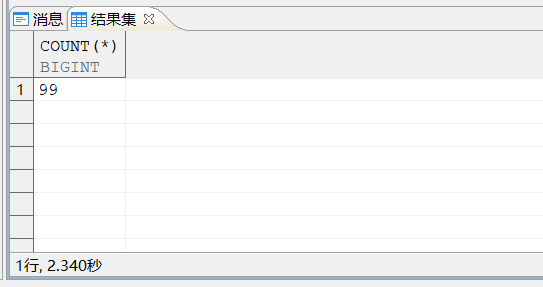
还是需要2.34S才能出结果,这个时候笔者就在想会不会是分页框架提供的分页方式不对,换个分页写法再试试。
-- 使用新的分页模板,没改语句
SELECT count(*)
FROM (SELECT *
FROM (SELECT t.*,
rownum ROW_ID
FROM (select pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 name,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN '是'
WHEN jfw01.JFW01009 = '0' THEN '否'
else '' end) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (partition by jbt.task_oid order by jbti.UPDATED_DATE desc) as rn,
(case
when jbt.BIZ_STATUS_CODE = 'WU999' then ''
else
(SELECT bl.REMARK
FROM qqqqq bl
where bl.biz_Status_Code IN
('WU104', 'WU107', 'WM106', 'WM109', 'WM112', 'WU110', 'WM115', 'WU110',
'WM115')
AND bl.TASK_OID = jbt.TASK_OID
order by bl.CREATED_DATE DESC LIMIT 1) end) reCallOpinion,
to_char(rr.a15021, 'yyyy') as promoteYear,
rr.a15017 as reviewResultType
FROM aaaaa jbti,
bbbbb jbt
inner join ccccc pp
on
jbt.task_oid = pp.TASK_ID
left join ddddd jfw01
on
pp.biz_person_id = jfw01.biz_person_id
left join uuuuu jfa34
on
pp.biz_person_id = jfa34.biz_person_id
left join vvvvv bu
on
pp.UNIT_ID = bu.UNIT_ID
left join
(select ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark desc, id desc) AS num,
a15021,
a15017,
biz_person_id
from rrrrr) rr
on
pp.biz_person_id = rr.biz_person_id
and rr.num = '1'
WHERE jbt.task_oid = jbti.task_oid
and pp.UNIT_ID in
(select unit_oid
from sssss
where user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE in
(select jmn.FLOW_NODE_CODE
from jjjjj jmn
where jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC) t)
WHERE rownum <= 100)
WHERE ROW_ID >= 1;
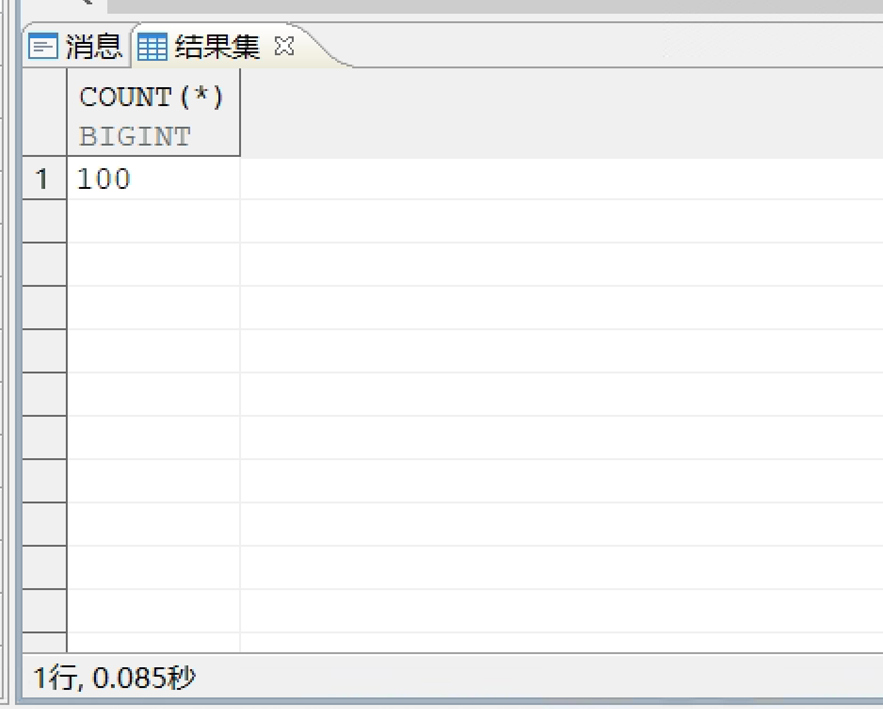
可以看到新的分页语句0.085S就能出结果了,简直秒杀。
总结:开发框架提的分页插件有可能提供错误的分页框架,会极大影响SQL语句原有的性能,需要多测试才能知道分页语句的性能是否符合性能要求,下面笔者提供个正确的分页框架:
select *
from (select *
from (select a.*, rownum rn from (
需要分页的 SQL
) a)
where rownum <= 10)
where rn >= 1;
最后,提供个left join 等价改写的方式干掉上面的标量子查询,但是在本案例中等价改写方式并没有太大性能提升,仅供娱乐:
-- 改分页模板,改SQL
SELECT count(*)
FROM (SELECT *
FROM (SELECT t.*,
rownum ROW_ID
FROM (SELECT pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 NAME,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN
'是'
WHEN jfw01.JFW01009 = '0' THEN
'否'
ELSE
''
END) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (PARTITION BY jbt.task_oid ORDER BY jbti.UPDATED_DATE DESC) AS rn,
(CASE WHEN jbt.BIZ_STATUS_CODE = 'WU999' THEN '' ELSE bl.REMARK END) reCallOpinion,
to_char(rr.a15021, 'yyyy') AS promoteYear,
rr.a15017 AS reviewResultType
FROM aaaaa jbti,
bbbbb jbt
left join
(select *
from (select REMARK,
TASK_OID,
row_number() over (PARTITION by TASK_OID ORDER by CREATED_DATE desc ) as rn
from qqqqq
where biz_Status_Code in ('WU104',
'WU107',
'WM106',
'WM109',
'WM112',
'WU110',
'WM115',
'WU110',
'WM115'))
where rn = 1) bl on jbt.task_oid = bl.task_oid
INNER JOIN ccccc pp
ON jbt.task_oid = pp.TASK_ID
LEFT JOIN ddddd jfw01
ON pp.biz_person_id = jfw01.biz_person_id
LEFT JOIN uuuuu jfa34
ON pp.biz_person_id = jfa34.biz_person_id
LEFT JOIN vvvvv bu
ON pp.UNIT_ID = bu.UNIT_ID
LEFT JOIN (SELECT ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark DESC, id DESC) AS num,
a15021,
a15017,
biz_person_id
FROM rrrrr) rr
ON pp.biz_person_id = rr.biz_person_id
AND rr.num = '1' WHERE jbt.task_oid = jbti.task_oid
AND pp.UNIT_ID IN
(SELECT unit_oid FROM sssss WHERE user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE IN
(SELECT jmn.FLOW_NODE_CODE
FROM jjjjj jmn
WHERE jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC) t)
WHERE rownum <= 99)
WHERE ROW_ID >= 1;
DM数据库SQL分页案例的更多相关文章
- 数据库SQL优化大总结之 百万级数据库优化方案(转载)
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 这篇文章我花费了大量的时间查找资料.修改.排版,希望大家阅读之后,感觉 ...
- 关于数据库SQL优化
1.数据库访问优化 要正确的优化SQL,我们需要快速定位能性的瓶颈点,也就是说快速找到我们SQL主要的开销在哪里?而大多数情况性能最慢的设备会是瓶颈点,如下载时网络速度可能会是瓶颈点,本地复制文件 ...
- 数据库sql优化总结之5--数据库SQL优化大总结
数据库SQL优化大总结 小编最近几天一直未出新技术点,是因为小编在忙着总结整理数据库的一些优化方案,特此奉上,优化总结较多,建议分段去消化,一口吃不成pang(胖)纸 一.百万级数据库优化方案 1.对 ...
- 盘点几种数据库的分页SQL的写法(转)
Data序列——盘点几种数据库的分页SQL的写法http://www.cnblogs.com/fireasy/archive/2013/04/10/3013088.html
- jDialects:一个从Hibernate抽取的支持70多种数据库方言的原生SQL分页工具
jDialects(https://git.oschina.net/drinkjava2/jdialects) 是一个收集了大多数已知数据库方言的Java小项目,通常可用来创建分页SQL和建表DDL语 ...
- 我的sql数据库存储过程分页- -
以前用到数据库存储过程分页的时候都是用 not in 但是最近工作的时候,随着数据库记录的不断增大,发现not in的效率 真的不行 虽然都设置了索引,但是当记录达到10w的时候就发现不行了,都是需要 ...
- sql分页查询(2005以后的数据库)和access分页查询
sql分页查询: select * from ( select ROW_NUMBER() over(order by 排序条件) as rowNumber,* from [表名] where 条件 ) ...
- oracle,mysql,SqlServer三种数据库的分页查询的实例。
MySql: MySQL数据库实现分页比较简单,提供了 LIMIT函数.一般只需要直接写到sql语句后面就行了.LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如 ...
- SQL分页查询,纯Top方式和row_number()解析函数的使用及区别
听同事分享几种数据库的分页查询,自己感觉,还是需要整理一下MS SqlSever的分页查询的. Sql Sever 2005之前版本: select top 页大小 * from 表名 where i ...
- MySQL 数据库增量数据恢复案例
MySQL 数据库增量数据恢复案例 一.场景概述 MySQL数据库每日零点自动全备 某天上午10点,小明莫名其妙地drop了一个数据库 我们需要通过全备的数据文件,以及增量的binlog文件进行数据恢 ...
随机推荐
- 【问题解决】docker版本v23.0后,构建Dockerfile中FROM私库镜像报错构建失败
问题情况 Docker版本在v23.0以后,只要Dockerfile中FROM的私库镜像不存在本地,就会报错: # 我本地是v24.0.2版本Docker [root@localhost ipd]# ...
- 实践分析丨AscendCL应用编译&运行案例
本文分享自华为云社区<AscendCL应用编译&运行问题案例>,作者: 昇腾CANN. AscendCL(Ascend Computing Language)是一套用于在昇腾平台上 ...
- Mysql高级2-SQL性能分析
一.SQL执行频率 MySQL客户端 连接成功后,通过show [session | global] status 命令可以提供服务器状态信息,通过如下指令,可以查看当前数据库的insert,upda ...
- Node: Module not found: Can't resolve 'xlsx'
报错信息 解决方案 npm install xlsx --save 参考链接 https://github.com/securedeveloper/react-data-export/issues/8 ...
- 批量获取FreeSWITCH所有分机号及其密码
前言 有次项目上需要获取所有FreeSWITCH注册分机的分机号和密码,就用python写了个小脚本来获取. 可以先把freeswitch/conf/directory/default/目录下的所有x ...
- 你们眼睛干涩,胀痛吗?C# WPF 久坐提醒桌面小程序
目录 说明 设置提醒时间,及休息时间 久坐提醒倒计时 休息提醒倒计时 休息到计时 代码说明 主窗体设置 工作到计时 休息倒计时 源码 久坐提醒桌面小程序: 干这行职业病比较多,之前用爱丽(即:玻璃酸钠 ...
- IDEA使用@Autowired注解为什么会提示不建议?
在使用IDEA编写Spring相关的项目时,当在字段上使用@Autowired注解时,总会出现一个波浪线提示:"Field injection is not recommended.&qu ...
- 【日常踩坑】从 SSLEOFError 到正确配置 Proxy
目录 踩坑 代理服务器 普通的代理服务器 因国家法律规定,部分内容已删除,完整内容请查看文章末尾链接 代理配置 追根溯源 urllib3 pip 万恶之源 urllib 参考资料 本文主要参考 Pyt ...
- 《Linux基础》07. 软件管理
@ 目录 1:软件管理 1.1:rpm 1.1.1:查询 1.1.2:卸载 1.1.3:安装 1.2:yum 1.3:dpkg 1.4:apt 1.4.1:相关配置 1.4.2:常用指令 1.4.3: ...
- RocketMQ 系列(二) 环境搭建
RocketMQ 系列(二) 环境搭建 上一个章节对于 RocketMQ 作了一些概念上的介绍,如果你对于 RocketMQ 没有概念,不妨先看RocketMQ系列(一) 基本介绍. 这个章节主要介绍 ...