精进语言模型:探索LLM Training微调与奖励模型技术的新途径
精进语言模型:探索LLM Training微调与奖励模型技术的新途径
LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。
有关 LLM 训练流程的更多细节可以参考 【LLM】从零开始训练大模型。
使用仓库之前,请先安装所有需要的依赖:
pip install -r requirements.txt
1. 继续预训练(Continue Pretraining)
继续预训练是指,在一个已有的模型上继续进行预训练增强,通常用于 英文模型的中文增强 或是 领域数据增强。
我们这里以英文模型 OpenLlama 在中文数据集 MNBVC 中的 少量数据 为例来演示整个流程。
1.1 数据压缩
由于预训练数据集通常比较庞大,因此先将训练数据进行压缩并流氏读取。
首先,进入到 data 目录:
cd data
找到目录下的 compress_data.py, 在该文件中修改需要压缩的数据路径:
SHARD_SIZE = 10 # 单个文件存放样本的数量, 示例中使用很小,真实训练可以酌情增大
...
def batch_compress_preatrain_data():
"""
批量压缩预训练数据。
"""
source_path = 'shuffled_data/pretrain' # 源数据文件
target_path = 'pretrain_data' # 压缩后存放地址
files = [ # 这三个文件是示例数据
'MNBVC_news',
'MNBVC_qa',
'MNBVC_wiki'
]
...
if __name__ == '__main__':
batch_compress_preatrain_data()
# batch_compress_sft_data()
Notes: 上述的 files 可以在 shuffled_data/pretrain/ 中找到,是我们准备的少量示例数据,真实训练中请替换为完整数据。
在 data 路径中执行 python compress_data.py, 终端将显示:
processed shuffled_data/pretrain/MNBVC_news.jsonl...
total line: 100
total files: 10
processed shuffled_data/pretrain/MNBVC_qa.jsonl...
total line: 50
total files: 5
processed shuffled_data/pretrain/MNBVC_wiki.jsonl...
total line: 100
total files: 10
随后可在 pretrain_data 中找到对应的 .jsonl.zst 压缩文件(该路径将在之后的训练中使用)。
1.2 数据源采样比例(可选)
为了更好的进行不同数据源的采样,我们提供了按照预设比例进行数据采样的功能。
我们提供了一个可视化工具用于调整不同数据源之间的分布,在 根目录 下使用以下命令启动:
streamlit run utils/sampler_viewer/web.py --server.port 8001
随后在浏览器中访问 机器IP:8001 即可打开平台。
我们查看 data/shuffled_data/pretrain 下各数据的原始文件大小:
-rw-r--r--@ 1 xx staff 253K Aug 2 16:38 MNBVC_news.jsonl
-rw-r--r--@ 1 xx staff 121K Aug 2 16:38 MNBVC_qa.jsonl
-rw-r--r--@ 1 xx staff 130K Aug 2 16:37 MNBVC_wiki.jsonl
并将文件大小按照格式贴到平台中:
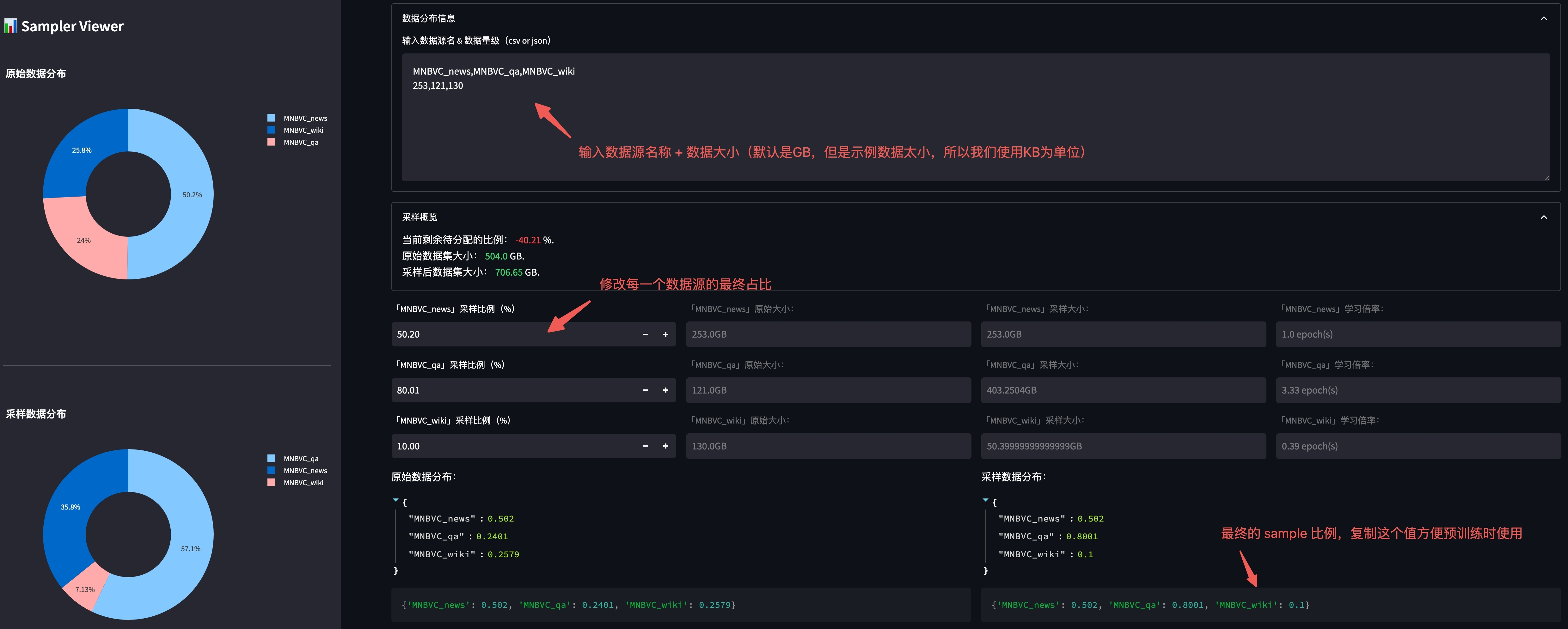
调整完毕后,复制上图右下角的最终比例,便于后续训练使用。
1.3 词表扩充(可选)
由于原始 Llama 的中文 token 很少,因此我们可以选择对原有的 tokenizer 进行词表扩充。
进入到 utils 目录:
cd utils
修改文件 train_tokenizer.py 中的训练数据(我们使用正式预训练训练数据集作为训练词表的数据集):
...
dataset = {
"MNBVC_news": "../data/pretrain_data/MNBVC_news/*.jsonl.zst",
"MNBVC_qa": "../data/pretrain_data/MNBVC_qa/*.jsonl.zst",
"MNBVC_wiki": "../data/pretrain_data/MNBVC_wiki/*.jsonl.zst",
}
执行完 train_tokenizer.py 后,路径下会出现训练好的模型 test_tokenizer.model。
随后,我们将训练好的 model 和原本的 llama model 做融合:
python merge_tokenizer.py
你可以使用 这个工具 很方便的对合并好后的 tokenizer 进行可视化。
1.4 平均初始化 extend token embedding(可选)
为了减小扩展的 token embedding 随机初始化带来模型性能的影响,我们提供使用将新 token 在原 tokenizer 中的 sub-token embedding 的平均值做为初始化 embedding 的方法。
具体使用方法在 utils/extend_model_token_embeddings.py。
1.5 正式训练
当完成上述步骤后就可以开始正式进行训练,使用以下命令启动训练:
sh train_llms.sh configs/accelerate_configs/ds_stage1.yaml \
configs/pretrain_configs/llama.yaml \
openlm-research/open_llama_7b_v2
多机多卡则启动:
sh train_multi_node_reward_model.sh configs/accelerate_configs/ds_stage1.yaml \
configs/pretrain_configs/llama.yaml \
openlm-research/open_llama_7b_v2
注意,所有的训练配置都放在了第 2 个参数 configs/pretrain_configs/llama.yaml 中,我们挑几个重要的参数介绍。
tokenizer_path (str):tokenizer 加载路径。ckpt (str):初始 model 加载路径。sample_policy_file (str):数据源采样配置文件,若不包含这一项则不进行数据源采样。train_and_eval (bool):该参数决定了是否在训练中执行评估函数。img_log_dir (str):训练过程中的 log 图存放目录。eval_methods (list):使用哪些评估函数,包括:single_choice_eval: 单选题正确率测试(如: C-Eval),评估数据格式参考
eval_data/knowledge/knowledge_and_reasoning.jsonl。generation_eval: 生成测试,给定 prompt,测试模型生成能力,评估数据格式参考
eval_data/pretrain/generation_test.jsonl。
work_dir (str):训练模型存放路径。save_total_limit (int):最多保存的模型个数(超过数目则删除旧的模型)
2. 指令微调(Instruction Tuning)
我们准备了部分 ShareGPT 的数据作为示例数据,我们仍旧使用 OpenLlama 作为训练的基座模型。
2.1 数据压缩
同预训练一样,我们先进入到 data 目录:
cd data
找到目录下的 compress_data.py, 在该文件中修改需要压缩的数据路径:
SHARD_SIZE = 10 # 单个文件存放样本的数量, 示例中使用很小,真实训练可以酌情增大
...
def batch_compress_sft_data():
"""
批量压缩SFT数据。
"""
source_path = 'shuffled_data/sft'
target_path = 'sft_data'
files = [
'sharegpt'
]
...
if __name__ == '__main__':
# batch_compress_preatrain_data()
batch_compress_sft_data()
Notes: 上述的 files 可以在 shuffled_data/sft/ 中找到,是我们准备的少量示例数据,真实训练中请替换为完整数据。
在 data 路径中执行 python compress_data.py, 终端将显示:
processed shuffled_data/sft/sharegpt.jsonl...
total line: 9637
total files: 964
随后可在 sft_data 中找到对应的 .jsonl.zst 压缩文件(该路径将在之后的训练中使用)。
2.2 特殊 token 扩充
受到 ChatML 的启发,我们需要在原有的 tokenizer 中添加一些 special token 用于对话系统。
一种最简单的方式是在 tokenizer 路径中找到 special_tokens_map.json 文件,并添加以下内容:
{
... # 需要添加的特殊 token
"system_token": "<|system|>", # system prompt
"user_token": "<|user|>", # user token
"assistant_token": "<|assistant|>", # chat-bot token
"chat_end_token": "<|endofchat|>" # chat end token
}
2.3 微调训练
当完成上述步骤后就可以开始正式进行训练,使用以下命令启动训练:
sh train_llms.sh configs/accelerate_configs/ds_stage1.yaml \
configs/sft_configs/llama.yaml \
openlm-research/open_llama_7b_v2
多机多卡则启动:
sh train_multi_node_reward_model.sh configs/accelerate_configs/ds_stage1.yaml \
configs/sft_configs/llama.yaml \
openlm-research/open_llama_7b_v2
注意,所有的训练配置都放在了第 2 个参数 configs/sft_configs/llama.yaml 中,我们挑几个重要的参数介绍。
tokenizer_path (str):tokenizer 加载路径。ckpt (str):初始 model 加载路径。train_and_eval (bool):该参数决定了是否在训练中执行评估函数。img_log_dir (str):训练过程中的 log 图存放目录。eval_methods (list):使用哪些评估函数,包括:generation_eval: 生成测试,给定 prompt,测试模型生成能力,评估数据格式参考
eval_data/sft/share_gpt_test.jsonl。暂无。
work_dir (str):训练模型存放路径。save_total_limit (int):最多保存的模型个数(超过数目则删除旧的模型)
3. 奖励模型(Reward Model)
3.1 数据集准备
我们准备 1000 条偏序对作为示例训练数据,其中 selected 为优势样本,rejected 为劣势样本:
{
"prompt": "下面是一条正面的评论:",
"selected": "很好用,一瓶都用完了才来评价。",
"rejected": "找了很久大小包装都没找到生产日期。上当了。"
}
这个步骤不再需要数据压缩,因此准备好上述结构的 .jsonl 文件即可。
3.2 RM 训练
当完成上述步骤后就可以开始正式进行训练,使用以下命令启动训练:
sh train_multi_node_reward_model.sh \
configs/accelerate_configs/ds_stage1.yaml \
configs/reward_model_configs/llama7b.yaml
注意,所有的训练配置都放在了第 2 个参数 configs/reward_model_configs/llama.yaml 中,我们挑几个重要的参数介绍。
tokenizer_path (str):tokenizer 加载路径。ckpt (str):初始 model 加载路径。train_and_eval (bool):该参数决定了是否在训练中执行评估函数。img_log_dir (str):训练过程中的 log 图存放目录。test_reward_model_acc_files (list):acc 测试文件列表。work_dir (str):训练模型存放路径。save_total_limit (int):最多保存的模型个数(超过数目则删除旧的模型)
项目链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/LLM/LLMsTrainer/readme.md
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

精进语言模型:探索LLM Training微调与奖励模型技术的新途径的更多相关文章
- 探索ASP.NET Core 3.0系列一:新的项目文件、Program.cs和generic host
前言:在这篇文章中我们来看看ASP.Net Core 3.0应用程序中一些基本的部分—— .csproj项目文件和Program.cs文件.我将会介绍它们从 ASP.NET Core 2.x 中的默认 ...
- Gazebo機器人仿真學習探索筆記(四)模型編輯
模型編輯主要是自定義編輯物體模型構建環境,也可以將多種模型組合爲新模型等,支持外部模型導入, 需要注意的導入模型格式有相應要求,否在無法導入成功, COLLADA (dae), STereoLitho ...
- AI探索(三)Tensorflow编程模型
Tensorflow编程模型 ....后续完善 import os os.environ[' import numpy as np num_points = data_array = [] for i ...
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案. 请注意, ...
- 🤗 PEFT: 在低资源硬件上对十亿规模模型进行参数高效微调
动机 基于 Transformers 架构的大型语言模型 (LLM),如 GPT.T5 和 BERT,已经在各种自然语言处理 (NLP) 任务中取得了最先进的结果.此外,还开始涉足其他领域,例如计算机 ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- 以小25倍参数量媲美GPT-3的检索增强自回归语言模型:RETRO
NLP论文解读 原创•作者 | 吴雪梦Shinemon 研究方向 | 计算机视觉 导读说明: 一个具有良好性能的语言模型,一定量的数据样本必不可少.现有的各种语言模型中,例如GPT3具有1750亿的参 ...
- 解密Prompt系列3. 冻结LM微调Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning
这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型.这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品.和前两章微调LM和全部冻结的pro ...
- 微软开源了一个 助力开发LLM 加持的应用的 工具包 semantic-kernel
在首席执行官萨蒂亚·纳德拉(Satya Nadella)的支持下,微软似乎正在迅速转变为一家以人工智能为中心的公司.最近微软的众多产品线都采用GPT-4加持,从Microsoft 365等商业产品到& ...
- 语言模型预训练方法(ELMo、GPT和BERT)——自然语言处理(NLP)
1. 引言 在介绍论文之前,我将先简单介绍一些相关背景知识.首先是语言模型(Language Model),语言模型简单来说就是一串词序列的概率分布.具体来说,语言模型的作用是为一个长度为m的文本确定 ...
随机推荐
- 拒绝了对对象 ‘GetTips‘ (数据库 ‘vipsoft‘,架构 ‘dbo‘)的 EXECUTE 权限
SQL Server 2016 安装 数据库-属性-权限-选择用户或角色-勾选执行权限即可.
- SQL Server 2016 安装
数据库安装 选择全新安装模式继续安装 输入产品秘钥:这里使用演示秘钥进行 接受许可 规则检测 可以后期再开放防火墙对外端口 选择需要安装的功能,想省事可以选择[全选] 可以安装JDK,这边选择取消 P ...
- No Feign Client for loadBalancing defined. Did you forget to include spring-cloud-starter-loadbalanc
No Feign Client for loadBalancing defined. Did you forget to include spring-cloud-starter-loadbalanc ...
- Mybatis 模块拆份带来的 Mapper 扫描问题
项目中,两个模块中都放了 Mapper,如下所示 @MapperScan(basePackages ={"com.vipsoft.his.mapper","com.vip ...
- 网络-华为、思科交换机配置TFTP自动备份、NTP时间同步、SYSLOG日志同步
配置使用TFTP进行交换机配置的自动保存 华为设备 <Huawei-sw>sys [Huawei-sw]set save-configuration interval 60 delay 3 ...
- 销售订单BAPI增强
一.需求背景 在销售订单批导时,需要调用BAPI:BAPI_SALESORDER_CREATEFROMDAT2维护成本中心字段, 二.增强实现 BAPI中没有该字段,需要通过增强的方式导入.通过BAP ...
- Windows 端使用 C++ 服务操作类
#pragma once #include <windows.h> #include <string> // #include <iostream> class S ...
- Vue项目中使用 tinymce 富文本编辑器的方法,附完整源码
Vue项目中使用 tinymce 富文本编辑器的方法,附完整源码 https://blog.csdn.net/snsHL9db69ccu1aIKl9r/article/details/11432414 ...
- hybird介绍
什么是hybird? hybrid即"混合",即前端和客户端的混合开发,需要前端开发人员和客户端开发人员配合完成. hybrid存在价值 可以快速迭代更新(无需app审核,思考为何 ...
- asio 使用 openssl 示例
#include <boost/asio.hpp> #include <boost/asio/ssl.hpp> #include <boost/algorithm/str ...