0013 基于DRF框架开发(01 基类视图 APIView)
之前学习了模型序列化和普通序列化,我们用最简单的视图和url实现了对序列化的操作。
而实际上,象之前那种由DRF自动生成所有的视图和url的情况,在应用是使用很少。而需要用户根据实际业务需求,自定义视图和url。
DRF提供了丰富的视图类,可以满足程序员的各种需求,基本上一个需求可以用多种视图来满足。
1 导入包
找到Applications/Exampls/views下的Schools.py文件,先导入以下包:
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from GeneralTools.CustomSchema import CustomSchema
from coreapi import Field
from coreschema import String
APIView根据浏览器url请求中是否带有ID参数分为两类。
2 url不带参请求
url不带参请求:浏览器请求时url中不带参数,主要用于查询和新增,与之对应的是get和post方法
不带参请求的类名格式为:模型名+List
在Schools.py中增加一个类,SchoolListView,代码如下:
class SchoolListView(APIView):
schema = CustomSchema(
manual_fields={
'post': [
Field(name='name', required=True, location='form', schema=String(description='学校名称')),
Field(name='email', required=False, location='form', schema=String(description='学校邮箱')),
Field(name='phone', required=True, location='form', schema=String(description='学校座机')),
Field(name='employment_rate', required=True, location='form', schema=String(description='就业率')),
Field(name='teacher_quantity', required=True, location='form', schema=String(description='教师人数')),
Field(name='student_quantity', required=True, location='form', schema=String(description='学生人数')),
Field(name='sms_code', required=True, location='form', schema=String(description='验证码')),
]
}
) @classmethod
def get(cls, request):
"""
【功能描述】用于查询所有学校信息</br>
【返回参数】</br>
1 name:学校名称</br>
2 email:学校电子邮箱</br>
3 phone:学校座机</br>
4 employment_rate:就业率</br>
5 teacher_quantity:教师人数</br>
6 student_quantity:学生人数</br>
"""
schools = Schools.objects.all()
serializer = SchoolsSerializer(schools, many=True)
return Response(serializer.data) @classmethod
def post(cls, request):
"""
【功能描述】用于新增学校信息</br>
【返回参数】</br>
1 成功返回201</br>
2 失败返回出错信息</br>
"""
serializer = SchoolsSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
为视图SchoolListViews增加一个url:path('SchoolList/', SchoolListView.as_view()),并在测试文档中测试,如图:
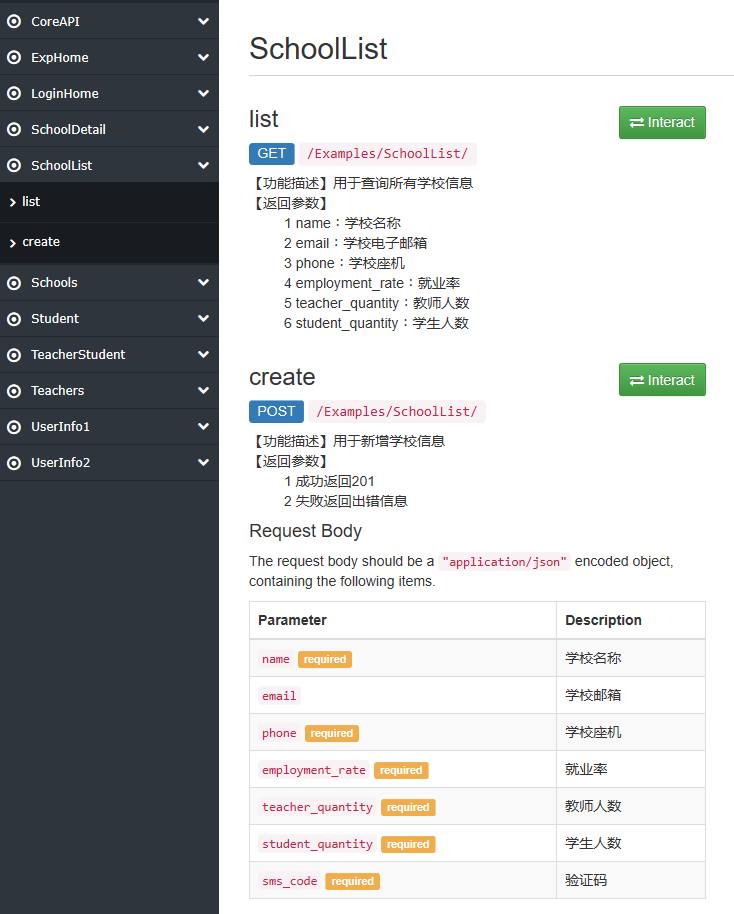
3 url带参数请求
带参数请求,主要是需要url中带上记录ID进行请求,主要用于查询指定记录(对应get方法),更改指定记录(对应put方法),删除指定记录(对应delete方法)
带参数请求的类名为:模型名+DetailView
在Schools.py中增加一个类,SchoolDetailView,代码如下:
class SchoolDetailView(APIView):
schema = CustomSchema(
manual_fields={
'put': [
Field(name='name', required=True, location='form', schema=String(description='学校名称')),
Field(name='email', required=False, location='form', schema=String(description='学校邮箱')),
Field(name='phone', required=True, location='form', schema=String(description='学校座机')),
Field(name='employment_rate', required=True, location='form', schema=String(description='就业率')),
Field(name='teacher_quantity', required=True, location='form', schema=String(description='教师人数')),
Field(name='student_quantity', required=True, location='form', schema=String(description='学生人数')),
Field(name='sms_code', required=True, location='form', schema=String(description='验证码')),
]
}
) @classmethod
def get(cls, request, pk):
"""
【功能描述】根据ID查询指定记录</br>
【返回参数】</br>
1 name:学校名称</br>
2 email:学校电子邮箱</br>
3 phone:学校座机</br>
4 employment_rate:就业率</br>
5 teacher_quantity:教师人数</br>
6 student_quantity:学生人数</br>
"""
try:
school = Schools.objects.get(pk=pk)
except Schools.DoesNotExist:
raise status.HTTP_404_NOT_FOUND
serializer = SchoolsSerializer(school)
return Response(serializer.data) @classmethod
def put(cls, request, pk):
"""
【功能描述】根据ID修改指定记录
【返回参数】</br>
1 name:学校名称</br>
2 email:学校电子邮箱</br>
3 phone:学校座机</br>
4 employment_rate:就业率</br>
5 teacher_quantity:教师人数</br>
6 student_quantity:学生人数</br>
"""
try:
school = Schools.objects.get(pk=pk)
except Schools.DoesNotExist:
raise status.HTTP_404_NOT_FOUND
serializer = SchoolsSerializer(school, data=request.data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(serializer.data) @classmethod
def delete(cls, request, pk):
"""
【功能描述】根据ID删除指定学校
【返回参数】</br>
1 成功返回204</br>
2 失败返回出错信息</br>
"""
try:
school = Schools.objects.get(pk=pk)
except Schools.DoesNotExist:
raise status.HTTP_404_NOT_FOUND
school.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
为视图SchoolDetailView增加一个url:path('SchoolDetail/<int:pk>', SchoolDetailView.as_view()),并在测试文档中测试,如图:
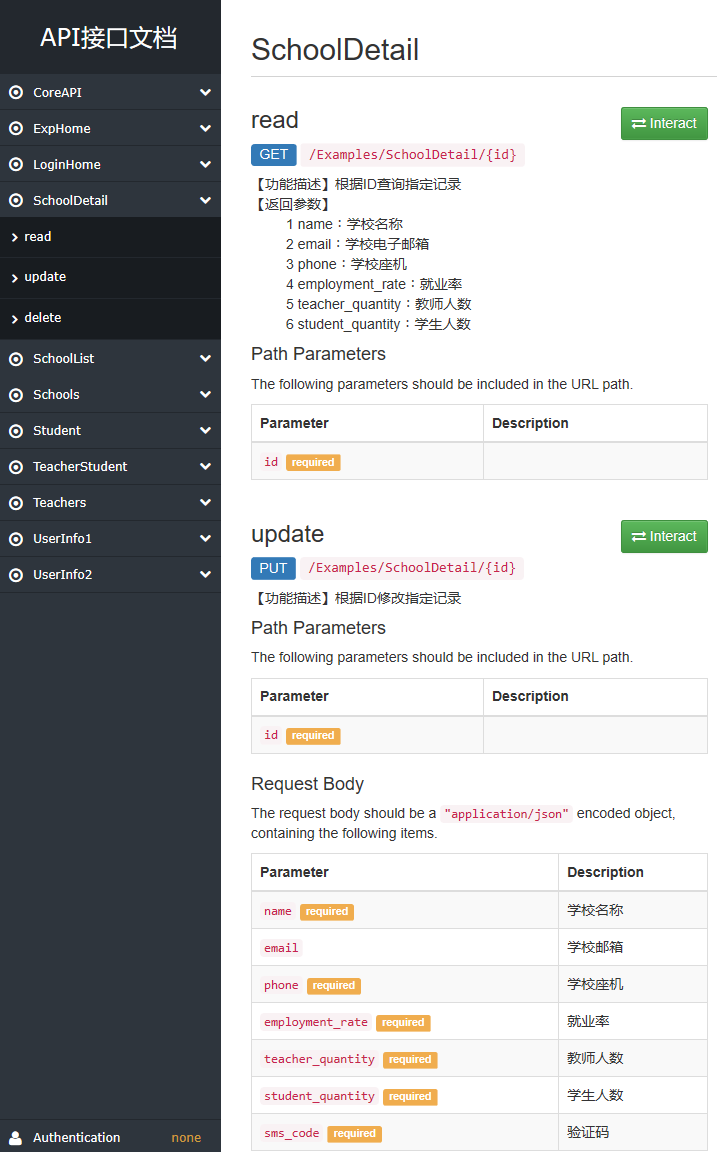
0013 基于DRF框架开发(01 基类视图 APIView)的更多相关文章
- 0014 基于DRF框架开发(02 基类视图 GenericAPIView)
前端于对数据操作的请求基本上就分为四类:增删改查,即增加.删除.修改.查询. 而DRF把前端请求分为两个大类:带ID参数请求和不带ID参数请求. 不带ID参数请求包括:增加.分布多条查询 带ID参数请 ...
- 0008 基于DRF框架开发(01 DRF开发的基本流程)
1 创建模型 由于之前在<004 工程配置>中,已在Applications/Organizations/models中创建了一个UserInfo模型.此处引用这个模型. from dja ...
- 0009 基于DRF框架开发(02 创建模型)
上一节介绍了DRF开发的基本流程,共五个步骤: 1 创建模型 2 创建序列化器 3 编写视图 4 配置URL 5 运行测试 本节主要讲解创建模型. 构建学校,教师,学生三个模型,这三个模型之间的关系是 ...
- 0010 基于DRF框架开发(03 模型序列化器)
序列化器:是指从数据库提取数据,转化前端所需要的数据格式并返回到前端. 反序列化器:是指把前端传回的数据,转换成数据库需要的格式,存入数据库. DRF提供了两种序列化器: 模型序列化器:是指和模型关联 ...
- 0012 基于DRF框架开发(04 序列化器的字段与选项)
1 常用字段类型 字段 构造方式 BooleanField BooleanField() NullBooleanField NullBooleanField() CharField CharField ...
- 0011 基于DRF框架开发(04 普通序列化器)
普通序列化器和模型无关,只是对针对提交字段的定义. 本文定义三个序列化器: 教师序列化器,学生序列化器,教师学生序列化器.这三个序列化器都使用普通序列化器. 1 教师序列化器 在Application ...
- 基于SSH框架开发的《高校大学生选课系统》的质量属性的实现
基于SSH框架开发的<高校大学生选课系统>的质量属性的实现 对于可用性采取的是错误预防战术,即阻止错误演变为故障:在本系统主要体现在以下两个方面:(1)对于学生登录模块,由于初次登陆,学生 ...
- MapReduce教程(一)基于MapReduce框架开发<转>
1 MapReduce编程 1.1 MapReduce简介 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题. MapReduce分成了两个部分: ...
- drf框架serializers中ModelSerializer类简化序列化和反序列化操作
0905自我总结 drf框架serializers中ModelSerializer类 基于seriallizer类进行简化 https://www.cnblogs.com/pythonywy/p/11 ...
随机推荐
- 最简单的windows 10 软路由
因为轻信了 小米路由器3潘多拉固件刷机教程 年前把自己的小米路由器3pro 刷程砖了,然后自己有一台 i5256 的三众小主机,连在电信光猫上,可以拨号,勉强可以用,but 家里的设备那么多尤其手机笔 ...
- 《Head first设计模式》之单例模式
单例模式(书中叫单件模式,个人习惯叫单例)确保一个类只有一个实例,并提供一个全局访问点. 有一些对象我们只需要一个,比方说:线程池.缓存.对话框.处理器偏好设置和注册表的对象等等.事实上,这类对象只能 ...
- 小程序在wxml页面格式化类似的2019-02-16T10:54:47.831000时间
其实新建小程序的时候,会有一个util.js文件,这个文件里已经有时间格式化的方法了,可是它却不能再wxml页面调用, 不过wxml页面是支持引入.wxs文件的,我们重新写一个这样子的工具文件就解决了 ...
- webpack 中那些最易混淆的 5 个知识点
学习博客:https://blog.csdn.net/wsyzxxn9/article/details/90677770 学习lodash:https://www.html.cn/doc/lodash ...
- 自动化测试中,cookie的调用方法。
以cookie为例 方法一: 将返回的cookie写到setUp()中,每次执行用例之前就会调用一次. 如: class AA(unittest.TestCase): def setUp(self): ...
- C# ,数据导出到带有级联下拉框的模板(一,模板的级联功能)
一.首先解决如何做模板中增加级联功能 1,首先打开一个新的Excel文件,新增sheet,把分类保存在里面,如下图所示 2.回到sheet1,选中要增加下拉框的行(注意:请排除首行,首行是标题) 3. ...
- C#使用Environment.TickCount 自定义的定时器类
Environment.TickCount, 官网介绍:一个 32 位带符号整数,它包含自上次启动计算机以来所经过的时间(以毫秒为单位). *由于 TickCount 属性值的值是32位有符号整数,因 ...
- Python实现进度条的4种方式
这里只列举了部分方法,其他方法或python库暂时还没使用到 马蜂窝刷粉丝[微信:156150954] 1.不用库,直接打印: 代码样例: import time #demo1 def process ...
- centos6.8 安装.net core2.1 sdk 或 .net core2.1 runtime
前段时间看.net core 更更更新了,大家反应都挺好,想有机会也学习一下,正好这两天要写一个简单的服务在centos上面跑,于是决定放弃使用java,直接.net core走起来,事情进行的非常顺 ...
- SparkShuffle机制
在早期版本的Spark中,shuffle过程没有磁盘读写操作,是纯内存操作,后来发现效率较低,且极易引发OOME,较新版本的Shuffle操作都加入了磁盘读写进行了改进. 1.未经优化的HashShu ...