论文阅读笔记(十三)【arxiv2018】:Revisiting Temporal Modeling for Video-based Person ReID
Introduction
(1)Motivation:
当前的一些video-based reid方法在特征提取、损失函数方面不统一,无法客观比较效果。本文作者将特征提取和损失函数固定,对当前较新的4种行人重识别模型进行比较。
(2)Contribution:
① 对四种ReId方法(temporal pooling, temporal attention, RNN and 3D conv)进行科学合理的比较;
② 提出了一种采用时空卷积提取时间特征的注意力提取网络。
Method
(1)视频片编码(video clip encoder):
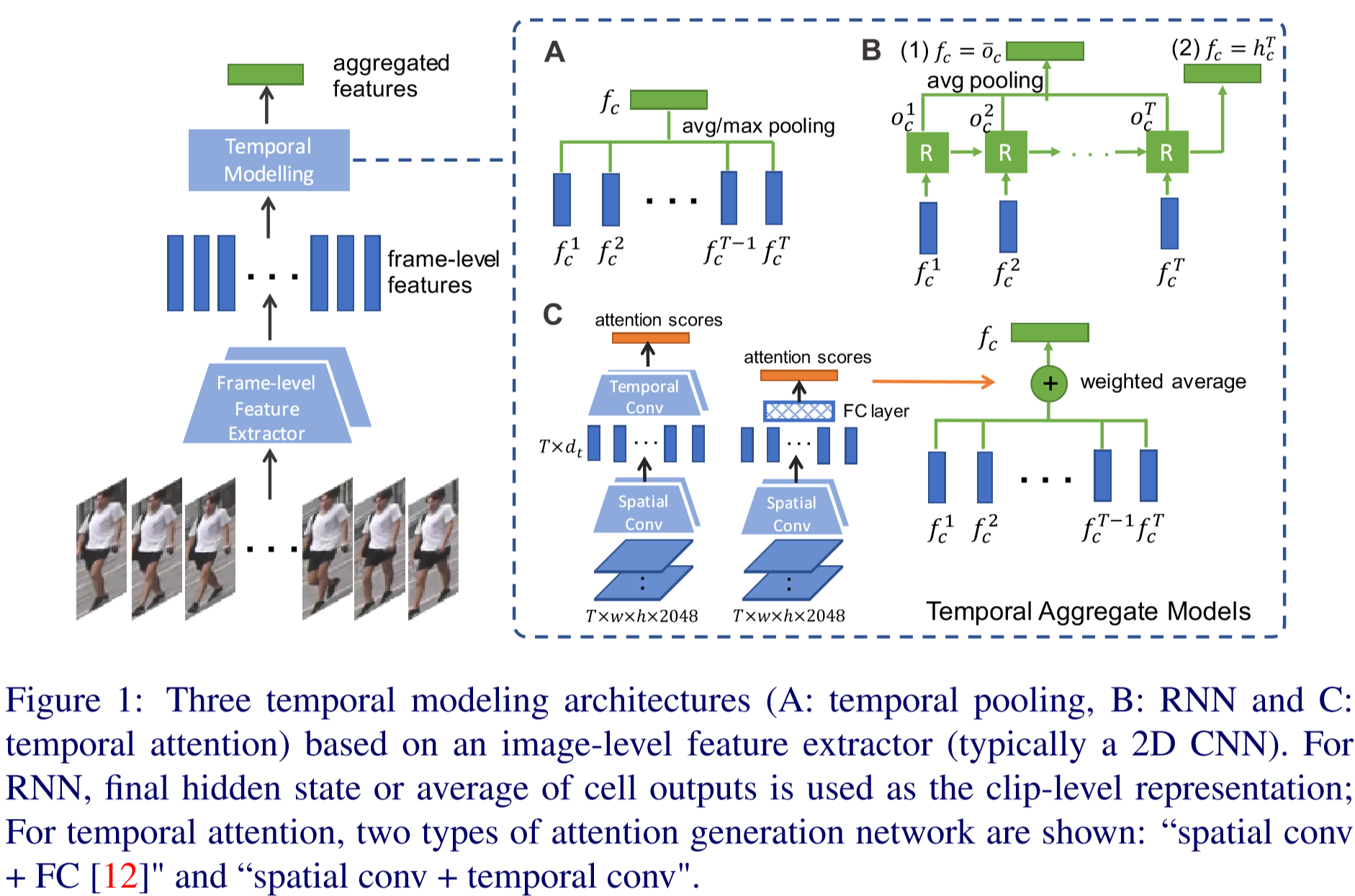
将视频切成若干片段 {ck},每个片段含有 T 帧,将每个片段编码成 D 维特征向量 fc ,视频的特征为这些片段取平均值。
① 3D CNN:采用3D ResNet模型,将最后一个分类层替换为行人身份的输出,将 T 帧输入网络中,输出即为特征表示。
对于 2D CNN:采用ResNet-50模型,每次输入一帧图像,每个片段提取 T 次特征,即 {fct},t 属于 [1, T],即 T*D 的特征矩阵,再采用以下方法将特征压缩到特征向量 fc 中。
② 时间池化(temporal pooling):考虑最大池化和平均池化,即:

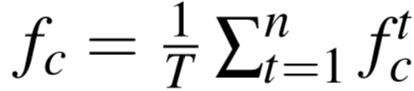
③ 时间注意力(temporal attention):应用注意力权重,设第 c 个视频段权重因子为 act,其中 t 属于 [1, T]:
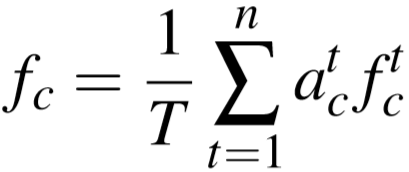
Resnet-50的最后卷积层规格 [w, h, 2048],其中 w 和 h 取决于输入图片的尺寸。
注意力提取网络的输入规格 [T, w, h, 2048],输出 T 个注意力得分。
考虑两种注意力网络:
空间卷积+全连接(spatial conv + FC):卷积层规格(kernel = w*h,input channel number = 2048,output channel number = dt),全连接层规格(input channel number = dt,output channel number = 1),输出结果为 sct,其中 t 属于 [1, T].
时空联合卷积(spatial + temporal conv):先通过空间卷积层(kernel = w*h,input channel number = 2048,output channel number = dt),再通过时间卷积层(个人理解参数3的含义是每个元素是由三帧计算而得,input channel number = dt,output channel number = 1),输出结果为 sct,其中 t 属于 [1, T].
使用softmax计算注意力得分 act:
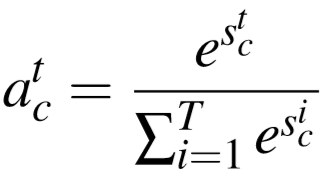
结合正则化(使用sigmoid函数):

④ RNN:考虑两种方法:
直接把隐藏层元素 hT 作为最后结果,即:

计算 RNN 输出 {ot} 的平均值,即:

(2)损失函数:
考虑两种损失函数,三元组损失(Batch Hard triplet loss)和交叉熵损失(Softmax cross-entropy loss)。
每个batch含有 P 个行人视频,每个视频含有 K 个视频片段,即每个batch含有 PK 个视频片段,三元组损失为:

交叉熵损失为:
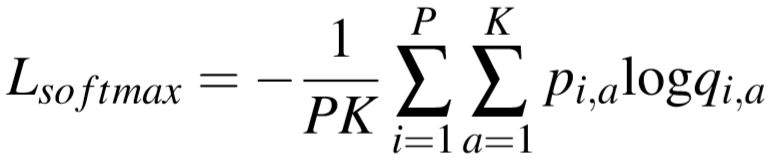
如何理解?

损失函数:
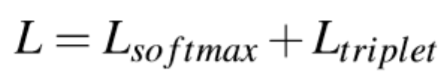
(3)相似度计算:
通过 L2 距离,计算视频特征的相似度。
Evaluation
(1)实验设置:
数据集:MARS
参数设置:batch size = 32,每个行人抽取4段tracklets,learning rate = 0.0001/0.0003,视频帧的规格为 224*112.(关于batch的设置描述模糊)
(2)实验结果:
① 3D CNN实验比较:

② Temporal pooling实验比较:

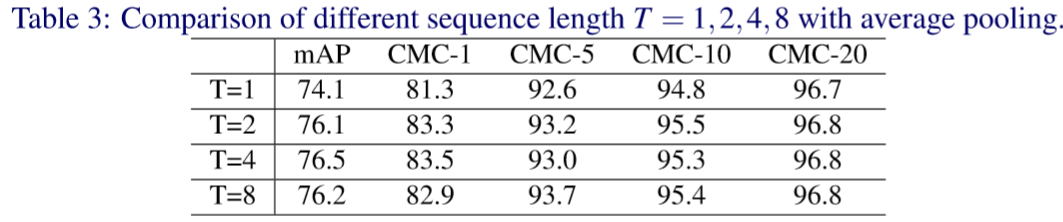
③ Temporal attention实验比较:


④ RNN实验比较:




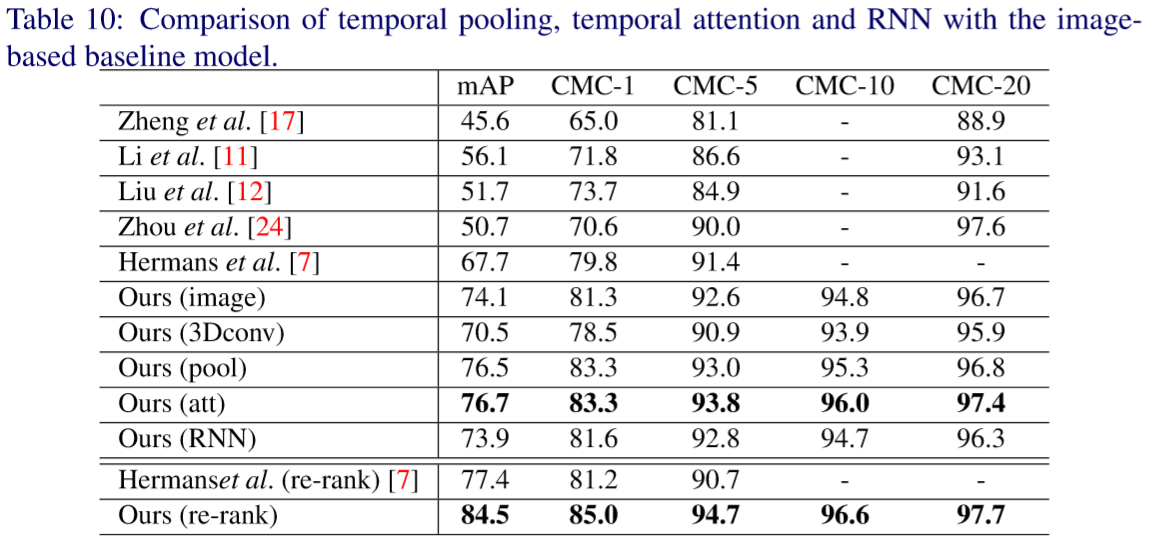
⑤ 对比方法:
论文阅读笔记(十三)【arxiv2018】:Revisiting Temporal Modeling for Video-based Person ReID的更多相关文章
- 论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)
论文链接:https://arxiv.org/pdf/1611.09326.pdf tensorflow代码:https://github.com/HasnainRaz/FC-DenseNet-Ten ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- [论文阅读笔记] Are Meta-Paths Necessary, Revisiting Heterogeneous Graph Embeddings
[论文阅读笔记] Are Meta-Paths Necessary? Revisiting Heterogeneous Graph Embeddings 本文结构 解决问题 主要贡献 算法原理 参考文 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
随机推荐
- PHP 中 new static 和 new self 的区别
今天老大在公司 问了一下 new static 和 new self 的区别 公司十个程序 竟然没有一个回答上来 后面画面自补 ... 本屌丝回家后 就百度了解了下 这二者区别 : ...
- nethogs-linux程序网络使用情况
netthogs可以显示每个程序的网络传输情况安装nethogs工具yum install https://mirrors.tuna.tsinghua.edu.cn/epel/7/x86_64/Pac ...
- Apache httpd.conf配置文件 3(虚拟主机)
### Section 3: Virtual Hosts 第三部分 虚拟主机 注意:在使用虚拟主机前,请先检查 http.conf 的 辅助配置文件httpd-vhosts.conf 是否注释 # ...
- php 安装 pdo_mysql
首先要安装 mysql客户端 然后再安装php mysql 扩展 1.安装 mysql客户端 和 mysql开发包 使用yum安装mysql client 到mysql官网下载 yum文件 http ...
- phpmyadmin配置文件详解
PHPMyadmin配置文件config.inc.php或config.default.php内容及作用解析大致如下: /** * phpMyAdmin Configuration File * * ...
- centos输入正确密码后依旧无法登陆问题
输入正确用户名和密码时依旧无法登录. 进入单用户模式重置密码: 开机启动时,按‘E’键(倒计时结束前)进入界面 选择第二项,按‘E’键再次进入 在最后一行添加‘ 1’(空格 1) 回车键保存,回到该界 ...
- href的几个特殊值
a href ="" :默认打开的还是当前页面,会刷新一下重新打开. a href ="#": 浏览器地址栏网址后面会多显示1个#.不会刷新页面,会回到页面顶部 ...
- nginx+uwsgi部署Django项目到Ubuntu服务器全过程,以及那些坑!!!
前言:自己在windows上用PyCharm编写的Django项目,编写完后在windows上运行一点问题都没有,但是部署到服务器上时却Bug百出.百度,CSDN,sf,各种搜索寻求解决方案在历时3天 ...
- Win10的Python3.8升级与安装
一.前言 1.说明 博主电脑Python3.6用了有3年多了,正好疫情期间有时间,给更新到3.8版本,边安装边记录下安装流程,希望对读者有帮助 2.系统环境 联想电脑,系统Win10,上一个Pytho ...
- Java自学-多线程 常见线程方法
Java 常见的线程方法 示例 1 : 当前线程暂停 Thread.sleep(1000); 表示当前线程暂停1000毫秒 ,其他线程不受影响 Thread.sleep(1000); 会抛出Inter ...