ACM北大暑期课培训第六天
今天讲了DFA,最小生成树以及最短路
DFA(接着昨天讲)
如何高效的构造前缀指针:
步骤为:根据深度一一求出每一个节点的前缀指针。对于当前节点,设他的父节点与他的边上的字符为Ch,如果他的父节点的前缀指针所指向的节点的儿子中,有通过Ch字符指向的儿子,那么当前节点的前缀指针指向该儿子节点,否则通过当前节点的父节点的前缀指针所指向点的前缀指针,继续向上查找,直到到达根节点为止。
ps:构造前缀指针时在最前面加一个0号节点。
对于一个插入了n个模式串的单词 前缀树构造其前缀指针的时间复杂 度为:O(∑len(i)) (i=1..n)
如何在建立好的Trie图上遍历:
遍历的方法如下:从ROOT出发,按照当前串的下一 个字符ch来进行在树上的移动。若当前点P不存在通过ch连接的儿子,那么考虑P的前缀指针指向的节点Q,如果还无法找到通过ch连接的儿子节点,再考虑Q的前缀指针… 直到找到通过ch连接的儿子,再继续遍历。如果遍历过程中经过了某个终止节点,则说明S包含该终止节点代表的模式串. 如果遍历过程中经过了某个非终止节点的危险节点, 则可以断定S包含某个模式串。要找出是哪个,沿着危险节点的前缀指针链走,碰到终止节点即可。
ps: 危险节点:1) 终止节点是危险节点 2) 如果一个节点的前缀指针指向危险节点,那么它也是危险节点。
这样遍历一个串S的时间复杂度是O(len(S))
最纯粹的Trie图题目:
给N个模式串,每个不超过个字符,再给M个句子,句子长度<
判断每个句子里是否包含模式串
N < , M < ,字符都是小写字母 abcde
defg
cdke
ab
f
abcdkef
abkef
bcd
bca
add
ab
qab
f
题目
#include <iostream>
#include <cstdio>
#include <cstring>
#include <vector>
#include <queue>
using namespace std;
#define LETTERS 26
int nNodesCount = ;
struct CNode
{
CNode * pChilds[LETTERS];
CNode * pPrev; //前缀指针
bool bBadNode; //是否是危险节点
void Init()
{
memset(pChilds,,sizeof(pChilds));
bBadNode = false;
pPrev = NULL;
}
};
CNode Tree[]; //10个模式串,每个10个字符,每个字符一个节点,也只要100个节点 void Insert( CNode * pRoot, char * s)
{
//将模式串s插入trie树
for( int i = ; s[i]; i ++ )
{
if( pRoot->pChilds[s[i]-'a'] == NULL)
{
pRoot->pChilds[s[i]-'a'] =Tree + nNodesCount;
nNodesCount ++;
}
pRoot = pRoot->pChilds[s[i]-'a'];
}
pRoot-> bBadNode = true;
}
void BuildDfa( )
{
//在trie树上加前缀指针
for( int i = ; i < LETTERS ; i ++ )
Tree[].pChilds[i] = Tree + ;
Tree[].pPrev = NULL;
Tree[].pPrev = Tree;
deque<CNode * > q;
q.push_back(Tree+);
while( ! q.empty() )
{
CNode * pRoot = q.front();
q.pop_front();
for( int i = ; i < LETTERS ; i ++ )
{
CNode * p = pRoot->pChilds[i];
if( p)
{
CNode * pPrev = pRoot->pPrev;
while( pPrev )
{
if( pPrev->pChilds[i] )
{
p->pPrev = pPrev->pChilds[i];
if( p->pPrev-> bBadNode)
p-> bBadNode = true;
//自己的pPrev指向的节点是危险节点,则自己也是危险节点
break;
}
else
pPrev = pPrev->pPrev;
}
q.push_back(p);
}
}
} //对应于while( ! q.empty() )
}
bool SearchDfa(char * s)
{
//返回值为true则说明包含模式串
CNode * p = Tree + ;
for( int i = ; s[i] ; i ++ )
{
while(true)
{
if( p->pChilds[s[i]-'a'])
{
p = p->pChilds[s[i]-'a'];
if( p-> bBadNode)
return true;
break;
}
else
p = p->pPrev;
}
}
return false;
}
int main()
{
nNodesCount = ;
int M,N;
scanf("%d%d",&N,&M); //N个模式串,M个句子
for( int i = ; i < N; i ++ )
{
char s[];
scanf("%s",s);
Insert(Tree + ,s);
}
BuildDfa();
for( int i = ; i < M; i ++ )
{
char s[];
scanf("%s",s);
cout << SearchDfa(s) << endl;
}
return ;
}
代码
PS:有可能模式串A是另一模式串B的子串,此情况下可能只能得出匹配B的结论而忽略也匹配A,所以不能只看终止节点,还要看危险节点:
对每个节点设置一个“是否计算过”的标记,当标记一个危险节点为“已匹配”时,沿该节点对应的S的所有后缀指针一直到根节点全标记为“已匹配”。
例题:1.POJ3987 Computer Virus on Planet Pandora 2010 福州赛区题目
2.POI #7 题:病毒
3.POJ 3691 DNA repair
4.POJ 1625 Censored!
5.POJ2778 DNA Sequence
最小生成树(MST)问题
生成树:
1.无向连通图的边的集合
2.无回路
3.连接所有的点
最小: 所有边的权值之和最小
有n个顶点,n-1条边
Prim算法
假设G=(V,E)是一个具有n个顶点的连通网, T=(U,TE)是G的最小生成树,U,TE初值均为空集。
首先从V中任取一个顶点(假定取v1),将它并入U中,此时U={v1},然后只要U是V的真子集(U∈V), 就从那些一个端点已在T中,另一个端点仍在T外 的所有边中,找一条最短边,设为(vi ,vj ),其中 vi∈U,vj∈V-U,并把该边(vi , vj )和顶点vj分别并入T 的边集TE和顶点集U,如此进行下去,每次往生成树里并入一个顶点和一条边,直到n-1次后得到最小生成树。
关键问题:每次如何从连接T中和T外顶点的所有边中,找 到一条最短的
1) 如果用邻接矩阵存放图,而且选取最短边的时候遍历所有点进行选取,则总时间复杂度为 O(V2 ), V为顶点个数
2)用邻接表存放图,并使用堆来选取最短边,则总时间复杂度为O(ElogV)
不加堆优化的Prim 算法适用于密集图,加堆优化的适用于稀疏图
Kruskal算法
假设G=(V,E)是一个具有n个顶点的连通网, T=(U,TE)是G的最小生成树,U=V,TE初值为 空。
将图G中的边按权值从小到大依次选取,若选取的边使生成树不形成回路,则把它并入TE中,若形成回路则将其舍弃,直到TE 中包含N-1条边为止,此时T为最小生成树。
关键问题:如何判断欲加入的一条边是否与生成树 中边构成回路。
利用并查集!
Kruskal 和 Prim 比较
Kruskal:将所有边从小到大加入,在此过程中 判断是否构成回路
– 使用数据结构:并查集
– 时间复杂度:O(ElogE)
– 适用于稀疏图
Prim:从任一节点出发,不断扩展
– 使用数据结构:堆
– 时间复杂度:O(ElogV) 或 O(VlogV+E)(斐波那契堆)
– 适用于密集图
– 若不用堆则时间复杂度为O(V2)
例题:1.POJ 1258 Agri-Net
2.POJ 2349 Arctic Network
3. 2011 ACM/ICPC亚洲区预选赛北京赛站
Problem A. Qin Shi Huang’s National Road System
最短路算法
Dijkstra 算法 解决无负权边的带权有向图 或 无向图的单源最短路问题
用邻接表,不优化,时间复杂度O(V2+E)
Dijkstra+堆的时间复杂度 o(ElgV)
用斐波那契堆可以做到O(VlogV+E)
若要输出路径,则设置prev数组记录每个节点的前趋点,在d[i] 更新时更新prev[i]
Dijkstra算法实现:
已经求出到V0点的最短路的点的集合为T
维护Dist数组,Dist[i]表示目前Vi到V0的“距离”
开始Dist[0] = 0, 其他Dist[i] = 无穷大, T为空集
1) 若|T| = N,算法完成,Dist数组就是解。否则取Dist[i]最 小的不在T中的点Vi, 将其加入T,Dist[i]就是Vi到V0的最短 路长度。
2) 更新所有与Vi有边相连且不在T中的点Vj的Dist值: Dist[j] = min(Dist[j],Dist[i]+W(Vi,Vj))
3) 转到1)
例题:1.POJ 3159 Candies
Bellman-Ford算法
解决含负权边的带权有向图的单源最短路径问题
不能处理带负权边的无向图(因可以来回走一条负权边)
限制条件: 要求图中不能包含权值总和为负值回路(负权值回路),如下图所示。 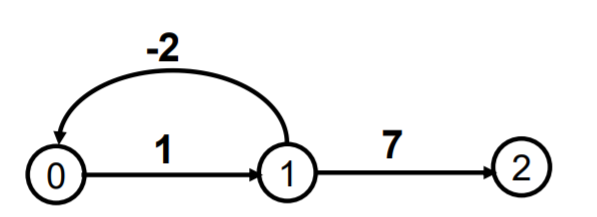
Bellman-Ford算法思想:
构造一个最短路径长度数组序列dist 1 [u], dist 2 [u], …, dist n-1 [u] (u = 0,1…n-1,n为点数)
dist n-1 [u]为从源点v出发最多经过不构成负权值回路的n-1条边到达终点u的 最短路径长度;
算法的最终目的是计算出dist n-1 [u],为源点v到顶点u的最短路径长度。
递推公式(求顶点u到源点v的最短路径):
dist 1 [u] = Edge[v][u]
dist k [u] = min{ dist k-1 [u], min{ dist k-1 [j] + Edge[j][u] } }, j=0,1,…,n-1,j≠u
若存在dist n [u] < dist n-1 [u],则说明存在从源点可达的负权值回路
在求出distn-1[ ]之后,再对每条边<u,k>判断一下:加入这条边是否会使得顶点k的最短路径值再缩短,即判断:dist[u]+w(u,k)<dist[k]否成立,如果成立,则说明存在从源点可达的负权值回路。
存在负权回路就一定能导致该式成立的证明:
如果成立,则说明找到了一条经过了n条边的从 s 到k的路径,且 其比任何少于n条边的从s到k的路径都短。
一共n个顶点,路径却经过了n条边,则必有一个顶点m经过了至少 两次。则m是一个回路的起点和终点。走这个回路比不走这个回路 路径更短,只能说明这个回路是负权回路。
Bellman-Ford算法改进:
Bellman-Ford算法不一定要循环n-1次,n为顶点个数,只要在某次循环过程中,考虑每条边后,源点到所有顶点的最短路径 长度都没有变,那么Bellman-Ford算法就可以提前结束了
Dijkstra算法与Bellman-Ford算法的区别
Dijkstra算法和Bellman算法思想有很大的区别:
Dijkstra算法在求解过程中,源点到集合S内各顶点的最短路径一旦求出,则之后不变了,修改的仅仅是源点到S外各顶点的最短路径长度。
Bellman-Ford算法在求解过程中,每次循环都要修改所有顶点的dist[ ],也就是说源点到各顶点最短路径长度一 直要到算法结束才确定下来。
例题:1.POJ 3259 Wormholes
要求判断任意两点都能仅通过正边就互相可达的有向图(图中有
重边)中是否存在负权环
Sample Input Sample Output
NO
YES 2个test case
每个test case 第一行:
N M W (N<=,M<=,W<=)
N个点
M条双向正权边
W条单向负权边
第一个test case 最后一行 是单向负权边,->1的边权值是-
题目
//by guo wei
#include <iostream>
#include <vector>
using namespace std;
int F,N,M,W;
const int INF = << ;
struct Edge
{
int s,e,w;
Edge(int ss,int ee,int ww):s(ss),e(ee),w(ww) { }
Edge() { }
};
vector<Edge> edges; //所有的边
int dist[];
int Bellman_ford(int v)
{
for( int i = ; i <= N; ++i)
dist[i] = INF;
dist[v] = ;
for( int k = ; k < N; ++k) //经过不超过k条边
{
for( int i = ; i < edges.size(); ++i)
{
int s = edges[i].s;
int e = edges[i].e;
if( dist[s] + edges[i].w < dist[e])
dist[e] = dist[s] + edges[i].w;
}
}
for( int i = ; i < edges.size(); ++ i)
{
int s = edges[i].s;
int e = edges[i].e;
if( dist[s] + edges[i].w < dist[e])
return true;
}
return false;
}
int main()
{
cin >> F;
while( F--)
{
edges.clear();
cin >> N >> M >> W;
for( int i = ; i < M; ++ i)
{
int s,e,t;
cin >> s >> e >> t;
edges.push_back(Edge(s,e,t)); //双向边等于两条边
edges.push_back(Edge(e,s,t));
}
for( int i = ; i < W; ++i)
{
int s,e,t;
cin >> s >> e >> t;
edges.push_back(Edge(s,e,-t));
}
if( Bellman_ford())//从1可达所有点
cout << "YES" <<endl;
else cout << "NO" <<endl;
}
}
for( int k = ; k < N; ++k) { //经过不超过k条边
for( int i = ;i < edges.size(); ++i) {
int s = edges[i].s;
int e = edges[i].e;
if( dist[s] + edges[i].w < dist[e])
dist[e] = dist[s] + edges[i].w;
}
}
会导致在一次内层循环中,更新了某个 dist[x]后,以后又用dist[x]去更新dist[y],这样dist[y]就是经过最多不超过k+1条边的情况了
出现这种情况没有关系,因为整个 for( int k = ; k < N; ++k) 循环的目的是要确保,对任意点u,如果从源s到u的最短路是经过不超过n-1条边的,则这条最短路不会被忽略。至于计算过程中对某些点 v 计算出了从s->v的经过超过N-1条边的最短路的情况,也不影响结果正确性。若是从s->v的经过超过N-1条边的结果比经过最多N-1条边的结果更小,那一定就有负权回路。有负权回路的情况下,再多做任意多次循环,每次都会发现到有些点的最短路变得更短了。
问题
2.POJ 1860
3.POJ 3259
4.POJ 2240
SPFA算法
快速求解含负权边的带权有向图的单源最短路径问题
是Bellman-Ford算法的改进版,利用队列动态更新dist[]
维护一个队列,里面存放所有需要进行迭代的点。初始时队列中只有一个 源点S。用一个布尔数组记录每个点是否处在队列中。
每次迭代,取出队头的点v,依次枚举从v出发的边v->u,若 Dist[v]+len(v->u) 小于Dist[u],则改进Dist[u](可同时将u前驱记为v)。 此时由于S到u的最短距离变小了,有可能u可以改进其它的点,所以若u不在队列中,就将它放入队尾。这样一直迭代下去直到队列变空,也就是S到所有节点的最短距离都确定下来,结束算法。若一个点最短路被改进的次数达到n ,则有负权环(原因同B-F算法。可以用spfa算法判断图有无负权环
在平均情况下,SPFA算法的期望时间复杂度为O(E)。
例题:1.POJ 3259 Wormholes
要求判断任意两点都能仅通过正边就互相可达的有向图(图中有
重边)中是否存在负权环
Sample Input Sample Output
NO
YES 2个test case
每个test case 第一行:
N M W (N<=,M<=,W<=)
N个点
M条双向正权边
W条单向负权边
第一个test case 最后一行 是单向负权边,->1的边权值是-
题目
///POJ3259 Wormholes 判断有没有负权环spfa
//by guo wei
#include <iostream>
#include <vector>
#include <queue>
#include <cstring>
using namespace std;
int F,N,M,W;
const int INF = << ;
struct Edge
{
int e,w;
Edge(int ee,int ww):e(ee),w(ww) { }
Edge() { }
};
vector<Edge> G[]; //整个有向图
int updateTimes[]; //最短路的改进次数
int dist[]; //dist[i]是源到i的目前最短路长度
int Spfa(int v)
{
for( int i = ; i <= N; ++i)
dist[i] = INF;
dist[v] = ;
queue<int> que;
que.push(v);
memset(updateTimes,,sizeof(updateTimes));
while( !que.empty())
{
int s = que.front();
que.pop();
for( int i = ; i < G[s].size(); ++i)
{
int e = G[s][i].e;
if( dist[e] > dist[s] + G[s][i].w )
{
dist[e] = dist[s] + G[s][i].w;
que.push(e); //没判队列里是否已经有e,可能会慢一些
++updateTimes[e];
if( updateTimes[e] >= N) return true;
}
}
}
return false;
}
int main()
{
cin >> F;
while( F--)
{
cin >> N >> M >> W;
for( int i = ; i <; ++i)
G[i].clear();
int s,e,t;
for( int i = ; i < M; ++ i)
{
cin >> s >> e >> t;
G[s].push_back(Edge(e,t));
G[e].push_back(Edge(s,t));
}
for( int i = ; i < W; ++i)
{
cin >> s >> e >> t;
G[s].push_back(Edge(e,-t));
}
if( Spfa())
cout << "YES" <<endl;
else cout << "NO" <<endl;
}
}
POJ 3259
2.POJ 2387
3.POJ 3256
弗洛伊德算法
用于求每一对顶点之间的最短路径。有向图,无向图均可,也可以有负权边。但不适合于有负权回路的题。
复杂度O(n3)
///弗洛伊德算法伪代码(三层循环)
for( int i = ; i <= vtxnum; ++i )
for( int j = ; j <= vtxnum; ++j)
{
dist[i][j] = cost[i][j]; // cost是边权值, dist是两点间最短距离
if( dist[i][j] < INFINITE) //i到j有边
path[i,j] = [i]+[j]; //path是路径
}
for( k = ; k <= vtxnum; ++k) //每次求中间点标号不超过k的i到j最短路
for( int i = ; i <= vtxnum; ++i)
for(int j = ; j <= vtxnum ; ++j)
if( dist[i][k] + dist[k][j] < dist[i][j])
{
dist[i][j] = dist[i][k]+dist[k][j];
path[i,j] = path[i,k]+path[k,j];
}
例题:1.POJ 3660 Cow Contest
2.POJ 1125
ACM北大暑期课培训第六天的更多相关文章
- ACM北大暑期课培训第一天
今天是ACM北大暑期课开课的第一天,很幸运能参加这次暑期课,接下来的几天我将会每天写博客来总结我每天所学的内容.好吧下面开始进入正题: 今天第一节课,郭炜老师给我们讲了二分分治贪心和动态规划. 1.二 ...
- ACM北大暑期课培训第七天
昨天没时间写,今天补下. 昨天学的强连通分支,桥和割点,基本的网络流算法以及Dinic算法: 强连通分支 定义:在有向图G中,如果任意两个不同的顶点 相互可达,则称该有向图是强连通的. 有向图G的极大 ...
- ACM北大暑期课培训第二天
今天继续讲的动态规划 ... 补充几个要点: 1. 善于利用滚动数组(可减少内存,用法与计算方向有关) 2.升维 3.可利用一些数据结构等方法使代码更优 (比如优先队列) 4.一般看到数值小的 (十 ...
- ACM北大暑期课培训第八天
今天学了有流量下界的网络最大流,最小费用最大流,计算几何. 有流量下界的网络最大流 如果流网络中每条边e对应两个数字B(e)和C(e), 分别表示该边上的流量至少要是B(e),最多 C(e),那么,在 ...
- ACM北大暑期课培训第五天
今天讲的扫描线,树状数组,并查集还有前缀树. 扫描线 扫描线的思路:使用一条垂直于X轴的直线,从左到右来扫描这个图形,明显,只有在碰到矩形的左边界或者右边界的时候,这个线段所扫描到的情况才会改变, ...
- ACM北大暑期课培训第四天
今天讲了几个高级搜索算法:A* ,迭代加深,Alpha-Beta剪枝 以及线段树 A*算法 启发式搜索算法(A算法) : 在BFS算法中,若对每个状态n都设定估价函数 f(n)=g(n)+h(n) ...
- ACM北大暑期课培训第三天
今天讲的内容是深搜和广搜 深搜(DFS) 从起点出发,走过的点要做标记,发现有没走过的点,就随意挑一个往前走,走不 了就回退,此种路径搜索策略就称为“深度优先搜索”,简称“深搜”. bool Dfs( ...
- 2019暑期北航培训—预培训作业-IDE的安装与初步使用(Visual Studio版)
这个作业属于那个课程 2019北航软件工程暑期师资培训 这个作业要求在哪里 预培训-IDE的安装与初步使用(Visual Studio版) 我在这个课程的目标是 提高自身实际项目实践能力,掌握帮助学生 ...
- 01派【北京大学ACM/ICPC竞赛训练暑期课】
01:派 总时间限制: 1000ms 内存限制: 65536kB 描述 我的生日要到了!根据习俗,我需要将一些派分给大家.我有N个不同口味.不同大小的派.有F个朋友会来参加我的派对,每个人会拿到一 ...
随机推荐
- 【原生JS】滑动门效果
效果图: 思路:通过每次鼠标移动至目标上使所有图片重置为初始样式再向左移动目标及其左侧每个图片隐藏部分距离即实现. HTML: <!DOCTYPE html> <html> & ...
- Django使用cors解决跨域问题
1.安装Django-cors-headers模块 pip install django-cors-headers 2.配置settings.py文件 INSTALLED_APPS = [ ... ' ...
- 【codeforces 789B】Masha and geometric depression
[题目链接]:http://codeforces.com/contest/789/problem/B [题意] 让你一个一个地写出等比数列的每一项 (注意是一个一个地写出); 有m个数字不能写; 且数 ...
- P1068 压缩技术
题目描述 设某汉字由N × N的0和1的点阵图案组成. 我们依照以下规则生成压缩码.连续一组数值:从汉字点阵图案的第一行第一个符号开始计算,按书写顺序从左到右,由上至下.第一个数表示连续有几个0,第二 ...
- P1006 输出第二个整数
题目描述 输入三个整数,整数之间由一个空格分隔,整数是32位有符号整数.把第二个输入的整数输出. 输入格式 输入三个整数,整数之间由一个空格分隔,整数是32位有符号整数. 输出格式 输出输入的三个整数 ...
- linux 后备缓存
一个设备驱动常常以反复分配许多相同大小的对象而结束. 如果内核已经维护了一套相同 大小对象的内存池, 为什么不增加一些特殊的内存池给这些高容量的对象? 实际上, 内核 确实实现了一个设施来创建这类内存 ...
- linux Tasklets 机制
tasklet 类似内核定时器在某些方面. 它们一直在中断时间运行, 它们一直运行在调度它 们的同一个 CPU 上, 并且它们接收一个 unsigned long 参数. 不象内核定时器, 但是, 你 ...
- 应用八:Vue之在nginx下的部署实践
最近有时间研究了下前端项目如何在nginx服务器下进行部署,折腾了两天总算有所收获,汗~~ 所以就想着写篇文章来总结一下,主要包括以下三个方面: 1.打包好的vue项目如何进行部署. 2.如何反向代理 ...
- Linux 字节序
小心不要假设字节序. PC 存储多字节值是低字节为先(小端为先, 因此是小端), 一些高 级的平台以另一种方式(大端)工作. 任何可能的时候, 你的代码应当这样来编写, 它不在 乎它操作的数据的字节序 ...
- es6笔记 day2---字符串模板及字符串新增
字符串连接案例 注意:引号变了,为键盘数字1旁边的飘花键 以前的老写法是在字符串中加入“+”号,给几个字符串给串起来,那种写法是要死人的. 现在只需加上一对``即可将字符串连接起来 --------- ...