python基础--包、logging、hashlib、openpyxl、深浅拷贝
包:它是一系列模块文件的结合体,表现形式就是一个文件夹,该文件夹内部通常会有一个__init__.py文件,包的本质还是一个模块。
首次导入包:(在导入语句中中 . 号的左边肯定是一个包(文件夹))
先产生一个执行文件的名称空间
1、创建包下面的__init__.py文件中的名称空间
2、执行包下面的__init__.py文件中的代码,将产生的名字放到包下面的__init___.py文件名称空间中
3、在执行文件中拿到一个指向包下面的__init__.py文件名称空间中的名字
包的设计者:
1、当模块的功能特别多的情况下,应该分文件夹管理
2、每个模块之间为了避免后期的模块名修改的问题,应该使用相对导入(包里面的文件都应该是被导入模块)
站在包的开发者:如果使用绝对路径来管理自己的模块的话,那么只要药永远以包的路径为准依次导入模块就行了
站在包的使用者:你必须得将包所在的那个文件夹路径添加到sys.path中
python2如果要导入包:包下面必须要有__init__.py文件
python3如果要导入包:包下面没有__init__.py文件也不会报错
当你在删除程序不必要文件的时候,千万不要随意删除__init__.py文件
logging模块:
五个等级:1、debug 2、info 3、warning 4、error 5、critical
logger对象:负责生产日志
filter对象:过滤日志(了解)
handler对象:控制日志输出的位置(文件/终端)
formatter对象:规定日志内容的格式
日志的一些配置参数:
import logging logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log',encoding='utf-8') # 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setLevel(logging.DEBUG) fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch) logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
配置字典:
import os
import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 定义日志输出格式 结束
"""
下面的两个变量对应的值 需要你手动修改
"""
logfile_dir = os.path.dirname(__file__) # log文件的目录
logfile_name = 'a3.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name)
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 默认都会使用该k:v配置
},
} # 使用日志字典配置
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger('日志文件名')
logger1.debug('要写入的内容')
hashlib模块:加密模块(这个加密的过程是无法解密的)
import hashlib md = hashlib.md5() # 生成一个造密文的对象
md.update('内容'.encode('utf-8')) # 往对象中传数据,update只接受bytes类型的数据 print(md.hexdigest()) # 获取明文数据对应的密文
对不hashlib内置的不同的算法,使用方法是相同的,只是密文的长度越长,内部对应的算法也越复杂。主要缺点有:1、时间消耗越长 2、占用的空间也就更大了 所以通常情况下使用md5就足够了
hashlib的应用场景:
1、密码的密文存储
2、校验文件的内容是否一致
hashlib中的加盐处理:
import hashlib md = hashlib.md5()
md.update('加盐的内容'.encode('utf-8')) # 要加盐的内容
md.update('真实的内容'.encode('utf-8')) # 要进行加密的内容
print(md.hexdigest())
openpyxl模块:比较火的操作excel表格的模块
03版本之前excel文件的后缀名是:xls
03版本之后excel文件的后缀名是:xlsx
xlwd:写excel
xlrt:读excel
写:
from openpyxl import Workbook
wb = Workbook()
wb1 = wb.create_sheet('index', 0) # 创建一个表单页, 后面可以通过数字控制位置
wb2 = wb.create_sheet('index')
wb1.title = 'login' # 后期可以通过表单也对象点title修改表单页的名称
wb1['A3'] = 666
wb1['A4'] = 444
wb1.cell(row=6,column=3,value=88888888)
wb1['A5'] = '=sum(A3:A4)'
# 保存新建的excel文件
wb.save('test.xlsx')
读:
# 读文件
from openpyxl import load_workbook wb = load_workbook('test.xlsx', read_only=True, data_only=True)
print(wb) # 可以通过wb对象来输出想要看的内容
深浅拷贝:
浅拷贝:
浅拷贝需要导入copy模块,并调用其中的copy方法。比如:b = copy.copy(a)
1、数字和字符串在内存中是同意块地址
2、无嵌套的列表和字典,如 a = [1, 2, 3]或a = {'user_name': 'william', 'password': 123},内存地址会改变
3、无嵌套的元组,如a = (1, 2, 3),在内存中是同一块地址
4、字典中嵌套列表,如:a= {'username':'zhangsan','password':123,'code':[1,2,3]},第一层的内存地址会改变,其它的内存地址不会发生变化(可以参考下图)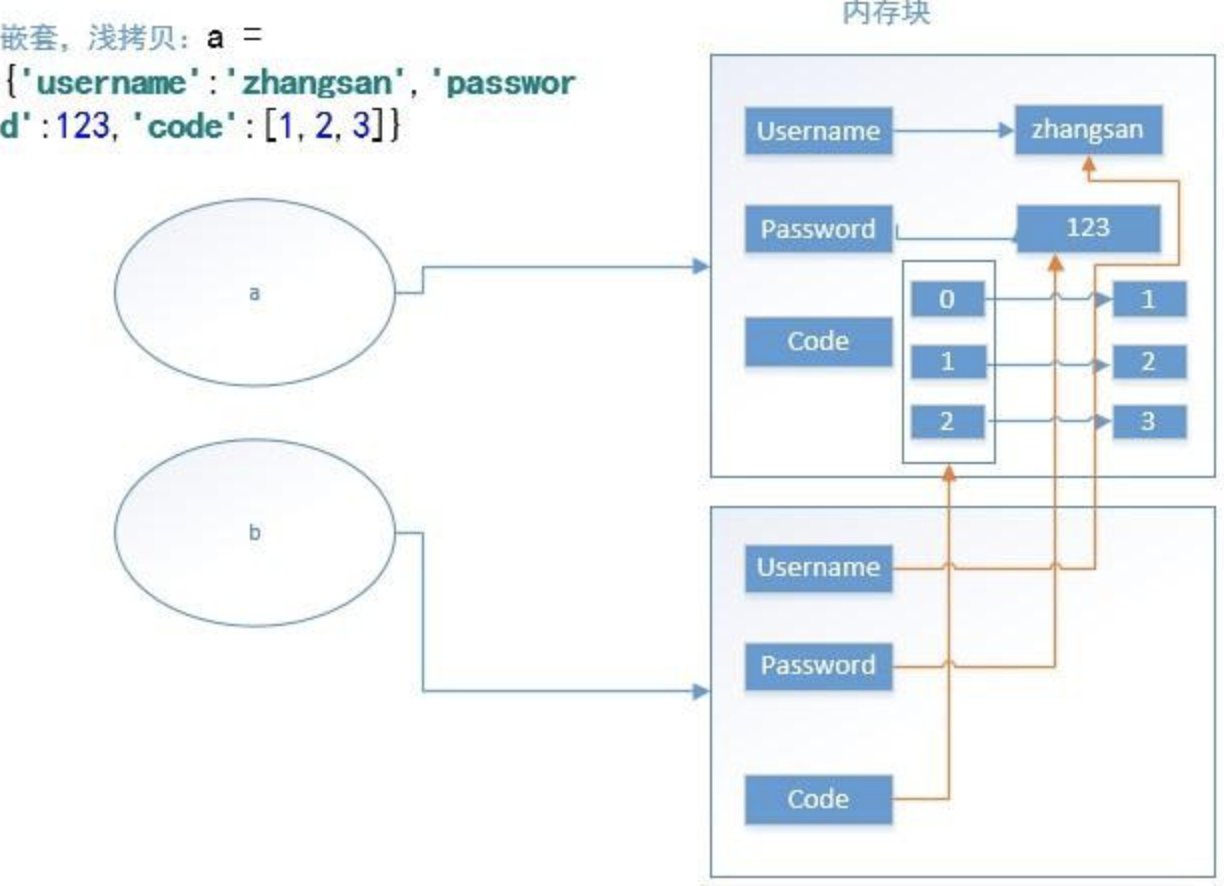
深拷贝:
深拷贝需要导入copy模块,并调用其deepcopy方法,比如:b = copy.deepcopy(a)
记住的点:一定会每曾重新开辟一块内存,但是最里边的最小元素,不会发生改变(如下图所示)
python基础--包、logging、hashlib、openpyxl、深浅拷贝的更多相关文章
- python基础知识5——赋值与深浅拷贝——整数和字符串,列表元组字典
深浅copy 一.数字和字符串 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. 1 import copy 2 # ######### 数字.字符串 #### ...
- python基础-3 集合 三元运算 深浅拷贝 函数 Python作用域
上节课总结 1 运算符 in 字符串 判断 : “hello” in "asdasfhelloasdfsadf" 列表元素判断:"li" in ['li', ...
- Python基础-包与模块
Python基础-包与模块 写在前面 如非特别说明,下文均基于Python3 摘要 为重用以及更好的维护代码,Python使用了模块与包:一个Python文件就是一个模块,包是组织模块的特殊目录(包含 ...
- python基础-包和模块
Python基础-包与模块 写在前面 如非特别说明,下文均基于Python3 摘要 为重用以及更好的维护代码,Python使用了模块与包:一个Python文件就是一个模块,包是组织模块的特殊目录(包含 ...
- day17_7.19包与logging模块,深浅拷贝
一.包 在模块的定义里,模块就是方法的集合,可以将一些常用的方法封装到一个py文件中,通过调用使用,而且,其中的表现形式也有以包的形式导入. 其实,包就是一系列模块的结合体,表示形式就是一个文件夹,在 ...
- Python学习基础(二)——集合 深浅拷贝 函数
集合 # 集合 ''' 集合是无序不重复的 ''' # 创建列表 l = list((1, 1, 1)) l1 = [1, 1, 1] print(l) print(l1) print("* ...
- 17.Python略有小成(包,logging模块)
Python(包,logging模块) 一.包 什么是包 官网解释 : 包是一种通过使用'.模块名'来组织python模块名称空间的方式 , 具体来讲 , 包就是一个包含有__ init __.py文 ...
- 基础数据 补充 set() 集合 深浅拷贝
一 对字符串的操作 li = ["张曼玉", "朱茵", "关之琳", "刘嘉玲"] s = "_" ...
- Core Python Programming一书中关于深浅拷贝的错误
该书关于深浅拷贝的论述: 6.20. *Copying Python Objects and Shallow and Deep Copies "when shallow copies are ...
随机推荐
- CF1163E Magical Permutation
题意:给定集合,求一个最大的x,使得存在一个0 ~ 2x - 1的排列,满足每相邻的两个数的异或值都在S中出现过.Si <= 2e5 解:若有a,b,c,令S1 = a ^ b, S2 = b ...
- csps模拟69chess,array,70木板,打扫卫生题解
题面:https://www.cnblogs.com/Juve/articles/11663898.html 69: 本以为T2傻逼题结果爆零了...T3原题虽然打的不是正解复杂度但是都不记得做过这道 ...
- WCF服务编程-基础
WCF是微软建立新一代的分布式应用及面向服务应用的标准平台,是基于原有.NET Framework 2.0的扩展.虽然在WCF发布不久就已经在项目中使用WCF技术了.但是由于在项目中还没有较大规模的应 ...
- [Ceoi2011]Traffic
#2387. [Ceoi2011]Traffic Online Judge:Bzoj-2387,Luogu-4700 Label:Yy,Tarjan缩点,dfs 题目描述 格丁尼亚的中心位于Kacza ...
- [转]Visual Studio 2010单元测试(3)--顺序单元测试
之前我们做的测试都是一个一个进行的,当然我们也可以一次性选择多个测试方法进行,但是测试运行的顺序以“测试列表编辑器”窗口中的默认列表顺序为准.在实际场景中,我们需要进行有顺序的单元测试,步骤可能每一步 ...
- PAT甲级——A1023 Have Fun with Numbers
Notice that the number 123456789 is a 9-digit number consisting exactly the numbers from 1 to 9, wit ...
- 《DSP using MATLAB》Problem 7.33
代码: %% ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ %% Output In ...
- HDFS的Web界面
- Python numpy.transpose 详解
前言 看Python代码时,碰见 numpy.transpose 用于高维数组时挺让人费解,通过一番画图分析和代码验证,发现 transpose 用法还是很简单的. 正文 Numpy 文档 numpy ...
- Leetcode459.Repeated Substring Pattern重复的子字符串
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成.给定的字符串只含有小写英文字母,并且长度不超过10000. 示例 1: 输入: "abab" 输出: True 解释 ...