Apache Flink 1.9.0版本新功能介绍
摘要:Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能。目前,Apache Flink 1.9.0版本已经正式发布,该版本有什么样的里程碑意义,又具有哪些重点改动和新功能呢?本文中,阿里巴巴高级技术专家伍翀就为大家带来了对于Apache Flink 1.9.0版本的介绍。
演讲嘉宾介绍:

本次分享主要分为以下三个方面:
- Flink 1.9.0的里程碑意义
- Flink 1.9.0的重点改动和新功能
- 总结
一、Flink 1.9.0的里程碑意义
下图展示的是在2019年中阿里技术微信公众号发表的两篇新闻,一篇为“阿里正式向Apache Flink贡献Blink代码”介绍的是在2019年1月Blink开源并且贡献给Apache Flink,另外一篇为“修改代码150万行!Apache Flink 1.9.0做了这些重大修改!”介绍的是2019年8月Bink合并入Flink之后首次发版。之所以将这两篇新闻放在一起,是因为无论是对于Blink还是Flink而言,Flink 1.9.0的发版都是具有里程碑意义的。

在2019年年初,Blink开源贡献给Apache Flink的时候,一个要点就是Blink会以Flink的一个分支来支持开源,Blink会将其主要的优化点都Merge到Flink里面,一起将Flink做的更好。如今,都已经过去了半年的时间,随着Flink1.9.0版本的发布,阿里巴巴的Blink团队可以骄傲地宣布自己已经兑现了之前的承诺。因此,当我们结合这两篇报道来看的时候,能够发现当初Blink的一些新功能如今已经能够在Flink1.9.0版本里面看到了,也能看出Flink社区的效率和执行力都是非常高的。
二、Flink 1.9.0的重点改动和新功能
这部分将为大家介绍Flink 1.9.0的重点改动和新功能。
架构升级
整体而言,如果一个软件系统产生了较大改动,那基本上就是架构升级带来的,对于Flink而言也不例外。想必熟悉Flink的同学对于下图中左侧的架构图一定不会陌生,在Flink的分布式流式执行引擎之上有一整套相对独立的DataStream API和DataSet API,它们分别负责流计算作业和批处理作业。在此基础之上Flink还提供了一个流批统一的Table API和SQL,用户可以使用相同的Table API或者SQL来描述流计算作业和批处理作业,只需要在运行时告诉Flink引擎以流模式运行还是以批模式运行即可,Table层将会把作业优化成为DataStream作业或者DataSet作业。但是Flink 1.8版本的架构在底层存在一些弊端,那就是DataStream和DataSet在底层共享的代码并不多。其次,两者的API也完全不同,因此就会导致上层重复开发的工作量比较大,长期来看就会使得Flink的开发和维护成本越来越大。
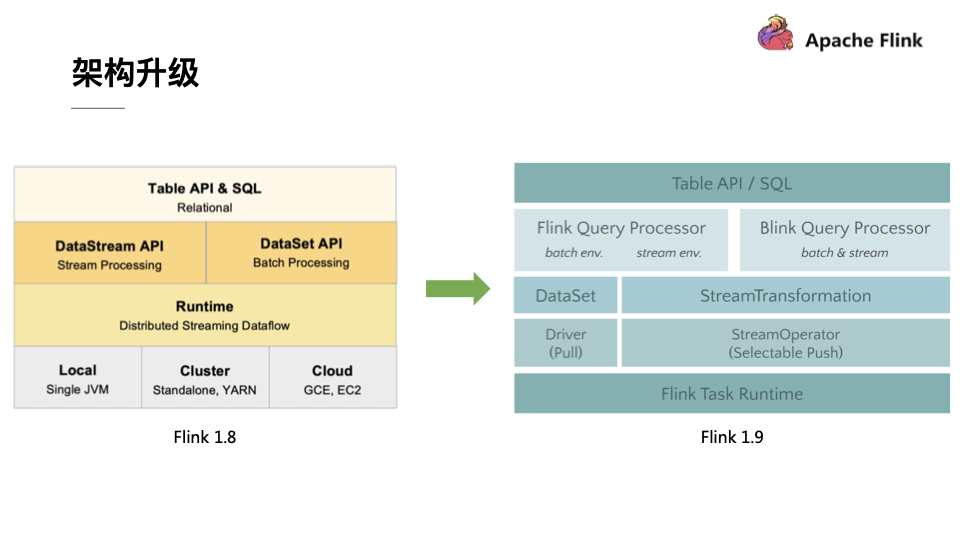
基于上述问题,Blink在架构上进行了一些新型的探索,经过和社区密切的讨论之后确定了Flink未来的架构路线。也就是在Flink未来的版本中,DataSet的API会被完全移除掉,SteamTransformation会作为底层的API来描述批作业和流作业,Table API和SQL会将流作业都翻译到SteamTransformation上,所以在Flink 1.9中为了不影响使用之前版本用户的体验,还需要一种能够让新旧架构并存的方案。基于这个目的,Flink的社区开发人员也做了一系列努力,提出了上图中右侧的Flink 1.9架构设计,将API和实现部分做了模块的拆分,并且提出了一个Planner接口,能够支持不同的Planner具体实现。Planner的具体工作就是优化和翻译成物理执行图等,也就是Flink Query Processor所做的工作。Flink将原本的实现全部移动到了Flink Query Processor中,将从Blink Merge过来的功能都放到了Blink Query Processor。这样就能够实现一举两得,不仅能够使得Table模块拆分之后变得更加清晰,更重要的是也不会影响老版本用户的体验,同时能够使得用户享受到Blink的新功能和优化。
Table API & SQL 重构和新功能
在Table API & SQL 重构和新功能部分,Flink在1.9.0版本中也Merge了大量从Blink中增加的SQL功能。这些新功能都是在阿里巴巴内部经过千锤百炼而沉淀出来的,相信能够使得Flink更上一层台阶。这里挑选了一些比较重要的成果为大家介绍,比如对于SQL DDL的支持,重构了类型系统,高效流式的TopN,高效流式去重,社区关注已久的维表关联,对于MinBatch以及多种解热点手段的支持,完整的批处理支持,Python Table API以及Hive的集成。接下来也会简单介绍下这些新功能。
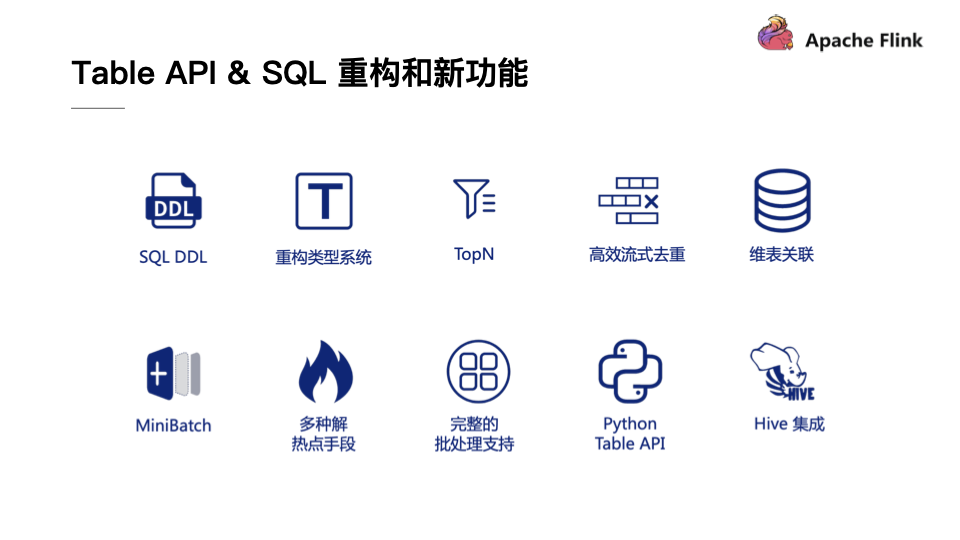
SQL DDL:在以前如果要注册一个Source或者Table Sink,必须要通过Java、Scala等代码或者配置文件进行注册,而在Flink 1.9版本中则支持了SQL DDL的语法直接去注册或者删除表。
重构类型系统:在Flink 1.9版本中实现了一套全新的数据类型系统,这套全新的类型系统与SQL标准进行了完全对齐,能够支持更加丰富的类型。这套全新的类型系统也为未来Flink SQL能够支持更加完备和完善的功能打下了坚实的基础。
TopN:在Flink 1.9版本提供强大的流处理能力以及社区期待已久的TopN来实时计算排行榜,能够实时计算排名靠前的店铺或者进行实时流数据的过滤。
高效流式去重:在现实的生产系统中,很多ETL作业或者任务没有做到端到端的一致性,这就导致明细层可能存在重复数据,这些数据交给汇总层做汇总时就会造成指标偏大,进而多计算了一些值,因此在进入汇总层之前往往都会做一个去重,这里引入了一个流计算中比较高效的去重功能,能够以比较低的代价来过滤重复的数据。
维表关联:能够实时地关联MySQL、HBase、Hive表中数据。
MinBatch&多种解热点手段:在性能优化方面,Flink 1.9版本也提供了一些性能优化的手段,比如提升吞吐的MinBatch的优化以及多种解热点手段。
完整的批处理支持:Flink 1.9版本具有完整的批处理支持,在下一个版本中也会继续投入力量来支持TBDS达到开箱即用的高性能。
Python Table API:在Flink 1.9版本中也引入了Python Table API,这也是Flink在多语言方向的有一个重大进步。能够使得Python用户能够轻松地玩转Flink SQL这样的功能。
Hive集成:Hive是Hadoop生态圈中不可忽视的重要力量,为了更好地去推广Flink批处理的功能,与Hive进行集成也是必不可少的。很高兴,在Flink 1.9版本的贡献者中也有两位Hive的PMC来推动集成工作。而首先需要解决的就是Flink如何读取Hive数据的问题,目前Flink已经完整打通了对于Hive MetaStore的访问,Flink可以直接去访问Hive MetaStore中的数据,同时反过来Flink也可以将其表数据中的元信息直接存储到Hive MetaStore里面供Hive访问,同时我们也增加了Hive的Connector支持CSV等格式,用户只需要配置Hive的MetaStore就能够在Flink直接读取。在此基础之上,Flink 1.9版本还增加了Hive自定义函数的兼容,Hive的自定义函数都能够在Flink SQL里面直接运行。
批处理改进:细粒度批作业恢复(FLIP-1)
Flink 1.9版本在批处理部分也做了较多的改进,首要的就是细粒度批作业的恢复。这个优化点在很早之前就被提出来了,而在1.9版本里终于将未完成的功能实现了收尾。在Flink 1.9版本中,如果批处理的作业有错误发生,Flink会首先计算这个错误影响的范围,这称为Fault Region,因为在批处理作业中有一些节点需要通过Pipeline的数据进行传输,而其他的节点可以通过Blocking的方式先把数据存储下来,下游再去读取存储下来的数据,如果算子的输出已经进行了完整的保存,那就没有必要将这个算子重新拉起来运行了,这样就使得错误恢复被控制在一个相对较小的范围里面。如果再极端一点,在每个数据Shuffle的地方都进行数据落盘,这就和MapReduce的Map行为比较类似了,不过Flink支持更加高级的用法,用户可以自行控制每个Shuffle的地方通过网络进行直连还是通过文件落盘的方式进行传输,这也是Flink的一个核心不同点。
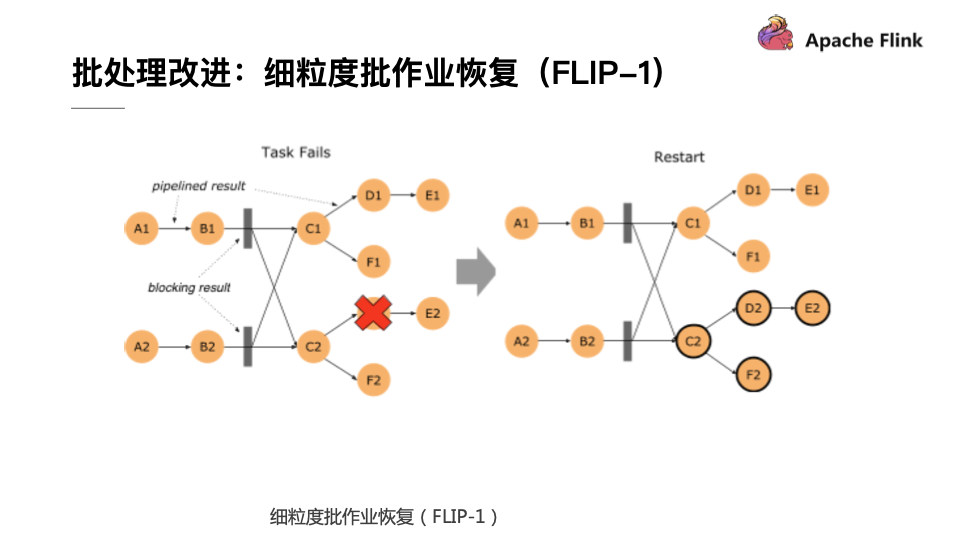
有了文件Shuffle之后,大家也会想是否能够将这个功能插件化,使其能够将文件Shuffle到其他地方,目前社区也在针对于这个方向做相应的努力,比如可以用Yarn做Shuffle的实现或者做一个分布式服务对于文件进行Shuffle。在阿里内部已经实现了这种架构,实现了单作业处理百TB级别的作业。当Flink具备这种插件化机制以后,就能够轻松地对接更加高效和灵活的Shuffle,让Shuffle这个批处理里面老大难的问题得到较好的解决。
流处理改进:State Processor API(FLIP-43)
流处理一直都是Flink的核心,所以在Flink 1.9版本里面也在流处理方面提出了很多改进,增加了一个非常实用的功能叫做Sate Processor API,其能够帮助用户直接访问Flink中存储的State,API能够帮助用户非常方便地读取、修改甚至重建整个State。这个功能的强大之处在于几个方面,第一个就是灵活地读取外部的数据,比如从一个数据库中读取自主地构建Savepoint,解决作业冷启动问题,这样就不用从N天前开始重跑整个数据。
此外,借助State Processor API,用户可以直接分析State中的数据,因为这部分数据在之前一直属于黑盒,这里面存储的数据是对是错,是否存在异常都用都无从得知,当有了State Processor API之后,用户就可以像分析普通数据一样来分析State数据,进而检测异常和分析故障。第三点就是对于脏数据的订正,比如有一条脏数据污染了State,就可以用State Processor API对于状态进行修复和订正。最后一点就是状态迁移,但用户修改了作业逻辑,还想要复用原来作业中大部分的State,或者想要升级这个State的结构就可以用这个API来完成相应的工作。在流处理面很多常见的工作和问题都可以通过Flink 1.9版本里面提供的State Processor API解决,因此也可以看出这个API的应用前景是非常广泛的。
重构的Web UI
除了上述功能的改进之外,Flink 1.9.0还提供了如下图所示的焕然一新的Web UI。这个最新的前端UI由专业Web前端工程师操刀,采用了最新的AngularJS进行重构。可以看出最新的Web UI非常的清新和现代化,也算是Apache开源软件里面自带UI的一股清流。
三、总结
经过紧锣密鼓的开发,Flink 1.9.0不仅迎来了众多的中国开发者,贡献了海量的代码,也带来了很多的用户。从下图可以看出,无论是从解决issue数量还是从代码commit数量上来看,Flink 1.9.0版本超过了之前两个版本的总和。从代码修改行数来看,Flink 1.9.0达到了150万行,是之前版本的代码修改行数的大约6倍,可以说Flink 1.9.0是Flink开源以来开发者最为活跃的一个版本。从Contributor数量上也可以看出,Flink也吸引了越来越多的贡献者,并且其中很多的贡献者都来自于中国。此外,根据Apache官方所发布的开源项目活跃指标来看,Flink的各项指标也都名列前茅。
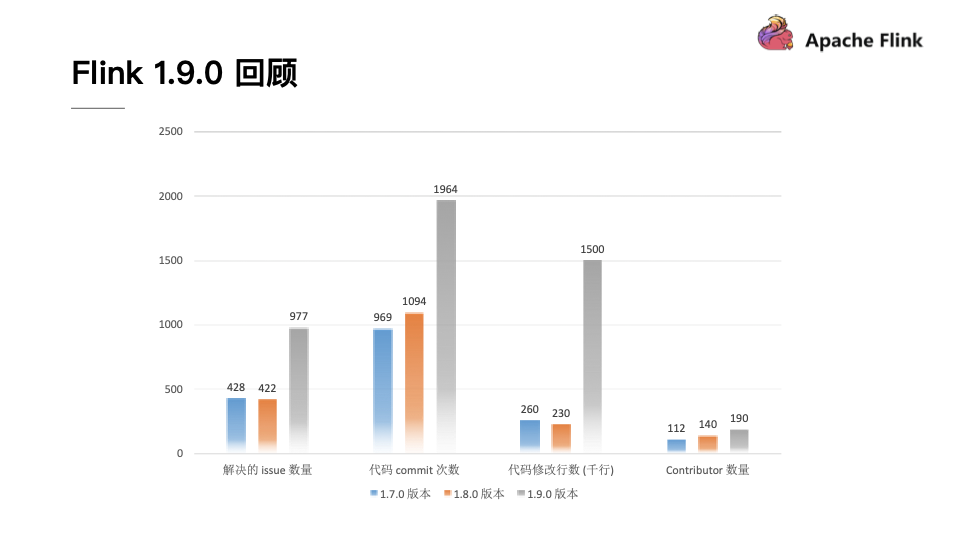
从这一切都能够看出,Flink 1.9.0是一个开始,在未来无论是Flink的功能还是生态都会变得越来越好。我们也由衷地希望更多的开发者能够加入Flink开发社区,一起将Flink做的越来越好。
今年11月底将会在北京召开全球最大的Apache Flink官方会议,届时将会有两千余名开发人员参加,希望大家可以关注。
此外,Apache Flink极客挑战赛正在举办中,感兴趣的同学可以关注。
本文作者:jark
本文为云栖社区原创内容,未经允许不得转载。
Apache Flink 1.9.0版本新功能介绍的更多相关文章
- CentOS以及Oracle数据库发展历史及各版本新功能介绍, 便于构造环境时有个对应关系
CentOS版本历史 版本 CentOS版本号有两个部分,一个主要版本和一个次要版本,主要和次要版本号分别对应于RHEL的主要版本与更新包,CentOS采取从RHEL的源代码包来构建.例如CentOS ...
- Eviews 8.0&9.0界面新功能介绍
Eviews 8.0&9.0界面新功能介绍 本文其中一些是自己的整理,也有一些是经管之家论坛中一位热心.好学坛友的整理,其中只是简单介绍一下这两个新版本的部分特性,分享出来,有兴趣的看客可以一 ...
- Kafka 0.11新功能介绍:空消费组延迟rebalance
Kafka 0.11新功能介绍:空消费组延迟rebalance 在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer inst ...
- Kafka 0.11版本新功能介绍 —— 空消费组延时rebalance
在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer instance启动的时间不可控,很有可能超出coordinator确定 ...
- geotrellis使用(二十)geotrellis1.0版本新功能及变化介绍
目录 前言 变化情况介绍 总结 一.前言 之前版本是0.9或者0.10.1.0.10.2,最近发现更新成为1.0.0-2077839.1.0应该也能称之为正式版了吧.发现其中有很多变化, ...
- [Android Pro] Android P版本 新功能介绍和兼容性处理(三)Android Studio 3.0 ~ 3.2 其他特性
cp : https://blog.csdn.net/yi_master/article/details/80067198 1:JAVA8特性支持 1)Base64.java 在升级到as3.0之后, ...
- hasura graphql-engine v1.0.0-alpha30 版本新功能介绍
hasura graphql-engine v1.0.0-alpha30 发布了,以下为一些变动的简单说明 破坏性的变动 order_by 中的desc 从 desc nulls last 修改为 d ...
- [Android P] Android P版本 新功能介绍和兼容性处理(一)
cp from :https://blog.csdn.net/yi_master/article/details/80046696 Android P版本已经到来,首篇我们当然要先看下Android ...
- 微信小程序0.11.122100版本新功能解析
微信小程序0.11.122100版本新功能解析 新版本就不再吐槽了,整的自己跟个愤青似的.人老了,喷不动了,把机会留给年轻人吧.下午随着新版本开放,微信居然破天荒的开放了开发者论坛.我很是担心官方 ...
随机推荐
- Hadoop国内主要发行版本
Hadoop主要版本 目前国内使用的不收费的Hadoop版本主要包括以下3个: Apache hadoop Cloudera的CDH Hortonworks版本(Hortonworks Data Pl ...
- [01]APUE:sysconf / pathconf
sysconf / pathconf:用于运行时确定特定系统实际支持的限制值 sysconf 函数的参数格式: “_SC_ + 限制项名称”,如:CHILD_MAX 限制值指每个实际用户 ID 可以启 ...
- 拾遗:{rpm、yum及源码方式管理软件包}
一.yum配置文件位置 /etc/yum.conf /etc/yum.repos.d/*.repo 二.yum常用命令 install pkgs reinstall pkgs update pkgs ...
- Spring Cloud Eureka 注册安全一定要做到位!
/eureka/ 参考配置如下: defaultZone: http://javastack:javastack@eureka1:8761/eureka/, http://javastack:java ...
- SpringMVC(day1搭建SpringWebMvc项目)
MVC和webMVC的区别 Model(模型) 数据模型,提供要展示的数据,因此包含数据和行为,行为是用来处理这些数据的.不过现在一般都分离开来:Value Object(数据) 和 服务层(行为). ...
- python初探爬虫
python爬虫初探 爬取前50名豆瓣电影: 废话少说,直接上代码! import reimport requestsfrom bs4 import BeautifulSoupdef get_co ...
- Codeforces 479【E】div3
题目链接:http://codeforces.com/problemset/problem/977/E 题意:就是给你相连边,让你求图内有几个环. 题解:我图论很差,一般都不太会做图论的题.QAQ看官 ...
- HTML_案例(首页制作)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- The linux command 之进程
******************查看进程********************* 一.使用ps命令 [me@linuxbox ~]$ ps PID TTY TIME CMD pts/ :: ba ...
- response.text与content的区别
在某些情况下来说,response.text 与 response.content 都是来获取response中的数据信息,效果看起来差不多.那么response.text 和 response.co ...