数据结构学习笔记_树(二叉搜索树,B-树,B+树,B*树)
一、查找二叉树(二叉搜索树BST)
1.查找二叉树的性质
1).所有非叶子结点至多拥有两个儿子(Left和Right);
2).所有结点存储一个关键字;
3).非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
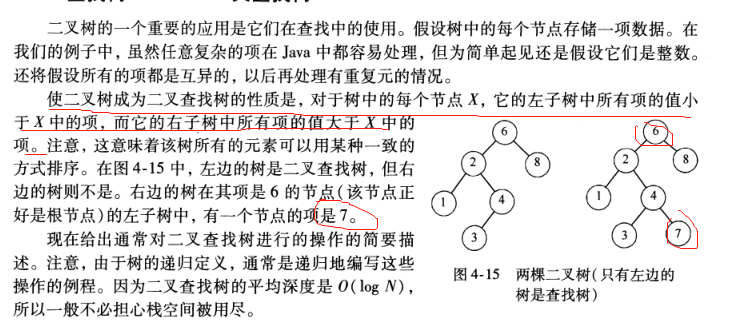
2.contains 方法
如果树T中含有节点X,那么返回true,如果节点不存在返回false(并且在左子树或右子树进行递归调用);
3.findMin和findMax方法
finMin是从根节点向左儿子进行,递归调用,终点就是最小的元素;
findMax是从根节点向右儿子进行,递归调用,终点就是最大的元素;
3.insert方法
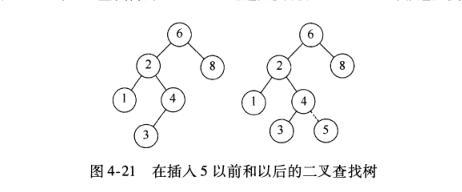
比如,要将5插入到上面的左树中,只需要找到4, 继续向右进行,但右边不存在子树,所5的插入位置就是在这里
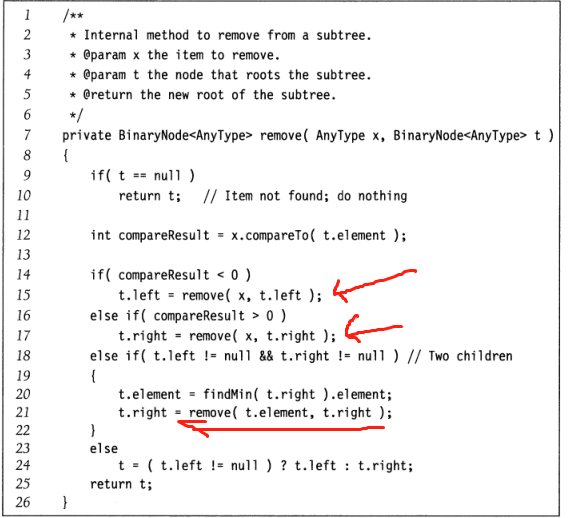
4.查找二叉树的remove(最困难)
1.节点是一篇树叶(没有儿子),立即被删除;
2.节点只有一个儿子,父节点绕过该儿子节点后被删除,例如下面左图;
3.节点有两个儿子,一般的删除策略是用里面找最小数来代替),并递归地删除那个节点(例如交换后的节点).因为右子树的最小节点不可能有左儿子;

删除程序如下:
5.平均深度
一个树的所有节点的深度和称为 内部路径长,

6. 优点和缺点
如果二叉搜索树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;
但它比连续内存空间的二分查找的优点是,改变二叉搜索树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
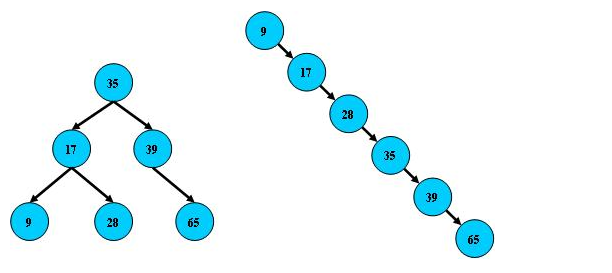
二叉搜索树在经过多次插入与删除后,有可能导致不同的结构:如下图
二、AVL树 (平衡二叉树)
带有平衡条件的查找二叉树. 一个AVL树,每个节点的左子树和右子树最多相差1(空树的节点为-1).
实际使用的二叉搜索树都是在原二叉搜索树的基础上加上平衡算法,即“平衡二叉树”;
如何保持B树 结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在二叉搜索树中插入和删除结点的策略;
常用算法有红黑树、AVL、Treap、伸展树等。在平衡二叉搜索树中,我们可以看到,其高度一般都良好地维持在O(log2n),大大降低了操作的时间复杂度.
调整平衡的基本思想:
当在二叉排序树中插入一个节点时,首先检查是否因插入而破坏了平衡,若破坏,则找出其中的最小不平衡二叉树,在保持二叉排序树特性的情况下,调整最小不平衡子树中节点之间的关系,以达到新的平衡。
所谓最小不平衡子树,指离插入节点最近且以平衡因子的绝对值大于1的节点作为根的子树。
先插入指定节点,记录下当前节点的信息,LH,EH或者RH。
1. 若左子树高LH,查看其左子树根节点的信息,若是LH,则一次右旋;若是RH,则一次左旋+一次右旋
2. 若右子树高RH,查看右子树根节点的信息,若是RH,则一次左旋;若是LH,则一次右旋+一次左旋
3. 调整改变的节点信息
追求绝对的高度平衡,随着树的高度的增加,动态插入和删除的代价也随之增加
三、 B树( B-树)
B-tree树即B树,B即Balanced,平衡的意思。因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,其实,这是个非常不好的直译,很容易让人产生误解。
如人们可能会以为B-树是一种树,而B树又是另一种树。而事实上是,B-tree就是指的B树。特此说明。
B树是一种自平衡的树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。
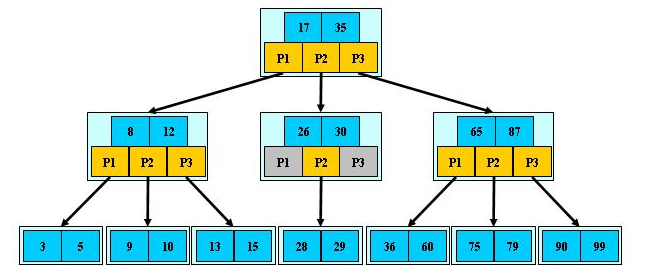
1. B树是一种多路搜索树(并不是二叉的,下面是M阶的B树):
1).定义任意非叶子结点最多只有M个儿子;且M>2;
2).根结点的儿子数为[2, M];
3).除根结点以外的非叶子结点的儿子数为[M/2, M];
4).每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5).非叶子结点的关键字个数=指向儿子的指针个数-1;(这里关键字用数字表示,指针用P表示)
6).非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];(即关键字按照某个形式排序)
7).非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
(如根节点P1指向的左边子树,都是小于K[1]=17的~)
8).所有叶子结点位于同一层; 如:(M=3)
2.B-树的搜索
从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
3.B-树的特性
1).关键字集合分布在整颗树中;
2).任何一个关键字出现且只出现在一个结点中;
3).搜索有可能在非叶子结点结束;
4).其搜索性能等价于在关键字全集内做一次二分查找;
5).自动层次控制;
4.搜索性能
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
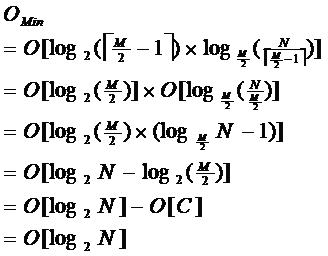
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
四、 B+树
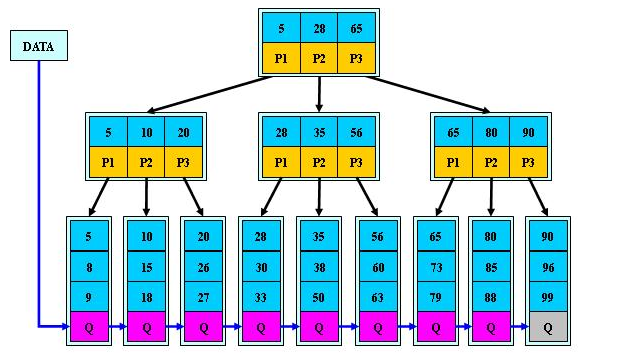
1.B+树是B-树的变体,也是一种多路搜索树:
1).其定义基本与B-树同,除了:
2).非叶子结点的子树指针与关键字个数相同;
3).非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间,B+是左开右闭);
5).为所有叶子结点增加一个链指针;
6).所有关键字都在叶子结点出现;如:(M=3)
2.B+的搜索和查询
与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
- B+树的头指针有两个,一个指向根节点,另一个指向关键字最小的元素,因此B+树有两种遍历的方式:
- 1.从根节点开始随机查询
- 2.从最小关键词顺序查询
3. B+的特性
1).所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2).不可能在非叶子结点命中;
3).非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4).更适合文件索引系统;
NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。
B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。
B+ 树元素自底向上插入。
4.B+的插入
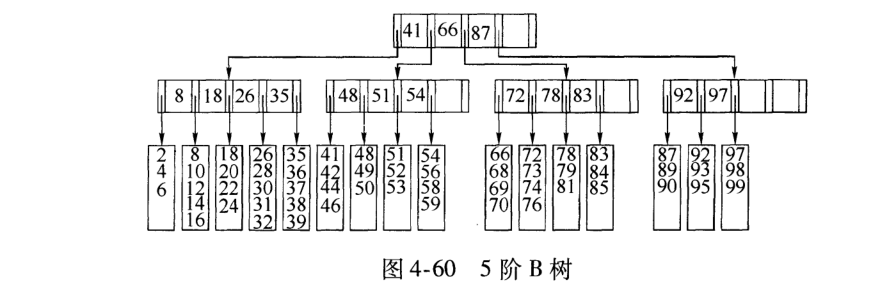
1) 将上图4-60的5阶B树插入. 观察一下,54指向的叶子只有4个数据未满状态,可以直接添加. (叶未满插入)
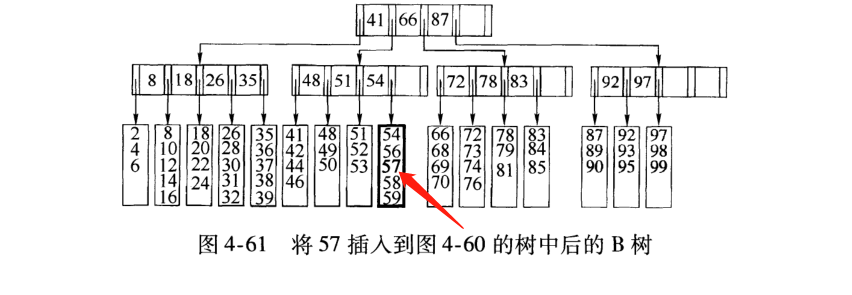
2) 继续插入 ,(叶满插入)
上面的叶子可以看到已满5个,不能继续插入,解决方法是重新分裂一个父节点,然后平分掉54指向的5个叶子+1个新插入的数据55.
这里的IO操作,至少有原叶子的数据更新,新叶子的数据更新和新增父节点57的更新.
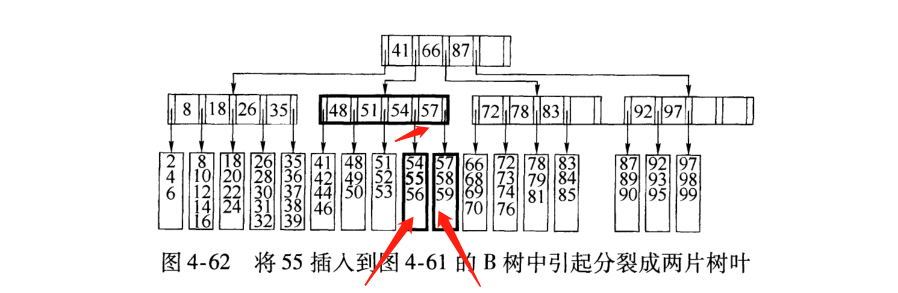
3)继续插入 (叶满父满插入)
上面的图中,35指向的叶子5个,不能分裂父节点(已满),这里采取的方法是继续上一层分列节点.
如果分裂到了树根,那么不能再将root分裂成两个root,可以新建一个树根,作为root的两个儿子,这是B树增加高度的唯一方式.
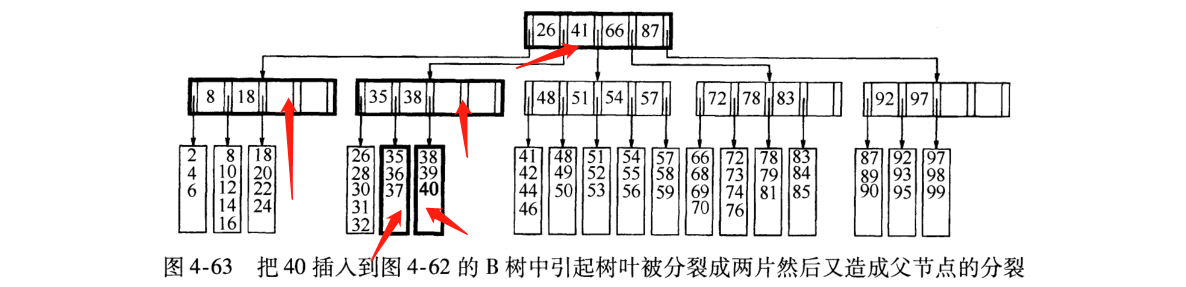
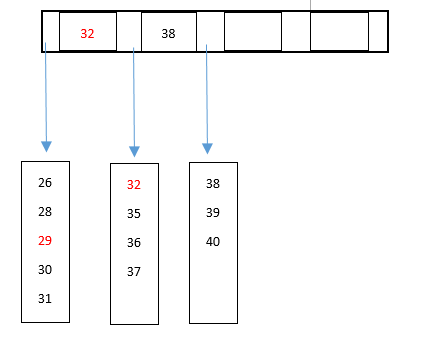
4) 继续插入29 (邻居领养过多儿子)
如果放入35左侧的叶子,会达到6个,那么可以分配一个数据到右边的叶子领养(右边三个数据)
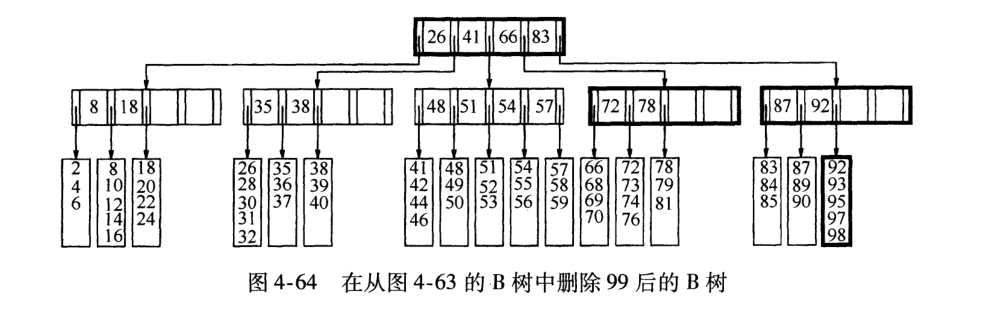
5) 删除99 (领养父亲)
如果把99删除, 那么92指向的叶子跟97,98合并成一个叶子, 导致父节点儿子低于最小值.(97父节点干掉了)
解决方法是: 从邻居父节点领养一个,72 -78-83-92 平均成两个父节点,当然这会调整更上层的父节点~
五、 B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
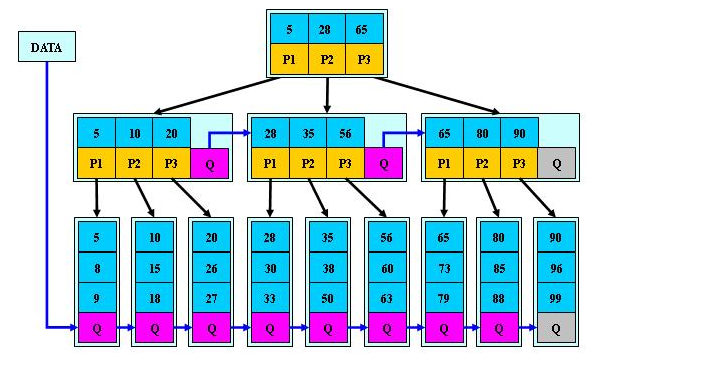
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
六、 总结
二叉搜索树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B(B-)树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
七、 问题
1.为什么说B+树比B 树更适合实际应用中操作系统的文件索引和数据库索引?
B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
数据结构学习笔记_树(二叉搜索树,B-树,B+树,B*树)的更多相关文章
- 树-二叉搜索树-AVL树
树-二叉搜索树-AVL树 树 树的基本概念 节点的度:节点的儿子数 树的度:Max{节点的度} 节点的高度:节点到各叶节点的最大路径长度 树的高度:根节点的高度 节点的深度(层数):根节点到该节点的路 ...
- 把二叉搜索树转化成更大的树 · Convert BST to Greater Tree
[抄题]: 给定二叉搜索树(BST),将其转换为更大的树,使原始BST上每个节点的值都更改为在原始树中大于等于该节点值的节点值之和(包括该节点). Given a binary search Tree ...
- 算法进阶面试题04——平衡二叉搜索树、AVL/红黑/SB树、删除和调整平衡的方法、输出大楼轮廓、累加和等于num的最长数组、滴滴Xor
接着第三课的内容和讲了第四课的部分内容 1.介绍二叉搜索树 在二叉树上,何为一个节点的后继节点? 何为搜索二叉树? 如何实现搜索二叉树的查找?插入?删除? 二叉树的概念上衍生出的. 任何一个节点,左比 ...
- LIntcode---将二叉搜索树转成较大的树
Given a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original B ...
- [LC]235题 二叉搜索树的最近公共祖先 (树)(递归)
①题目 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先. 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p.q,最近公共祖先表示为一个结点 x,满足 x 是 p.q 的祖先 ...
- Java实现 LeetCode 530 二叉搜索树的最小绝对差(遍历树)
530. 二叉搜索树的最小绝对差 给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值. 示例: 输入: 1 \ 3 / 2 输出: 1 解释: 最小绝对差为 1,其中 2 ...
- 动态平衡二叉搜索树的简易实现,Treap 树
http://blog.csdn.net/qichi_bj/article/details/8232048
- AOJ/树二叉搜索树习题集
ALDS1_7_A-RootedTree. Description: A graph G = (V, E) is a data structure where V is a finite set of ...
- 【算法学习】AVL平衡二叉搜索树原理及各项操作编程实现(C语言)
#include<stdio.h> #include "fatal.h" struct AvlNode; typedef struct AvlNode *Positio ...
随机推荐
- day 91 Django学习之django自带的contentType表
Django学习之django自带的contentType表 通过django的contentType表来搞定一个表里面有多个外键的简单处理: 摘自:https://blog.csdn.net ...
- Android 7.0 IMS框架详解
本文主要讲解IP Multimedia Subsystem (IMS)在Android 7.0上由谷歌Android实现的部分内容.从APP侧一直到Telephony Framework,是不区分CS ...
- Mybatis 使用的 9 种设计模式,真是太有用了~
Java技术栈 ) { name = fullname.substring(0, delim); children = fullname.substring(delim + 1); ...
- C4D中python初探
use_name = input('请输入账号') password = input('请输入密码') if use_name == 'alex' and password == 'alex3714' ...
- xwiki系统 知识库 xwiki
1.下载tomcat tar -zxvf apache-tomcat-8.0.14.tar.gz mv apache-tomcat-8.0.14 tomcat-xwiki-8.0 2.下载xwik ...
- Linux 系统版本查询命令
.# uname -a (Linux查看版本当前操作系统内核信息) .# cat /proc/version (Linux查看当前操作系统版本信息) .# cat /etc/issue 或 cat / ...
- 【学术篇】SDOI2010 古代猪文
这里可能包含传送门 又双叒叕数论大杂烩... 定理什么我都不会证 题目很长很啰嗦 但是题意很显然... 化完式子之后就是这么个东东:\(G^{\sum_{k|n}C_k^{\frac{n}{k}}}\ ...
- MongoDB使用固定集合
MongoDB中的固定集合:大小是固定的,类似于循环队列,如果没有空间了,最老的文档会被删除以释放空间,新插入的会占据这块空间. 1.固定集合(oplog) oplog是一个典型的固定集合,因为其大小 ...
- Java怎样判断身份证号
判断身份证号是否正确使用的是正则,Java与js中使用正则的方式大差不差,下面是Java通过正则判断身份证号是否正确的 * */ @Test public void cardId() { System ...
- Sublime Text最舒服的主题
Theme - Afterglow (官网链接) 贴上 preferences -> settings 里面的配置 { "theme": "Afterglow-gr ...