01hive基础操作
一. Hive基础概念
我自己本人一开始学习Hive的时候,最大的疑问就是hive和hbase到底有什么区别?(因为自己本身学校课程设置问题有了解到一丢丢hbase的知识)
所以先甩一篇博客提供给跟我一样有疑问的同学。https://blog.csdn.net/vipyeshuai/article/details/50847281
1.什么是Hive
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
本质是:将 HQL 转化成 MapReduce 程序。
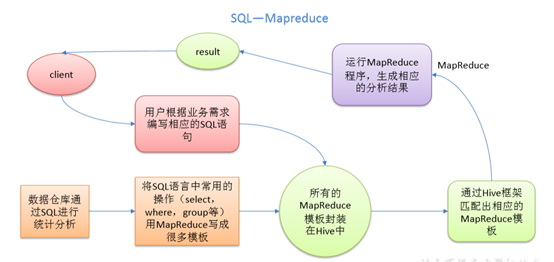
1)Hive 处理的数据存储在 HDFS
2)Hive 分析数据底层的默认实现是 MapReduce
3)执行程序运行在 Yarn 上
2.优缺点
2.1 优点
1) 操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
2) 避免了去写 MapReduce,减少开发人员的学习成本。
3) Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
4) Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
5) Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
2.2 缺点
1.Hive 的 HQL 表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗
3. 架构原理

1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java 访问 hive)、WEBUI(浏览器访问 hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3.Hadoop 使用 HDFS 进行存储,使用 MapReduce 进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
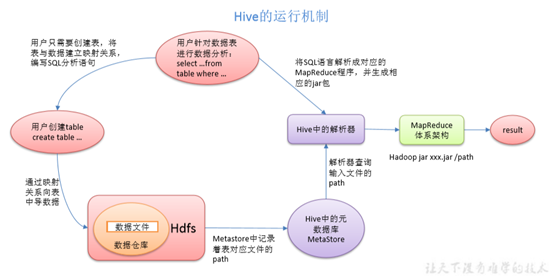
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,
结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
4.Hive 和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本节将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
4.1 查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
4.2 数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
4.3 数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需 要 经 常 进 行 修 改 的 , 因 此 可 以 使 用 INSERT INTO … VALUES 添 加 数 据 , 使用 UPDATE … SET 修改数据。
4.4 索引
Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
4.5 执行
Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
4.6 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
4.7 可扩展性
由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009 年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
4.8 数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
二. Hive从本地加载数据
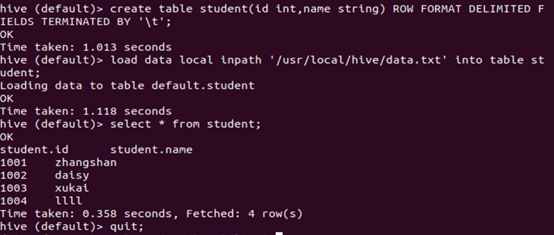
先新建一个data.txt文件

进入hive输入对应的命令
三. Hive JDBC访问

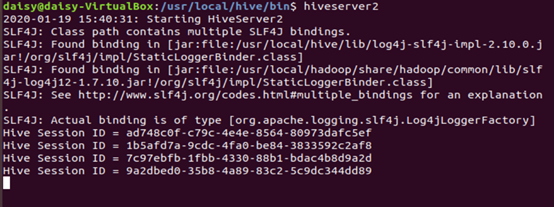
1.先打开hiveserver2

2.重新开一个终端
3.进入hadoop的配置文件core-site.xml
添加以下内容
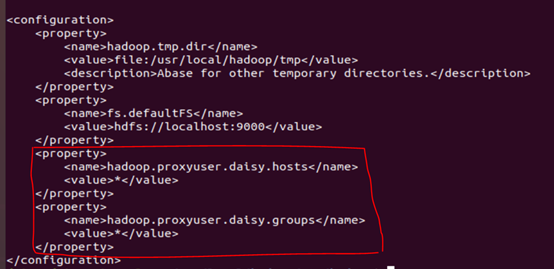
4.确认hiveserver2已开启

5.开启beeline
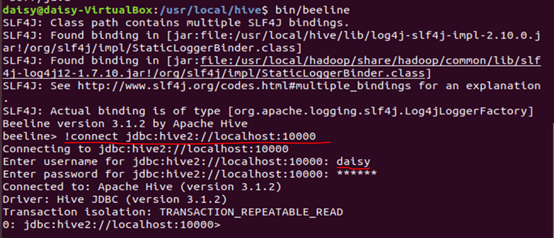
username对应core-site.xml里边设置的用户
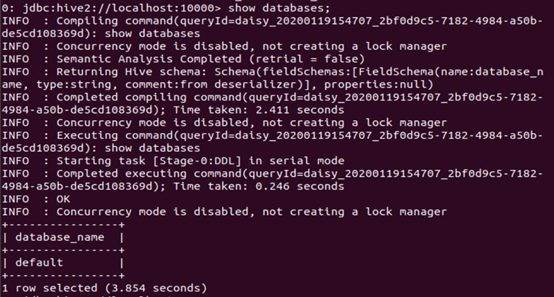
输入show databases;成功显示!
四. hive常用交互命令
1.“-e”不进入 hive 的交互窗口执行 sql 语句
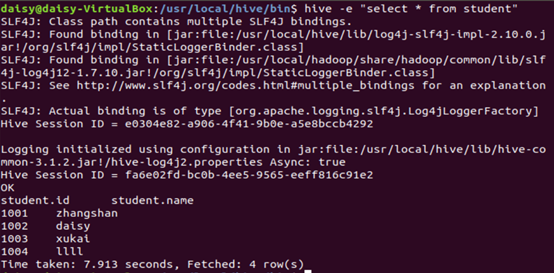
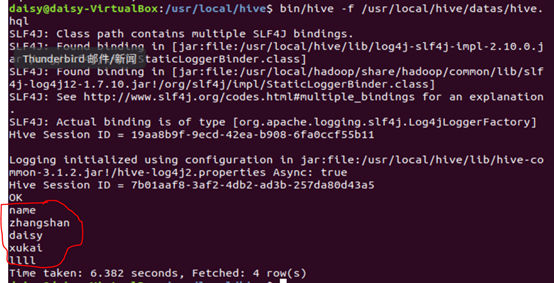
2.“-f”执行脚本中 sql 语句
1)创建hive.hql文件,其中内容为要操作的sql语句

2)bin/hive -f /usr/local/hive/datas/hive.hql
五. Hive 其他命令操作
1.在 hive cli 命令窗口中查看 hdfs 文件系统
hive> dfs -ls /;
2.在 hive cli 命令窗口中如何查看本地文件系统
hive> ! ls /usr/local/hive/datas;
3.查看在 hive 中输入的所有历史命令
(1)进入到当前用户的根目录/root 或/home/atguigu
(2)查看. hivehistory 文件 cat .hivehistory
六. Hive 运行日志信息配置
1.Hive 的 log 默认存放在/tmp/daisy/hive.log 目录下(当前用户名下)
2.修改 hive 的 log 存放日志到/opt/module/hive/logs
(1)复制conf下边的hive-log4j.properties.template 文件为hive-log4j.properties

(2)在 hive-log4j.properties 文件中修改 log 存放位置
hive.log.dir=/usr/local/hive/logs
重启之后可发现目录下已有logs文件夹

七. 参数配置方式
1.查看当前所有的配置信息
hive>set;
2.参数的配置三种方式
(1)配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因
为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件
的设定对本机启动的所有 Hive 进程都有效。
(2)命令行参数方式
启动 Hive 时,可以在命令行添加-hiveconf param=value 来设定参数。
例如: $ bin/hive -hiveconf mapred.reduce.tasks=10;
注意:仅对本次 hive 启动有效
查看参数设置: hive (default)> set mapred.reduce.tasks;
(3)参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
例如: hive (default)> set mapred.reduce.tasks=100;
注意:仅对本次 hive 启动有效。
查看参数设置 hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。
即配置文件<命令行参数<参数声明。
注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
01hive基础操作的更多相关文章
- python基础操作以及hdfs操作
目录 前言 基础操作 hdfs操作 总结 一.前言 作为一个全栈工程师,必须要熟练掌握各种语言...HelloWorld.最近就被"逼着"走向了python开发之路, ...
- MYSQL基础操作
MYSQL基础操作 [TOC] 1.基本定义 1.1.关系型数据库系统 关系型数据库系统是建立在关系模型上的数据库系统 什么是关系模型呢? 1.数据结构可以规定,同类数据结构一致,就是一个二维的表格 ...
- 【Learning Python】【第二章】Python基础类型和基础操作
基础类型: 整型: py 3.0解决了整数溢出的问题,意味着整型不必考虑32位,64位,有无符号等问题,你写一个1亿亿亿,就是1亿亿亿,不会溢出 a = 10 ** 240 print(a) 执行以上 ...
- Emacs学习心得之 基础操作
作者:枫雪庭 出处:http://www.cnblogs.com/FengXueTing-px/ 欢迎转载 Emacs学习心得之 基础操作 1.前言与学习计划2.Emacs基础操作 一. 前言与学习计 ...
- Git基础操作
配置秘钥 1.检查本机有没有秘钥 检查~/.ssh看看是否有名为d_rsa.pub和id_dsa.pub的2个文件. $ ~/.sshbash: /c/Users/lenovo/.ssh: Is a ...
- activiti基础操作
package activitiTest; import java.io.InputStream; import java.util.List; import java.util.zip.ZipInp ...
- 《Genesis-3D开源游戏引擎-官方录制系列视频教程:基础操作篇》
注:本系列教程仅针对引擎编辑器:v1.2.2及以下版本 G3D基础操作 第一课<G3D编辑器初探> G3D编辑器介绍,依托于一个复杂场景,讲解了场景视图及其基本操作,属性面板和工具栏的 ...
- MYSQL 基础操作
1.MySQL基础操作 一:MySQL基础操作 1:MySQL表复制 复制表结构 + 复制表数据 create table t3 like t1; --创建一个和t1一样的表,用like(表结构也一样 ...
- php之文件基础操作
在php中对文件的基础操作非常的简单,php提供的函数粗略的用了一遍. file_get_contents():可以获取文件的内容获取一个网络资源的内容,这是php给我封装的一个比较快捷的读取文件的内 ...
随机推荐
- html5 流式布局 弹式布局 flex
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8& ...
- vue -bug1
打包问题: 1.在终端用 npm run build 如果想要在本地资源也能访问 2.npm install -g http-server 3.配置好如下 3.1 config->index. ...
- 训练20191009 2018-2019 ACM-ICPC, Asia East Continent Finals
2018-2019 ACM-ICPC, Asia East Continent Finals 总体情况 本次训练共3小时20分钟,通过题数4. 解题报告 D. Deja vu of - Go Play ...
- [一本通学习笔记] RMQ专题
傻傻地敲了好多遍ST表. 10119. 「一本通 4.2 例 1」数列区间最大值 #include <bits/stdc++.h> using namespace std; const i ...
- 计算a除b的第一位小数 in C++.
my codes: #include<iostream> #include<cstdio> using namespace std; int main() { int a,b; ...
- python os 模块详解
os.sep:取代操作系统特定的路径分隔符 os.name:指示你正在使用的工作平台.比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'. os.getcwd:得 ...
- 期货homes平台以及仿ctp接口
实盘账户或者模拟账户可以下挂多个子账户 子账户也可以是homes母账户,理论上可以一层一层套下去. 所有交易细节全部保存,收盘定时结算. 功能很强大,并且还有很多拓展空间. 连接homes平台,需要用 ...
- java基础(三)之面向对象编程
对象的创建方法 语法: class 类名{ 属性; 方法; } 生成对象的方法 类名 对象名 = new 类名(); Dog dog = new Dog(); 对象的使用方法1.对象.变量;2.对象. ...
- python3.0练习100题——001
自学python3中,现在开始每天在python2.71 100例中做一道题,用python3实现,并写下一些思考-加油(ง •̀灬•́)ง 题目网站(http://www.runoob.com/py ...
- Leetcode 面试题 01.01. 判定字符是否唯一
实现一个算法,确定一个字符串 s 的所有字符是否全都不同. 示例 1: 输入: s = "leetcode"输出: false 示例 2: 输入: s = "abc&qu ...