Storm 系列(九)—— Storm 集成 Kafka
一、整合说明
Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下:
- Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持;
- Storm Kafka Integration (0.10.x+) : 包含 Kafka 新版本的 consumer API,主要对 Kafka 0.10.x + 提供整合支持。
这里我服务端安装的 Kafka 版本为 2.2.0(Released Mar 22, 2019) ,按照官方 0.10.x+ 的整合文档进行整合,不适用于 0.8.x 版本的 Kafka。
二、写入数据到Kafka
2.1 项目结构
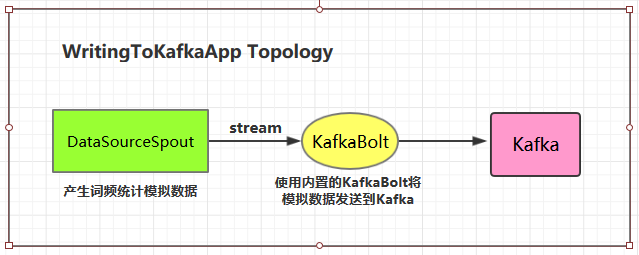
2.2 项目主要依赖
<properties>
<storm.version>1.2.2</storm.version>
<kafka.version>2.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
</dependencies>2.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm2.4 WritingToKafkaApp
/**
* 写入数据到 Kafka 中
*/
public class WritingToKafkaApp {
private static final String BOOTSTRAP_SERVERS = "hadoop001:9092";
private static final String TOPIC_NAME = "storm-topic";
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
// 定义 Kafka 生产者属性
Properties props = new Properties();
/*
* 指定 broker 的地址清单,清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找其他 broker 的信息。
* 不过建议至少要提供两个 broker 的信息作为容错。
*/
props.put("bootstrap.servers", BOOTSTRAP_SERVERS);
/*
* acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。
* acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
* acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
* acks=all : 只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
*/
props.put("acks", "1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaBolt bolt = new KafkaBolt<String, String>()
.withProducerProperties(props)
.withTopicSelector(new DefaultTopicSelector(TOPIC_NAME))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper<>());
builder.setSpout("sourceSpout", new DataSourceSpout(), 1);
builder.setBolt("kafkaBolt", bolt, 1).shuffleGrouping("sourceSpout");
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterWritingToKafkaApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWritingToKafkaApp",
new Config(), builder.createTopology());
}
}
}2.5 测试准备工作
进行测试前需要启动 Kakfa:
1. 启动Kakfa
Kafka 的运行依赖于 zookeeper,需要预先启动,可以启动 Kafka 内置的 zookeeper,也可以启动自己安装的:
# zookeeper启动命令
bin/zkServer.sh start
# 内置zookeeper启动命令
bin/zookeeper-server-start.sh config/zookeeper.properties启动单节点 kafka 用于测试:
# bin/kafka-server-start.sh config/server.properties2. 创建topic
# 创建用于测试主题
bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 --replication-factor 1 --partitions 1 --topic storm-topic
# 查看所有主题
bin/kafka-topics.sh --list --bootstrap-server hadoop001:90923. 启动消费者
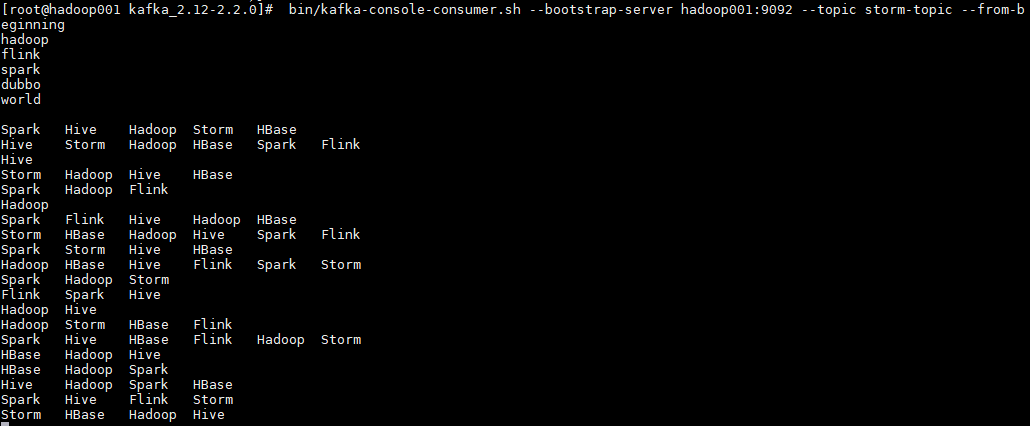
启动一个消费者用于观察写入情况,启动命令如下:
# bin/kafka-console-consumer.sh --bootstrap-server hadoop001:9092 --topic storm-topic --from-beginning2.6 测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true启动后,消费者监听情况如下:
三、从Kafka中读取数据
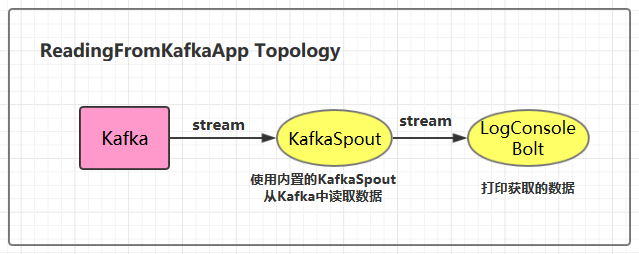
3.1 项目结构
3.2 ReadingFromKafkaApp
/**
* 从 Kafka 中读取数据
*/
public class ReadingFromKafkaApp {
private static final String BOOTSTRAP_SERVERS = "hadoop001:9092";
private static final String TOPIC_NAME = "storm-topic";
public static void main(String[] args) {
final TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka_spout", new KafkaSpout<>(getKafkaSpoutConfig(BOOTSTRAP_SERVERS, TOPIC_NAME)), 1);
builder.setBolt("bolt", new LogConsoleBolt()).shuffleGrouping("kafka_spout");
// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterReadingFromKafkaApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalReadingFromKafkaApp",
new Config(), builder.createTopology());
}
}
private static KafkaSpoutConfig<String, String> getKafkaSpoutConfig(String bootstrapServers, String topic) {
return KafkaSpoutConfig.builder(bootstrapServers, topic)
// 除了分组 ID,以下配置都是可选的。分组 ID 必须指定,否则会抛出 InvalidGroupIdException 异常
.setProp(ConsumerConfig.GROUP_ID_CONFIG, "kafkaSpoutTestGroup")
// 定义重试策略
.setRetry(getRetryService())
// 定时提交偏移量的时间间隔,默认是 15s
.setOffsetCommitPeriodMs(10_000)
.build();
}
// 定义重试策略
private static KafkaSpoutRetryService getRetryService() {
return new KafkaSpoutRetryExponentialBackoff(TimeInterval.microSeconds(500),
TimeInterval.milliSeconds(2), Integer.MAX_VALUE, TimeInterval.seconds(10));
}
}
3.3 LogConsoleBolt
/**
* 打印从 Kafka 中获取的数据
*/
public class LogConsoleBolt extends BaseRichBolt {
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(Tuple input) {
try {
String value = input.getStringByField("value");
System.out.println("received from kafka : "+ value);
// 必须 ack,否则会重复消费 kafka 中的消息
collector.ack(input);
}catch (Exception e){
e.printStackTrace();
collector.fail(input);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}这里从 value 字段中获取 kafka 输出的值数据。
在开发中,我们可以通过继承 RecordTranslator 接口定义了 Kafka 中 Record 与输出流之间的映射关系,可以在构建 KafkaSpoutConfig 的时候通过构造器或者 setRecordTranslator() 方法传入,并最后传递给具体的 KafkaSpout。
默认情况下使用内置的 DefaultRecordTranslator,其源码如下,FIELDS 中 定义了 tuple 中所有可用的字段:主题,分区,偏移量,消息键,值。
public class DefaultRecordTranslator<K, V> implements RecordTranslator<K, V> {
private static final long serialVersionUID = -5782462870112305750L;
public static final Fields FIELDS = new Fields("topic", "partition", "offset", "key", "value");
@Override
public List<Object> apply(ConsumerRecord<K, V> record) {
return new Values(record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value());
}
@Override
public Fields getFieldsFor(String stream) {
return FIELDS;
}
@Override
public List<String> streams() {
return DEFAULT_STREAM;
}
}3.4 启动测试
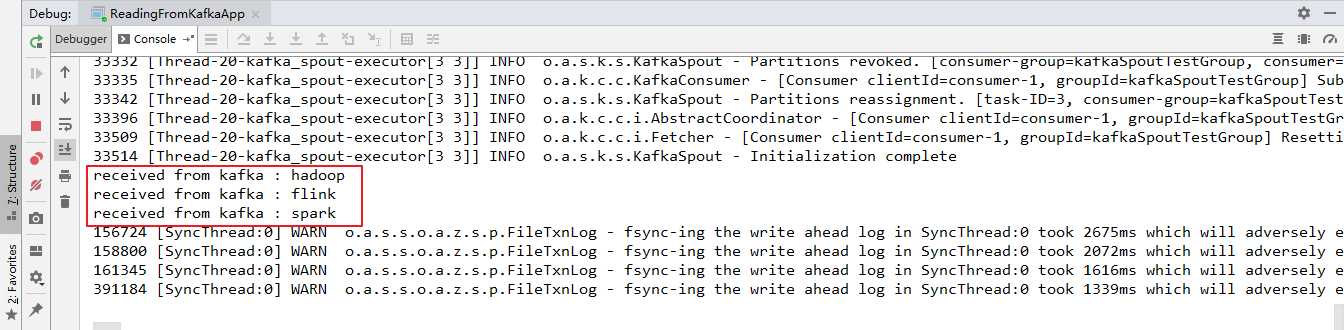
这里启动一个生产者用于发送测试数据,启动命令如下:
# bin/kafka-console-producer.sh --broker-list hadoop001:9092 --topic storm-topic
本地运行的项目接收到从 Kafka 发送过来的数据:
用例源码下载地址:storm-kafka-integration
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(九)—— Storm 集成 Kafka的更多相关文章
- Storm系列一: Storm初步
初入Storm 前言 学习Storm已经有两周左右的时间,但是认真来说学习过程确实是零零散散,遇到问题去百度一下,找到新概念再次学习,在这样的一个循环又不成体系的过程中不断学习Storm. 前人栽树, ...
- Storm系列(九)架构分析之Supervisor-同步Nimbus的事件线程
Supervisor由三个线程组成,一个计时器线程和两个事件线程. 计时器线程负责维持心跳已经更新Zookeeper中的状态,还负责每隔一定的时间将事件线程需要执行的事件添加到其对应的队列中. 两个事 ...
- Storm系列之一——Storm Topology并发
1.是什么构成一个可运行的topology? worker processes(worker进程),executors(线程)和tasks. 一台Storm集群里面的机器可能运行一个或多个worker ...
- MP实战系列(九)之集成Shiro
下面示例是在之前的基础上进行的,大家如果有什么不明白的可以参考MP实战系列的前八章 当然,同时也可以参考MyBatis Plus官方教程 建议如果参考如下教程,使用的技术为spring+mybatis ...
- Spring Boot系列 八、集成Kafka
一.引入依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId> ...
- Storm应用系列之——集成Kafka
本文系原创系列,转载请注明. 原帖地址:http://blog.csdn.net/xeseo 前言 在前面Storm系列之——基本概念一文中,提到过Storm的Spout应该是源源不断的取数据,不能间 ...
- Storm集成Kafka应用的开发
我们知道storm的作用主要是进行流式计算,对于源源不断的均匀数据流流入处理是非常有效的,而现实生活中大部分场景并不是均匀的数据流,而是时而多时而少的数据流入,这种情况下显然用批量处理是不合适的,如果 ...
- storm集成kafka的应用,从kafka读取,写入kafka
storm集成kafka的应用,从kafka读取,写入kafka by 小闪电 0前言 storm的主要作用是进行流式的实时计算,对于一直产生的数据流处理是非常迅速的,然而大部分数据并不是均匀的数据流 ...
- Storm集成Kafka的Trident实现
原本打算将storm直接与flume直连,发现相应组件支持比较弱,topology任务对应的supervisor也不一定在哪个节点上,只能采用统一的分布式消息服务Kafka. 原本打算将结构设 ...
- Storm 系列(七)—— Storm 集成 Redis 详解
一.简介 Storm-Redis 提供了 Storm 与 Redis 的集成支持,你只需要引入对应的依赖即可使用: <dependency> <groupId>org.apac ...
随机推荐
- RV32I基础整数指令集
RV32I是32位基础整数指令集,它支持32位寻址空间,支持字节地址访问,仅支持小端格式(little-endian,高地址高位,低地址地位),寄存器也是32位整数寄存器.RV32I指令集的目的是尽量 ...
- 批处理(bat)的一些记录
总览:https://www.jb51.net/article/151923.htm 如何判断空格与回车的输入:https://www.lmdouble.com//113311107.html 设置命 ...
- 利用Python模拟登录pastebin.com
任务 在https://pastebin.com网站注册一个账号,利用python实现用户的自动登录和创建paste.该任务需要分成如下两步利用python实现: 账号的自动登录 paste的自动创建 ...
- mtime, atime, ctime 的区别
mtime ls -l 显示最近修改文件内容的时间 atime ls -lu 显示最近访问文件的时间 ctime ls -li 显示最近文件有所改变的状态,如文件修改,属性\属主改变,节点,链接变化等 ...
- Django admin简单介绍
生成同步数据库的脚本: python manage.py makemigrations 同步数据库: python manage.py migrate 创建后台用户 python manage.py ...
- linux 互斥锁和条件变量
为什么有条件变量? 请参看一个线程等待某种事件发生 注意:本文是linux c版本的条件变量和互斥锁(mutex),不是C++的. mutex : mutual exclusion(相互排斥) 1,互 ...
- [MySQL] 为什么要给表加上主键
1.一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐. 2.一个加了主键的表,并不能被称之为「表」.如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结 ...
- MySQL添加CSV文件中的数据
一.MySQL添加csv数据 此问题是前几天整理数据的时候碰到的,数据存在 CSV文件中(200多万记录),通过python 往数据库中导入太慢了,后来使用MySQL 中自带的命令 LOAD DATA ...
- Python类的使用总结
Python是一个面向对象的解释型语言,所以当然也有类的概念.在Python中,所有数据类型都可以视为对象,当然也可以自定义对象.自定义的对象数据类型就是面向对象中的类(Class)的概念.之前接触类 ...
- Spring(003)-消费返回list的rest服务
通过spring提供的RestTemplate就可以访问rest服务.首先需要创建一个RestTemplate,这个需要手动来创建bean @Configuration public class De ...