学习Spring-Data-Jpa(十一)---抓取策略与实体图
1、抓取策略
在前面说到的关联关系注解中,都有一个fetch属性,@OneToOne、@ManyToOne中都默认是FetchType.EAGER,立即获取。@OneToMany、@ManyToMany默认值是FetchType.LAZY,延迟获取。这些注解的的fetch属性定义的是合适获取,至于如何获取,对与FetchType.EAGER,使用的是JOIN。FetchType.LAZY使用的是SELECT。JPA并没有提供我们设置如何获取的方式,如果想要进行修改要使用Hibernate提供的Fetch注解配置FetchMode。里面提供了三种方式SELECT、JOIN、SUBSELECT。(大多数情况下,我们不需要进行设置如何加载,使用默认的即可)
但是对于JPA的fetch,使用起来只有在使用Spring-Data-Jpa为我们提供的findById方法时,配置的fetch=FetchType.EAGER才会生效。而我们根据Spring-Data-Jpa规则定义的方法查询则不生效,还是会进行延迟加载。
1.1、执行findById会进行关联查询
/**
* 对于fetch= FetchType.EAGER ,使用findById会执行关联查询。
*/
@Test
void testFindById(){
Optional<Book> bookOptional = bookRepository.findById(1L);
if (bookOptional.isPresent()) {
Book book = bookOptional.get();
System.out.println(book.getCategory().getCategoryName());
}
}
findById控制台的打印信息
Hibernate: select book0_.id as id1_4_0_, book0_.book_name as book_nam2_4_0_, book0_.category_id as category4_4_0_, book0_.publish_date as publish_3_4_0_, category1_.id as id1_6_1_, category1_.category_name as category2_6_1_, category1_.parent_id as parent_i3_6_1_ from cfq_jpa_book book0_ left outer join cfq_jpa_category category1_ on book0_.category_id=category1_.id where book0_.id=?
Java
1.2、执行findByBookName不会进行关联查询
/**
* 根据书名进行查询书籍
* @param bookName bookName
* @return book
*/
Optional<Book> findByBookName(String bookName);
/**
* 对于fetch= FetchType.EAGER ,使用我们自己定义的查询方法,则不生效,会使用懒加载的方式
*/
@Test
void findByBookName(){
Optional<Book> bookOptional = bookRepository.findByBookName("java编程思想");
if (bookOptional.isPresent()) {
Book book = bookOptional.get();
System.out.println(book.getCategory().getCategoryName());
}
}
findByBookName控制台的打印信息
Hibernate: select book0_.id as id1_4_, book0_.book_name as book_nam2_4_, book0_.category_id as category4_4_, book0_.publish_date as publish_3_4_ from cfq_jpa_book book0_ where book0_.book_name=?
Hibernate: select category0_.id as id1_6_0_, category0_.category_name as category2_6_0_, category0_.parent_id as parent_i3_6_0_ from cfq_jpa_category category0_ where category0_.id=?
Java
这样的话,如果我们对于图书(Book)来说,我们使用findById方法时,是可以直接拿到门类(Category)信息的。但是通过findByBookName进行查询时,只有我们使用到门类的时候,才会发送一条查询门类的SQL,只是对于一条记录还好。但是如果我们查询一个图书列表(N本图书)的时候,这时就会执行N+1条SQL。如下所示,根据出版时间进行查询,一共有3条记录,执行了4句SQL。
/**
* 对于fetch= FetchType.EAGER ,使用我们自己定义的查询方法,则不生效,会使用懒加载的方式,执行 N+1条SQL。
*
*/
@Test
void findByPublishDate(){
List<Book> books = bookRepository.findByPublishDate(LocalDate.of(2019,11,17));
books.forEach(b -> System.out.println(b.getCategory().getCategoryName()));
}
Hibernate: select book0_.id as id1_4_, book0_.book_name as book_nam2_4_, book0_.category_id as category4_4_, book0_.publish_date as publish_3_4_ from cfq_jpa_book book0_ where book0_.publish_date=?
Hibernate: select category0_.id as id1_6_0_, category0_.category_name as category2_6_0_, category0_.parent_id as parent_i3_6_0_ from cfq_jpa_category category0_ where category0_.id=?
Hibernate: select category0_.id as id1_6_0_, category0_.category_name as category2_6_0_, category0_.parent_id as parent_i3_6_0_ from cfq_jpa_category category0_ where category0_.id=?
Hibernate: select category0_.id as id1_6_0_, category0_.category_name as category2_6_0_, category0_.parent_id as parent_i3_6_0_ from cfq_jpa_category category0_ where category0_.id=?
Java
数据结构
数据库
对于这个问题,我们怎么来解决呢?
2、使用@Query自己写JPQL语句进行解决N+1条SQL问题。
/**
* 使用@Query,JPQL中 声明要查询category属性,减少子查询。
* @param publishDate publishDate
* @return list
*/
@Query(value = "select b,b.category from Book b where b.publishDate = :publishDate ")
// @Query(value = "select b,c from Book b inner join Category c on b.category = c where b.publishDate = :publishDate ")
List<Book> findByPublishDateWithQuery(LocalDate publishDate);
/**
* 对于fetch= FetchType.EAGER ,使用@Query,自己写查询语句,解决N+1条SQL问题。
*/
@Test
void findByPublishDateWithQuery(){
List<Book> books = bookRepository.findByPublishDateWithQuery(LocalDate.of(2019, 11, 17));
books.forEach(b -> System.out.println(b.getCategory().getCategoryName()));
}
findByPublishDateWithQuery控制台打印的信息
Hibernate: select book0_.id as id1_4_0_, category1_.id as id1_6_1_, book0_.book_name as book_nam2_4_0_, book0_.category_id as category4_4_0_, book0_.publish_date as publish_3_4_0_, category1_.category_name as category2_6_1_, category1_.parent_id as parent_i3_6_1_ from cfq_jpa_book book0_ inner join cfq_jpa_category category1_ on book0_.category_id=category1_.id where book0_.publish_date=?
Java
数据结构
数据库
在很多情况下,我们使用Spring-Data-Jpa,一些简单的查询,我们都喜欢用定义方法查询,而不是写JPQL。JPA为我们提供了一组注解:使用Spring-Data-Jpa为我们提供的@EntityGraph,或@EntityGraph和@NamedEntityGraph进行解决。
3、@NamedEntityGraphs、@NamedEntityGraph、@EntityGraph
3.1、@NamedEntityGraphs:用于对@NamedEntityGraph注解进行分组。
3.2、@NamedEntityGraph:用于指定查找操作或查询的路径和边界。
属性name:(可选) 实体图的名称。 默认为根实体的实体名。
属性attributeNodes:(可选) 包含在该图中的实体属性列表。
属性:includeAllAttributes:(可选)将注释实体类的所有属性作为属性节点包含在NamedEntityGraph中,而无需显式列出它们。包含的属性仍然可以由引用子图的属性节点完全指定。默认为false。一般不需要设置。
属性subgraphs:(可选)包含在实体图中的子图列表。这些是从NamedAttributeNode定义中按名称引用的。
属性subclassSubgraphs:(可选) 子图列表 这些子图将向实体图添加注释实体类的子类的附加属性。超类中的指定属性包含在子类中。
3.3、@EntityGraph: 注解用于配置 JPA 2.1规范支持的javax.persistence.EntityGraph,应该使用在repository的方法上面。从1.9开始,我们支持动态EntityGraph定义,允许通过attributePaths()配置自定义fetch-graph。如果指定了attributePaths(),则忽略entity-graph的name(也就是配置的value()),并将EntityGraph视为动态的。
属性value:要使用的名称。如果为空,则返回JpaQueryMethod.getNamedQueryName()作为value。一般为@NamedEntityGraph的name值,或者不填使用自己的attributePaths属性。
属性type:要使用的EntityGraphType,默认为EntityGraphType.FETCH。
属性attributePaths:要使用的属性路径,默认为空。可以直接引用实体属性,也可以通过roperty.nestedProperty引用嵌套属性。
枚举EntityGraphType:
LOAD("javax.persistence.loadgraph"):当javax.persistence.loadgraph属性用于指定实体图时,由实体图的attributePaths指定的属性将被视为FetchType.EAGER,未指定的属性,将根据其设置的或默认的FetchType来进行处理。
FETCH("javax.persistence.fetchgraph"):当javax.persistence.fetchgraph属性用于指定实体图时,由实体图的attributePaths指定的属性将被视为FetchType.EAGER,而未指定的属性被视为FetchType.LAZY。
3.4、使用方法1:
3.4.1、在实体上定义一个NamedEntityGraph

3.4.2、在Repository的查询方法上引用实体图。
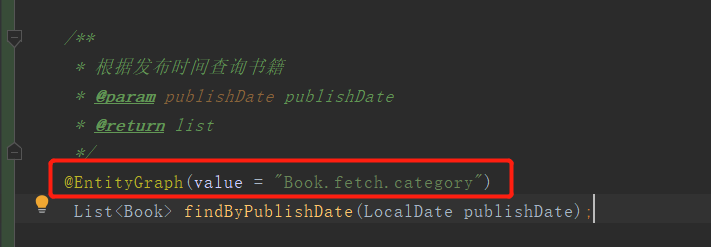
3.4.3、测试根据出版时间进行查询,由4条SQL变为3条。
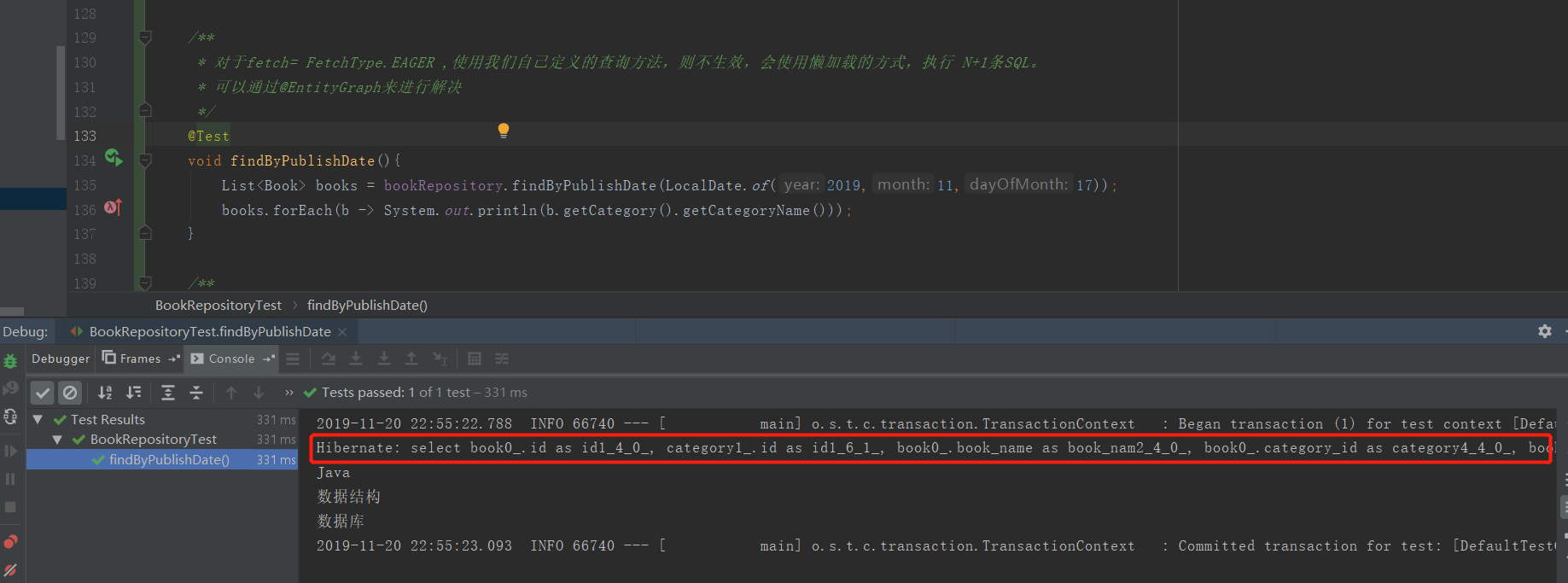
3.5、使用方法2:也可以不用再实体上定义NamedEntityGraph,直接使用@EntityGraph的attributePaths属性来设置,效果是一样的。只不过如果有多个属性都要一起查出来,而且有多个方法都用到了,使用@EntityGraph的attributePaths属性修改起来就不是那么方便了,结合自己的情况进行选择。
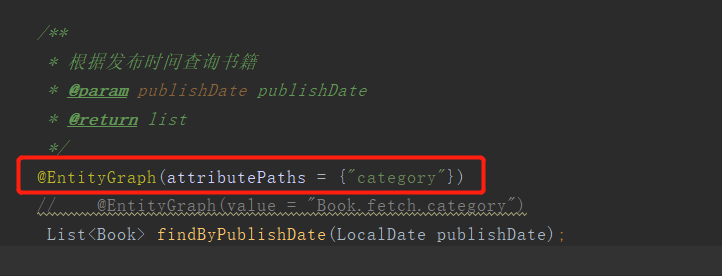
4、对于具有父子关系的处理
场景:门类(Category),常常具有父子关系,比如说,文学类图书下面可能有小说分类,而小说分类下,又分为长、中、短篇小说。我们怎么一次查出需要的树形结果呢?
准备工作:
4.1、Category实体:
/**
* 类别
* @author caofanqi
*/
@Data
@Entity
@Builder
@Table(name = "jpa_category")
@NoArgsConstructor
@AllArgsConstructor
public class Category { @Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id; private String categoryName; /**
* 父门类,通过parent_id来维护父子关系。
* 使用@ToString.Exclude,解决lombok的toString方法循环引用问题。
*/
@ToString.Exclude
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "parent_id",referencedColumnName = "id")
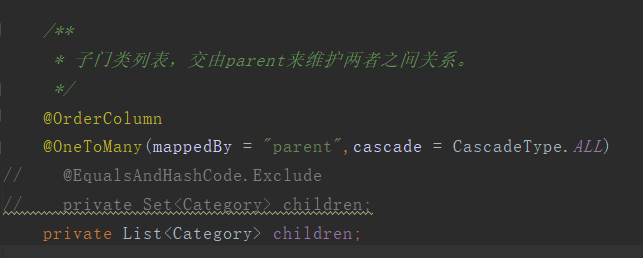
private Category parent; /**
* 子门类列表,交由parent来维护两者之间关系。
*/
@OneToMany(mappedBy = "parent",cascade = CascadeType.ALL)
private List<Category> children; /**
* 门类和书是一对多的关系
* 由多的一方来维护关联关系
*/
@OneToMany(mappedBy = "category")
@OrderBy("bookName DESC")
private List<Book> books; }
4.2、数据准备
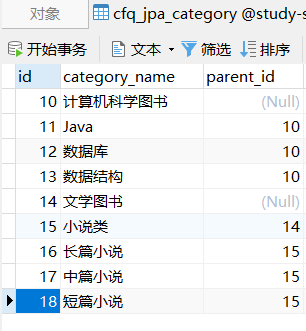
4.3、对于数据量比较小,我们可以重写JpaRepository的findAll方法,并添加@EntityGraph注解,抓取子节点,如下所示:
@Override
@EntityGraph(attributePaths = "children")
List<Category> findAll();
测试用例:
/**
* 测试 一次查询树形结构
*/
@Test
void findAll(){
List<Category> categories = categoryRepository.findAll();
categories.stream().filter(c -> c.getParent() == null).forEach(c -> printName(c,null));
} private void printName(Category category,String prefix){ if (StringUtils.isEmpty(prefix)){
prefix = "---";
} System.out.println(prefix + category.getCategoryName()); List<Category> children = category.getChildren();
if (!CollectionUtils.isEmpty(children)){
for (Category c : children){
printName(c,prefix + "---");
}
} }
控制台输出信息:
Hibernate: select category0_.id as id1_6_0_, children1_.id as id1_6_1_, category0_.category_name as category2_6_0_, category0_.parent_id as parent_i3_6_0_, children1_.category_name as category2_6_1_, children1_.parent_id as parent_i3_6_1_, children1_.parent_id as parent_i3_6_0__, children1_.id as id1_6_0__ from cfq_jpa_category category0_ left outer join cfq_jpa_category children1_ on category0_.id=children1_.parent_id
---计算机科学图书
------Java
------数据库
------数据结构
---文学图书
------小说类
---------长篇小说
---------中篇小说
---------短篇小说
这种方式的优点是,不管层级多深,只有一次join。缺点是需要查询出来全部的门类,然后再代码中过滤出顶级门类,出给前端使用。而且,对于只查询某一门类,和下面的子门类不适用。
4.4、根据父门类,一次性查询子门类及子门类的所有子节点。
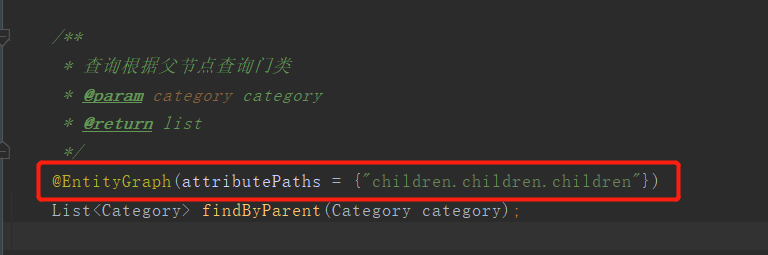
4.4.1、findByParent
/**
* 查询根据父节点查询门类
* @return list
*/
@EntityGraph(attributePaths = {"children"})
List<Category> findByParent(Category category);
4.4.2、这时我们测试发现,只是第一层的门类不用再执行SQL了,而下面的门类一样要执行。
@Test
void findByParent(){
List<Category> categories = categoryRepository.findByParent(null);
categories.forEach(c -> printName(c,null));
}
Hibernate: select category0_.id as id1_6_0_, children1_.id as id1_6_1_, category0_.category_name as category2_6_0_, category0_.parent_id as parent_i3_6_0_, children1_.category_name as category2_6_1_, children1_.parent_id as parent_i3_6_1_, children1_.parent_id as parent_i3_6_0__, children1_.id as id1_6_0__ from cfq_jpa_category category0_ left outer join cfq_jpa_category children1_ on category0_.id=children1_.parent_id where category0_.parent_id is null
---计算机科学图书
------Java
Hibernate: select children0_.parent_id as parent_i3_6_0_, children0_.id as id1_6_0_, children0_.id as id1_6_1_, children0_.category_name as category2_6_1_, children0_.parent_id as parent_i3_6_1_ from cfq_jpa_category children0_ where children0_.parent_id=?
------数据库
Hibernate: select children0_.parent_id as parent_i3_6_0_, children0_.id as id1_6_0_, children0_.id as id1_6_1_, children0_.category_name as category2_6_1_, children0_.parent_id as parent_i3_6_1_ from cfq_jpa_category children0_ where children0_.parent_id=?
------数据结构
Hibernate: select children0_.parent_id as parent_i3_6_0_, children0_.id as id1_6_0_, children0_.id as id1_6_1_, children0_.category_name as category2_6_1_, children0_.parent_id as parent_i3_6_1_ from cfq_jpa_category children0_ where children0_.parent_id=?
---文学图书
------小说类
Hibernate: select children0_.parent_id as parent_i3_6_0_, children0_.id as id1_6_0_, children0_.id as id1_6_1_, children0_.category_name as category2_6_1_, children0_.parent_id as parent_i3_6_1_ from cfq_jpa_category children0_ where children0_.parent_id=?
---------长篇小说
Hibernate: select children0_.parent_id as parent_i3_6_0_, children0_.id as id1_6_0_, children0_.id as id1_6_1_, children0_.category_name as category2_6_1_, children0_.parent_id as parent_i3_6_1_ from cfq_jpa_category children0_ where children0_.parent_id=?
---------中篇小说
Hibernate: select children0_.parent_id as parent_i3_6_0_, children0_.id as id1_6_0_, children0_.id as id1_6_1_, children0_.category_name as category2_6_1_, children0_.parent_id as parent_i3_6_1_ from cfq_jpa_category children0_ where children0_.parent_id=?
---------短篇小说
Hibernate: select children0_.parent_id as parent_i3_6_0_, children0_.id as id1_6_0_, children0_.id as id1_6_1_, children0_.category_name as category2_6_1_, children0_.parent_id as parent_i3_6_1_ from cfq_jpa_category children0_ where children0_.parent_id=?
4.4.3、解决多次查询问题,上面说到@EntityGraph的attributePaths是支持属性嵌套的,我们写一个children就会关联一次,如果我们知道层级的话,可以用.进行连接children,如下图,就会与自己关联三次有几层,就要至少有几个children,也就会进行几次关联。(层级越多,关联的次数越多)
也可以使用@NamedEntityGraph(感觉不如attributePaths简介),写法如下:
@NamedEntityGraph(name = "Category.findByParent",
attributeNodes = {@NamedAttributeNode(value = "children", subgraph = "son")}, //第一层
subgraphs = {@NamedSubgraph(name = "son", attributeNodes = @NamedAttributeNode(value = "children", subgraph = "grandson")), //第二层
@NamedSubgraph(name = "grandson", attributeNodes = @NamedAttributeNode(value = "children"))//第三层
})
但是现在光做这些还不够,执行测试用例,会抛出 org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags:异常;想知道为啥的可以点击这里。
我推荐两个解决办法:
①将List集合修改为Set,并使用@EqualsAndHashCode.Exclude解决lombok的hashcode方法引入的异常。

②使用@OrderColumn,这样jpa会在数据库中多出一列,用于自己维护关系。(一开始就要这样哦,半路改的,会有问题)
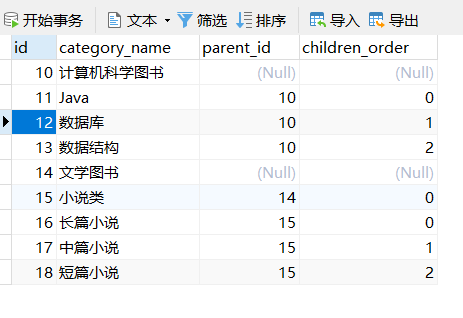
以上任意一种修改后,执行测试用例,控制台输出结果如下:
Hibernate: select category0_.id as id1_6_0_, children1_.id as id1_6_1_, children2_.id as id1_6_2_, children3_.id as id1_6_3_, category0_.category_name as category2_6_0_, category0_.parent_id as parent_i3_6_0_, children1_.category_name as category2_6_1_, children1_.parent_id as parent_i3_6_1_, children1_.parent_id as parent_i3_6_0__, children1_.id as id1_6_0__, children1_.children_order as children4_0__, children2_.category_name as category2_6_2_, children2_.parent_id as parent_i3_6_2_, children2_.parent_id as parent_i3_6_1__, children2_.id as id1_6_1__, children2_.children_order as children4_1__, children3_.category_name as category2_6_3_, children3_.parent_id as parent_i3_6_3_, children3_.parent_id as parent_i3_6_2__, children3_.id as id1_6_2__, children3_.children_order as children4_2__ from cfq_jpa_category category0_ left outer join cfq_jpa_category children1_ on category0_.id=children1_.parent_id left outer join cfq_jpa_category children2_ on children1_.id=children2_.parent_id left outer join cfq_jpa_category children3_ on children2_.id=children3_.parent_id where category0_.parent_id is null
---文学图书
------小说类
---------长篇小说
---------中篇小说
---------短篇小说
---计算机科学图书
------Java
------数据库
------数据结构
源码地址:https://github.com/caofanqi/study-spring-data-jpa
学习Spring-Data-Jpa(十一)---抓取策略与实体图的更多相关文章
- 学习Spring Data JPA
简介 Spring Data 是spring的一个子项目,在官网上是这样解释的: Spring Data 是为数据访问提供一种熟悉且一致的基于Spring的编程模型,同时仍然保留底层数据存储的特殊 ...
- 学习-spring data jpa
spring data jpa对照表 Keyword Sample JPQL snippet And findByLastnameAndFirstname - where x.lastname = ? ...
- 在Spring Data JPA 中使用Update Query更新实体类
对于 Spring Data JPA 使用的时间不长,只有两年时间.但是踩过坑的却不少. 使用下列代码 @Modifying @Query("update User u set u.firs ...
- Spring Data JPA 查询结果返回至自定义实体
本人在实际工作中使用Spring Data Jpa框架时,一般查询结果只返回对应的Entity实体.但有时根据实际业务,需要进行一些较复杂的查询,比较棘手.虽然在框架上我们可以使用@Query注解执行 ...
- 【Spring Data 系列学习】了解 Spring Data JPA 、 Jpa 和 Hibernate
在开始学习 Spring Data JPA 之前,首先讨论下 Spring Data Jpa.JPA 和 Hibernate 之前的关系. JPA JPA 是 Java Persistence API ...
- Hibernate学习---第十一节:Hibernate之数据抓取策略&批量抓取
1.hibernate 也可以通过标准的 SQL 进行查询 (1).将SQL查询写在 java 代码中 /** * 查询所有 */ @Test public void testQuery(){ // ...
- 一步步学习 Spring Data 系列之JPA(二)
继上一篇文章对Spring Data JPA更深( )一步剖析. 上一篇只是简单的介绍了Spring Data JPA的简单使用,而往往在项目中这一点功能并不能满足我们的需求.这是当然的,在业务中查询 ...
- Spring Data JPA 学习记录1 -- 单向1:N关联的一些问题
开新坑 开新坑了(笑)....公司项目使用的是Spring Data JPA做持久化框架....学习了一段时间以后发现了一点值得注意的小问题.....与大家分享 主要是针对1:N单向关联产生的一系列问 ...
- spring data jpa入门学习
本文主要介绍下spring data jpa,主要聊聊为何要使用它进行开发以及它的基本使用.本文主要是入门介绍,并在最后会留下完整的demo供读者进行下载,从而了解并且开始使用spring data ...
随机推荐
- 【Uiautomatorviewer】报错:Unexpected error while obtaining UI hierarchy java.lang.reflect.InvocationT...
android 9.0系统不能用uiautomator识别 解决方法:android 8.0 以后 uiautomator 无法直接使用的问题https://www.cnblogs.com/copyw ...
- [笔记] 命令行参数 int main(int argc,char *argv[])
int main(int argc,char *argv[]) // argument count 变量个数 argument values 变量值 C程序的main函数有两个形参* argc:整数, ...
- MNIST机器学习入门(一)
一.简介 首先介绍MNIST 数据集.如图1-1 所示, MNIST 数据集主要由一些手写数字的图片和相应的标签组成,图片一共有10 类,分别对应从0-9 ,共10 个阿拉伯数字. 原始的MNIST ...
- RabbitMQ Policy的使用
RabbitMQ作为最流行的MQ中间件之一,广泛使用在各类系统中,今天我们就来讨论一下如何通过Policies给RabbitMQ中已经创建的Queue添加属性和参数. Policise 的作用 通常来 ...
- 2019 钢银java面试笔试题 (含面试题解析)
本人3年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条. 钢银等公司offer,岗位是Java后端开发,最终选择去了 钢银. 面试了很多家公司,感觉大部分公司考察的点都差 ...
- eclipse中启动tomcat后, 无法访问localhost:8080
问题: 今天老师讲了Servlet路径问题, 做了个测试在eclipse中启动tomcat后,在浏览器地址栏输入 http://localhost8080无法访问, 提示404错误, 正常情况是可以访 ...
- k8s--yml文件
- java中异常的抛出:throw throws
java中异常的抛出:throw throws Java中的异常抛出 语法: public class ExceptionTest{ public void 方法名(参数列表) throws 异常列表 ...
- Angular使用操作事件指令ng-click传多个参数示例
本文实例讲述了Angular使用操作事件指令ng-click传多个参数功能.分享给大家供大家参考,具体如下: <!DOCTYPE html> <html ng-app="m ...
- Java项目部分总结
一.数据库sql操作: 1.三表查询的时候,最后的条件由于当前字段必须判断是属于哪个表,所以需要注明根据哪个表中的字段进行判断: 并且再在后面加上limit的时候,需要注意先进行添加,避免系统不能识别 ...