mysql常用操作(测试必备)
现在互联网的主流关系型数据库是mysql,掌握其基本的增、删、改、查是每一个测试人员必备的技能。
sql语言分类
1、DDL语句(数据库定义语言): 数据库、表、视图、索引、存储过程,例如:CREATE、DROP、ALTER
2、DML语句(数据库操纵语言): 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT
3、DCL语句(数据库控制语言): 控制用户的访问权限GRANT、REVOKE
操作库
我们可以把库看做是文件夹。
mysql自带的库:

information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql: 授权库,主要存储系统用户的权限信息
test: MySQL数据库系统自动创建的测试数据库
增
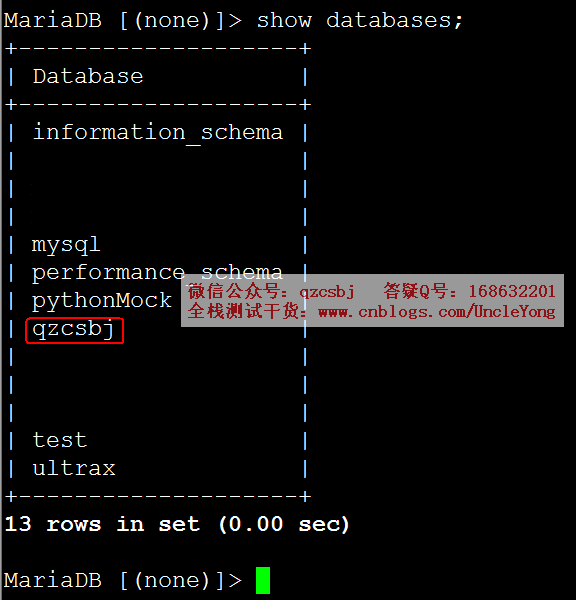
连接数据库,查看已有的数据库,show databases;

展示了已有的所有库(包含了我自己创建的数据库),如果只看到部分数据库,解决方案参考:https://www.cnblogs.com/UncleYong/p/10931195.html

创建库,指定编码,create database qzcsbj charset utf8;

库的存放位置

查
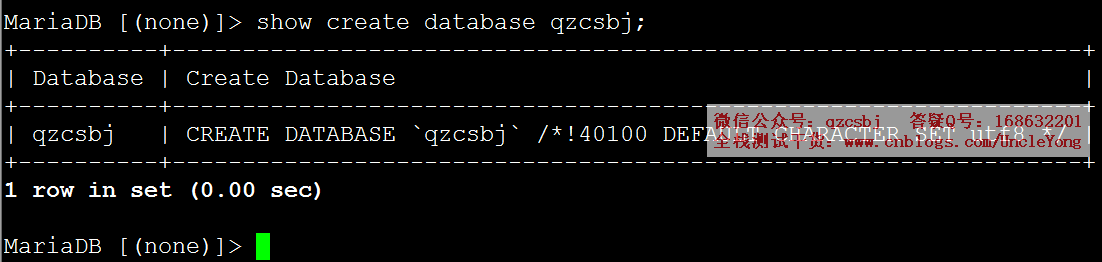
show create database qzcsbj;
show databases;
查看当前所在的库
select database();

改
修改编码,alter database qzcsbj charset gbk;

删
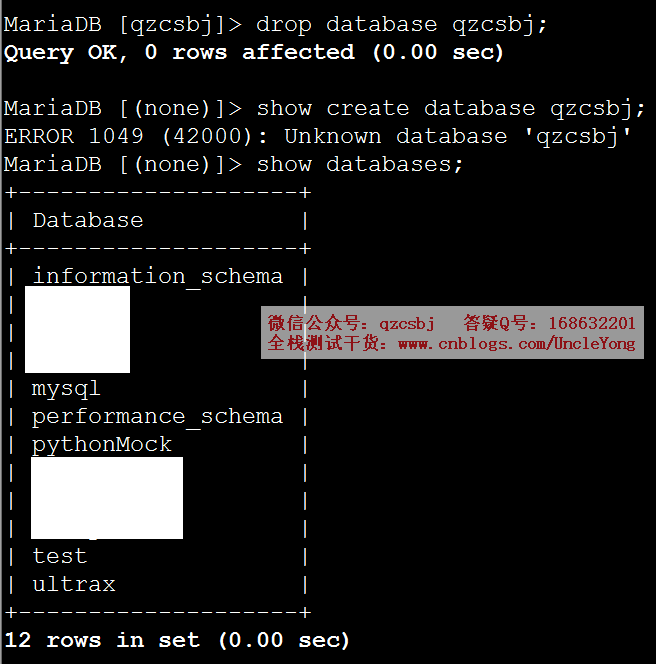
drop database qzcsbj;
操作表及列
我们可以把表看做是文件
切换数据库(文件夹):use qzcsbj ;
查看当前所在数据库(文件夹):select database();

增
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
增加前,只有一个opt文件

create table test(id int, name varchar(255));

增加后,多了一个frm文件,frm是表结构

查
show create table test \G; # \G表示按行显示表的详细结构

show tables;

desc test; # 等价于describe test;

复制
insert test(id,name) values(1,'qzcsbj1'),(2,'qzcsbj2'),(3,'qzcsbj3');
复制表结构+记录:
create table test2 select * from test;

只复制表结构:
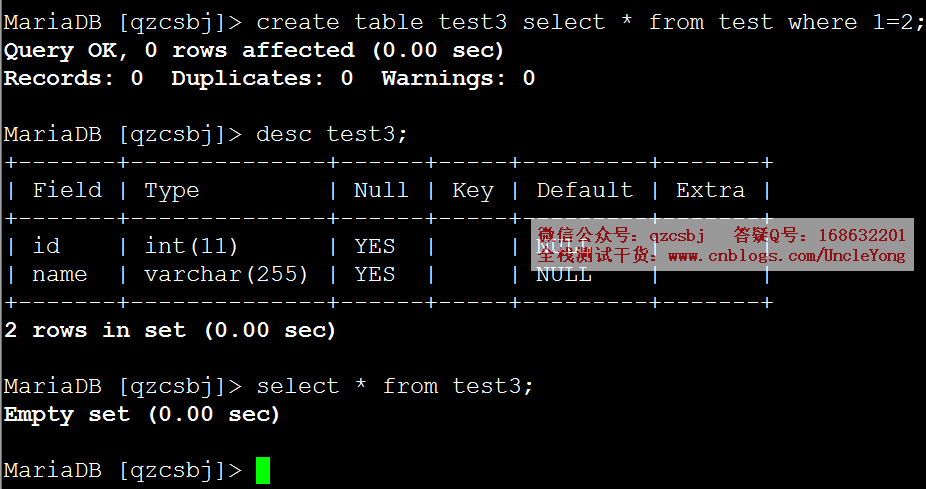
create table test3 select * from test where 1=2;
或者:
create table test4 like test;

改
ALTER TABLE 表名
# 修改表名
RENAME 新表名;
# 增加字段
ADD 字段名 数据类型 [完整性约束条件…];
ADD 字段名 数据类型 [完整性约束条件…] FIRST; # 添加到第一个字段
ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; # 添加到某个字段之后
# 删除字典
DROP 字段名;
# 修改字段
MODIFY 字段名 数据类型 [完整性约束条件…];
CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…];
CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
MODIFY,可以改字段属性
CHANGE,可以改字段名、字段属性
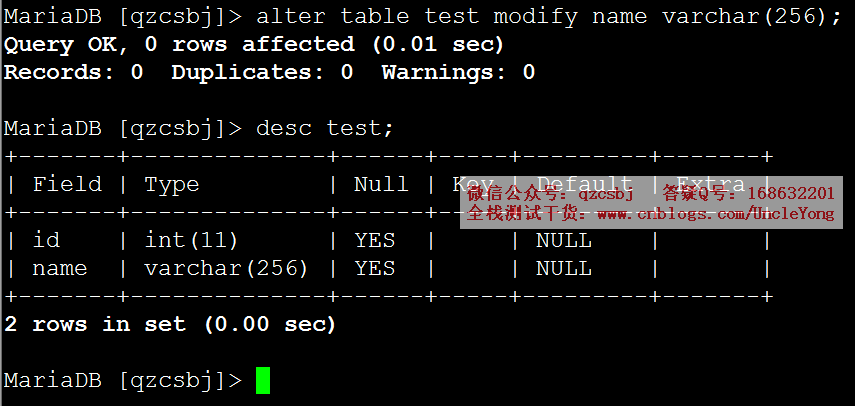
alter table test modify name varchar(256);
desc test;
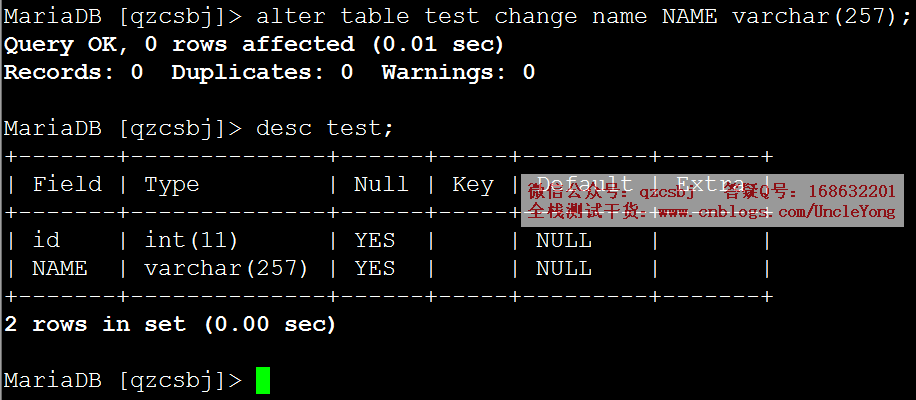
alter table test change name NAME varchar(257);
desc test;
删
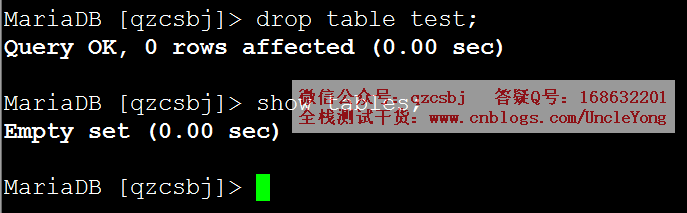
drop table test;
show tables;
操作记录
记录可以看做文件夹中文件的内容
增
全字段插入
INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); # into可以省略
多条数据逗号分隔
INSERT INTO 表名 VALUES
(值1,值2,值3…值n),
(值1,值2,值3…值n),
(值1,值2,值3…值n);
指定字段插入
INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…);
插入查询结果
INSERT INTO 表名(字段1,字段2,字段3…字段n)
SELECT (字段1,字段2,字段3…字段n) FROM 表2 WHERE …;
create table test(id int, name varchar(255));
insert test(id,name) values(1,'qzcsbj1'),(2,'qzcsbj2'),(3,'qzcsbj3');

查
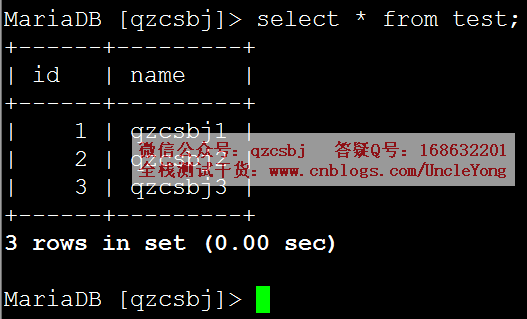
select * from test;
如果在其它库查test,表前必须加库作为前缀。
select * from qzcsbj.test;

改
UPDATE 表名 SET
字段1=值1
WHERE 约束条件;
update test set name='qzcsbj' where id=2;

删
delete from test where id=3;

delete,用于删除数据,自增长字段的值未重置
truncate,用于清空表,自增长字段的值也被重置
注意:delete不能给表取别名

数据类型
数字
参考:https://www.runoob.com/mysql/mysql-data-types.html

日期类型
年:year
年月日:date
时分秒:time
年月日时分秒:datetime
create table student(
id int,
name char(6), # 最大存储6个字符
born_year year, # 年
birth_date date, # 年月日
class_time time, # 时分秒
reg_time datetime # 年月日时分秒
);
插入数据
insert into student values(1,'jack',now(),now(),now(),now());
insert into student values(2,'tom',"2017","2017-12-12","12:12:12","2017-12-12 12:12:12");
now()是mysql提供的函数

字符类型
# 宽度指的是字符的个数
create table test(name char(5));
create table test(name varchar(5));
char:按指定长度存,存取速度快,但是当存的数据的长度小于字段定义的长度时浪费空间
varchar:存数据更精简,更加节省空间(是在存的数据的长度小于字段定义的长度时;否则必char浪费空间,因为多少了头,要花1个byte),缺点,存取速度慢,要先存头,再存数据;先取头,再取数据;
现如今,存储空间已经不是限制了,要追求存取速度,大部分用char,与查询无关的用varchar
建表的时候,定长的数据往前放,变长的往后放,而且,一张表中,不要char和varchar混用
枚举及集合类型
enum 单选,只能在给定的范围内选一个值,如性别
sex enum('male','female','other'),
set 多选,在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
hobbies set('play','music','read','run')
drop table test;
create table test(
id int,
name char(16),
sex enum('male','female','other'),
hobbies set('play','music','read','run')
);
插入
insert into test values(1,'jack','male','music,read'); # 集合多个值用逗号分隔
存储引擎
分类
1、InnoDB 存储引擎
2、MyISAM 存储引擎
3、NDB 存储引擎
4、Memory 存储引擎
5、Infobright 存储引擎
6、NTSE 存储引擎
7、BLACKHOLE
详见mysql性能调优篇。
约束
作用:保证数据的完整性和一致性
分类
PRIMARY KEY (PK),标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK),标识该字段为该表的外键
NOT NULL,标识该字段不能为空
UNIQUE KEY (UK),标识该字段的值是唯一的
AUTO_INCREMENT, 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT, 为该字段设置默认值
primary key
#方法一:在某一个字段后用primary key
drop table test;
create table test(
id int primary key,
name char(255)
);
#方法二:not null+unique
创建表时未指定主键,会找不为空且唯一的字段作为主键
drop table test;
create table test(
id int not null unique,
name char(255)
);
#方法三:在所有字段后单独定义primary key
drop table test;
create table test(
id int,
name varchar(255),
constraint pk_name primary key(id)
);
foreign key
建立表之间的关系
create table student(
id int primary key,
name char(255),
age int
); # 关联的表
create table class(
id int primary key,
name char(255),
stu_id int,
foreign key(stu_id) references student(id)
on delete cascade # 删除同步
on update cascade # 修改同步
);
not null与default
drop table test;
create table test(
id int,
name char(255),
sex enum('male','female') not null default 'male'
);
unique key
单列唯一:方式一
drop table test;
create table test(
id int unique,
name char(255) unique
);
单列唯一:方式二
drop table test;
create table test(
id int,
name char(255),
unique(id),
unique(name)
);
联合唯一
drop table test;
create table test(
id int,
name char(255),
unique(id,name)
);
复合主键
drop table test;
create table test(
id int,
name char(255),
primary key(id, name)
);
auto_increment
约束字段为自动增长,增长字段必须设置为key,primary key,unique key
drop table test;
create table test(
id int primary key auto_increment,
name char(255)
);
表与表之间的关系
一对一:身份证号与姓名
一对多:一个班级有多个学生
多对多:一个老师给多个班级授课,一个班级有多位授课老师
固定套路格式
一个单表复杂且完整的sql格式是如下的样子,如果是多表,加个join及连接条件就可以了,很简单。
select distinct 字段1,字段2,字段3 # 要查询的字段或者分组字段聚合函数
from 库.表 # 从哪个表查,如果当前所在的库不是这个表所在的库,表的前面需要加上库名
where # 约束条件
group by # 分组
having # 过滤
order by # 排序
limit # 限制条数
select
select distinct 字段1,字段2,字段3 # 要查询的字段或者分组字段聚合函数
distinct
去重
from
from 库.表 # 从哪个表查,如果当前所在的库不是这个表所在的库,表的前面需要加上库名
where
where是分组之前过滤,后面是普通条件
1.比较运算符:><>= <= <> !=
2.逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
3.between 10 and 100 值在10到100之间
4.in(80,90) 值是80或90
5.like 'qzcsbj%',除了%还可以_,%表示任意多字符,_表示一个字符
group by
一般来说,“每”这个字后面的字段,就是我们分组的字段
having
having是分组之后过滤,后面是聚合条件
聚合函数(以组为单位进行统计)
max,最大
min,最小
avg,平均
sum,和
count,数量
order by
默认升序,asc
降序,desc
也可以先按某个字段升序,再按某个字段降序,例如:select * from test order by id asc, name desc;
limit
limit n,默认初始位置为0,从1开始取,取n条,如果不足n条记录,那么有多少条就取多少条
limit m,n,表示位置m,从m+1开始取,取n条记录,如果不足n条记录,那么有多少条就取多少条
执行顺序
5 select
6 distinct
1 from 库.表
2 where
3 group by
4 having
7 order by
8 limit
多表查询
我们不可能把数据都存在一个表中,而是存多个表中,这就涉及到多表查询了
交叉连接
生成笛卡尔积,不适用任何匹配条件。
内连接
只取两张表的共同部分,join on
左外连接
显示左表全部记录,在内连接的基础上增加左边有右边没有的结果,left join on
右外连接
显示右表全部记录,在内连接的基础上增加右边有左边没有的结果,right join on
全外连接
显示左右两个表全部记录,在内连接的基础上增加左边有右边没有的和右边有左边没有的结果,
union,其与union all的区别是,union会去掉相同的纪录,另外,mysql不支持full join on
账号权限管理
创建新用户:CREATE USER 'test'@'localhost' IDENTIFIED BY '123456';
新用户授权:GRANT ALL PRIVILEGES ON *.* TO 'test'@'%'IDENTIFIED BY '123456' WITH GRANT OPTION;
授权(只能root操作)
*.* # 所有库下的所有表(以及表下的所有字段)都有权限
qzcsbj.* # test库下的所有表(qzcsbj数据库下所有表,以及表下的所有字段)
qzcsbj.test # qzcsbj库下test表(某一张表,以及该表下的所有字段)
columns_priv字段:id,name # 字段(某一个或几个字段),grant select(id,name),update(name) on qzcsbj.test to 'test'@'localhost'; 收回权限
revoke select on qzcsbj.test from 'test'@'localhost';
刷新授权:flush privileges;
内置函数
(待补充)
数值函数
字符串函数
日期时间函数
流程控制函数
系统信息函数
索引
见性能优化篇
python操作mysql
参考:https://www.cnblogs.com/UncleYong/p/10938993.html
综合练习
设计表
表关系: 下面每个表的第一个字段是主键,未建立外键,使用逻辑外键

创建表
班级表
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(255) NOT NULL,
`grade_id` int(11) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8;
年级表
DROP TABLE IF EXISTS `class_grade`;
CREATE TABLE `class_grade` (
`gid` int(11) NOT NULL AUTO_INCREMENT,
`gname` varchar(255) NOT NULL,
PRIMARY KEY (`gid`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
课程表
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` int(11) NOT NULL,
`cname` varchar(255) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
成绩表
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`score` varchar(255) DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8;
学生表
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`sname` varchar(255) NOT NULL,
`gender` enum('女','男') NOT NULL DEFAULT '男',
`class_id` int(11) NOT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
老师表
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL,
`tname` varchar(255) DEFAULT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
班级任职表
DROP TABLE IF EXISTS `teacher2cls`;
CREATE TABLE `teacher2cls` (
`tcid` int(11) NOT NULL AUTO_INCREMENT,
`tid` int(11) NOT NULL,
`cid` int(11) NOT NULL,
PRIMARY KEY (`tcid`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
初始化数据
大家自己完成,这样可以熟悉表关系。
练习题
1.查询“生物”课程和“物理”课程成绩都及格的学生id和姓名;
2.查询每个年级的班级数,取出班级数最多的前三个年级;
3.查询每位学生的学号,姓名,选课数,平均成绩;
4.查询每个年级的学生人数;
(文末加群获取参考答案)
mysql常用操作(测试必备)的更多相关文章
- Windows平台下MySQL常用操作与命令
Windows平台下MySQL常用操作与命令 Windows平台下MySQL常用操作与命令,学习mysql的朋友可以参考下. 1.导出整个数据库 mysqldump -u 用户名 -p --defau ...
- mysql常用操作语句
mysql常用操作语句 1.mysql -u root -p 2.mysql -h localhost -u root -p database_name 2.列出数据库: 1.show datab ...
- MySQL常用操作总结
MySQL常用操作 前提条件:已安装MySQL. 学习目标:用一条sql语句写出A和B的剩余数量 AA表 BB表 以上为一道面试题,接下来由这道面试题来回顾一些数据库的基本操作. 登录MySQL su ...
- centos LAMP第四部分mysql操作 忘记root密码 skip-innodb 配置慢查询日志 mysql常用操作 mysql常用操作 mysql备份与恢复 第二十二节课
centos LAMP第四部分mysql操作 忘记root密码 skip-innodb 配置慢查询日志 mysql常用操作 mysql常用操作 mysql备份与恢复 第二十二节课 mysq ...
- MySQL常用操作2
MySQL常用操作2 判断函数 IF(expr, value1, value2) -- 如果表达式expr为true,则返回value1,否则返回value2 IFNULL(value1, val ...
- MYSQL常用操作函数的封装
1.mysql常用函数封装文件:mysql.func.php <?php /** * 连接MYSQL函数 * @param string $host * @param string $usern ...
- Linux 笔记 - 第十五章 MySQL 常用操作和 phpMyAdmin
博客地址:http://www.moonxy.com 一.前言 前面几章介绍了 MySQL 的安装和简单的配置,只会这些还不够,作为 Linux 系统管理员,我们还需要掌握一些基本的操作,以满足日常管 ...
- mysql常用操作及常见问题
常用操作 mysql备份: --整库备份 docker exec 容器ID mysqldump -uroot -p密码 --databases 库名 > 库名.sql --仅导出表和数据 mys ...
- 第二篇 Mysql常用操作记录(转载)
我们在创建网站的时候,一般需要用到数据库.考虑到安全性,建议使用非root用户.常用命令如下: 1.新建用户 //登录MYSQL@>mysql -u root -p@>密码//创建用户my ...
- mysql常用操作 mysql备份与恢复
先登录mysql ==>mysql -uroot -p 查看数据库的版本 select version(); 查看有哪些库 show datases; 查看当前处于哪个库 select da ...
随机推荐
- [LeetCode] 263. Ugly Number 丑陋数
Write a program to check whether a given number is an ugly number. Ugly numbers are positive numbers ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- PurpleAir空气质量数据采集
PurpleAir空气质量数据采集 # -*- coding: utf-8 -*- import time, datetime, calendar import urllib, requests im ...
- PHP服务端优化全面总结
一.优化PHP原则 1.1PHP代码的优化 (1)升级最新的PHP版本 鸟哥PPT里的对比数据,就是WordPress在PHP5.6执行100次会产生70亿次的CPU指令执行数目,而在PHP7中只需要 ...
- MySQL的统计总数count(*)与count(id)或count(字段)的之间的各自效率性能对比
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和cou ...
- 折腾linux随笔 之 关闭Budgie默认自动隐藏应用的菜单栏 与 Gnome系桌面应用菜单无内容解决
关闭Budgie默认自动隐藏应用菜单栏 首选项 -> 设置 -> 通用辅助功能 -> 打开 始终显示通用辅助菜单 后的开关 -> 注销桌面重新登录. done. 解决Gnome ...
- WebStrom安装Markdown插件
安装步骤 File→Settings→Plugins→关键字搜索markdown→选择Markdown Navigator→点击Install→出现下载弹窗,等待下载完毕→重启Webstrom 效果预 ...
- Redis-1-简介与安装
目录 1.Redis 简介 2.安装Redis 1.安装gcc redis是c语言编写的 2.下载redis安装包,在root目录下执行 3.解压redis安装包 4.进入redis目录 5.编译安装 ...
- .net Core 学习笔记(增加Nlog日志)
https://github.com/NLog/NLog.Web/wiki/Getting-started-with-ASP.NET-Core-2 (日志下载) https://github.com ...
- C++初探
//string1.cpp #include <iostream> int main() { using namespace std; ]={'d','o','g'}//这是char数组, ...