批处理引擎MapReduce编程模型
批处理引擎MapReduce编程模型
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
MapReduce是一个经典的分布式批处理计算引擎,被广泛应用于搜索引擎索引构建,大规模数据处理等场景中,具有易于编程,良好的扩展性与容错性以及高吞吐率等特点。它主要由两部分组成:编程模型和运行时环境。其中编程模型为用户提供了非常易用的编程接口,用户只需像编写串行程序一样实现几个简单的函数即可实现一个分布式程序,而其他比较复杂的工作,如节点间的通信,节点失效,数据切分等,全部由MapReduce运行时环境完成,用户无需关心这些细节。
一.MapReduce产生背景
Hadoop最早起源于Nutch。Nutch是一个开源的网络搜索引擎,由Doug Cutting于2002年创建。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取,索引,查询等功能,但随着网页数量的增加,遇到了严重的可扩展性问题,即:不能解决数十亿网页的存储和索引问题。
之后,两片谷歌论文为该问题提供了可行的解决方案:一篇是2003年发表的关于谷歌分布式文件系统(Google File System,简称GFS)的论文,该论文描述了谷歌搜索引擎网页相关数据的存储架构,该架构可解决Nutch遇到的网页抓取和索引过程中产生的超大文件存储需求的问题,但由于谷歌仅开源了思想而未开源代码,Nutch项目组便根据论文完成了一个开源实现,即:Nutch的分布式文件系统(NDFS)
另一篇是2004年发表的关于谷歌分布式计算框架MapReduce的论文,该论文描述了谷歌内部最重要的分布式计算框架MapReduce的设计艺术,该框架可用于处理海量网页的索引问题,同样,由于谷歌未开源代码,Nutch的开发人员完成了一个开源实现。
由于NDFS和MapReduce不仅适用于搜索引擎领域。2006年初,开发人员便将其移出Nutch,成为Lucene组织一个专门的团队继续发展Hadoop。大于同一时间,Doug Cutting加入雅虎公司,且公司统一组织一个专门的团队继续发展Hadoop,于同年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2008年1月,Hadoop成为Apache顶级项目,迎来了它的快速发展期。
二.MapReduce设计目标
我们知道Hadoop MapReduce诞生于搜索引擎领域,主要解决搜索引擎面临的海量数据处理扩展性差的问题。它的实现很大成都上借鉴了谷歌MapReduce的设计思想,包括简化编程接口,提高系统容错性等。
总结Hadoop MapReduce设计目标,主要有一下几个:
(1):易于编程
传统的分布式程序设计非常复杂(如MPI),用户需要关注的细节非常多,比如数据分片,数据传输,节点间通信等,因而设计分布式程序的门槛非常高。MapReduce的一个重要设计目标便是简化分布式程序设计。它将于并行程序逻辑无关的设计细节抽象成公共模块并交由系统实现,而用户只需专注于自己的应用程序逻辑实现,这样简化了分布式程序设计且提高了开发效率。
(2):良好的扩展性
随着业务的发展,积累的数据量(如搜索公司的网页量)会越来越大,当数据量增加到一定成都后,现有集群可能已经无法满足其计算和存储需求,这时候管理员可能期望通过添加机器以达到线性扩展集群能力的目的。 (3):高容错性
在分布式环境下,随着集群规模的增加,集群中的故障次数(这里的“故障”包括磁盘损坏,机器宕机,节点间通信是啊比等硬件故障和程序bug产生的软件故障)会显著增加,进而导致任务失败或者数据丢失的可能性增加,为了避免这些问题,MapReduce通过计算迁移或者数据迁移等策略提高集群的可用性和容错性。 (4):高吞吐率
一个分布式系统通常需要在高吞吐率和低延迟之间做权衡,而MapReduce计算引擎则选择了高吞吐率。MapReduce通过分布式并行技术,能够利用多机资源,一次读取和写入海量数据。
三.MapReduce编程思想
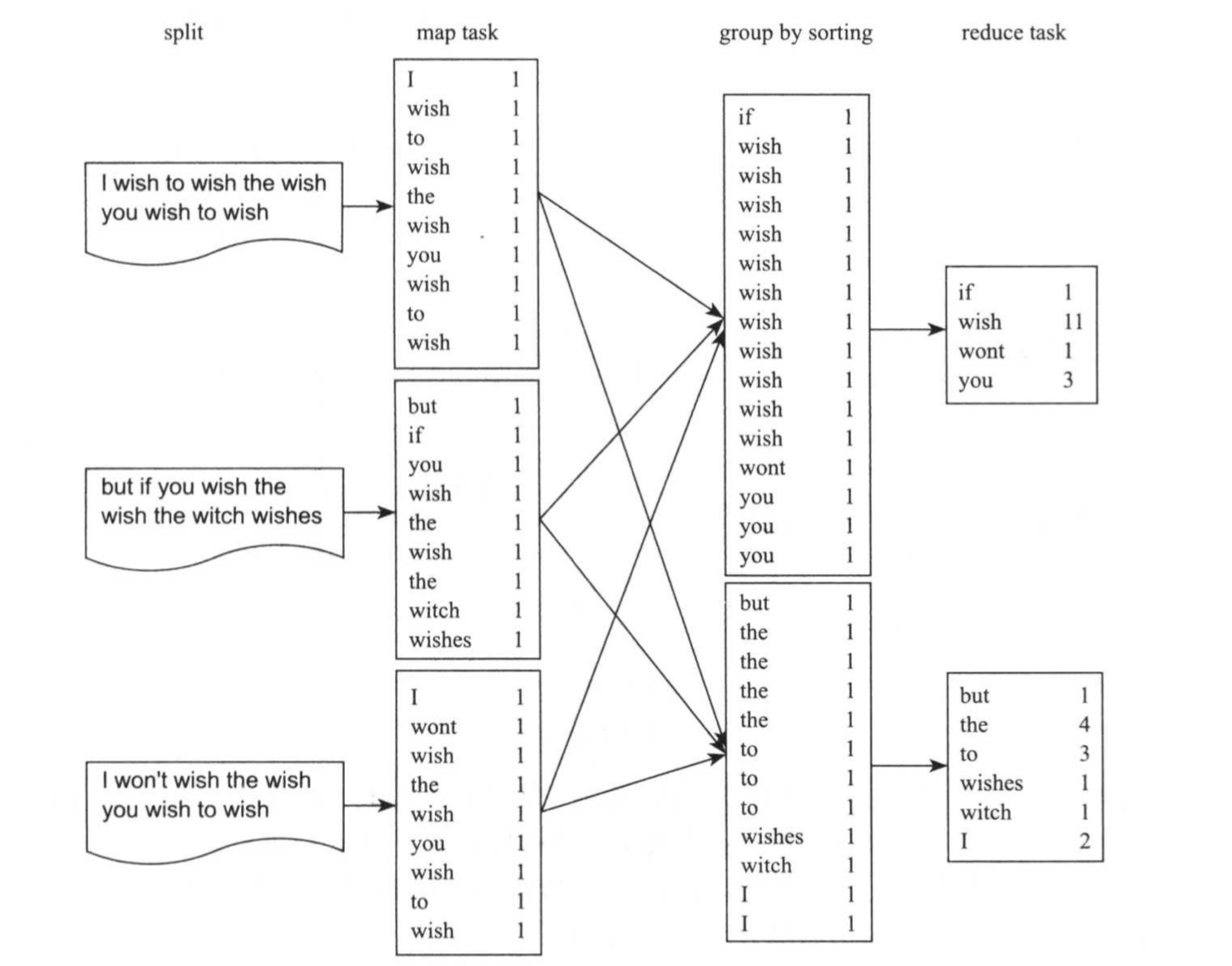
类似于编程语言中的入门程序“hello world”,在分布式计算领域,也有一个入门级的程序:“wordcount”,它需要解决的问题是:给定一个较大(可能是GB甚至TB级别)的文本数据集,如果统计出每个词在整个数据集中出现的总频率?该问题在数据量不大的情况下,可很容易通过单机程序解决。但当数据量达到一定程度后,必须采用分布式方式解决,一种可行的方案是分布式多线程:将数据按照文件切分后,分发到N太机器上,每台机器启动多个线程(map thread)统计给定文件中每个词出现的频率,之后在启动另外一些线程(成为reduce thread)统计每个词在所有文件中出现的总频率。该方案是可行的,但需要用户完成大量的开发工作,包括:
(1):数据切分
将输入文件切分成等大的小文件,分发到N台机器上,以便并行处理。
(2):数据传输
map thread产生的中间结果需要通过网络传输给reduce thread,以便进一步对局部统计结果进行汇总,产生全局结果。
(3):机器故障
机器故障是很常见的,需要设计一定的机制保证某台机器出现故障后,不会导致整个计算任务失败。
(4):扩展性
需要考虑系统扩展性问题,即当增加一批新机器后,整个计算过程如何能快速应用新增资源。
总之,我们实现分布式多线程的方法是可行的,但编程工作量极大,用户需要花费大量时间处理于应用程序逻辑无直接关系的分布式问题。为了简化分布式数据处理,MapReduce模型诞生了。
MapReduce模型是对大量分布式处理问题的总结和抽象,它的核心思想是分而治之,即将一个分布式计算过程拆解成两个阶段:
第一阶段:Map阶段
由多个可并行执行的Map Task构成,主要功能是,将待处理数据集按照数据量大小切分成等大的数据分片,每个分片交由一个任务处理。
第二阶段:Reduce阶段
由多个可并行执行的Reduce Task构成,主要功能是,对前一阶段中各任务产生的结果进行归约,得到最终结果。
MapReduce的出现,使得用户可以把主要精力放在设计数据处理算法上,至于其他的分布式问题,包括节点间的通信,节点失效,数据切分,任务并行化等,全部由MapReduce运行时环境完成,用户无需关心这些细节。以前面的wordcount为例,用户只需编写map()和reduce()两个函数,即可完成分布式程序的设计,这两个函数作用如下:
map()函数:
获取给定文件中一行字符串,对其分词后,依次输出这些单词。
reduce()函数:
将相同的词汇聚集在一起,统计每个词出现的总频率,并将结果输出。
以上两个函数于“回调函数”类似,MapReduce框架将在合适的时机主动调用它们,并处理与之相关的数据切片,数据读取,任务并行化等复杂问题。
四.MapReduce编程组件
为了简化程序设计,MapReduce首先对数据进行了建模。MapReduce将待处理数据划分成若干个InputSplit(简称split),它是一个基本计算单位。考虑到HDFS以固定大小的block(默认是128MB)为基本单位存储数据,split与block存在一定的对应关系,具体如下图所示。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始为止,数据长度,数据所在节点等。
split的划分方法完全受用用户程序控制,默认情况下,每个split对应一个block。但需要注意但是,split的多少决定了map task的数目,因为每个split会交由一个map task处理。
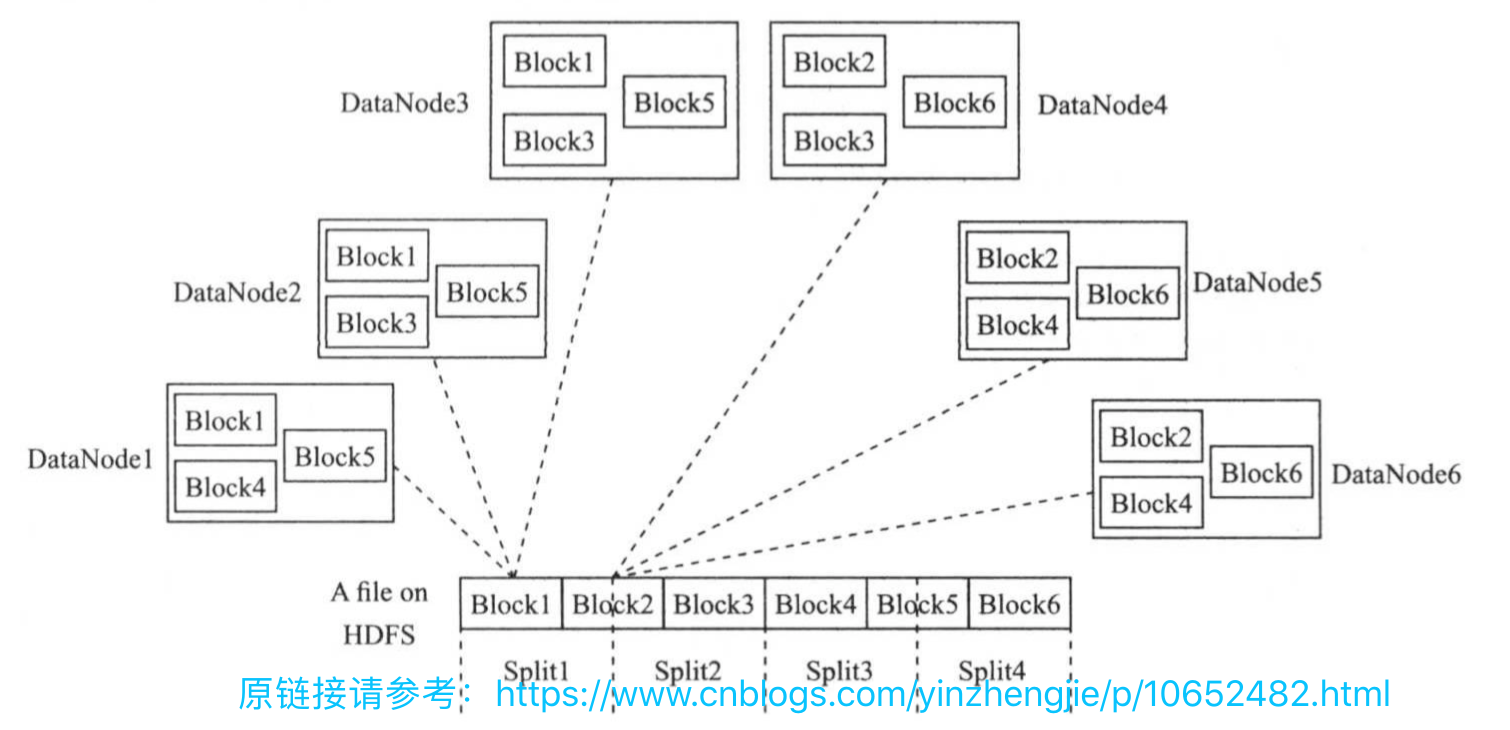
数据在MapReduce引擎中是以<key,value>形式流动的:首先,每个split中的数据会被转换成一些列<key,value>,交由用户的map()函数处理,该函数进一步产生另外一系列<key,value>,之后,经(按照key)排序分组后,交给用户编写的reduce()函数处理,最终产生结果。
总结起来,MapReduce编程模型实际上是一种包含5个步骤的分布式计算方法:
(1):迭代(iteration)遍历输入数据,并将之解析成<key,value>对。
(2):将输入<key,value>对映射(map)成为另外一些<key,vlaue>对。
(3):根据key对中间数据进行分组(grouping)。
(4):以组为单位对数据进行归约(reduce)
(5):迭代(iteration)将最终产生对<key,vlaue>保存到输出文件中。
MapReduce将计算过程分解成以上5个步骤带来的最大好处是组件化与并行化。为了实现MapReduce编程模型,Hadoop设计了一系列对外编程接口,用户可通过实现这些接口完成应用程序的开发。
Hadoop MapReduce对外提供了5个可编程组件,分别是InputFormat,Mapper,Partitioner,Reducer和OutputFormat,其中Mapper和Reducer跟应用程序逻辑相关,因此必须由用户编写(一个MapReduce程序可以只有Mapper没有Reducer),至于其他几个组件,MapReduce引擎内置了默认实现,如果这些默认实现能够满足用户需求,则可以直接使用。
1>.Mapper
Mapper中封装了应用程序的数据处理逻辑,为了简化接口,MapReduce要求所有存储在底层分布式文件系统上的数据均要解释成<key,value>的形式,并以迭代方式依次交给Mapper中的map函数处理,产生另外一些<kye,value>。
在MapReduce中,Mapper是一个基础类,它的主要定义如下:

从定义中可以看出,Mapper是一个模板类,它包含四个模板参数:前两个是输入key和value的数据类型,后两个是输出key和value的数据类型。
它内部包含了一系列方法,其中最重要的是map方法,它包含三个参数:
(1)输入的key
(2)输入的数值
(3)运行上下文对象,(可通过该对象获取当前执行环境信息,比如taskid,配置信息等。)
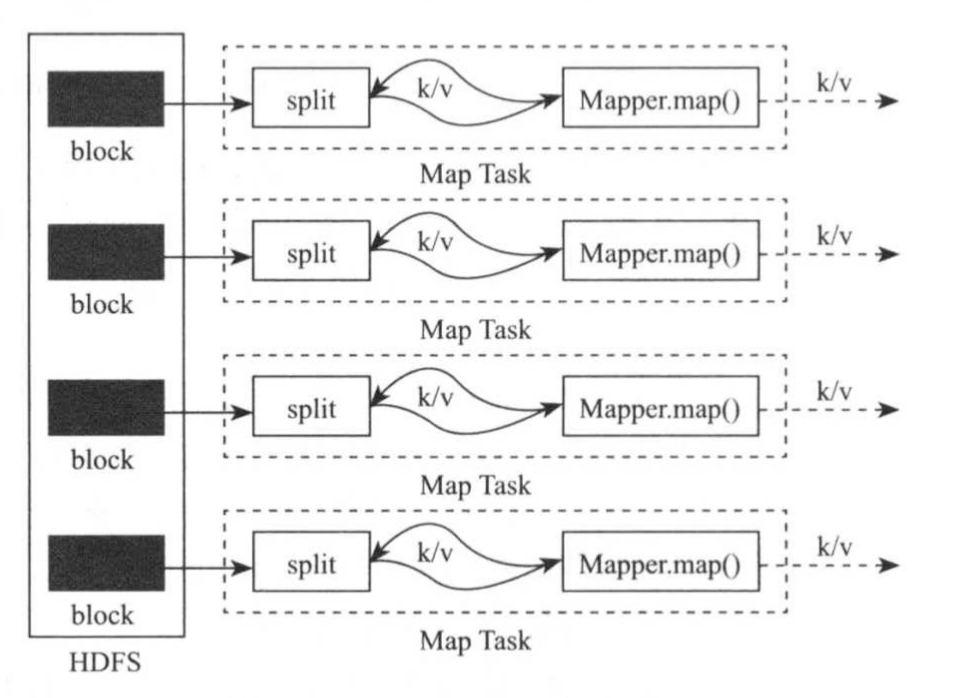
该函数会被多个Map Task并行调用,具体如下图所示。 在MapReduce中,key/value对象可能被写入磁盘,或者通过网络传输到不同机器上,因此他们必须是序列化的。为了简化用户开发量工作,MapReduce对常用的基本类型进行封装,使其变得可序列化,包括IntWritable,FloatWriteable,LongWriteable,BytesWriteable,Text等。用户可以通过集成Writeable类实现自己的可序列化类。
2>.Reducer
Reduce主要作用是,基于Mapper产生的结果进行归约操作,产生最终结果。Map 阶段产生的数据,按照key分片后,被远程拷贝给不同的Reduce Task。Reduce Task 按照key对其排序,进而产生一系列以key为划分单位的分组,它们迭代被Reduce函数处理,进而产生最终的<key,value>对。
与Mapper类似,Reducer是一个基础类,它的主要定义如下:

类似与Mapper,Reducer也是一个模板类,四个参数含义与Mapper一致,但需要注意的是,Reducer的输入key/value数据类型与Mapper的输出key/value数据类型一致的。
Reducer内部包含一系列方法,其中最重要的是reduce方法,它包含三个参数:
(1)输入key
(2)输入key锁对应的所有value
(3)运行上下文对象
该函数将被多个Reduce Task并行调用,具体如下图所示。
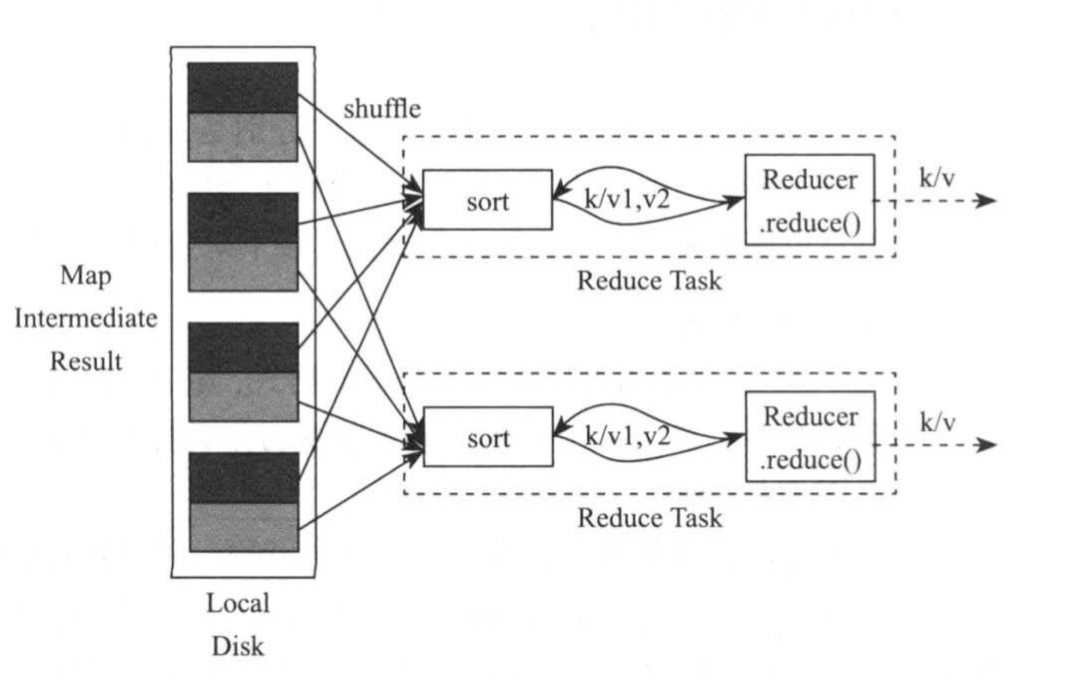
用户编写完MapReduce程序后,按照一定的规则指定程序的输入和输出目录,并提交到Hadoop集群中。作业在Hadoop中执行过程如下图所示,Hadoop会将输入数据到切分成若干个split,并将每个split交给一个Map Task处理。
Map Task以迭代的方式从对应的split中解析出一系列<key,value>,并调用map()函数处理。待数据处理完后,Reduce Task将启动多线程远程拷贝各自对应的数据,然后使用基于排序的方法将key相同的数据聚集在一起,并调用reduce()函数处理,将结果输出到文件中。
细心的同学可能注意到,上图的程序还缺少三个基本的组件,功能分别是:
()输入数据格式解析
解析输入文件的格式。将输入数据切分成若干个split,且将split解析成一系列<key,value>对。
()Map输出结果分片
确定map()函数产生的每对<key,value>发给哪个reduce()处理。
()输出数据格式转化
指定输出文件格式,即每个<key,value>对以何种形式保存到输出文件中。
在Hadoop MapReduce中,这三个组件分别是InputFormat,Partitioner和OutputFormat,他们均由用户根据实际应用需求设置,而对与上面的WordCount例子,Hadoop采用的默认实现正好可以满足要求,因而不必再提供。接下来分别介绍下这三个组件。
3>.InputFormat
InputFormat主要用于描述输入数据的格式,它提供以下两个功能:
()数据切片
按照某个策略将输入数据切分成若干个split,以便确定Map Task个数以及对应的split。
()我为Mapper提供输入数据
给定某个split,能够将其解析成一系列<key,value>对。
为了方便用户编写MapReduce程序,Hadoop自带了一些针对数据库和文件的InputFormat实现,具体如下图所示。通常而言,用户需要处理的数据均以文件形式存储在HDFS上,所以我们重点针对文件的InputFormat实现进行讨论。
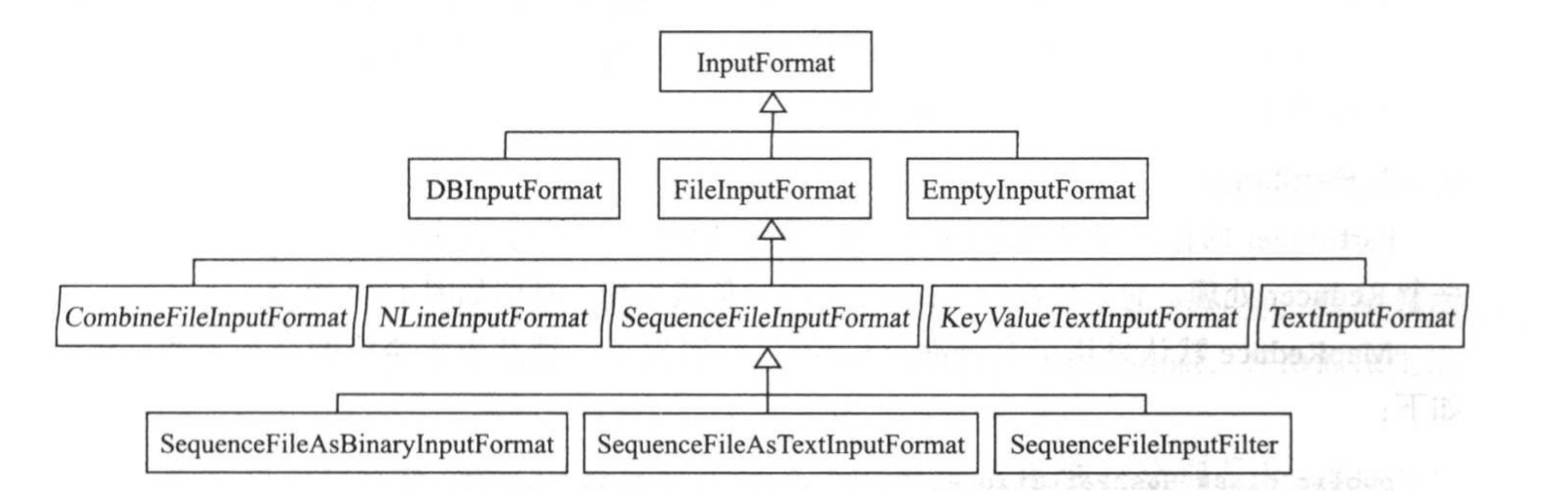
如上图所示,所有基于文件的InputFormat实现的基类是FileInputFormat,并由此派生出针对文本文件格式的TextInputFormat,KeyValueTextInputFormat和NLineInputFormat,针对二进制文件格式的SequenceFileInputFormat等。
整个基于文件的InputFormat体系的设计思路是,由公共基类FileInputFormat采用统一的方法对各种输入文件进行切分,比如按照某个固定大小等分,而由各个派生InputFormat自己提供机制进一步解析InputSplit。对应到具体的实现是,基类FileInputFormat提供getSplits实现,而派生类提供getRecoredReader实现。
接下来重点介绍两种常用的InputFormat:TextInputFormat和SequenceFileInputFormat。
(1)TextInputFormat
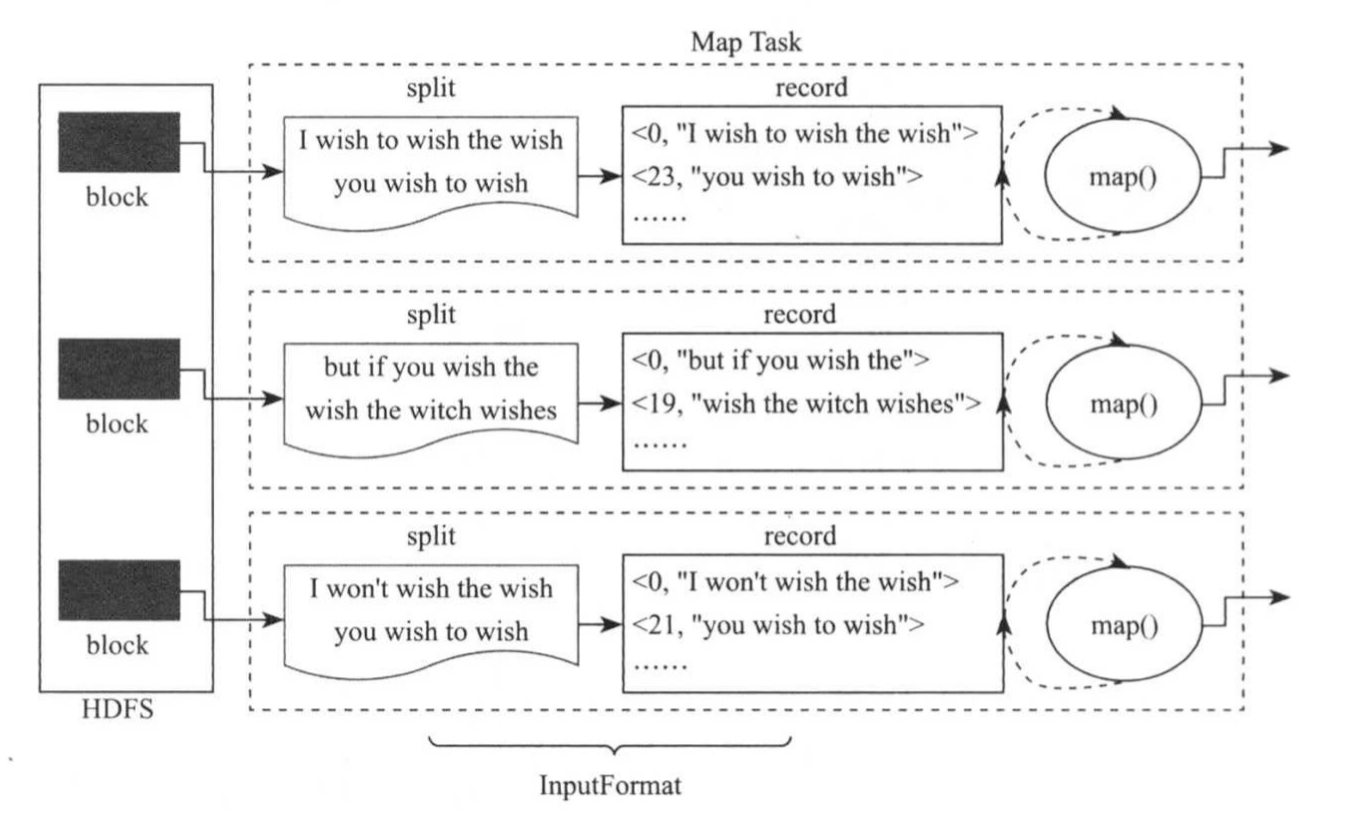
专门针对文本文件格式的InputFormat,它按照数据量大小将输入温和或目录切分成split,并以行为单位将split转换成一系列<key,value>对,其中key是当前行所在文件中的偏移量(通常在程序中不会使用),value是当前行的内容,具体如下图所示。
举个例子,如果一个存储在HDFS集群上的文件大小为1GB,则默认情况下TextInputFormat将其分成1024MB/128MB=8个split,进而启动8个Map Task处理;如果一个目录下有10个文本文件,每个文本文件大小为10MB(在HDFS中,每个文件单独存成一个block),则TextInputFormat将其分成10个split。
(2)SequenceFileInputFormat
专门针对二进制文件格式大的InputFormat,以key/value方式组织数据,其中key和value均可以是任意二进制数据,它按照数据量大小将输入文件或目录切分成split,并进一步将split拆分成一系列<key,value>对
4>.Partitioner
Partitioner的作用是对Mapper产生的中间结果进行分片,以便将同一组的数据交给同一个Reducer处理,它直接影响Reduce阶段的负载均衡,具体如下图所示。
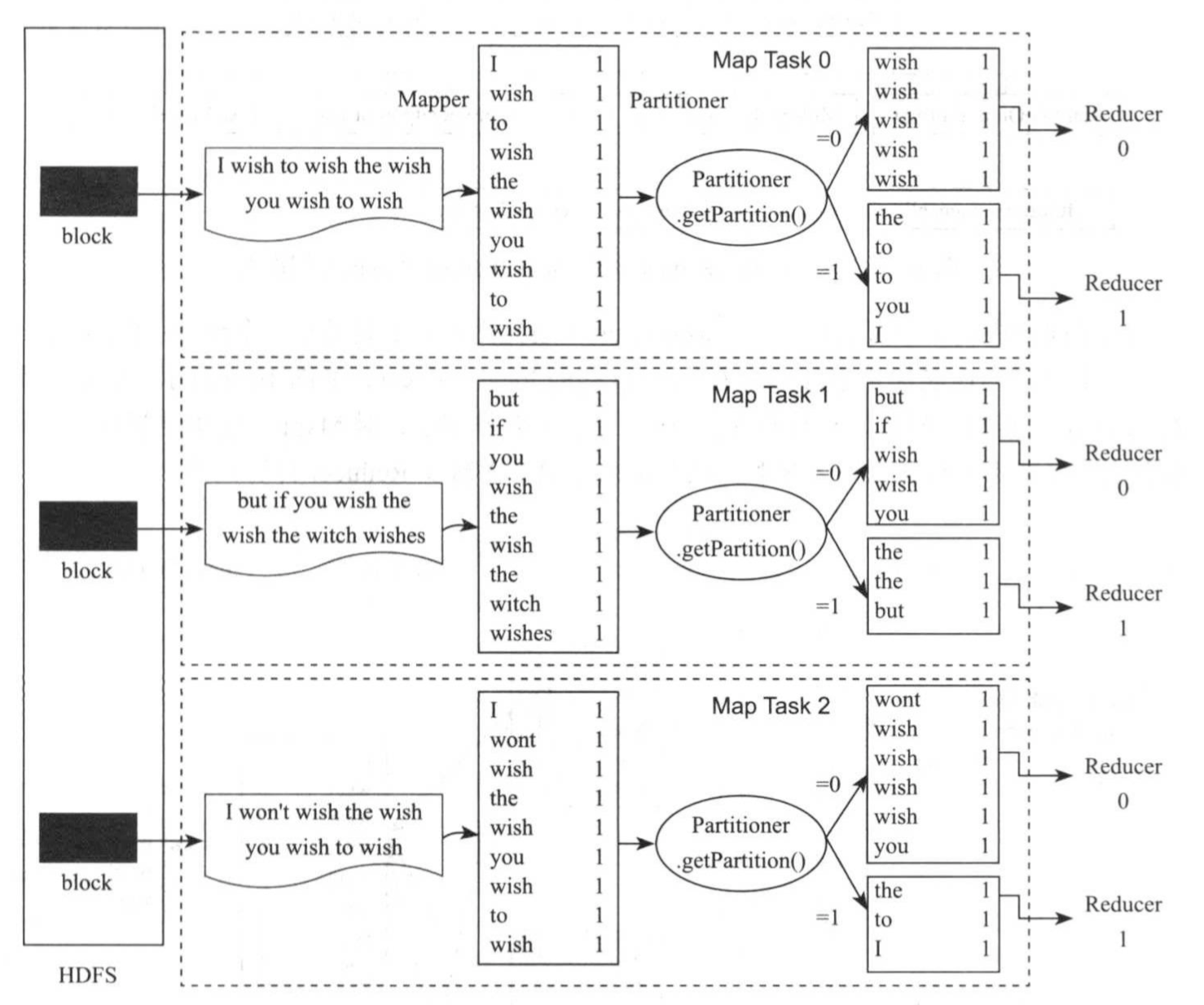
MapReduce默认采用了HashPartitioner,它实现了一种基于哈希值的分片方法,代码如下:

HashPartitioner能够将key相同的所有<key,value>交给同一个Reduce Task处理,适用于绝大部分应用场景,比如WordCount。用户也可以按照自己的需求定制Partitioner。
5>.OutputFormat
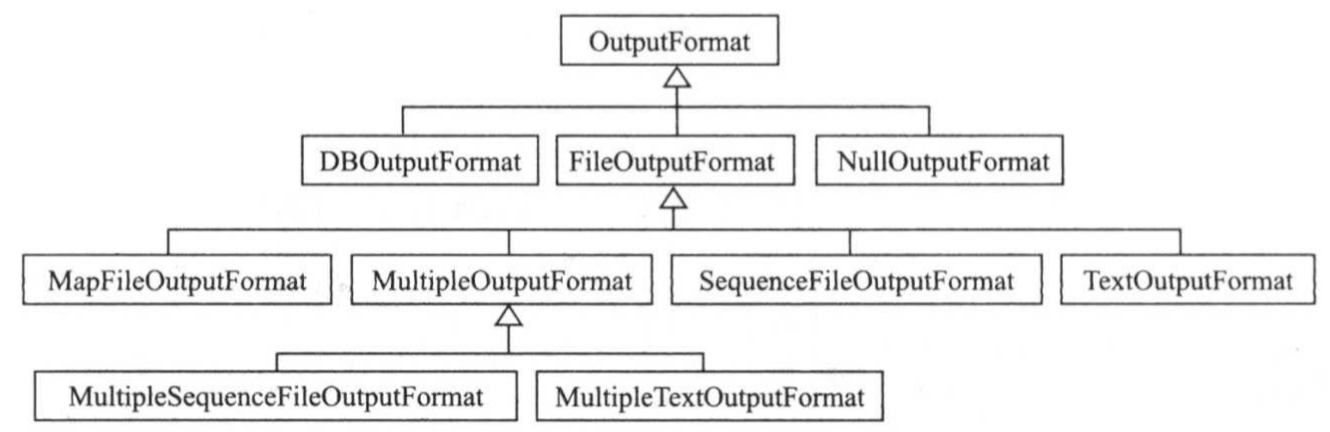
OutputFormat主要用于描述输出数据的格式,它能够将用户提供key/value对写入特定格式的文件中。
Hadoop自带了很多OutputFormat实现,他们与InputFormat实现想对应,具体如下图所示,所有基于文件的OutputFormat实现的基类为FileOutputFormat,并由此派生出一些基于文本文件格式,二进制文本格式的或者多输出的实现。
综上所属,Hadoop MapReduce对外提供了5个可编程组件,分别是InputFormat,Mapper,Partitioner,Reducer和OutputFormat,用户可根据自己的应用需求定制这些组件。
除了前面说的5个可编程组件,MapReduce还允许用户定制另外一个组件:Combiner,它是一个可选的性能优化组件,可看作Map端的local reducer,如下图所示,它通常跟Reducer的逻辑是一样的,运行在Map Task中,主要作用是,对Mapper输出结果做一个局部聚集,以减少本地磁盘写入量和网络数据传输量,并减少Reducer计算压力。

五.批处理引擎MapReduce程序设计
详情请参考:https://www.cnblogs.com/yinzhengjie/p/10780538.html。
六.批处理引擎MapReduce内部原理
详情请参考:https://www.cnblogs.com/yinzhengjie/p/10787968.html。
七.批处理引擎MapReduce应用案例
详情请参考:https://www.cnblogs.com/yinzhengjie/p/10793758.html。
批处理引擎MapReduce编程模型的更多相关文章
- 批处理引擎MapReduce内部原理
批处理引擎MapReduce内部原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce作业生命周期 MapReduce作业作为一种分布式应用程序,可直接运行在H ...
- 批处理引擎MapReduce程序设计
批处理引擎MapReduce程序设计 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce API Hadoop同时提供了新旧两套MapReduce API,新AP ...
- mapreduce编程模型你知道多少?
上次新霸哥给大家介绍了一些hadoop的相关知识,发现大家对hadoop有了一定的了解,但是还有很多的朋友对mapreduce很模糊,下面新霸哥将带你共同学习mapreduce编程模型. mapred ...
- MapReduce 编程模型
一.简单介绍 1.MapReduce 应用广泛的原因之中的一个在于它的易用性.它提供了一个因高度抽象化而变得异常简单的编程模型. 2.从MapReduce 自身的命名特点能够看出,MapReduce ...
- MapReduce编程模型详解(基于Windows平台Eclipse)
本文基于Windows平台Eclipse,以使用MapReduce编程模型统计文本文件中相同单词的个数来详述了整个编程流程及需要注意的地方.不当之处还请留言指出. 前期准备 hadoop集群的搭建 编 ...
- MapReduce编程模型简介和总结
MapReduce应用广泛的原因之一就是其易用性,提供了一个高度抽象化而变得非常简单的编程模型,它是在总结大量应用的共同特点的基础上抽象出来的分布式计算框架,在其编程模型中,任务可以被分解成相互独立的 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- [转]Hadoop集群_WordCount运行详解--MapReduce编程模型
Hadoop集群_WordCount运行详解--MapReduce编程模型 下面这篇文章写得非常好,有利于初学mapreduce的入门 http://www.nosqldb.cn/1369099810 ...
- MapReduce 编程模型概述
MapReduce 编程模型给出了其分布式编程方法,共分 5 个步骤:1) 迭代(iteration).遍历输入数据, 并将之解析成 key/value 对.2) 将输入 key/value 对映射( ...
随机推荐
- haproxy2.0入门部署教程
测试后发现,haproxy2.0和之前的版本部署有些许差异,配置文件的写法也是不同的 测试环境:Centos7.3 IP:172.16.1.227 172.16.1.228 部署httpd,页面内容为 ...
- [LeetCode] 548. Split Array with Equal Sum 分割数组成和相同的子数组
Given an array with n integers, you need to find if there are triplets (i, j, k) which satisfies fol ...
- 【Linux】僵尸进程,孤儿进程以及wait函数,waitpid函数(有样例,分析很详细)
本文内容: 1.僵尸进程,孤儿进程的定义,区别,产生原因,处理方法 2.wait函数,waitpid函数的分析,以及比较 背景:由于子进程的结束和父进程的运行是一个异步的过程,即父进程永远无法预测子进 ...
- Docker部署ELK 7.0.1集群之Logstash安装介绍
1.下载镜像 [root@vanje-dev01 ~]# docker pull logstash: 2.安装部署 2.1 创建宿主映射目录 [root@vanje-dev01 ~]# mkdir ...
- BZOJ3791 作业(DP)
题意: 给出一个长度为n的01序列: 你可以进行K次操作,操作有两种: 1.将一个区间的所有1作业写对,并且将0作业写错: 2.将一个区间的所有0作业写对,并且将1作业写错: 求K次操作后最多写对了多 ...
- 路由Routers
路由Routers 对于视图集ViewSet,我们除了可以自己手动指明请求方式与动作action之间的对应关系外,还可以使用Routers来帮助我们快速实现路由信息. REST framework提供 ...
- 少儿编程|Scratch编程教程系列合集,总有一款适合你
如果觉得资源不错,友情转发,贵在分享!!! 少儿编程Scratch: 少儿编程Scratch第一讲:Scratch完美的初体验少儿编程Scratch第二讲:奇妙的接球小游戏少儿编程Scratch第三讲 ...
- PowerBuilder中pbm_keydown()和pbm_dwnkey()的区别:
原地址:https://vcoo.cc/blog/463/ PowerBuilder开发中我们经常会用到快捷键的事件编程,在PB中的键盘事件主要用三个:pbm_dwnkey.pbm_keydown.p ...
- 创建包含CRUD操作的Web API接口-第一部
在这里,我们将创建一个新的Web API项目,它将使用实体框架实现Get,POST.PUT和DELETE方法来实现CRUD操作. 首先,在Visual Studio 2013 for Web expr ...
- org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): 错误解决
报错信息:org.apache.ibatis.binding.BindingException: Invalid bound statement (not found) 说明:这段报错信息表示 Map ...