web端自动化——selenium项目集成HTML测试报告
参考内容:
虫师:《selenium2自动化测试实战——基于python语言》
PS:书中的代码,只能做参考,最好还是自己码一码,不一定照搬就全是对的,实践出真知。。。
随着软件不断迭代功能越来越多,对应的测试用例也会呈指数增长。一个实现几十个功能的项目,对应的用例可能有上百个甚至更多,如果全部集成在一个文件中,那么这个文件就很臃肿且维护麻烦。
一个很好的方法就是将这些用例按照功能类型进行拆分,分散到不同测试文件中,即一个项目,对应多个分支。
前言:
HTML测试报告
对软件测试人员来讲,测试的产出很难衡量。换句话说,测试人员的价值比较难以量化和评估,相信这一点对软件测试人员来说深有体会。我们花费了很多时间与精力所做的自动化测试也是如此。所以,需要一份漂亮且通俗易懂的测试报告来展示自动化测试成果。显然,一个简单的Log文件是不够的。
HTMLTestRunner是Python标准库unittest单元测试框架的一个扩展,它生成易于使用的HTML测试报告。HTMLTestRunner是在BSD许可证下发布的。
下载地址如下:
http://tungwaiyip.info/software/HTMLTestRunner.html
这个扩展非常简单,只有一个HTMLTestRunner.py文件,选中后单击鼠标右键,在弹出的快捷菜单中选择链接另存为,将它保存到本地。安装方法也很简单,将其复制到Python安装目录下即可。
Windows:将下载的文件保存到...\Python\Lib目录下。
1.1 修改HTMLTestRunner
因为HTMLTestRunner.py是基于Python 2开发的,为了使其支持Python 3的环境,需要对其中的部分内容进行修改。下面通过编辑器打开HTMLTestRmmer.py文件。
#94行
import StringIO
修改为
import io
#539行
self.outputBuffer = StringIO.StringIO ()
修改为:
self.outputBuffer = io.StringIO()
#631行
print >>sys.stderr,'\nTime Elapsed: %s'(self.stopTime-self.startTime)
修改为:
print(sys.stderr,'\nTime Elapsed: %s'(self.stopTime-self.startTime))
#642行
if not rmap.has_key(cls):
修改为:
if not cls in rmap:
#766行
uo = o.decode('latin-1')
修改为: uo = e
#772行
ue = e.decode('latin-1')
修改为:
ue = e
一、分拆后的实现代码(***实例)
在pycharm中新建如下目录:
test_baidu.py代码如下:
from selenium import webdriver
import unittest
from time import * class MyDriver(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.base_url = "https://www.baidu.com/"
def test_baidu(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_id("kw").send_keys("HTMLTestRunner")
driver.find_element_by_id("su").click()
sleep(3)
title = driver.title
self.assertEqual(title,'HTMLTestRunner_百度搜索')
def tearDown(self):
self.driver.quit()
if __name__ == "__main__":
unittest.main()
test_youdao.py代码如下:
from selenium import webdriver
import unittest #导入单元测试框架
from time import * class MyDriver(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.base_url = "http://www.youdao.com/"
def test_youdao(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_xpath(".//*[@id='translateContent']").clear()
driver.find_element_by_xpath(".//*[@id='translateContent']").send_keys("webdriver")
driver.find_element_by_xpath(".//*[@id='form']/button").click()
sleep(2)
title = driver.title
self.assertEqual(title,'【webdriver】什么意思_英语webdriver的翻译_音标_读音_用法_例句_在线翻译_有道词典')
def tearDown(self):
self.driver.quit()
if __name__ == "__main__":
unittest.main()
HtmlReport.py代码如下:
import unittest
import time
from HTMLTestRunner import HTMLTestRunner#将HTMLTestRunner模块导入
#指定测试用例为当前文件夹的test_case目录
test_dir='./test_case'
discover=unittest.defaultTestLoader.discover(test_dir,pattern='test*.py')
if __name__=='__main__':
#按照一定格式获取当前时间
now=time.strftime("%Y-%m-%d %H-%M-%S")
filename=test_dir+'./'+now+'result.html'
#通过open()方法以二进制写模式打开当前目录下的result.html,如果没有,则自动创建该文件。
fp=open (filename,'wb')
#定义测试报告:stream指定测试报告文件, title用于定义测试报告的标题,description用于定义测试报告的副标题。
runner=HTMLTestRunner(stream=fp,title='百度搜索测试报告',description='用例测试执行情况:')
# 运行项目组装的用例
runner.run(discover)
# 关闭报告文件
fp.close()
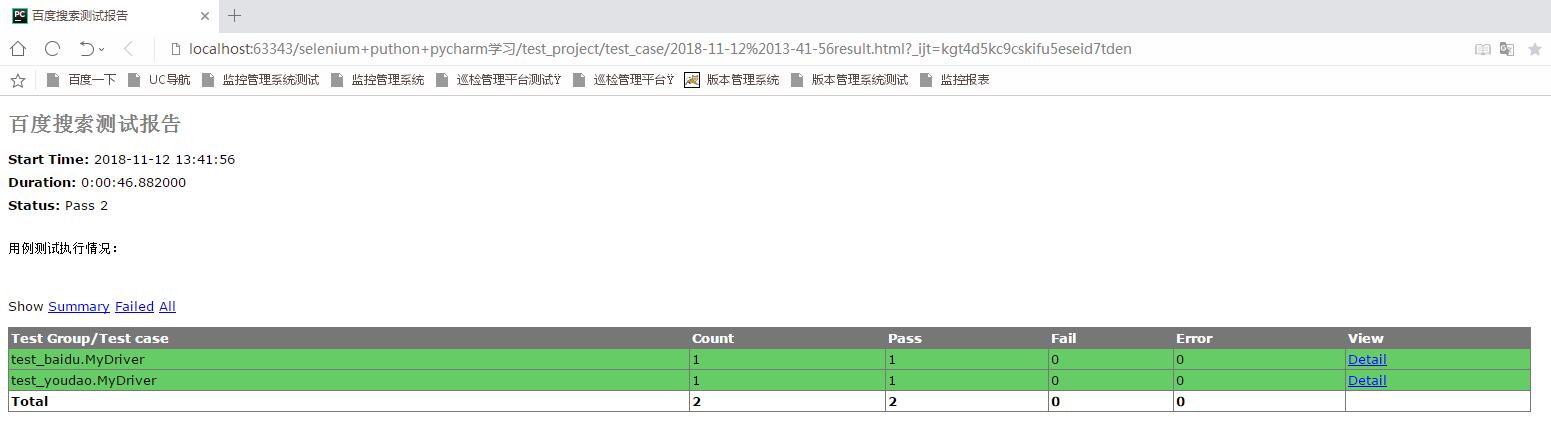
备注:运行上面HtmlReport.py代码,会在test_case目录下生成2018-11-12 13-41-56result.html的测试报告,使用浏览器打开如下图所示:
web端自动化——selenium项目集成HTML测试报告的更多相关文章
- web端自动化——selenium测试报告生成、找到测试报告路径、实现发邮件(整合)
有这样的一个场景: 假设生成的测试报告与多人相关,每个人都去测试服务器査看就会比较麻烦,如果把这种主动的且不及时的査看变成被动且及时的査收,就方便多了. 整个程序的执行过程可以分为三个步骤: ① ...
- web端自动化——selenium Page Object设计模式
Page Object设计模式的优点如下: ① 减少代码的重复. ② 提高测试用例的可读性. ③ 提高测试用例的可维护性,特别是针对UI频繁变化的项目. 当为Web页面编写测试时,需 ...
- web端自动化——Selenium Grid原理
利用Selenium Grid可以在不同的主机上建立主节点(hub)和分支节点(node),可以使主节点上的测试用例在不同的分支节点上运行. 对不同的节点来说,可以搭建不同的测试环境(操作系统.浏 ...
- web端自动化——Selenium Server环境配置
Selenium Server环境配置 下面下载.配置并运行Selenium Server. ① 下载 Selenium Server. 下载地址为:https://pypi.python.or ...
- 接口自动化、移动端、web端自动化如何做?
1.<Python+Appium移动端自动化项目实战>-带您进入APP自动化测试的世界https://yuedu.baidu.com/ebook/765b38a5690203d8ce2f0 ...
- 使用Selenium+Java+Juint实现移动web端自动化的代码实现
浏览器: Chrome 首先通过developer模式查看Chrome浏览器支持哪些手机,如图: 在代码中使用ChromeOptions对象的addArguments方法来设置参数,如下代码所示: p ...
- web端自动化——自动化测试准备工作
准备工作# 在开始自己项目的自动化测试之前,我们最好已经完成了下面的准备工作: 1.熟悉待测系统 对项目的待测系统整体功能和业务逻辑有比较清晰的认识. 2.编写系统的自动化测试用例大纲和自动化测试用例 ...
- web端自动化——Selenium3+python自动化(3.7版本)-火狐62版本环境搭建
前言 目前selenium版本已经升级到3.0了,网上的大部分教程是基于2.0写的,所以在学习前先要弄清楚版本号,这点非常重要.本系列依然以selenium3为基础. 一.selenium简介 Sel ...
- web端自动化——Selenium3+python自动化(3.7版本)-chrome67环境搭建
前言 目前selenium版本已经升级到3.0了,网上的大部分教程是基于2.0写的,所以在学习前先要弄清楚版本号,这点非常重要.本系列依然以selenium3为基础. 一.selenium简介 Sel ...
随机推荐
- am335x system upgrade rootfs for bridge-utils cross compile (十四)
bridge-utils移植 [目的] 移植bridge-utils的目是在AM335X开发板上使用bridge功能. [环境] 1. Ubuntu 16.04发行版 2. MC183平台 3. ...
- 关灯问题II 状压DP
关灯问题II 状压DP \(n\)个灯,\(m\)个按钮,每个按钮都会对每个灯有不同影响,问最少多少次使灯熄完. \(n\le 10,m\le 100\) 状压DP的好题,体现了状压的基本套路与二进制 ...
- 洛谷 P2058 海港 题解
P2058 海港 题目描述 小K是一个海港的海关工作人员,每天都有许多船只到达海港,船上通常有很多来自不同国家的乘客. 小K对这些到达海港的船只非常感兴趣,他按照时间记录下了到达海港的每一艘船只情况: ...
- Windows下 Python 2 与 Python 3 共存
转自:http://lovenight.github.io/2016/09/27/Windows%E4%B8%8B-Python-2-%E4%B8%8E-Python-3-%E5%85%B1%E5%A ...
- linux 使用yum安装mysql详细步骤
环境:Centos 6.5 Linux 使用yum命令安装mysql 1. 先检查系统是否装有mysql [root@localhost ~]#yum list installed mysql* [r ...
- vue+vue-resource设置请求头(带上token)
前言 有这样的一个需求,后台服务器要求把token放在请求头里面 嗯一般是通过data里面通过参数带过去的 第一种方法 全局改变: Vue.http.headers.common['token'] = ...
- 2019软工实践_Alpha(3/6)
队名:955 组长博客:https://www.cnblogs.com/cclong/p/11872693.html 作业博客:https://edu.cnblogs.com/campus/fzu/S ...
- openssl从内存中读取私钥进行签名
麻痹的找了好久,真恶心! #include <stdio.h> #include <stdlib.h> #ifdef WIN32 #include <windows.h& ...
- 解决无法将java项目部署到tomcat中去
project facets java转成web项目 用Eclipse开发项目的时候,把一个Web项目导入到Eclipse里会变成了一个Java工程,将无法在Tomcat中进行部署运行. 方法: 1. ...
- MySQL参数: innodb_flush_log_at_trx_commit和sync_binlog
innodb_flush_log_at_trx_commit 当innodb_flush_log_at_trx_commit=0时, log buffer将每秒一次地写入log file, 并且log ...