Spark2.x(六十一):在Spark2.4 Structured Streaming中Dataset是如何执行加载数据源的?
本章主要讨论,在Spark2.4 Structured Streaming读取kafka数据源时,kafka的topic数据是如何被执行的过程进行分析。
以下边例子展开分析:
SparkSession sparkSession = SparkSession.builder().getOrCreate();
Dataset<Row> sourceDataset = sparkSession.readStream().format("kafka").option("", "").load(); sourceDataset.createOrReplaceTempView("tv_test");
Dataset<Row> aggResultDataset = sparkSession.sql("select ...."); StreamingQuery query = aggResultDataset.writeStream().format("kafka").option("", "")
.trigger(Trigger.Continuous(1000))
.start();
try {
query.awaitTermination();
} catch (StreamingQueryException e1) {
e1.printStackTrace();
}
上边例子业务,使用structured streaming读取kafka的topic,并做agg,然后sink到kafka的另外一个topic上。
DataSourceReader#load方法
要分析DataSourceReader#load方法返回的DataSet的处理过程,需要对DataSourceReader的load方法进行分析,下边这个截图就是DataSourceReader#load的核心代码。
在分析之前,我们来了解一下测试结果:
package com.boco.broadcast
trait MicroBatchReadSupport {
}
trait ContinuousReadSupport {
}
trait DataSourceRegister {
def shortName(): String
}
class KafkaSourceProvider extends DataSourceRegister
with MicroBatchReadSupport
with ContinuousReadSupport{
override def shortName(): String = "kafka"
}
object KafkaSourceProvider{
def main(args:Array[String]):Unit={
val ds=classOf[KafkaSourceProvider].newInstance()
ds match {
case s: MicroBatchReadSupport =>
println("MicroBatchReadSupport")
case s:ContinuousReadSupport=>
println("ContinuousReadSupport")
}
}
}
上边这个执行结果时只会执行输出“MicroBatchReadSupport”,永远走不到ConitnuousReadSupport match分支,后边会单独介绍这个事情。。。
带着这个测试结果,我们分析DataSourceReader的load方法代码:
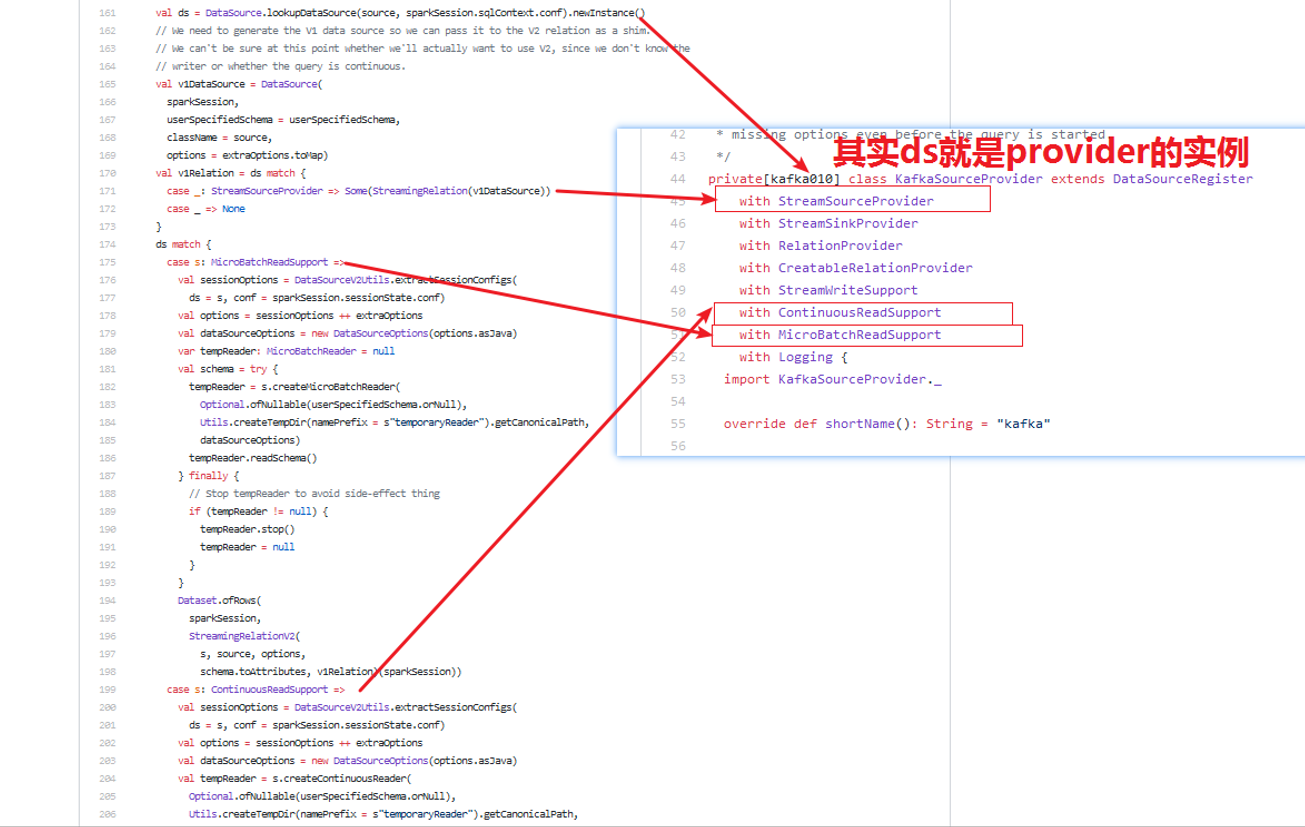
1)经过上篇文章《Spark2.x(六十):在Structured Streaming流处理中是如何查找kafka的DataSourceProvider?》分析,我们知道DataSource.lookupDataSource()方法,返回的是KafkaSourceProvider类,那么ds就是KafkaSourceProvider的实例对象;
2)从上边截图我们可以清楚的知道KafkaSourceProvider(https://github.com/apache/spark/blob/master/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSourceProvider.scala)的定义继承了DataSourceRegister,StreamSourceProvider,StreamSinkProvider,RelationProvider,CreatableRelationProvider,StreamWriteProvider,ContinuousReadSupport,MicroBatchReadSupport等接口
3) v1DataSource是DataSource类,那么我们来分析DataSource初始化都做了什么事情。
// We need to generate the V1 data source so we can pass it to the V2 relation as a shim.
// We can't be sure at this point whether we'll actually want to use V2, since we don't know the
// writer or whether the query is continuous. val v1DataSource = DataSource(
sparkSession,
userSpecifiedSchema = userSpecifiedSchema,
className = source,
options = extraOptions.toMap)
在DataSource初始化做的事情只有这些,并未加载数据。
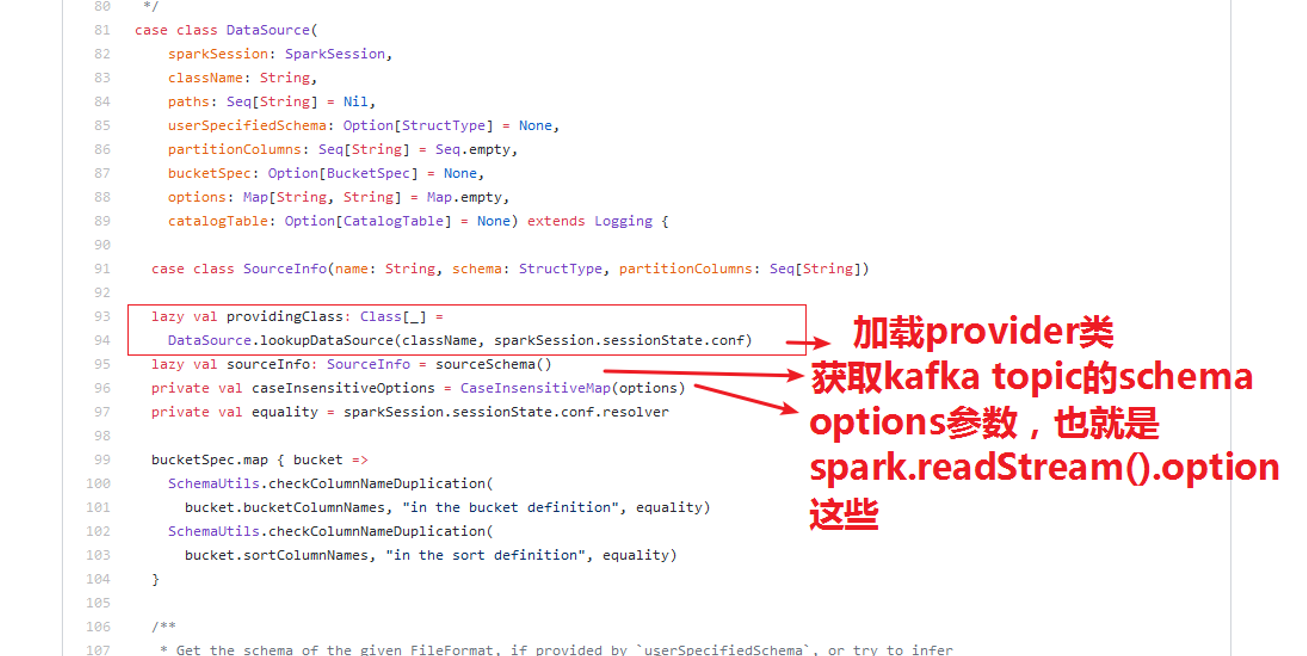
1)调用object DataSource.loopupDataSource加载provider class;
2)获取kafka的topic的schema;
3)保存option参数,也就是sparkSession.readStream().option相关参数;
4)获取sparkSession属性。
DataSource#sourceSchema()方法:
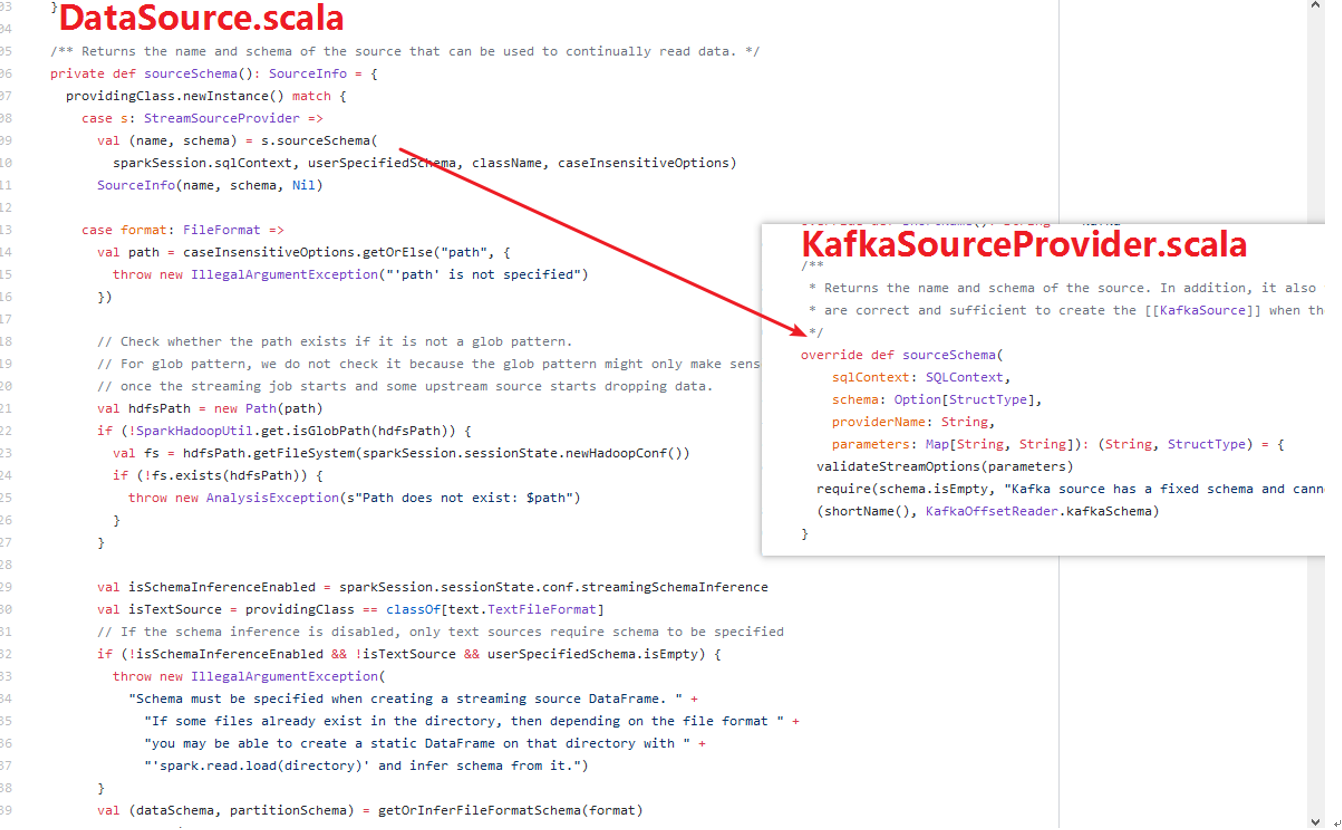
1)DataSource#sourceSchema方法内部调用KafkaSourceProvider的#sourceShema(。。。);
2)KafkaSourceProvider#sourceSchema返回了Map,(key:shourName(),value:KafkaOffsetReader.kafkaSchema)。
在DataSource的sourceSchema方法下边包含:
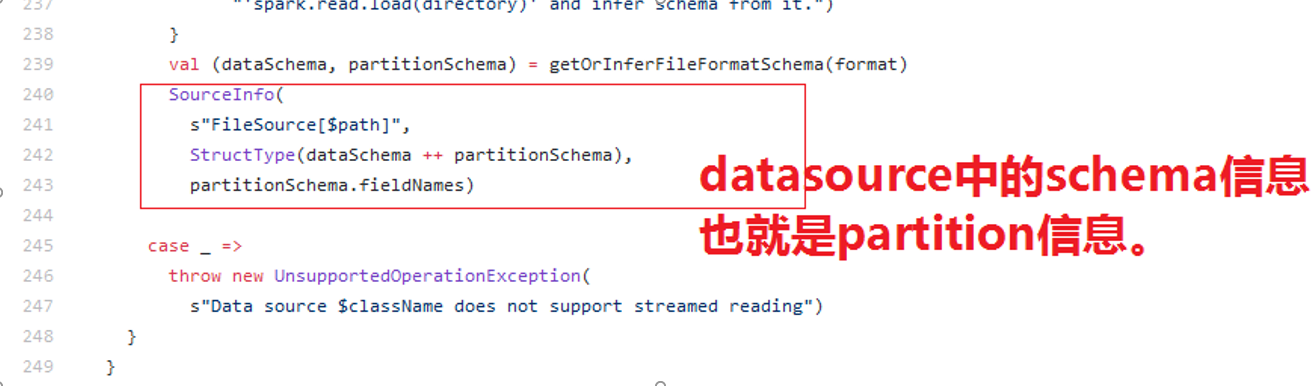
在KafkaOffsetReader中返回的schema信息包含:

代码分析到这里并未加载数据。
ds就是provider实例,
v1DataSource是实际上就是包含source的provider,source的属性(spark.readeStream.option这些参数[topic,maxOffsetsSize等等]),source的schema的,它本身是一个数据描述类。
ds支持MicroBatchReadSupport与ContinuousReadSuuport的分支:

两个主要区别还是在tempReader的区别:
MicroBatchReadSupport:使用KafkaSourceProvider的createMicroBatchReader生成KafkaMicroBatchReader对象;
ContinuousReadSuuport:使用KafkaSourceProvider的createContinuousReader生成KafkaContinuousReader对象。
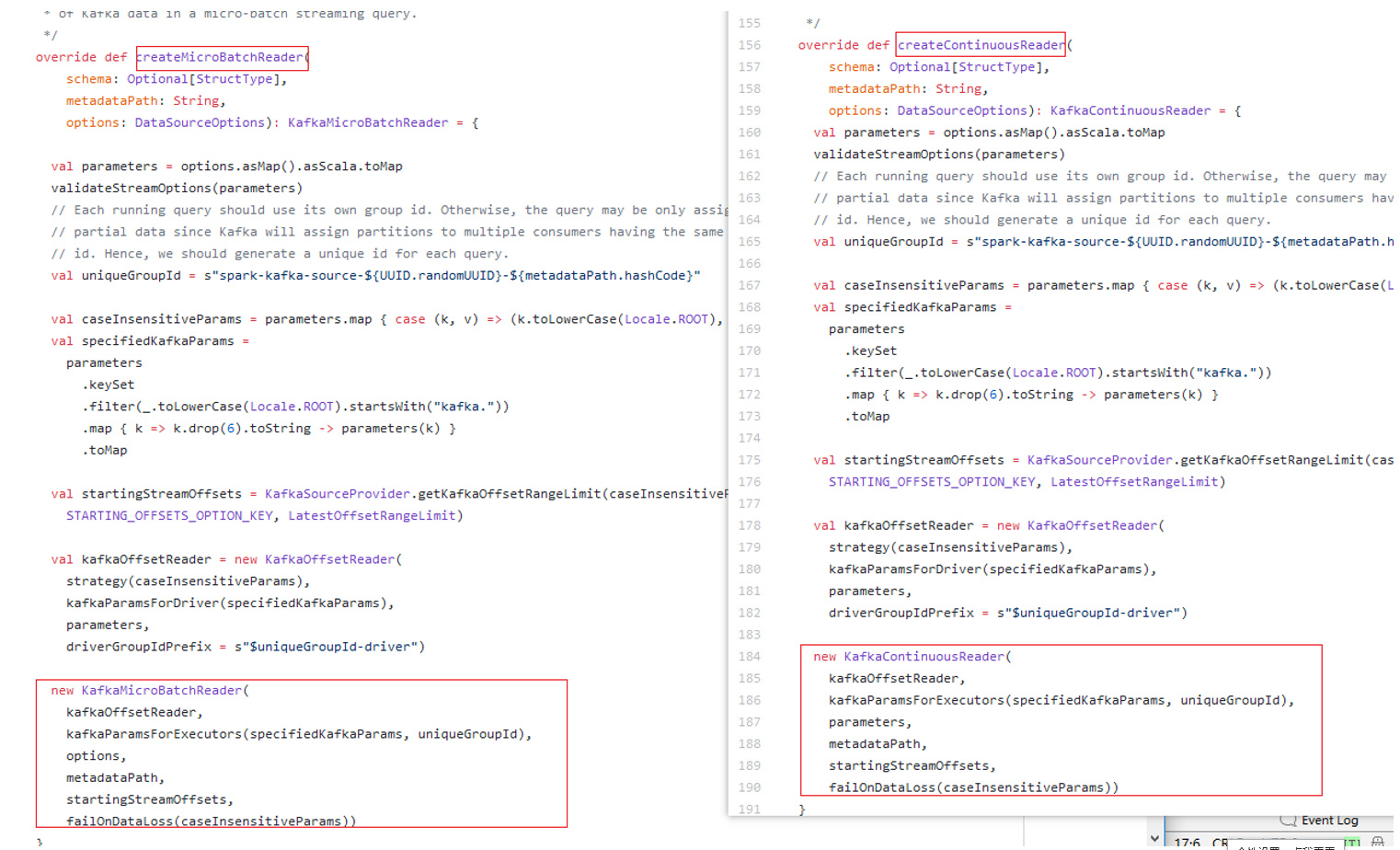
DataSourceReader的format为kafka时,执行的ds match分支分析
测试代码1:
package com.boco.broadcast import java.util.concurrent.TimeUnit
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import org.apache.spark.sql.{Row, SparkSession} object TestContinuous {
def main(args:Array[String]):Unit={
val spark=SparkSession.builder().appName("test").master("local[*]").getOrCreate()
val source= spark.readStream.format("kafka")
.option("subscribe", "test")
.option("startingOffsets", "earliest")
.option("kafka.bootstrap.servers","localhost:9092")
.option("failOnDataLoss",true)
.option("retries",2)
.option("session.timeout.ms",3000)
.option("fetch.max.wait.ms",500)
.option("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
.option("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
.load() source.createOrReplaceTempView("tv_test")
val aggResult=spark.sql("select * from tv_test")
val query=aggResult.writeStream
.format("csv")
.option("path","E:\\test\\testdd")
.option("checkpointLocation","E:\\test\\checkpoint")
.trigger(Trigger.Continuous(5,TimeUnit.MINUTES))
.outputMode(OutputMode.Append())
.start()
query.awaitTermination()
}
}
测试代码2:
package com.boco.broadcast import java.util.concurrent.TimeUnit
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import org.apache.spark.sql.{Row, SparkSession} object TestContinuous {
def main(args:Array[String]):Unit={
val spark=SparkSession.builder().appName("test").master("local[*]").getOrCreate()
val source= spark.readStream.format("kafka")
.option("subscribe", "test")
.option("startingOffsets", "earliest")
.option("kafka.bootstrap.servers","localhost:9092")
.option("failOnDataLoss",true)
.option("retries",2)
.option("session.timeout.ms",3000)
.option("fetch.max.wait.ms",500)
.option("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
.option("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
.load()
source.createOrReplaceTempView("tv_test") val aggResult=spark.sql("select * from tv_test")
val query=aggResult.writeStream
.format("kafka")
.option("subscribe", "test_sink")
.option("checkpointLocation","E:\\test\\checkpoint")
.trigger(Trigger.Continuous(5,TimeUnit.MINUTES))
.outputMode(OutputMode.Append())
.start()
query.awaitTermination()
}
}
测试代码的Pom文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.boco.broadcast.test</groupId>
<artifactId>broadcast_test</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.12</scala.version>
<spark.version>2.4.0</spark.version>
</properties> <repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories> <pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories> <dependencies>
<!--Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<!--Scala --> <!--Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.0</version>
</dependency>
<!--Spark --> <dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
调试结果:
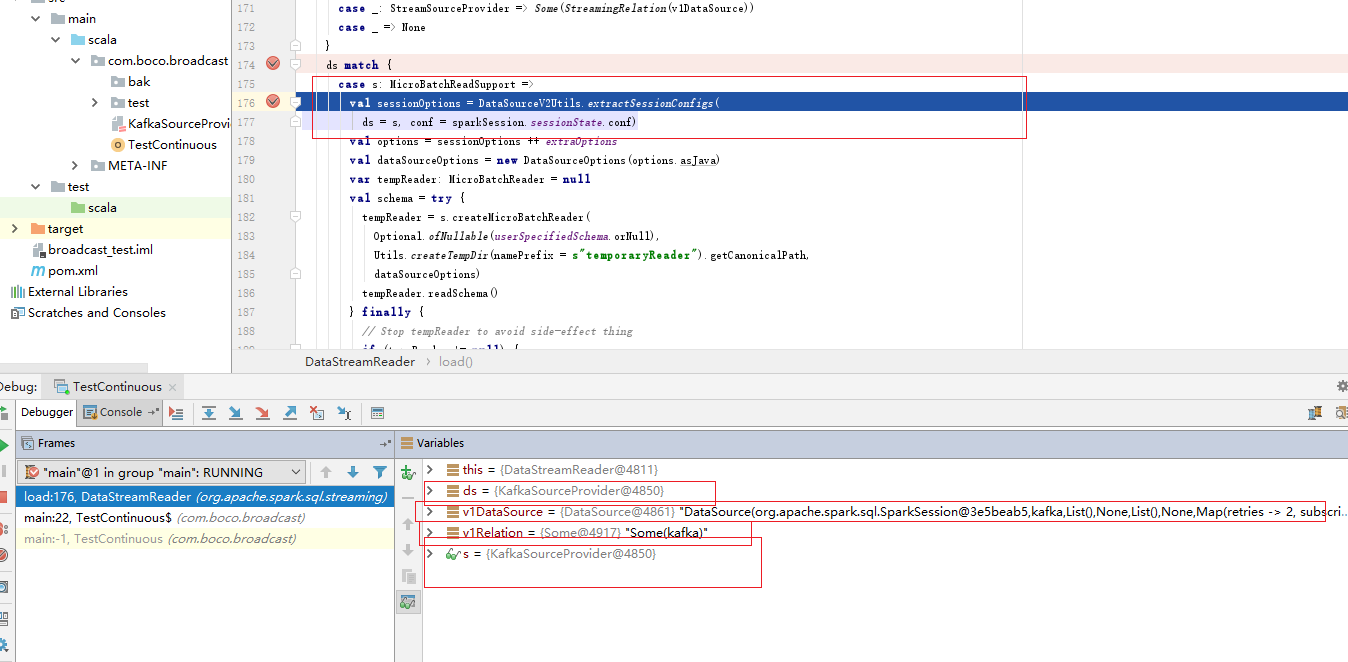
不管是执行“测试代码1” ,还是执行“测试代码2”,ds match的结果一样,都是只走case MicroBatchReadSupport分支,这里一个疑问:
为什么在Trigger是Continous方式时,读取kafka topic数据源采用的是“KafkaMicroBatchReader”,而不是“KafkaContinuousReader”?
DataSourceReader#load返回Dataset是一个LogicPlan
但是最终都被包装为StreamingRelationV2 extends LeafNode (logicPlan)传递给Dataset,Dataset在加载数据时,执行的就是这个logicplan
package org.apache.spark.sql.execution.streaming import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.analysis.MultiInstanceRelation
import org.apache.spark.sql.catalyst.expressions.Attribute
import org.apache.spark.sql.catalyst.plans.logical.{LeafNode, LogicalPlan, Statistics}
import org.apache.spark.sql.execution.LeafExecNode
import org.apache.spark.sql.execution.datasources.DataSource
import org.apache.spark.sql.sources.v2.{ContinuousReadSupport, DataSourceV2} object StreamingRelation {
def apply(dataSource: DataSource): StreamingRelation = {
StreamingRelation(
dataSource, dataSource.sourceInfo.name, dataSource.sourceInfo.schema.toAttributes)
}
} /**
* Used to link a streaming [[DataSource]] into a
* [[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]]. This is only used for creating
* a streaming [[org.apache.spark.sql.DataFrame]] from [[org.apache.spark.sql.DataFrameReader]].
* It should be used to create [[Source]] and converted to [[StreamingExecutionRelation]] when
* passing to [[StreamExecution]] to run a query.
*/
case class StreamingRelation(dataSource: DataSource, sourceName: String, output: Seq[Attribute])
extends LeafNode with MultiInstanceRelation {
override def isStreaming: Boolean = true
override def toString: String = sourceName // There's no sensible value here. On the execution path, this relation will be
// swapped out with microbatches. But some dataframe operations (in particular explain) do lead
// to this node surviving analysis. So we satisfy the LeafNode contract with the session default
// value.
override def computeStats(): Statistics = Statistics(
sizeInBytes = BigInt(dataSource.sparkSession.sessionState.conf.defaultSizeInBytes)
) override def newInstance(): LogicalPlan = this.copy(output = output.map(_.newInstance()))
} 。。。。 // We have to pack in the V1 data source as a shim, for the case when a source implements
// continuous processing (which is always V2) but only has V1 microbatch support. We don't
// know at read time whether the query is conntinuous or not, so we need to be able to
// swap a V1 relation back in.
/**
* Used to link a [[DataSourceV2]] into a streaming
* [[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]]. This is only used for creating
* a streaming [[org.apache.spark.sql.DataFrame]] from [[org.apache.spark.sql.DataFrameReader]],
* and should be converted before passing to [[StreamExecution]].
*/
case class StreamingRelationV2(
dataSource: DataSourceV2,
sourceName: String,
extraOptions: Map[String, String],
output: Seq[Attribute],
v1Relation: Option[StreamingRelation])(session: SparkSession)
extends LeafNode with MultiInstanceRelation {
override def otherCopyArgs: Seq[AnyRef] = session :: Nil
override def isStreaming: Boolean = true
override def toString: String = sourceName override def computeStats(): Statistics = Statistics(
sizeInBytes = BigInt(session.sessionState.conf.defaultSizeInBytes)
) override def newInstance(): LogicalPlan = this.copy(output = output.map(_.newInstance()))(session)
}
那两个reader是microbatch和continue获取数据的根本规则定义。
StreamingRelation和StreamingRelationV2只是对datasource的包装,而且自身继承了catalyst.plans.logical.LeafNode,并不具有其他操作,只是个包装类。
实际上这些都是一个逻辑计划生成的过程,生成了一个具有逻辑计划的Dataset,以便后边触发流处理是执行该逻辑计划生成数据来使用。
Dataset的LogicPlan怎么被触发?
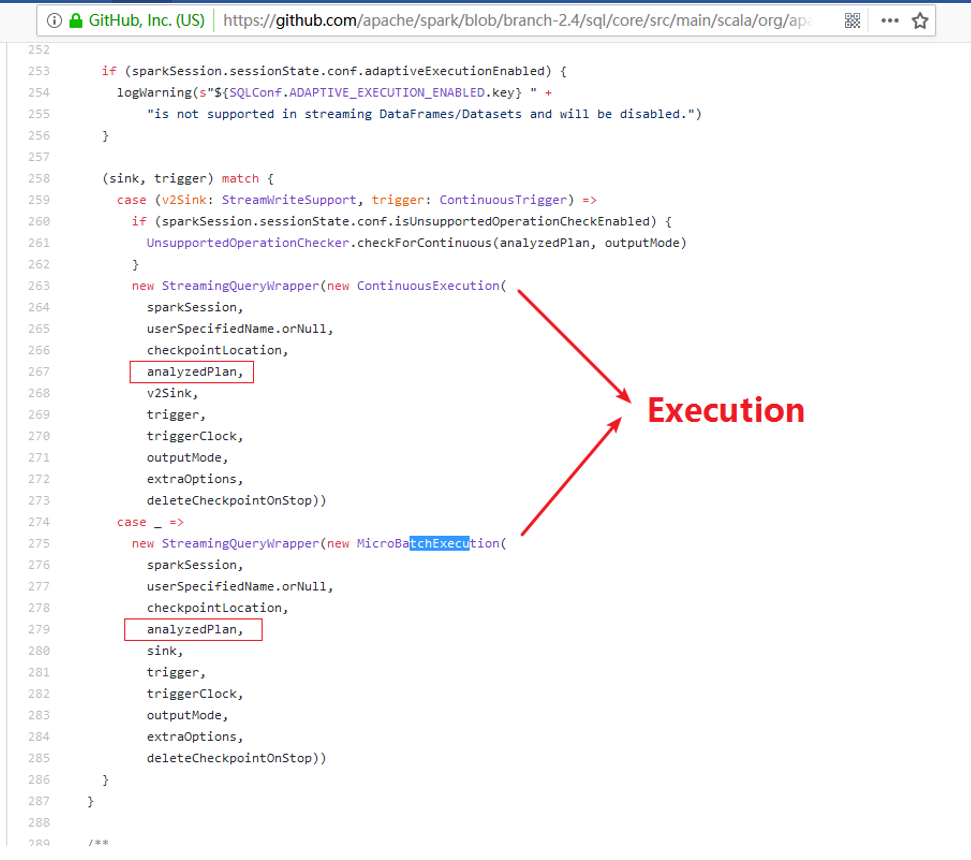
start()方法返回的是一个StreamingQuery对象,StreamingQuery是一个接口类定义在:
aggResult.wirteStream.format(“kafka”).option(“”,””).trigger(Trigger.Continuous(1000)),它是一个DataStreamWriter对象:
在DataStreamWriter中定义了一个start方法,在这个start方法是整个流处理程序开始执行的入口。
DataStreamWriter的start方法内部走的分支代码如下:

上边的DataStreamWriter#start()最后一行调用的StreamingQueryManager#startQuery()
Spark2.x(六十一):在Spark2.4 Structured Streaming中Dataset是如何执行加载数据源的?的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十六)Structured Streaming中ForeachSink的用法
Structured Streaming默认支持的sink类型有File sink,Foreach sink,Console sink,Memory sink. ForeachWriter实现: 以写 ...
- Spark2.x(六十):在Structured Streaming流处理中是如何查找kafka的DataSourceProvider?
本章节根据源代码分析Spark Structured Streaming(Spark2.4)在进行DataSourceProvider查找的流程,首先,我们看下读取流数据源kafka的代码: Spar ...
- Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中<Memory usage of state in Spark Structured Streaming>讲解Spark内存分配情况,以及提到了HDFSBackedState ...
- Spark2.3(三十五)Spark Structured Streaming源代码剖析(从CSDN和Github中看到别人分析的源代码的文章值得收藏)
从CSDN中读取到关于spark structured streaming源代码分析不错的几篇文章 spark源码分析--事件总线LiveListenerBus spark事件总线的核心是LiveLi ...
- Spark2.3(三十四):Spark Structured Streaming之withWaterMark和windows窗口是否可以实现最近一小时统计
WaterMark除了可以限定来迟数据范围,是否可以实现最近一小时统计? WaterMark目的用来限定参数计算数据的范围:比如当前计算数据内max timestamp是12::00,waterMar ...
- Structured Streaming教程(1) —— 基本概念与使用
近年来,大数据的计算引擎越来越受到关注,spark作为最受欢迎的大数据计算框架,也在不断的学习和完善中.在Spark2.x中,新开放了一个基于DataFrame的无下限的流式处理组件--Structu ...
- Structured Streaming编程向导
简介 Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark ...
- ASP.NET MVC深入浅出(被替换) 第一节: 结合EF的本地缓存属性来介绍【EF增删改操作】的几种形式 第三节: EF调用普通SQL语句的两类封装(ExecuteSqlCommand和SqlQuery ) 第四节: EF调用存储过程的通用写法和DBFirst模式子类调用的特有写法 第六节: EF高级属性(二) 之延迟加载、立即加载、显示加载(含导航属性) 第十节: EF的三种追踪
ASP.NET MVC深入浅出(被替换) 一. 谈情怀-ASP.NET体系 从事.Net开发以来,最先接触的Web开发框架是Asp.Net WebForm,该框架高度封装,为了隐藏Http的无状态 ...
- FreeSql (二十六)贪婪加载 Include、IncludeMany、Dto、ToList
贪婪加载顾名思议就是把所有要加载的东西一次性读取. 本节内容为了配合[延时加载]而诞生,贪婪加载和他本该在一起介绍,开发项目的过程中应该双管齐下,才能写出高质量的程序. Dto 映射查询 Select ...
随机推荐
- Java 之 ArrayList 集合
一.ArrayList 概述 java.util.ArrayList 是 大小可变的数组 的实现,存储在内的数据称为元素.该类是一个 集合类(容器),可以让我们更便捷的存储和操作对象数据. 该类可以 ...
- ip协议栈
struct iphdr { #if defined(__LITTLE_ENDIAN_BITFIELD) __u8 ihl:4, version:4; #elif defined (__BIG_END ...
- 06-Vue路由
什么是路由 对于普通的网站,所有的超链接都是URL地址,所有的URL地址都对应服务器上对应的资源: 对于单页面应用程序来说,主要通过URL中的hash(#号)来实现不同页面之间的切换,同时,hash有 ...
- Centos7 rsync+inotify实现实时同步更新
inotify slave部署 把master上指定文件下载到本地的主机指定目录 yum install rsync –y [root@localhost ~]# useradd rsync ...
- Flask基础之session验证与模板渲染语法(jinja2)
目录 1.http传输请求头参数 2.Flask中request.data参数处理 3.Flask中request.json参数 4.Flask中的session管理 5.Flask中模板语法(if, ...
- kubernetes集群证书过期之后--转发
步骤 如果有多master,需要在每个master上进行以下操作. 需要进行以下步骤 重新生成证书 重新生成对应的配置文件 重启docker 和 kubelet 拷贝kubectl 客户端文件 [ro ...
- Dapper 一对多查询 one to many
参考文档:Dapper one to many Table public class Person { public int Id { get; set; } public string Name { ...
- C++学习(11)—— 友元
生活中你的家有客厅(Public),有你的卧室(Private) 客厅所有来的客人都可以过去,但是你的卧室是私有的,也就是说只有你能进去 但是呢,你也可以允许你的好闺蜜好基友进去 在程序里,有些私 ...
- xadmin引入django-debug-toolbar调试工具
一.安装: pip install django-debug-toolbar 安装django-debug-toolbar库 https://github.com/jazzband/django-de ...
- LoarRunner脚本录制-Port Mapping
使用LR录制脚本时经常会因为内外网访问限制,或浏览器兼容等问题,导致无法正常录制脚本. 这里简单介绍一下使用LR端口映射的方式进行脚本录制,与之前介绍的<Jmeter脚本录制--HTTP代理服务 ...