TVM:
Hello TVM
TVM 是什么?A compiler stack,graph level / operator level optimization,目的是(不同框架的)深度学习模型在不同硬件平台上提高 performance (我要更快!)
TVM, a compiler that takes a high-level specification of a deep learning program from existing frameworks and generates low-level optimized code for a diverse set of hardware back-ends.
compiler比较好理解。C编译器将C代码转换为汇编,再进一步处理成CPU可以理解的机器码。TVM的compiler是指将不同前端深度学习框架训练的模型,转换为统一的中间语言表示。stack我的理解是,TVM还提供了后续处理方法,对IR进行优化(graph / operator level),并转换为目标硬件上的代码逻辑(可能会进行benchmark,反复进行上述优化),从而实现了端到端的深度学习模型部署。
我刚刚接触TVM,这篇主要介绍了如何编译TVM,以及如何使用TVM加载mxnet模型,进行前向计算。Hello TVM!
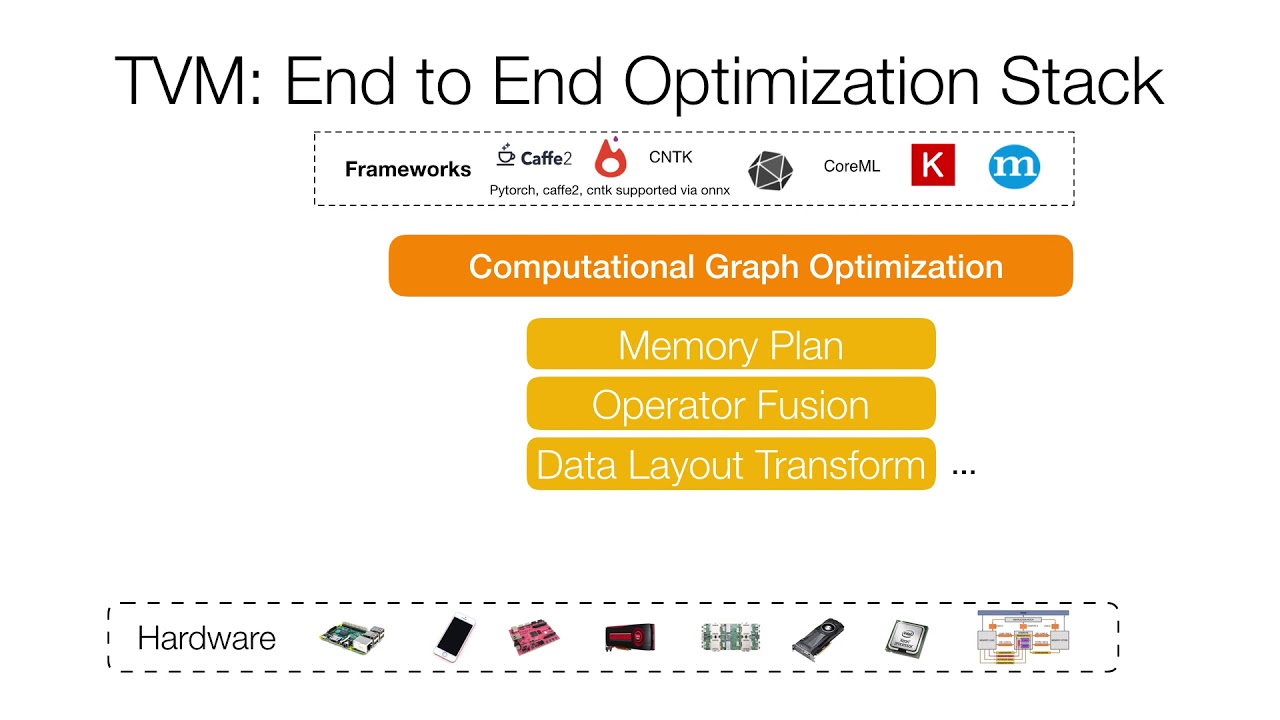
背景介绍
随着深度学习逐渐从研究所的“伊甸园”迅速在工业界的铺开,摆在大家面前的问题是如何将深度学习模型部署到目标硬件平台上,能够多快好省地完成前向计算,从而提供更好的用户体验,同时为老板省钱,还能减少碳排放来造福子孙。
和单纯做研究相比,在工业界我们主要遇到了两个问题:
- 深度学习框架实在是太TMTM多了。caffe / mxnet / tensorflow / pytorch训练出来的模型都彼此有不同的分发格式。如果你和我一样,做过不同框架的TensorRT的部署,我想你会懂的。。。
- GPU实在是太TMTM贵了。深度学习春风吹满地,老黄股票真争气。另一方面,一些嵌入式平台没有使用GPU的条件。同时一些人也开始在做FPGA/ASIC的深度学习加速卡。如何将深度学习模型部署适配到多样的硬件平台上?
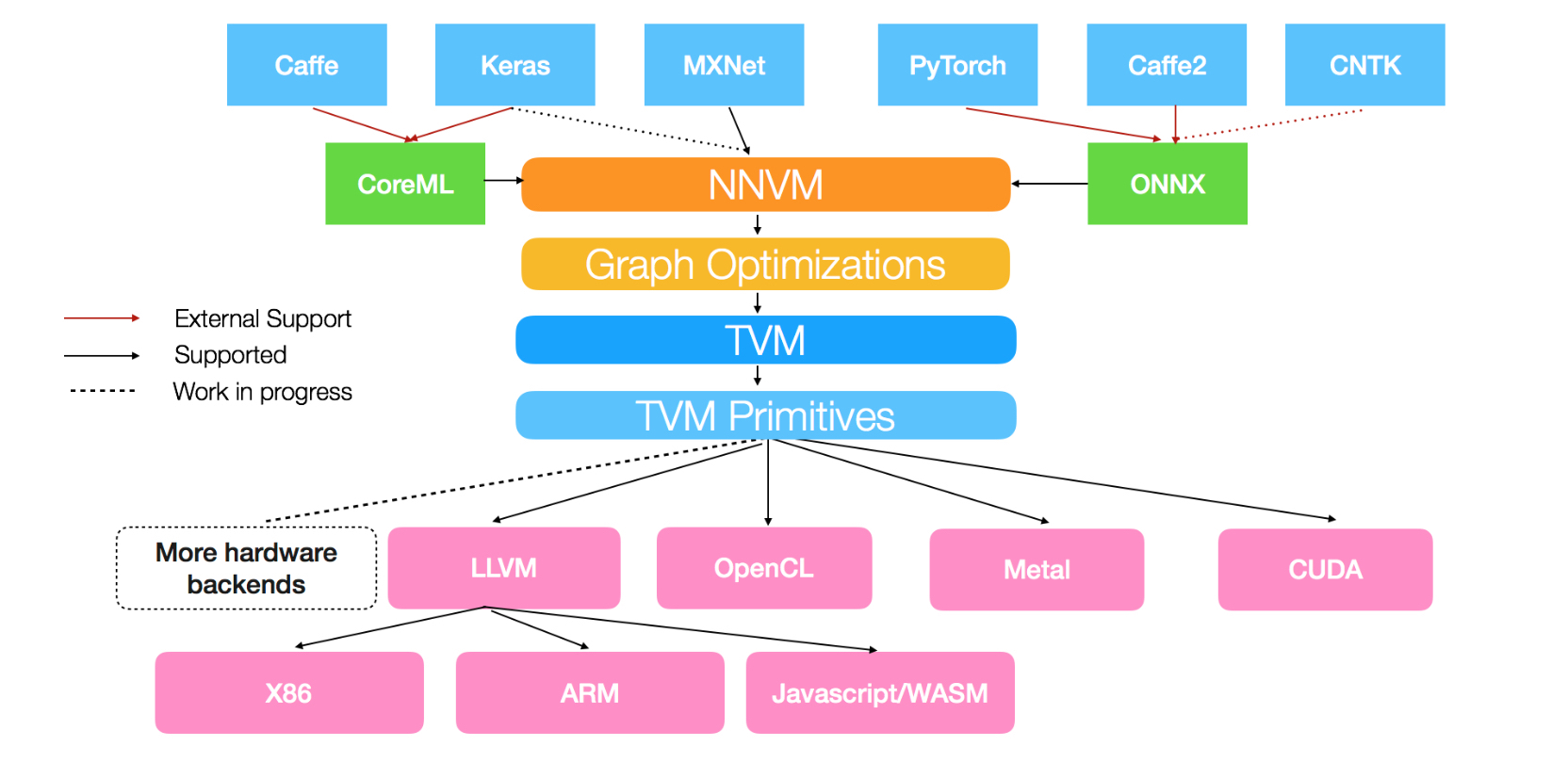
为了解决第一个问题,TVM内部实现了自己的IR,可以将上面这些主流深度学习框架的模型转换为统一的内部表示,以便后续处理。若想要详细了解,可以看下NNVM这篇博客:NNVM Compiler: Open Compiler for AI Frameworks。这张图应该能够说明NNVM在TVM中起到的作用。
为了解决第二个问题,TVM内部有多重机制来做优化。其中一个特点是,使用机器学习(结合专家知识)的方法,通过在目标硬件上跑大量trial,来获得该硬件上相关运算(例如卷积)的最优实现。这使得TVM能够做到快速为新型硬件或新的op做优化。我们知道,在GPU上我们站在Nvidia内部专家的肩膀上,使用CUDA / CUDNN / CUBLAS编程。但相比于Conv / Pooling等Nvidia已经优化的很好了的op,我们自己写的op很可能效率不高。或者在新的硬件上,没有类似CUDA的生态,如何对网络进行调优?TVM这种基于机器学习的方法给出了一个可行的方案。我们只需给定参数的搜索空间(少量的人类专家知识),就可以将剩下的工作交给TVM。如果对此感兴趣,可以阅读TVM中关于AutoTuner的介绍和tutorial:Auto-tuning a convolutional network for ARM CPU。
编译
我的环境为Debian 8,CUDA 9。
准备代码
config文件
编辑config文件,打开CUDA / BLAS / cuBLAS / CUDNN的开关。注意下LLVM的开关。LLVM可以从这个页面LLVM Download下载,我之前就已经下载好,版本为7.0。如果你像我一样是Debian8,可以使用for Ubuntu14.04的那个版本。由于是已经编译好的二进制包,下载之后解压即可。
找到这一行,改成
编译
这里有个坑,因为我们使用了LLVM,最好使用LLVM中的clang。否则可能导致tvm生成的代码无法二次导入。见这个讨论帖:_cc.create_shared error while run tune_simple_template。
python包安装
demo
使用tvm为mxnet symbol计算图生成CUDA代码,并进行前向计算。
最后的话
我个人的观点,TVM是一个很有意思的项目。在深度学习模型的优化和部署上做了很多探索,在官方放出的benchmark上表现还是不错的。如果使用非GPU进行模型的部署,TVM值得一试。不过在GPU上,得益于Nvidia的CUDA生态,目前TensorRT仍然用起来更方便,综合性能更好。如果你和我一样,主要仍然在GPU上搞事情,可以密切关注TVM的发展,并尝试使用在自己的项目中,不过我觉得还是优先考虑TensorRT。另一方面,TVM的代码实在是看不太懂啊。。。
想要更多
- TVM paper:TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
- TVM 项目主页:TVM
后续TVM的介绍,不知道啥时候有时间再写。。。随缘吧。。。
如何评价陈天奇团队新开源的TVM?
1,824
101,159
他们也关注了该问题





举报
12 个回答

从去年nnvm推出之后,非常感谢在zhihu和
上有一些讨论 如何评价陈天奇的模块化深度学习系统NNVM? ,关于nnvm剩下的瓶颈。这个讨论本身加上早期的nnvm编译尝试,让我意识到了可以支持快速调优底层op的重要性。在接下来的八个多月里面我们不断迭代完成了TVM。
TVM尝试从更高的抽象层次上总结深度学习op的手工优化经验,用来使得用户可以快速地以自动或者半自动的方法探索高效的op实现空间。
TVM和已有的解决方案不同,以XLA作为例子,TVM走了和目前的XLA比更加激进的技术路线,tvm可以用来使得实现XLA需要的功能更加容易 :已有的解决方案本身基于高级图表示的规则变换,可以产生一些图级别的组合op优化,如conv-bn fusion,但是依然要依赖于手写规则来达到从图的表示到代码这一步。图的op表示到代码本身可以选择的东西太多,如何做线程,如何利用shared memory,而大部分没有在图语言里面得到刻画,导致难以自动化。 这样下去深度学习系统的瓶颈必然从op实现的复杂度变成了实现graph compiler中模式生成规则的复杂度。走这个方向需要非常大的工程团队的支持,而我们希望采用更少的人力达到同样甚至更好的效果。
我们采取了风险更大但是回报也更大的长远技术路线。简单地说,TVM通过把图到op生成规则这一步进一步抽象化,把生成规则本身分成各个操作原语,在需要的时候加以组合。基于tvm我们可以快速地组合出不同的schedule方案。
这个想法并不新颖,正如其它回答中提到的Halide,或者polyhedra method都是尝试去做这件事情。想法虽然美好,但是自动代码生成这条路线必须要生成代码效率到达手写的80%-90%效率以上,才会有实际使用的价值。一旦到达了80%到90%的效率以上,通过fusion,layout的一些高级联合优化就可以弥补这一个gap来得到比直接组合手写代码更好的效果。
但是这也正是这个问题最困难的地方,我们需要能使得自动或者半自动生成的代码达到手写代码的效果。在TVM之前,已有的解决方案都还没有解决这个问题。我知道的最好的GPU自动生成代码大概可以到Cublas的50%的运行效率,而大部分的已有方案只是针对单线程cpu有比较好的效果。
当然已有的解决方案有不少值得参考的地方。比如polyhedra method本身非常精辟地把程序优化的大部分问题总结为针对整数集的分析。Halide里面的schedule和declaration分离的思想等。这些思想都非常强地影响了TVM的设计
这本身是一个很有趣的科研问题,dmlc的的初衷就是去解决这样新的问题,发布新的解决方案。TVM在很大程度上解决了这个问题。要解决它,需要做到两点:设计足够大的schedule空间,使得它可以囊括包括cpu和gpu在内可以做到的手写优化,设计足够强大的搜索算法。之前的方法之所以没有图片,难点在于需要足够大的空间。
所有的抽象总是有缺陷的,所以死抱一个固定的抽象肯定不能解决所有的问题。但是可以被写出来的手工优化基本上也是可以被抽象的。过去的几个月我们就是沿着这样的思路,不断地去总结手工优化的经验加以抽象到TVM中。虽然我们不敢保证TVM包含所有可能的手工优化,但是我基本上cover了我知识范围里面可以涉及到的东西(使得TVM至少比我知道的多)。随着TVM的演化,会有更多的这样的手工优化经验可以被加入进来。这也真是需要HPC机器学习和编译等各方面人才一起合力的结果。
到目前为止,我们基本可以确定TVM目前提供的schedule空间在cpu上可以做到90%,相似或者超过一些手写优化库效果的方案,在gpu上几本可以做到达到或者超过手写cuda的方案,但是和手写assembly在一些情况还有80%的差距(主要来源于gpu的寄存器分配比较困难)。TVM本身也意识到的手写优化的重要性,会在允许在各个级别混用手写优化的代码, 来弥补剩下这一平衡。
这是一个非常激动的前沿课题,基于这个项目本身还会有不少有趣的研究方向,我们在很多地方已经可以看到非常好的效果。所以我们非常希望对于机器学习,hpc,编译原理,硬件加速 有兴趣的同学一起加入进来,一起来推动这个项目。而因为我们目前到达的效果本身,TVM已经可以被使用于实际的应用场景中了。
最后有一些细节上面的东西,TVM本身的设计中是非常注重开发效率和可扩展性。TVM直接提供了非常好用的python和真机调试框架,可以不依赖于上层框架直接基于python开发调试。这一点使得tvm在调试开发和效率迭代上面比起已有的方案有比较大的优势。未来我们也会放出一些样例教程,让大家都可以开发高效的代码
未来会有自动图编译以及直接在python端定义customop
收藏感谢
收起

目前 TVM 放出的资料还较少,周日学习了下代码,和大家交流分享,有疏漏烦请回复指出。
TVM 的应用场景,是跟 TensorFlow XLA 对标,提供将模型输出到不同设备 native code 的能力。这里面有几个可以对标的组件:
- TOPI (TVM Operator Inventory) 大约对应 XLA HLO, 描述在 DL 领域会用到的高层次 Operator 如 matmul, conv2d 等。这一层次可以做 CSE、Fusion 等优化。
- Schedule + HalideIR + TVM IR 无对应
- 代码输出 TVM 使用 LLVM IR 和 Source Code, 对应 XLA 使用 LLVM IR.
这里面,TVM 的切入点是在 High Level 到 Low Level 中间,插入了 Schedule 层,大概流程是 NNVM -> TVM/TOPI -> TVM/Schedule -> TVM/HalideIR -> TVM IR -> LLVM IR 或 Source Code。中间 TVM Schedule 的主要思想来自于 Halide. 这里要简单介绍一下 Halide 这个为图像处理设计的语言。Halide 其特点是计算描述(algorithm)和计算过程(schedule)分离(http://people.csail.mit.edu/jrk/jrkthesis.pdf)。这么做是因为计算机体系结构的设计(缓存,SIMD 等),直接裸写算法不能获得最高性能(一个例子是三重循环裸写矩阵乘会很慢)。因此不同的体系结构,对一个算法的计算过程也就不同。分离算法定义和计算过程,则方便为不同的体系结构制定不同的 schedule, 进一步可以探索 schedule 的自动生成(Automatically Scheduling Halide Image Processing Pipelines)。更详细的介绍建议去 Halide 官网 Halide 学习。
当初看到 Halide 的时候,就在想这个想法在 DL 领域一定会有用,如今终于被 DMLC 推动进入了人们的视线。我对这个事情的看法是:
- Halide 可以比较快的实现一个性能还不错的 kernel,开发效率很高,换不同 schedule 测试方便。对比传统 kernel 实现一般是手写 C/C++ 或者汇编代码,开发效率较低。但任何抽象都不是完美的,有足够人力的情况下,传统写法一定可以获得不低于 Halide 的效率。
- Halide 提供了 auto-tune 的可能,但目前也只是在学术界研究,离工业级生产还远。因此可预见的未来,我们还是要为不同的 target 手写 schedule 的。
根据
介绍,TVM 相对 Halide 做的比较多的工作,主要的是去解决 schedule 空间包含手写优化的问题。具体内容移步 crowowrk 的回答。
TVM 的另一个目的是,希望通过 TOPI 这个 Operator 库,为所有兼容 dlpack 的深度学习框架提供 kernel 库,这个目标是十分欢迎的,具体效果还有待观察。
反过来看 TensorFlow 的 XLA,目前 XLA 还在快速开发中,有几点可以注意:
- XLA 并不反对独立出来给其他框架用 XLA standalone
- XLA 欢迎尝试各种 idea,目前有人在 Incorporate Polyhedral Compilation
- XLA 目前很多 kernel 实现是基于 Eigen 的。某种程度上,Eigen 这种数学库也是 TOPI 的对标。
总的来说,TVM 目标是很好的,非常支持。Soumith (PyTorch 主要作者)也在积极参与 TVM 项目并表示在接下来的几个月内会有更多关于 TVM/PyTorch 的消息 Twitter 。
edit: 跟作者交流更新了若干技术细节。
收藏感谢
收起

最近阵容有点强大。
这周四我们请了天奇来将门做线上直播,给大家亲自讲讲TVM。
天奇的直播首秀,就在本周四(16号)下午1点,将门创投斗鱼直播间!
欢迎大家呼朋引伴来给天奇打call!!
收藏感谢

最近在考虑将深度学习移植到移动端, 面对很多问题:
- ios 11有coreml, ios10用metal, 更低版本需要手写低版本metal代码
- neon指令集优化
- 安卓gpu
- caffe,tensorflow,darknet等一堆框架,移植不便,而且无法一一优化.
瞌睡送枕头, 感觉tvm就是答案.
github上关注了tianqi, 一直纳闷最近半年为啥没有提交代码, 难道上课太忙?
直到昨天...
突然都亮起来了.
吐槽一句, mxnet号称是轻量级框架, 各种宏,lambda看的怀疑人生,nnvm居然还能把torch弄过来用Orz. 后来看了caffe, 很多功能都用第三方库, 主体代码很清晰简单啊, 这才是轻量啊...
利益相关: dmlc脑残粉, tianqi脑残粉
收藏感谢


大家还记得找不到工作的bhuztez么
他在去年在一位七岁小朋友的指导下预言,2017年出现的下一代深度学习框架后端会利用Polyhedral model做fusion,减少GPU内存带宽压力,提升运行速度。被某人下结论说“真心不会.. 合并带来的内存节省只是一次elementwise op的代价,比起卷积开销真是一个毛毛”
https://www.zhihu.com/question/48615510/answer/115592046
而现在的广告
“现在我们看到了 TVM 构建了由循环转换工具比如 loopy、多面体分析启发的图优化”
“我们通过自动融合运算符并使 TVM 生成融合的内核,在图形节点之间和之中应用优化”
bhuztez不如赶紧改行,事实证明他那点破烂水平,连名校博士头衔都没有,真心不适合写程序 ,我建议他还是去卖煎饼果子吧 :)
如何评价陈天奇的模块化深度学习系统NNVM?
项目地址:GitHub - dmlc/nnvm: Intermediate Computational Graph Representation for Deep Learning Systems
NNVM是否会成为深度学习时代的汇编语言,成为沟通底层计算设备(GPU、FPGA)与高层的计算图描述语言(Tensorflow、MXNet)的通用桥梁?
1,443
51,424
他们也关注了该问题


举报
7 个回答
北京时间 10 月 13 日 12:00 更新:
加个 Disclaimer: 本文仅代表个人观点,与雇主无关。
北京时间 10 月 4 日 1:40 更新:
看到作者
的 回答,并且在评论中进行了简单交流。我的看法和作者的想法,都是认同 graph 定义和优化这一层的,区别是我认为这一层放在框架内部更方便开发,而 NNVM 想把这一层拿出来大家一起做大做强避免重复劳动。这个想法我是非常支持的,但最终是否好用还是要看工程的发展和理论总结,尤其是在当前 NNVM 的实现还非常单薄的情况下。
我之前的回答,主要是在把 NNVM 跟 TF 内部的 graph 这层比对,并不是为了分出高下,而只是在做技术上的比对,并表达我的一些想法。希望大家不要有门派之争,理性讨论,共同促使技术进步。
=== 10 月 3 日答案原文如下 ===
tl;dr NNVM 的出现不在于技术上有多大突破(该有的 TF 都有),而在于意欲打造一个公共接口(虽然我并不认同)。当下推出的 TinyFlow, 也有一点集合社区力量对抗 Google 的 TensorFlow 的意思。不管怎么说,DL Framework 社区活跃,终归是一件好事,作为从业者非常感谢!
首先建议想做技术分析的同学,都先看看 TensorFlow 的代码,虽然量很大,但核心都在core/framework 和 common_runtimecore/distributed_runtime 几个目录下面,从 Session 一路分析进去,并不难懂。
nnvm 从 github 上看,是为了作为模块化 DL 系统中的计算图的一环。
NNVM offers one such part, it provides a generic way to do computation graph optimization such as memory reduction, device allocation and more while being agnostic to the operator interface definition and how operators are executed. NNVM is inspired by LLVM, aiming to be a high level intermediate representation library for neural nets and computation graphs generation and optimizations.
这些部分,在 TensorFlow 里面都有相对成熟的实现。
先说图表示,在 TensorFlow 里面有两种图,一种是用于接口的,基于 protobuf 表示的图 tensorflow/graph.proto,称之为 GraphDef。另一种是 C++ 内部运行时用的图表示 tensorflow/graph.h,称之为 Graph. 而 Operator 的定义,TF 是通过一个在 C++ 里面实现的 DSL 做的 tensorflow/op.h 使用方法例如 tensorflow/math_ops.cc,这个在 NNVM 里面也采用了类似的形式。
之后做图的优化,在 C++ 层面有 tensorflow/graph_optimizer.h. 基于这个接口,目前也做了若干实现 tensorflow/graph_optimizer.cc 如常数折叠,公共表达式消除等。除此之外,在 Python 层面也有 graph_editor 用来做图的编辑。比如 Sublinear Memory 理论上用 GraphEditor 是可以做到的。
TF 的 Operator 和 Kernel 也是分开的,相同的 Operator 可以有 CPU/CUDA 等多种实现,OpenCL 也在进行中。往 TF 里面加 Operator 并不复杂 https://www.tensorflow.org/versions/r0.11/how_tos/adding_an_op/index.html.
所以先泼一瓢冷水:我粗略的扫了一下 NNVM 的代码,可以说目前 NNVM 的目标,在 TF 内部都有实现并且都有比较好的抽象隔离。重新造轮子,政治意义大于技术意义。
转载作者 陈天奇 的微博 关于今天深度学习系统争论。目前的壁垒并非... 来自陈天奇怪:
关于今天深度学习系统争论。目前的壁垒并非使用哪一个,而是系统内部高度耦合,使得改进或者从头fork打造系统的代价变高。通过模块化,去中心化来解决这些问题,防止垄断。 当大家都可以通过组装组件几天从头打造MX, TF或者类似系统的时候。这些争论就不复存在了。
最近推出的 TinyFlow 号称是 2k 行的 TensorFlow,但其实看代码会发现,做到当面这个层面,即使完全重写,代码成本也不算高。TinyFlow 目前(2016.10.3)的本质是一个 Python DSL 到 Lua 代码的转换器。而 TensorFlow 本身的结构并不复杂,难点在于无穷多 Operator 的实现,和当初分布式架构的设计。这两个实现出来,本质上都是工作量问题,这也是 TF 的 codebase 如此庞大的原因。
NNVM 目前(2016.10.3)自身也不包括 Operator 的定义,这会导致使用 NNVM 的不同框架本质上是无法互换的。而定义 Operator 这个工作量比较大,甚至不一定能完成(比如不同 Framework 对 padding 的定义就不太一样),不知道 NNVM 是否有意愿往这个方向发展。
目前 DL 的领域还在高速发展,新的网络结构(比如 ResNet, GAN)、计算节点(各种神奇的 Operator)、计算方法(比如 lowbit, sublinear memory)、计算设备(比如 TPU,寒武纪)都在不断涌现。分布式架构也在不断演进。在这个时间点,我认为 monolithic 的框架重构相对方便,会有更加旺盛的生命力。而 NNVM 的理想,恐怕跟现实还是有一定差距的。目前更有价值的,我觉得并不在图表示层,而是各种 Operator 的 kernels. 每个设备的 kernel 都需要专业人员定制,工作量大,难度高。cudnn 解决了 CUDA 设备上的大部分问题,但仍然有很多 Operator 需要自己实现。lowbit 目前也并没有特别可用的实现。如果能有一个统一的库,定义每个 Operator 在各种设备上的最优运行代码,应该对社区更有帮助。而上层的网络定义,和具体每个图的运行调度方式(比如 MXNet 的 Dependency Engine,TensorFlow 的分布式框架和 rendezvous 设计),这些代码量不大,但更容易体现出差异化的部分,我想还是留待每个框架自己解决吧。
个人愚见,请各位参考。虽然我并不认同 NNVM 的目标,但依然对陈天奇先生对社区的贡献非常钦佩。各位如想评论,请至少大略了解 NNVM,TensorFlow 和 MXNet 的内部实现架构,以节省大家时间。
收藏感谢
收起
15 条评论

KaiJ2 年前
同意。另外不知道“从头fork打造系统”的需求是哪儿来的,而且有了nnvm也并不容易从头打造系统,因为最麻烦的还是opr。。而且跟llvm的情形不同,PL的前端非常丰富而且差异巨大,而中间表示用上三地址码可以用很多现成的优化理论。 但deep learning的前端基本就是graph的描述,并没有太多接口以外的差异。而在不考虑opr具体特性情况下的中间表示能带来的优化有限,可能最有用的就是内存分配;像const folding目前看来在nnvm的框架里并不好做,因为需要知道opr的具体操作,需要定义好tensor结构,管理一些内存分配,这样nnvm就要膨胀成大半个dl框架了。如答主所述,真正加速还得看后面的kernel和硬件,这块门槛最高,价值最大,但现在社区里能看到的成果也是最少的。5回复踩举报


刘知远2 年前
文笔很好呀!1回复踩举报

渡河2 年前
膜拜大大!1回复踩举报
某一个吃货2 年前
其实看最新mxnet的issue,整个mxnet将会在nnvm上进行重构。我觉得良好的系统结构抽象和完全的性能不可兼得。但并不是说选择优秀的抽象就不如优秀的性能。整个mxnet在几位大牛(感觉就五个人左右)的贡献下(和TF几十个人的团队相比),开发效率非常高,这也和优秀的抽象和思考是分不开的。2回复踩举报
某一个吃货2 年前
其实我觉得做这个的大家都明白框架之间的差异其实都并不大,核心就是分布式和Operator的支持程度。Google有着最优秀的研究和工程人才自然有优势。但我觉得nnvm志不在此,并不是为了和TF一较高下,而是一个开源社区降低入门contribution门槛的阶梯。其实当有一天nnvm(dmlc)社区成长的和keras一样之后,优秀架构的潜力就会慢慢显现,之前的那些问题也都不会是问题。1回复踩举报
某一个吃货2 年前
我觉得就像当年推出Java的时候,只是为了解决一个问题(跨平台)而不是为了解决所有的问题(性能啊语言特性啊),肯定不会想到现在的用途。毕竟有一个重要的人生经验【一个人的命运啊,当然要靠自我奋斗,但是也要考虑到历史的行程】赞回复踩举报

谢流远2 年前
tf分布式效率那么差,架构设计并不能算优点吧4回复踩举报
谢流远2 年前
kernel其实常用的性能瓶颈10个都不到,剩下的长尾优化意义不大而且永远不可能写完。如果你做的是novel research,那你用的op必然不可能有别人给你写好。3回复踩举报
dzhwinter2 年前
反对一下,TF的抽象做的太多了,分布式设计易用性并不好,小operator组合导致效率差现在还没有解决。认同NNVM讲的三个story。4回复踩举报
刘弈2 年前
飞机好厉害~虽然我看不懂 0.0赞回复踩举报
王雷2 年前
赞同楼上的反对,TF的抽象过多,设计质量和代码质量并不理想赞回复踩举报
时间的朋友1 年前
一个在科研界混的人觉得NNVM更像一个科研项目,设计追求各种灵活,这在很大程度上确实能够促进社区的发展。但重口难调啊,设计无比灵活的东西针对特定需求,性能却不一定牛逼,在工程应用上各家有各家的独特需求和硬件条件,个人觉得更需要针对需求的定制。
赞回复踩举报
zhuao8 个月前
我是做系统多媒体框架的,对DL的东西不了解,看了陈天奇的回答,觉得蛮有感触的。
Android上的多媒体框架就是一个渣。stagefright的player连google自己的应用都不使用;java层重新封装的exoplayer也并没有为广大第三方应用所接受。因为他的思路就是面向特定的应用来构建实现,没有留给第三方开发者真正的定制化开发空间。比如你想在视频播放过程中加一个额外的后处理实现图像增强,这不能够通过添加一个新的组件来简单的解决。从陈天奇的回复来看,TF也是类似的解决方案 -- 你想添加一个额外的处理环节,很难。而这是在做框架设计的时候需要慎重考虑的东西。
而参考其他的多媒体框架,像Linux的GStreamer,Windows的DShow;都是可以方便地做到上面的事情。也就是他们是真的面向pipeline的graph设计:每个模块(算子,plugin)具有统一的直观的接口(而不是具象的每个特定属性);不同的模块(算子)可以自动地完成连接和交互数据。内存的管理和数据的流动在框架的约束下交由模块自动完成。这样在搭建的新的场景的时候,就是垒积木,足够简单;在pipeline中添加和去除处理环节也可以通过几行代码来完成。
至于“相对干净的Op应该去推动成为一个独立的模块”,这个可以参考多媒体领域的ffmpeg。他就是focuse在具体的视频编解码和处理功能,而独立于不同的多媒体框架(可以充分被Gstreamer,VLC,甚至stagefright所使用)
这种框架设计的思路,随着场景和工程的演进,可以表现出更多的优势。
赞回复踩举报
发布
之前讨论过后更加意识到了@王健飞 所说的更好地支持更多平台的op调优的重要性。昨天我们发布了dmlc/tvm 来解决这部分问题。
-------
在几个月之后给了几个关于NNVM的报告,也思考了它和已有系统的差别。追加一下这一页slide,是我对于在抽象成面上面各个系统差别的理解。

原回答
-------
我是NNVM的作者。
总结一下,技术上本身的NNVM和现有的东西的差别是最小模块化和去中心化,降低深度学习系统优化门槛。除了为了解决现有问题,更多是为了未来考虑。
关于是否重复造轮子的问题,图表示和优化本身在MXNet就已经存在,楼上也提到TF也有对应的抽象,为什么我们需要重新写一遍呢,基本上也就是以上两点原因。
基本上现有的深度学习系统分成两块,1) 基本的operator的实现, 2)支撑其中的系统调度,优化,解释或者编译架构。
在工程难点上,operator需要堆代码,但是对于工程架构的难度上面而言相对较低(也就是说可以写的人比较多一些),但是需要堆比较大量的代码。而剩下的系统优化部分,内存,执行调度和分布式优化对于整体系统而言的难度相对高一些。Operator的集合问题虽然是一个问题,看已经有的成熟框架不论是Torch, Theano或者MXNet的operator完整程度基本上可以满足于大部分应用,也就是说这部分暂时属于已经解决或者可以通过堆积工程力量容易解决的问题。楼上说的最小化通用的 Op接口很重要,和NNVM我们考虑的方向垂直。我觉得相对干净的Op应该去推动成为一个独立的模块,而Op实现本身其实没有必要和框架耦合很深(虽然遗憾的是目前的设计暂时没有做到这一点)。
NNVM希望解决的是垂直于operator实现的问题。有趣的是其实TF在这一暂时没有花特别多的力气,所以会让人觉得operator是大头。其实这里有很多有趣的东西,在执行,调度和编译优化上面。编程模型和一个图本身的执行模式和硬件也会有更多的差异。
直接讨论一下设计,目前TF采取了单一的动态执行模式,使得本身执行特别依赖于动态内存分配以及threading。而这并非是大部分场景下的最优方案。大部分场景下基于对于有限的图进行的静态分配,可以更大的缓解这个问题,实际情况如MX本身的内存损耗可以做的更好。为什么目前TF不会出现多种执行模式呢,是因为TF本身Op的接口还是过于一般地针对的动态,而如果要更好的优化需要更细化的Op接口(分开内存分配和计算的部分),这就考虑到一个Op甚至可能有多种接口的可能性。
NNVM本身的图的设计参考了TF,MX和caffe2的图部分。楼上的评论基本上提到了几个非常重要的概念,即系统优化和Op具体的性息相关。但是和PL不同,我们不能直接简单的抽象出有限个操作来表示整个程序。这个时候似乎框架和Op会有比较强的关联性,导致比较大的耦合。但是也并非如此,因为每一个优化本身其实只依赖于Op的部分属性。比如有同学提到的常数折叠,其实需要知道的是一个Op是否是常数,以及如何去展开常数两个函数。NNVM本身的做法是允许注册这两个额外属性来允许常数折叠优化。但是当不需要这个优化的时候,可以直接去掉这一部分。使得深度学习的优化可以插拔。现在看起来可能有些overkill,但是我们相信未来深度学习系统在这方面会有很大的发展,允许不同的优化来自于不同群体和研究人员是我们更加喜欢的方式。
基于以上原因,NNVM允许给每个op注册任意的信息。并且可以使得属性和注册和op的实现分开。这相对于TF的op接口而言是一个进步的地方。TF内部的所有op属性是需要提前数据结构指定的,也就是说,目前TF可以注册shape inference, op的输入参数的个数,但是无法注册比如我们需要的新的细化Op接口,或者有些人关心的代码生成函数。如果需要加入这些特性,必须要修改Op的接口。这意味着所有的开发需要在一个中心,并且只能保留大家关心的东西。如果forkA有feature1, forkB有feature2的情况,forkB想要拿到 feature1就会比较不方便。因为NNVM允许不修改Op接口注册任意信息,相对解决了这个问题。
当然模块化和去中心化并非对于所有人都重要,就是见仁见智把。
未来的深度学习系统会有更多系统的问题,使得优化和执行更加多样化。我们不能够期待所有的优化都来自于一个团队,或者只应用于一个框架。更多的优化看起来会带来更多的耦合,但是也并非如此。
发布TinyFlow原因很简单。大部分人并没有意识到其实目前深度学习的“系统”部分可以通过简单抽象得到。TinyFlow作为一个教程性质的项目,可以用比较短的代码展示目前有的大部分优化概念,并且把Op的部分代理给Torch(因为Op本身虽然重要,但是并不作为架构一部分)。如果可以有更多的同学来关注深度学习系统优化,基本这个项目的目的就达到了。
值得承认的是,NNVM目前只是走出了第一步,只是包含了MXNet原有的一些优化,暂时内容不多,我们会继续带来更多好玩的东西。 我们也会继续坚持模块化和去中心化的思想,使得我们新的成果可以更好的用在各个平台里面
收藏感谢
收起
12 条评论

一枚做猎头的姑娘2 年前
当然模块化和去中心化并非对于所有人都重要,就是见仁见智吧赞回复踩举报

强黄2 年前
为你们感到骄傲2回复踩举报

王健飞2 年前
自定义 attributes 的部分不太理解。为了使用 nnvm 的不同框架能够交互,必然还是要规定一组 common attributes 的,这些 common attributes 可能跟其他框架内置固定的 attributes 并无二致。
如果要某个框架要增加新的 attributes, 在不求通用性的前提下,可以不改 NNVM 只在自己前后端实现,但这跟在一个 monolithic 框架中增加一个新的 attributes, 似乎代码量不相上下?以及,支持自定义 attributes 只要支持一个 map 即可,我没有确认目前各个框架的实现,但即使目前不是 map, 在 Operator 定义中增加一个 map 支持任意 attributes 也不是难事吧?
1回复踩举报- 没错,任意attr实现代码量不多。通用性,可拆除和去中心化,是我们关心的东西。这里的意义在于基于NNVM的attr优化可以复用于各个前后端。如果所有的东西都是一个团队在一个框架里面实现,同样代码量没有多大差别。
只是在考虑通用性的时候会多一个心眼,有时候代码会比hack的干净一些。这是在从MXNet转化到NNVM的一个体会。
虽然复制总是可能的,大家都会做,但是还是希望可以有共同的抽象。就好象op和模型,也是一样的道理。
最后,其实我们就是希望用最小的代码完成最多的事情,而不是overdesign一个东西。虽然不一定形成技术壁垒,但是有利于增加新的好玩的东西进行高效开发
2回复踩举报

陈天奇 (作者) 2 年前
恩,我的理解是DL本身已经很难用枚举instruction set的方式来统一中间表示了。所以通过通用的Attr来统一。如何根据各个优化的需求抽象出合适的Attr以及对应的优化的确是未来的关键。使用NNVM的设计基本上就是强迫我们在未来系统演化中有更多这样的思考。
现在DL系统开发还有很多不确定因素,相信不论大家角度如何,总会有更多好玩的东西出来的
1回复踩举报

齐显东2 年前
现在出来了 Weld,可以对比一下吗?是类似的框架吗?赞回复踩举报

余风云1 年前
还以为是寒武纪
赞回复踩举报
ForAnyThing1 年前
人和人差距真大,现在留言还这么少,等你真的全民皆知的时候,至少我早点膜拜了大神。赞回复踩举报
还是用化名10 个月前
同膜拜
赞回复踩举报
发布

NNVM Compiler: Open Compiler for AI Frameworks
盗一张文中图:

给我一种感觉,nnvm牵起了pytorch,cntk,caffe2,caffe,keras(?)的小手,开始干xla。。(keras怎么哪都有你。。)
收藏感谢
7 条评论

charging1 年前
keras蛮好用的1回复踩举报



bingo1 年前
不是中文图吗赞回复踩举报

sean zhuh1 年前
感觉tf好高傲,自成一家不和我们玩TVM:的更多相关文章
- TVM代码生成codegen
TVM代码生成codegen 硬件后端提供程序(例如Intel,NVIDIA,ARM等),提供诸如cuBLAS或cuDNN之类的内核库以及许多常用的深度学习内核,或者提供框架例,如带有图形引擎的DNN ...
- 将代码生成器带入TVM
将代码生成器带入TVM 为了使数据科学家不必担心开发新模型时的性能,硬件后端提供程序(例如Intel,NVIDIA,ARM等)可以提供诸如cuBLAS或cuDNN之类的内核库以及许多常用的深度学习内核 ...
- TVM设计与构架构建
TVM设计与构架构建 本文档适用于希望了解TVM体系结构和/或在项目上进行积极开发的开发人员.该页面的组织如下: 实例编译流程Example Compilation Flow描述TVM把一个模型的高级 ...
- 卷积神经网络 CNN 系列模型阐述
http://www.sohu.com/a/134347664_642762 Lenet,1986年 https://github.com/BVLC/caffe/blob/master/example ...
- java web 开发三剑客 -------电子书
Internet,人们通常称为因特网,是当今世界上覆盖面最大和应用最广泛的网络.根据英语构词法,Internet是Inter + net,Inter-作为前缀在英语中表示“在一起,交互”,由此可知In ...
- 所有selenium相关的库
通过爬虫 获取 官方文档库 如果想获取 相应的库 修改对应配置即可 代码如下 from urllib.parse import urljoin import requests from lxml im ...
- 自主数据类型:在TVM中启用自定义数据类型探索
自主数据类型:在TVM中启用自定义数据类型探索 介绍 在设计加速器时,一个重要的决定是如何在硬件中近似地表示实数.这个问题有一个长期的行业标准解决方案:IEEE 754浮点标准.1.然而,当试图通过构 ...
- Python之路【第七篇续】:进程、线程、协程
Socket Server模块 SocketServer内部使用 IO多路复用 以及 “多线程” 和 “多进程” ,从而实现并发处理多个客户端请求的Socket服务端.即:每个客户端请求连接到服务器时 ...
- 第二篇:JMeter实现接口/性能自动化(JMeter/Ant/Jenkins)
主要是对HTML报告的优化 如果按JMeter默认设置,生成报告如下:
随机推荐
- Codechef September Challenge 2019 Division 2
Preface 这确实应该是我打过的比较水的CC了(其实就打过两场) 但由于我太弱了打的都是Div2,所以会认为上一场更简单,其实上一场Div的数据结构是真的毒 好了废话不多说快速地讲一下 A Eas ...
- 【转】pywinauto教程
一.环境安装 1.命令行安装方法 pip install pywinauto==0.6.7 2.手动安装方法 安装包下载链接:pyWin32: python调用windows api的库https:/ ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- CentOS7系统yum方式安装MySQL5.7
参考:https://www.cnblogs.com/bigbrotherer/p/7241845.html#top 1.在CentOS中默认安装有MariaDB,这个是MySQL的分支,但为了需要, ...
- 网格弹簧质点系统模拟(Spring-Mass System by Fast Method)附源码(转载)
转载: https://www.cnblogs.com/shushen/p/5311828.html 弹簧质点模型的求解方法包括显式欧拉积分和隐式欧拉积分等方法,其中显式欧拉积分求解快速,但积分步长 ...
- 微信小程序navigator页面跳转失效原因
在编写小程序时遇到一个问题:使用 <navigator url='/pages/lists/index'>...</navigator>进行跳转没有反应.控制台也没有报错,ap ...
- chrome安装react-devtools开发工具
我开始安装react-devtools的时候 百度了一波,都是写的不清不楚,官网又都是英文的 也不是完全理解,经过一番折腾出来以后,写个文档记录一下,也可避免新手首次安装走弯路 我安装react-de ...
- 在Angular4中使用ng2-baidu-map详解
一.引言 之前在Angular4使用过百度地图,记录一下踩过的坑 二.实现 1.安装 npm install angular2-baidu-map 2.在app.module.ts配置 ak key在 ...
- chattr lsattr文件隐藏属性
chattr [-RV][-v<版本编号>][+/-/=<属性>][文件或目录...] lsattr [-adlRvV][文件或目录...] 改变/显示文件隐藏属性 chatt ...
- [日期工具分享][Shell]为特定命令依次传入顺序日期执行
[日期工具分享][Shell]为特定命令依次传入顺序日期执行 使用方式: <本脚本文件名(必要时需要全路径)> <要执行的命令所在的文件名> <开始日期> < ...
- TVM代码生成codegen