python 皮尔森相关系数
皮尔森理解
皮尔森相关系数(Pearson correlation coefficient)也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
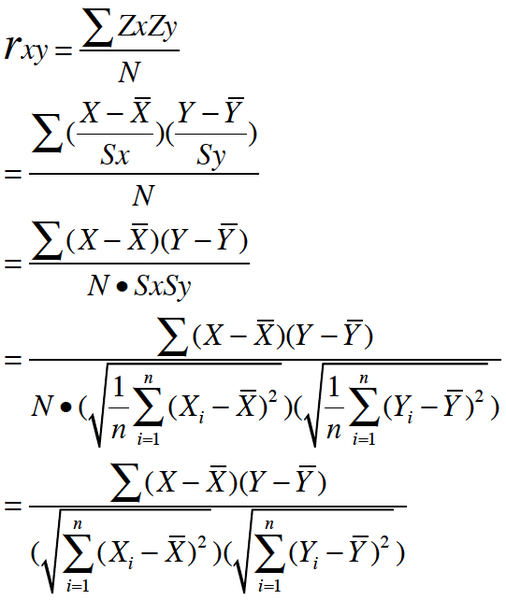
简单的相关系数的分类
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r 的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。
python 实现
# encoding:utf-8
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plot
import math
#target_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data")
#rockVMines = pd.read_csv(target_url ,header=None,prefix="V") #prefix前缀
rockVMines = pd.read_csv('../rockdata.txt',header=None,prefix="V") #prefix前缀
row2 = rockVMines.iloc[1,0:60]
row3 = rockVMines.iloc[2,0:60]
n = len(row2)
mean2 = row2.mean()
mean3 = row3.mean()
t2=0 ; t3=0;t1=0
for i in range(n):
t2 += (row2[i] - mean2) * (row2[i] - mean2) / n
t3 += (row3[i] - mean3) * (row3[i] - mean3) / n
r23=0
for i in range(n):
r23 += (row2[i] - mean2)*(row3[i] - mean3)/(n* math.sqrt(t2 * t3))
print r23
corMat = DataFrame(rockVMines.corr()) #corr 求相关系数矩阵
print corMat
plot.pcolor(corMat)
plot.show()
python 皮尔森相关系数的更多相关文章
- Spearman秩相关系数和Pearson皮尔森相关系数
1.Pearson皮尔森相关系数 皮尔森相关系数也叫皮尔森积差相关系数,用来反映两个变量之间相似程度的统计量.或者说用来表示两个向量的相似度. 皮尔森相关系数计算公式如下:
- 【ML基础】皮尔森相关系数(Pearson correlation coefficient)
前言 参考 1. 皮尔森相关系数(Pearson correlation coefficient): 完
- spark MLlib 概念 1:相关系数( PPMCC or PCC or Pearson's r皮尔森相关系数) and Spearman's correlation(史匹曼等级相关系数)
皮尔森相关系数定义: 协方差与标准差乘积的商. Pearson's correlation coefficient when applied to a population is commonly r ...
- 相关性系数及其python实现
参考文献: 1.python 皮尔森相关系数 https://www.cnblogs.com/lxnz/p/7098954.html 2.统计学之三大相关性系数(pearson.spearman.ke ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (二)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- python 推荐算法
每个人都会有这样的经历:当你在电商网站购物时,你会看到天猫给你弹出的“和你买了同样物品的人还买了XXX”的信息:当你在SNS社交网站闲逛时,也会看到弹出的“你可能认识XXX“的信息:你在微博添加关注人 ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (四)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (三)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- Python金融量化
Python股票数据分析 最近在学习基于python的股票数据分析,其中主要用到了tushare和seaborn.tushare是一款财经类数据接口包,国内的股票数据还是比较全的 官网地址:http: ...
随机推荐
- VC++中如何复制对话框资源
法1: 在你的工程中添加另一个工程的rc文件,这时资源视图中就会出现两个rc,从后加的rc中拷贝资源到你自己工程的rc中就可以了. 法2:vc中如何拷贝一个工程的对话框资源到另一个工程 ...
- Entity Framework6测试使用
Entity Framework6安装完成后测试下 上一篇中完成了对Entity Framework6的下载安装,一下做一个简单的数据添加测试 1.创建一个简单的控制台测试项目 2.创建实体数据模型 ...
- C#设计模式--装饰器模式
0.C#设计模式-简单工厂模式 1.C#设计模式--工厂方法模式 2.C#设计模式--抽象工厂模式 3.C#设计模式--单例模式 4.C#设计模式--建造者模式 5.C#设计模式--原型模式 6.C# ...
- 23种设计模式之模板方法(Template Method)
模板方法模式是一种类的行为型模式,用于定义一个操作中算法的骨架,而将一些步骤延迟到子类中.模板方法模式使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤,其缺点是对于不同的实现,都需要定义 ...
- Express 4.x Node.js的Web框架----《转载》
本文使用node.js v0.10.28 + express 4.2.0 1 Express概述 Express 是一个简洁而灵活的node.js的MVC Web应用框架,提供一系列强大特性创建各种W ...
- vue--使用定时器的问题
https://blog.csdn.net/ywl570717586/article/details/79963162
- Java String, StringBuffer和StringBuilder实例
1- 分层继承2- 可变和不可变的概念3- String3.1- 字符串是一个非常特殊的类3.2- String 字面值 vs. String对象3.3- String的方法3.3.1- length ...
- HDU 6447 - YJJ's Salesman - [树状数组优化DP][2018CCPC网络选拔赛第10题]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6447 Problem DescriptionYJJ is a salesman who has tra ...
- iOS-相关集合类
第一:NSArrary 1.1:集合的基本方法 1.创建集合 NSArray 是不可变数组,一旦创建完成就不能够对数组进行,添加,删除等操作 NSArray * array = [[NSArray ...
- hmm三个问题
现在,重点是要了解并解决HMM 的三个问题. 问题1,已知整个模型,我女朋友告诉我,连续三天,她下班后做的事情分别是:散步,购物,收拾.那么,根据模型,计算产生这些行为的概率是多少. 问题2,同样知晓 ...