机器学习实战-KNN
KNN算法很简单,大致的工作原理是:给定训练数据样本和标签,对于某测试的一个样本数据,选择距离其最近的k个训练样本,这k个训练样本中所属类别最多的类即为该测试样本的预测标签。简称kNN。通常k是不大于20的整数,这里的距离一般是欧式距离。
对于上边的问题,①计算测试样本与训练样本的距离,②选择与其最近的k个样本,③排序,选择k个样本所属类别最多作为预测标签
KNN问题的python实现代码
import numpy as np
import operator
import matplotlib.pyplot as plt def createDataSet():
group = np.array([[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]])
lables=['A','A','B','B']
return group,lables def classify1(inX,dataSet,labels,k):
#距离计算
dataSetSize =dataSet.shape[0]#得到数组的行数。即知道有几个训练数据
diffMat=np.tile(inX,(dataSetSize,1))-dataSet #tile:numpy中的函数。tile将原来的一个数组,扩充成了4个一样的数组。diffMat得到了目标与训练数值之间的差值。
sqDiffMat=diffMat**2 #各个元素分别平方
sqlDistances=sqDiffMat.sum(axis=1) #对应列相乘,即得到了每一个距离的平方
distances=sqlDistances**0.5 #开方,得到距离。 #[ 1.3453624 1.41421356 0.2236068 0.1 ]
sortedDistIndicies=distances.argsort() #升序排列 y=array([])将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y [3 2 0 1]
#选择距离最小的k个点
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1 #get():该方法是访问字典项的方法,即访问下标键为numOflabel的项,如果没有这一项,那么初始值为0。然后把这一项的值加1。#{'B': 2, 'A': 1}
#排序
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #operator模块提供的itemgetter函数用于获取对象的哪些维的数据 #[('B', 2), ('A', 1)]
"""
operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为一些序号(即需要获取的数据在对象中的序号),下面看例子。
a = [1,2,3]
>>> b=operator.itemgetter(1) //定义函数b,获取对象的第1个域的值
>>> b(a)
2
>>> b=operator.itemgetter(1,0) //定义函数b,获取对象的第1个域和第0个的值
>>> b(a)
(2, 1)
要注意,operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。
"""
return sortedClassCount[0][0]
对于上边方法的测试:
>>> group,lables=createDataSet()
>>> classify1([0,0],group,lables,3)
通过上边的结果得到了结果:B
上边全部过程是使用KNN算法的最基本的也是最核心的部分。
下边用来解决实际问题。
问题描述:



如果想要使用KNN算法,首先需要处理海伦收集到的数据,把收集到的数据转化为分类器可以接受的形式:
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = np.zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
通过上边的过程已经把数据格式化为KNN分类器需要的形式,但是,自己查看数据,以一行数据为例,数据的内容是:
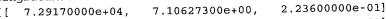
通过观察,可以得到,不同特征值的数据的数量级是不一样的,如果这个时候直接使用KNN中的计算距离的方法,则容易造成数据倾斜,因此增加了一个归一化的过程,归一化的公式为:
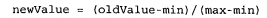
min,max分别是某一个特征的最大数值和最小数值,通过上边的过程,数据被归一化为一个0-1之间的数值,归一化的pyhton实现源码是:
#[ 1.44880000e+04 7.15346900e+00 1.67390400e+00]数据的中有的特别大有的特别小,在之后的计算数据的时候大的数据会影响很大,因此需要归一化
def autoNorm(dataSet):
minVals = dataSet.min(0) #min() 方法返回给定参数的最小值,参数可以为序列,即在这个题目中返回每列数据的最小值
maxVals = dataSet.max(0)
ranges = maxVals - minVals #差值
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (m,1))
normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
至此,数据处理阶段已经全部完成,而接下来的工作就是使用KNN算法进行预测,并估计算法的准确度
def datingClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]#得到数组的行数。即知道有几个训练数据
numTestVecs = int(m*hoRatio) #哪些用来当测试集哪些用来当训练集
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify1(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) #第一个参数树测试集,第二个参数是训练集,第三个参数是类标签,第四个参数是k
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount += 1.0
print("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print(errorCount)
在上边的过程中,把数据集分为训练集和测试集,验证测试集中的每一条数据的测试结果和真实结果的差别。并验证测试数据的准确度。
输入某人的信息,预测出对方的喜欢程度
#输入某人的信息,便得出对对方喜欢程度的预测值
def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(np.raw_input("percentage of time spent playing video games?"))
ffMiles = float(np.raw_input("frequent flier miles earned per year?"))
iceCream = float(np.raw_input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = np.array([ffMiles, percentTats, iceCream])
classifierResult = classify1((inArr - minVals)/ranges, normMat, datingLabels,3)
print('You will probably like this person: ', resultList[classifierResult - 1])
机器学习实战-KNN的更多相关文章
- 《机器学习实战-KNN》—如何在cmd命令提示符下运行numpy和matplotlib
问题背景:好吧,文章标题是瞎取得.平常用cmd运行python代码问题不大,我在学习<机器学习实战>这本书时,发现cmd无法运行import numpy as np以及import mat ...
- 机器学习实战kNN之手写识别
kNN算法算是机器学习入门级绝佳的素材.书上是这样诠释的:“存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都有标签,即我们知道样本集中每一条数据与所属分类的对应关系.输入没有标签的新数据 ...
- 机器学习实战knn
最近在学习这本书,按照书上的实例编写了knn.py的文件,使用canopy进行编辑,用shell交互时发现运行时报错: >>> kNN.classify0([0,0],group,l ...
- sklearn机器学习实战-KNN
KNN分类 KNN是惰性学习模型,也被称为基于实例的学习模型 简单线性回归是勤奋学习模型,训练阶段耗费计算资源,但是预测阶段代价不高 首先工作是把label的内容进行二值化(如果多分类任务,则考虑On ...
- 机器学习实战笔记——KNN约会网站
''' 机器学习实战——KNN约会网站优化 ''' import operator import numpy as np from numpy import * from matplotlib.fon ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 算法代码[置顶] 机器学习实战之KNN算法详解
改章节笔者在深圳喝咖啡的时候突然想到的...之前就有想写几篇关于算法代码的文章,所以回家到以后就奋笔疾书的写出来发表了 前一段时间介绍了Kmeans聚类,而KNN这个算法刚好是聚类以后经常使用的匹配技 ...
- 机器学习实战 之 KNN算法
现在 机器学习 这么火,小编也忍不住想学习一把.注意,小编是零基础哦. 所以,第一步,推荐买一本机器学习的书,我选的是Peter harrigton 的<机器学习实战>.这本书是基于pyt ...
- 基于kNN的手写字体识别——《机器学习实战》笔记
看完一节<机器学习实战>,算是踏入ML的大门了吧!这里就详细讲一下一个demo:使用kNN算法实现手写字体的简单识别 kNN 先简单介绍一下kNN,就是所谓的K-近邻算法: [作用原理]: ...
随机推荐
- SpringBoot系列八:SpringBoot整合消息服务(SpringBoot 整合 ActiveMQ、SpringBoot 整合 RabbitMQ、SpringBoot 整合 Kafka)
声明:本文来源于MLDN培训视频的课堂笔记,写在这里只是为了方便查阅. 1.概念:SpringBoot 整合消息服务 2.具体内容 对于异步消息组件在实际的应用之中会有两类: · JMS:代表作就是 ...
- TXT文件用法大全【荐】--------按键精灵
来源:全文链接 (3)读取TXT文件指定某一行的第?到第?个字 UserVar t=2 "读出txt第几行文本" UserVar i=5 "从第几个字开始读取" ...
- angular.extend深拷贝(deep copy)
在用到angular.extend的时候,正好碰到一个对象,是层层嵌套的Array, 结果发现只能extend第一层,查阅官文档,确实不支持deep copy: Note: Keep in mind ...
- 【python-proxy by sockets5】pysocks
pip install pysocks https://stackoverflow.com/questions/2317849/how-can-i-use-a-socks-4-5-proxy-with ...
- Salience Model
Who is a stakeholder? Simply anyone with a stake in the project either direct or indirect. PMBOK say ...
- [Module] 03 - Software Design and Architecture
本篇涉及内容: ORM框架(无需再用contentprovider或者sqlitedatebasehelper之类的古董工具了) 规划各种业务Bean文件(配合ORM框架) 设计一个好的请求基类(Ba ...
- android studio 导入第三方库的记录
android studio 导入第三方库的记录.jar包 和 库 一.jar包 1.jar包的话很简单,首先换成project模式,将你要用的jar包复制到lib下面.如图 2.然后右键选择Add ...
- Eclipse------新建文件时没有JSP File解决方法
1.为没有web选项的eclipse添加web and JavaEE插件 .在Eclipse中菜单help选项中选择install new software选项 .在work with 栏中输入 Ju ...
- ios开发之--tableview刷新某一个区和某一行
在开发中,有时候,我们不需要刷新整个表,只需要刷新局部数据即可,具体代码如下: //section刷新 NSIndexSet *indexSet=[[NSIndexSet alloc]initWith ...
- iOS 添加Resource bundle target(静态库中使用图片等资源)
一.首先将资源文件打包成bundle 新建工程:File -> New -> Project... -> OS X -> Framework & Library -&g ...