elasticsearch分词器ik
1. 下载和es配套的版本
git clone https://github.com/medcl/elasticsearch-analysis-ik
2. 编译
- cd elasticsearch-analysis-ik/
- mvn clean package
3. 将release下的zip包拷贝至es/plugins目录下解压,并命名为ik
- cd elasticsearch-6.1.1-node3/plugins/
- tar zxvf elasticsearch-analysis-ik-6.1.1.zip
- unzip elasticsearch-analysis-ik-6.1.1.zip
- mv elasticsearch-analysis-ik-6.1.1.zip ../../
- mv elasticsearch ik
4. 重启es
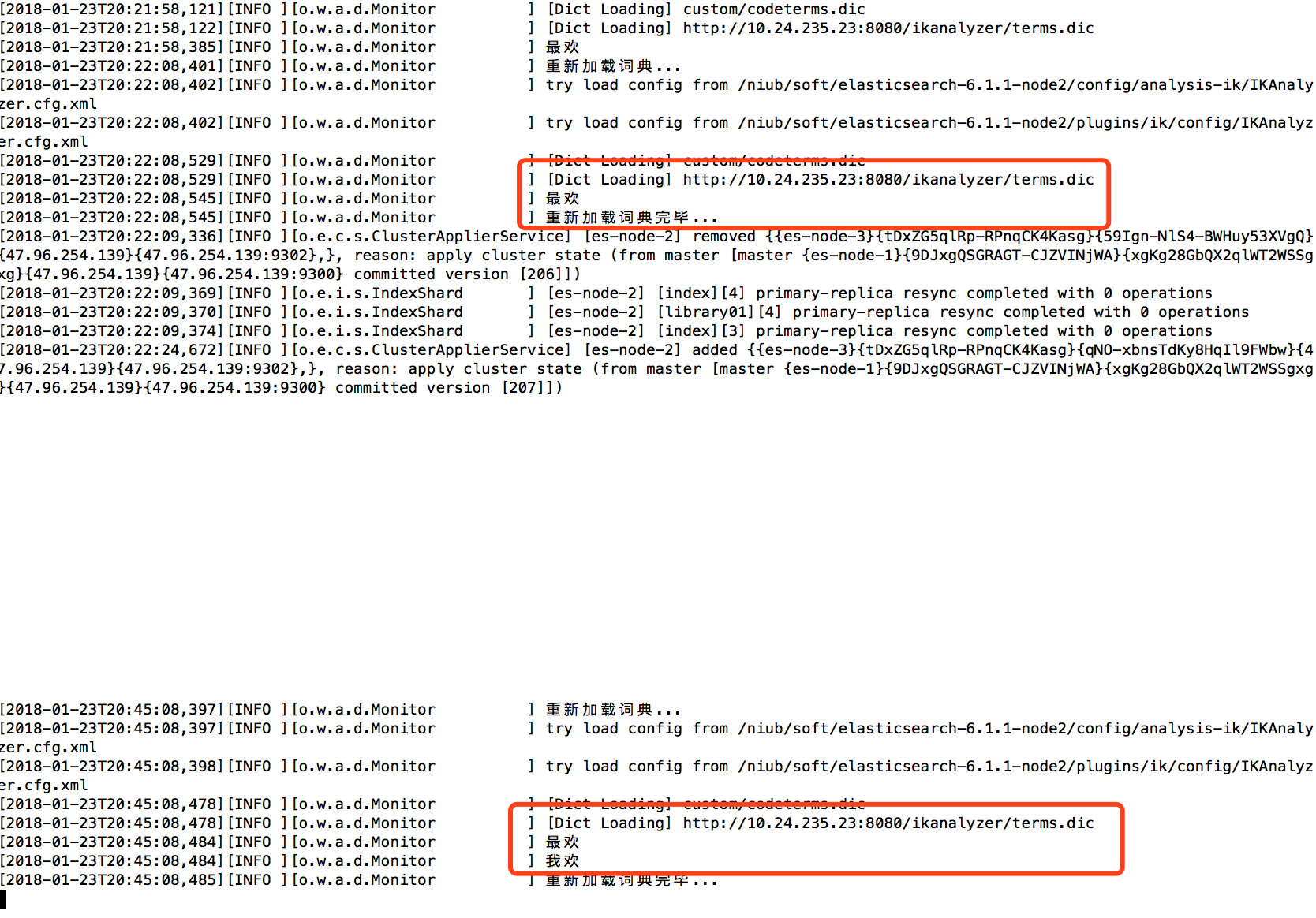
5. 热更新IK分词
ik热更新1分钟发一次请求head请求,检查last modify time 和etag。有变化,则更新。
官方文档很详细:https://github.com/medcl/elasticsearch-analysis-ik
坑:
添加《热更新 IK 分词 》后,
<entry key="remote_ext_dict">http://10.24.235.23:8080/ikanalyzer/terms.dic</entry>
启动抛下面的错:
access denied ("java.net.SocketPermission" "10.24.235.23:8080" "connect,resolve")
解决:
- vim /etc/alternatives/jre_1.8.0/lib/security/java.policy
- 添加:
- permission java.net.SocketPermission "10.24.235.23:8080","accept";
- permission java.net.SocketPermission "10.24.235.23:8080","listen";
- permission java.net.SocketPermission "10.24.235.23:8080","resolve";
- permission java.net.SocketPermission "10.24.235.23:8080","connect";
elasticsearch分词器ik的更多相关文章
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
- 如何给Elasticsearch安装中文分词器IK
安装Elasticsearch安装中文分词器IK的步骤: 1. 停止elasticsearch 2.2的服务 2. 在以下地址下载对应的elasticsearch-analysis-ik插件安装包(版 ...
- 沉淀再出发:ElasticSearch的中文分词器ik
沉淀再出发:ElasticSearch的中文分词器ik 一.前言 为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了 ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 如何在Elasticsearch中安装中文分词器(IK+pinyin)
如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题--中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组. ...
- elasticsearch插件安装之--中文分词器 ik 安装
/** * 系统环境: vm12 下的centos 7.2 * 当前安装版本: elasticsearch-2.4.0.tar.gz */ ElasticSearch中内置了许多分词器, standa ...
- docker 安装ElasticSearch的中文分词器IK
首先确保ElasticSearch镜像已经启动 安装插件 方式一:在线安装 进入容器 docker exec -it elasticsearch /bin/bash 在线下载并安装 ./bin/ela ...
随机推荐
- POJ-1189 钉子和小球(动态规划)
钉子和小球 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 7452 Accepted: 2262 Description 有一个 ...
- poj3347 Kadj Squares【计算几何】
Kadj Squares Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 3594 Accepted: 1456 Desc ...
- HDU 5512 - Pagodas - [gcd解决博弈]
题目链接:http://acm.split.hdu.edu.cn/showproblem.php?pid=5512 Time Limit: 2000/1000 MS (Java/Others) Mem ...
- POJ 1185 - 炮兵阵地 & HDU 4539 - 郑厂长系列故事——排兵布阵 - [状压DP]
印象中这道题好像我曾经肝过,但是没肝出来,现在肝出来了也挺开心的 题目链接:http://poj.org/problem?id=1185 Time Limit: 2000MS Memory Limit ...
- SQL Fundamentals || Single-Row Functions || 通用函数 General function || (NVL,NVL2,NULLIF,DECODE,CASE,COALESCE)
SQL Fundamentals || Oracle SQL语言 SQL Fundamentals: Using Single-Row Functions to Customize Output使用单 ...
- 在选定合适的执行引擎之后,通过敏感字段重写模块改写 SQL 查询,将其中的敏感字段根据隐藏策略(如只显示后四位)进行替换。而敏感字段的隐藏策略存储在 ranger 中,数据管理人员可以在权限管理服务页面设置各种字段的敏感等级,敏感等级会自动映射为 ranger 中的隐藏策略。
https://mp.weixin.qq.com/s/4G_OvlD_5uYr0o2m-qPW-Q 有赞大数据平台安全建设实践 原创: 有赞技术 有赞coder 昨天
- PLSQL过程创建和调用
存储过程 创建过程范例 create or replace procedure pro_kingsql_p1( p_one in varchar2,--可以传入参数 p_two out varchar ...
- linux系统java的安装
(一)下载java8 下载链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html ...
- 【make install】自定义安装目录,添加动态链接库 【--prefix】 【ldconfig】 【LD_LIBRARY_PATH】
怎么卸载make install安装的软件? https://www.zhihu.com/question/20092756 怎么指定安装目录以及对应的添加动态库的方法 linux库在不指定安装路径时 ...
- 交换机-查看mac地址表
1.使用交换机命令行 en 或者 enable 进入特权模式 Switch> Switch>en Switch# Switch# 2.查看交换机中的MAC地址表 Switch#sh ...