用深度学习LSTM炒股:对冲基金案例分析
英伟达昨天一边发布“全球最大的GPU”,一边经历股价跳水20多美元,到今天发稿时间也没恢复过来。无数同学在后台问文摘菌,要不要抄一波底嘞?
今天用深度学习的序列模型预测股价已经取得了不错的效果,尤其是在对冲基金中。股价数据是典型的时间序列数据。

什么是序列数据呢?语音、文字等这些前后关联、存在内有顺序的数据都可以被视为序列数据。
将序列模型应用于语音和文字,深度学习在语音识别、阅读理解、机器翻译等任务上取得了惊人的成就。
具体怎么操作?效果又如何呢?来看文摘菌今天带来的这篇深度学习炒股指南。
对冲基金是深度学习应用中具有吸引力的领域之一,也是投资基金的一种形式。不少金融组织从投资者那里筹集资金后对其进行管理,并通过分析时间序列数据来做出一些预测。在深度学习中,有一种适用于时间序列分析的架构是:递归神经网络(RNNs),更具体地说,是一种特殊类型的递归神经网络:长短期记忆网络(LSTM)。
RNNs维基解释:
https://en.wikipedia.org/wiki/Recurrent_neural_network
LSTM 维基解释:
https://en.wikipedia.org/wiki/Long_short-term_memory
LSTMs能够从时间序列数据中捕捉最重要的特征并进行关联建模。股票价格预测模型是关于对冲基金如何使用此类系统的典型案例,使用了Python编写的PyTorch框架进行训练,设计实验并绘制结果。
在介绍真实案例之前,我们先了解一下深度学习的基础:
- 首先,引入深度学习这个抽象概念。
- 其次,引入RNNs(或更具体地说是LSTMs)以及它们如何进行时间序列分析。
- 接着,让读者熟悉适合深度学习模型的金融数据。
- 接着,举一个实例来说明一支对冲基金如何使用深度学习预测股票价格。
- 最后,就如何使用深度学习来提高对现有或新购对冲基金的表现提供可操作的建议。
介绍用深度学习进行交易的案例
金融行业最具挑战性和令人兴奋的任务之一便是:预测未来股价是上涨还是下跌。据我们所知,深度学习算法非常擅长解决复杂的任务,因此深度学习系统是否能够成功地解决预测未来价格这个问题是值得尝试的。
股价预测:
https://www.toptal.com/machine-learning/s-p-500-automated-trading
人工神经网络这个概念已经存在了很长一段时间,但由于硬件受限,一直无法进行深度学习方面的快速实验。十年前,Nvidia为其Tesla系列产品研发的高速计算的图形处理单元(GPUs)促进了深度学习网络的发展。除了在游戏和专业设计程序中提供更高质量的图形显示外,高度并行化的GPUs也可以计算其他数据,而且在很多情况下,它们的表现远优于CPUs。
Nvidia Tesla维基解释:
https://en.wikipedia.org/wiki/Nvidia_Tesla
在金融领域应用深度学习的科学论文并不多,但是金融公司对深度学习专家却有很大的需求,显然,这些公司认识到了深度学习的应用前景。
本文将尝试说明:为什么深度学习在用金融数据来构建深度学习系统时越来越受欢迎,同时也会介绍LSTMs这种特殊的递归神经网络。我们将概述如何使用递归神经网络解决金融相关问题。
本文还以对冲基金如何使用深度学习系统为例进行典型案例分析,并展示实验过程及结果。同时我们将分析如何提高深度学习系统性能,以及如何通过引进人才(如需要什么样背景的深度学习人才)来搭建应用于对冲基金的深度学习系统。
是什么使对冲基金与众不同
在我们进入这个问题的技术层面之前,我们需要解释的是什么使对冲基金与众不同。首先要明白的是,什么是对冲基金?
对冲基金是一种投资基金,金融组织从投资者筹集资金并将其投入短期和长期投资项目或者不同金融产品。它的形式一般是有限合伙企业或有限责任公司。
对冲基金的目标是最大化回报,回报是其在特定时间段内净值的收益或损失。普遍认为,投资风险越大,相应的回报或损失也越大。
为了获得良好的回报,对冲基金依赖各种投资策略,试图通过利用市场低效率来赚钱。由于对冲基金有普通投资基金所不允许的各种投资策略,其并未被认定为一般基金,也不像其他基金那样由国家监管。
因此他们不需要公布他们的投资策略和业务结果,这可能会使相关经营活动充满风险。虽然一些对冲基金产生的收益超过市场平均水平,但也有一些损失了资金。其中一些的损失无法挽回,也有一些对冲基金的结果是可逆的。
通过投资对冲基金,投资者可以增加基金的净值。不过,并不是所有人都可以投资于对冲基金,它只适用于少数富有的投资者。通常,想要参与对冲基金投资的人需要获得认证。
这意味着他们必须在金融监管法律方面拥有特殊地位。不同国家对于“特殊地位”的认定有所不同。通常,投资者的净资产需要非常高——不仅是个人,而且银行和大公司也可以在对冲基金中运作。该认证旨在让那些有必要投资知识的个人才能参与其中,从而保护经验不足的小型投资者免受风险。
美国是全球金融市场最发达的国家,因此本文主要参考美国的监管体系。在美利坚合众国,美国证券交易委员会(SEC)的D规则501规定了“认可投资者”一词。
根据这一规定,认可的投资者可以是:
- 银行
- 私营企业
- 组织机构
- 提供或出售证券的发行机构的董事,执行官和普通合伙人
- 个人净资产或与该人配偶合资净值超过1,000,000美元的自然人
- 自然人在最近两年每个年度的个人收入超过20万美元,或与该人的配偶每年在该年度的共同收入超过30万美元,并且当年的预期收入也达到相同的水平。
- 信托资产总额超过5,000,000美元
- 所有股权拥有者均为认可投资者的实体
对冲基金管理者管理对冲基金时必须要找到一种方法形成竞争优势从而取得成功,即需比竞争对手更具创造力,带来更大价值。这是一个非常有吸引力的职业选择,因为如果一个人擅长管理基金,就可能从中获利许多。
另一方面,如果很多对冲基金管理者的决定很糟糕,他们不仅不会获得收益,还会造成负面影响。最好的对冲基金管理者可以获得行业中薪酬最高的职位。
除了管理费外,对冲基金管理者还可以从资金获利中抽成。这种补偿方式使对冲基金管理者更积极地投资以获得更高的回报,但与此同时,这也会使投资者承担更多风险。
对冲基金简史
第一支对冲基金出现于1949年,由作家和社会学家Alfred Winslow Jones创立。1948,Alfred就当时的投资趋势发表了一篇文章。
他在资金管理方面获得了巨大的成功。利用他的投资创新筹集资金,这种投资创新现在被广泛称为多/空投股票。该策略目前在对冲基金中仍非常受欢迎。股票可以被买入(买入:买多)或卖出(卖出:卖空)。
当股价低但预计股价将会走高时,买入股票(多头),一旦达到高价时并卖出(空头),这正是Alfred所创理论的核心——对预计将升值的股票中持仓多头,对预计将下跌的股票持仓空头。
金融数据和数据集
金融数据属于时间序列数据。时间序列是一系列按时间顺序排列的数据点。通常,时间序列是连续、等间隔的时间序列:即离散时间序列数据。举例来说,海洋潮汐的高度,太阳黑子的数量以及道琼斯工业平均指数的每日收盘价都是时间序列。
这里的历史数据是指过去的时间序列数据。这是预测未来价格走向最重要和最有价值的部分。
网上有一些公开可用的数据集,但通常情况下,数据缺少很多特征——如间隔1天的数据,间隔1小时的数据或间隔1分钟的数据。
具有更丰富特征和更小时间间隔的数据集通常不公开,并且需要高价购买。
更小的间隔意味着更多的时间序列数据在一个固定的时间段内——一年内有365(或366)天,所以最多有365个(或366个)天数据点可用。每天有24小时,所以在一年内有8,760(或8,784)小时数据点,每天有86,400分钟,所以在一年内有525,600(或527,040)分钟的数据点可用。
越多的数据意味着越多的可用信息,也意味着可以更好地判断下一刻会发生什么——当然,如果数据包含足够的特征也可以泛化的很好。
在全球金融危机高峰时期,2007年至2008年的股价数据由于存在偏差,所以可能无法预测近期价格趋势。越小的时间间隔,在固定的时间间隔内就会有更多数据点,从而更容易地预测接下来会发生什么。
如果我们拥有n年内每一纳秒的数据,那么很容易预测下一纳秒会发生什么,同理在股市中,有了一定时间内的数据,在对接下来的情况作预测就容易的多。
当然,这也并不意味通过一系列数据后,只有所作的短期预测才是正确的,长期预测也可以是正确的。
每个短期预测都会产生误差,因此通过链接多个预测,长期预测最终将产生更大的误差而导致预测无效。以下是雅虎财经在线提供的间隔为1天的Google股票数据示例。

数据集中只有日期,开盘价,最高价,最低价和平仓价等五列数据,分别表示交易开放时证券首先交易的价格,即证券在给定交易日上达到的最高价格,给定交易日的最低价格以及当天交易证券的最终价格。
通常,此类数据集中还有两列——“调整后收盘价”和“成交量”,但它们在这里并不相关。调整后收盘价是指调整适用分割和股息分配后的收盘价,而成交量指是在给定时间段内在市场上交易的股票数量。
可以看到数据中缺失了部分日期。这些是证券交易所休市的日子(一般是在周末和假日)。
为了演示深度学习算法,休市的日子使用之前的交易日价格。例如,2010-01-16,2010-01-17,2010-01-18的收盘价格将全部为288.126007,因为这就是2010-01-15。对于我们的算法来说,数据没有间隙是非常重要的,所以我们不会混淆它。
深度学习算法可以通过周末和节假日的数据学习——比如说,了解到在五个工作日后,从最后一个工作日起,会有两天的平价。

这是一张自2010-01-04以来谷歌股价变动的图表。要注意的是,图表中只显示了交易日的变化趋势。
什么是深度学习?
深度学习基于数据表示学习,属于机器学习的一个分支。机器学习不是通过编程,而是从数据中学习得到的算法。它本质上是人工智能的一种方法。
深度学习已经应用到了多个领域:计算机视觉,语音识别,自然语言处理,机器翻译,而且在某些任务中,它的表现甚至超过人类。
深度神经网络是深度学习的核心,它最简单、最基本的例子就是前馈神经网络,如下图所示,一个基本的前馈神经网络包括输入层、输出层和隐藏层。

隐藏层是输入层和输出层之间的多个单独层。我们通常说如果一个神经网络隐藏层的个数大于1,那么这个网络就是深度的。
每一层都由不同数量的神经元组成。这个基本前馈神经网络中的层称之为线性层,线性层中的神经元仅仅将1-D(或者2-D,如果数据是分批输入网络的)的输入和合适的权重相乘并求和,作为1-D或2-D输出的最终结果。
前馈网络中通常引入激活函数(activation function)表示非线性关系,进而对更复杂的非线性问题建模。在前馈神经网络中,数据从输入层流向输出层,并不会反向传播。
神经元之间的连接是加权的。这些权重需要调整以便神经网络对于给定输入返回准确的输出。前馈网络将数据从输入空间映射到输出空间。隐藏层从前一层的特征中提取重要的和更抽象的特征。
通用深度学习管道和机器学习管道一样,都包含以下步骤:
- 数据采集。数据被分成3部分:训练集、验证集和测试集。
- 使用训练集进行多轮(每一轮包含多个迭代过程)训练DNN模型,并在每轮训练后使用验证集进行验证。
- 在不断训练和验证后,测试模型(一个带有固定参数的神经网络实例)。
训练神经网络实际上是通过反向传播算法结合随机梯度下降法来最小化损失函数,以此来不断调整神经元之间的权重。
除了通过学习过程确定的权重,深度学习算法通常还需要设置超参数——一类无法从学习过程获得,但需要在学习过程前确定的参数。如网络层数、网络层中的神经元数、网络层的类型、神经元的类型和初始权重都属于超参数。
在超参数设置中,第一存在硬件限制,目前,在一个GPU上设置一万亿个神经元是不可能的。第二超参数搜索问题属于组合爆炸;彻底搜索所有可能的超参数组合是不可能的,因为这个过程需要无限长的时间。
由于上述原因,超参数的设置通常是随机的,或者采用一些启发式方法和一些论文中提供的知名方法——本文稍后展示一个用于金融数据分析的循环神经网络的超参数设置实例,许多科学家和工程师已经证明循环神经网络在时间序列数据处理方面表现突出。
通常,验证一个超参数对于指定问题的效果是好是坏的最好方法就是做实验。
训练的目的是使得神经网络很好地拟合训练数据。每个训练步骤之后的模型验证和整个训练过程结束后的模型测试都是为了确定模型是否具有良好的泛化能力。
泛化能力强意味着神经网络模型对于新数据也能做出准确的预测。
关于模型选择有两个重要的术语:过拟合和欠拟合。如果一个神经网络对于它所训练的数据太复杂——如果它有太多的参数(网络层数太多,以及/或者网络层中有太多的神经元)——这个神经网络很有可能过拟合。
因为它有足够的能力去拟合所有数据,所以它能很好的适应训练数据,但是这个模型在验证集和测试集上的性能会很差。如果一个神经网络对于它所训练的数据太过简单,这个模型会欠拟合。
此时神经网络在训练集、验证集和测试集中性能都很差,因为它的能力不足以拟合训练数据并且进行泛化。在下图中我们用图形来解释这几个术语。
蓝色的线表示神经网络模型。第一张图表示当神经网络参数较少时,不能拟合训练数据和泛化的情况。第二张图表示在有最优参数数量时,神经网络对新的数据有较好的泛化能力。第三张图表示当神经网络参数太多时,这个模型过拟合训练数据,但是在验证集和测试集中表现不佳。

循环神经网络
神经网络中一个更复杂的版本是循环神经网络(Recurrent neural network)。与前馈神经网络不同,循环神经网络中的数据可以向任意方向流动。RNN可以更好的表示时间序列的相关性。一般循环神经网络的结构如下图所示。

一个循环神经元的表示如下图所示。在t时刻以X_{t}作为输入,返回t时的隐藏状态h_{t}作为输出,隐藏层输出反向传播回神经元。循环神经元展开后的表示如下图右侧部分。X_{t_0}表示t_{0}时刻的点,X_{t_1}表示t_{1}时刻的点,X_{t}表示t时刻的点。通过t_{0},t_{1},…,t_{n}时刻的输入X_{t_0},X_{t_1},…,X_{t_n}获得的输出就叫做隐藏输出,即h_{t_0},h_{t_1},…,h_{t_n}。

最有效的一个循环神经网络架构是LSTM结构。表示如下:
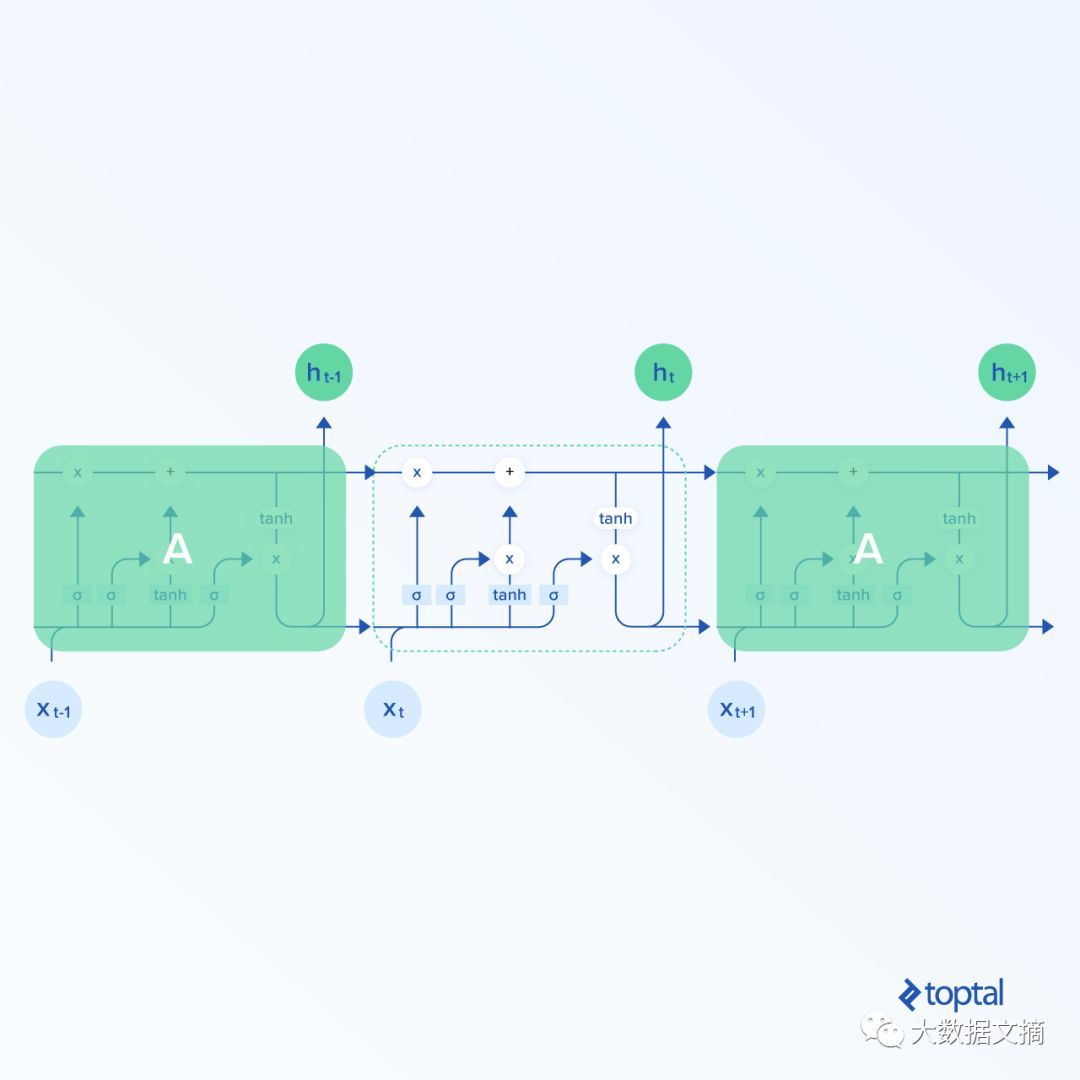
LSTMs与一般的循环神经网络结构一样,但是不同的是循环神经元的结构更为复杂。从上图可以看出,在一个LSTM单元内存在大量的计算。
在这篇文中,LSTM单元可以视为一个黑盒子,但是对于好奇的读者来说,可以看一篇阐述LSTMs内的计算以及其他一些内容的博客。
博客链接:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
我们把神经网络的输入称为“特征向量”。这是一个n维向量,其元素是特征:f_{0},f_{1},f_{2}…,f_{n}。现在,我们来解释循环神经网络是如何应用到与金融相关的任务上的。循环神经网络的输入是[X_{t_0},X_{t_1},X_{t_2},…,X_{t_n}]。这里让n=5。
我们采用Google连续5天(见上面开盘/高/低/收盘数据表)的股票收盘价,选择时间段为2010-01-04到2010-01-08,也就是[[311.35],[309.98],[302.16],[295.13],[299.06]]。这个例子中的特征向量是一维的。时间序列包含5个这样的特征向量。循环神经网络的输出是隐藏特征[h_{t_0},h_{t_1},h_{t_2},…,h_{t_n}]。
这些特征比输入特征[X_{t_0},X_{t_1},X_{t_2},…,X_{t_n}]更加抽象——LSTM需要学习到输入特征的重要部分并将它们映射到隐藏特征空间。
这些隐藏的抽象特征在下一个LSTM单元中传播并提供一组隐藏、更加抽象的特征,这些特征又可以在下一个LSTM单元中传播,以此类推。
在LSTMs连接序列之后,神经网络的最后一个组成部分是线性层(前一节介绍的简单前馈网络的构建部分),线性层将最后的LSTM的隐藏向量映射到一维空间的某个点上,这个点就是该网络的最终输出——时间周期X_{t+1}中预测的收盘价。在这个例子中应该是298.61。
注意:也有少量的LSTM将LSTMs的数量作为一个超参数,该参数通常由经验获得,当然也可以使用一些启发式的方法。如果数据不是很复杂,我们可以使用一些不那么复杂的结构来避免过拟合。如果数据比较复杂,我们使用一个复杂些的模型来防止欠拟合。
在训练过程中,预测的收盘价会跟实际价格比较,其差值采用反向传播算法和梯度下降优化算法(或者其他形式——具体来讲在这篇文章中将使用梯度下降优化算法的“Adam”版本),通过改变神经网络权重来最小化。
模型经过训练和测试之后,在以后的使用中,用户只需要给模型输入数据,模型将会返回预测价值(理想情况下,价格会非常接近未来的真实价格)。
还有一件事要需注意,通常来讲,在训练和测试部分,数据分批次通过网络,对于网络来讲只需要一次就可以计算出多个输出。
下图是这篇文章中使用的架构,包括2个LSTMs栈和一个线性层。

对冲基金算法实验
试着用一个简单的交易策略实现算法,描述如下:如果算法预测明天股价会上升,就买入n(在这个例子里n=1股该公司的股票(做多),否则就卖掉所持有的该公司的所有股票(做空)。
投资组合的初始价值(现金和股票的总价值)设定为100,000美元。每次交易行为将买入n股该公司(以Google为例)的股票或卖出所持有的该公司的所有股票。在初始时刻,系统对该给定公司股票的持有量为0。
需要时刻牢记的是这只是一个非常基础和简单的例子,并不适用于现实生活。若是想使这个模型在实际中很好地应用,仍需要进行很多的研发工作来调整模型。
有些在本例中被忽略的因素,在应用于实际场景时,都应当被纳入考虑中:比如,交易费用没有被考虑在模型之中。另外假设系统可以在每天的同一时间交易并且认为每一天,即使是周末或假期,都是交易日。
对于模型测试,我们使用回溯测试法。该方法利用历史数据,基于开发策略所定义的规则重建过去本该发生的交易。我们将数据集划分为两部分——第一部分作为训练集(作为历史交易数据),第二部分作为测试集(作为未来交易数据)。
模型在训练集上进行训练,训练完成后,我们在第二部分测试集上预测未来交易,从而检验训练得到的模型在不属于训练集的“未来交易”数据上的表现。
用于评价交易策略的指标是夏普比率(Sharpe ratio,年化值,假设一年中的每一天都是交易日,一年有365天:sqrt(365)*mean(returns)/std(returns))),其中收益率定义为p_{t}/p_{t-1} - 1, p_{t}是t时刻的价格。
夏普比率反映了投资组合的收益率与额外的风险之间的比率,所以夏普比率越大越好。一般地,对投资者来说,夏普比率大于1是令人满意的,大于2是非常不错的,而大于3则是极好的。
本例中,只选用来自雅虎的金融数据库(Yahoo Finance dataset)的谷歌历史价格的每日收盘价作为特征。虽然其他特征也有用,但是讨论该数据集中的其他特征(开盘价、最高价、最低价)是否起作用并不在本文讨论的范围之内。
其他一些不在该数据表中的特征可能也有用——例如某一特定分钟的新闻观点或某一天发生的重要事件。
然而,有时候很难将这些特征表示成对神经网络有用的输入并将其与现有特征结合起来。比如,对每一个给定时期,扩充特征向量并加入一个代表新闻观点或特朗普(Trump)在Tweet发表的观点是容易的(-1表示赞同,0表示中立,+1表示不赞同)。
但是,将特定的事件驱动的时刻(苏伊士运河的海盗事件,德克萨斯州炼油厂发现炸弹)加入特征向量并不容易,因为对于每一个这样的特定时刻,我们需要向特征向量中加入一个额外的元素,当该事件发生时令其为1,否则为0。
这样以来,为了考虑所有可能的特定时刻,我们需要向特征向量中加入无穷多个元素。
对那些更加复杂的数据,我们可以定义一些类别,对每一个特定时刻,确定它属于哪一个类别。我们也可以在系统中加入其他公司的股票特征,让模型学习不同公司股票价格之间的相关性。
此外,我们可以将循环层与另一种专门用于计算机视觉的神经网络——卷积神经网络(convolutional neural networks)结合起来以探究视觉特征是如何与某些公司股价相关联的,这也是一种很有趣的做法。
也许我们可以将使用相机拍摄的一张拥挤的火车站的照片作为一个特征,并将其加入神经网络,从而探究神经网络所“看”到的是否与某些公司的股价相关——或许在这个平庸且荒唐的例子中也存在着某些隐藏的信息。
下图展示了平均训练损失随时间逐渐减少的过程,这表明神经网络有足够的能力去拟合训练集。必须强调的是需要将数据进行标准化处理以保证深度学习算法能够收敛。

下图展示了平均测试损失随时间逐渐减少的过程,这表明神经网络对新数据有一定的泛化能力。

该算法具有贪心性质:如果它预测明天股价将上升,那么算法将会立即买入n=1份该公司的股票(如果投资组合中有足够的现金),否则它将会卖出所持有的该公司所有的股票(如果有的话)。
投资的时间段固定为300天。在300天以后,卖出所有股票。训练后的模型在新的数据上的模拟结果如下图所示。下图展现了随着每天做多/做空的交易(或不做交易),投资组合的价值随时间变化的过程。

上述投资模拟的夏普比率为1.48。300天后最终的投资组合的价值为100,263.79美元。如果我们只在第一天买入股票,并在300天后卖出,组合价值为99,988.41美元。
下图展示的是由于神经网络训练得不好而在300天的固定投资时期后亏损的情况。

这一模拟的夏普比率为-0.94。300天后投资组合的最终价值为99,868.36美元。
下面是一个有趣的例子:上述算法具有贪心性质并且仅仅估计了第二天的股价,并且仅仅基于这一预测值作出决策。但仍有可能需要连接多个预测值并且预测未来多期的价格。
比如,有了第一组输入[X_ground_truth_{t0},X_ground_truth_{t1},X_ground_truth_{t2},X_ground_truth_{t3},X_ground_truth_{t4}]和第一个输出[X_ground_truth_{t5}],我们可以把这一预测值输给神经网路来继续预测,即下一组输入为[X_ground_truth_{t1},X_ground_truth_{t2},X_ground_truth_{t3},X_ground_truth_{t4},X_ground_truth_{t5}],此时输出为[X_predicted_{t6}。
类似的,接着下一组输入为X_ground_truth_{t2},X_ground_truth_{t3},X_ground_truth_{t4},X_predicted_{t5},X_predicted_{t6}],由此可以得到[X_predicted_{t7}]等。
这里存在的问题是我们引入了一个预测误差,并且这一误差随着每一步新的预测而不断增加,最终导致了一个很差的长期的预测结果,如下图所示。最开始模型预测值有真实值具有相同的下降趋势,随后停滞,并且随着时间的推移变得越来越差。
对谷歌股票价格进行了简单的深度学习的分析,只要数据量足够大且质量足够好,这一模型几乎可以包含任何金融数据集。但是数据必须是可判别的,并且能够很好地描述和表示问题。

总结
如果模型对于大量的测试都表现得很好并有很强的泛化能力,那么它便可以使对冲基金管理者使用深度学习和算法交易策略来预测未来某一公司的股票价格。
对冲基金管理者可以向系统输入资金金额使其每天完成自动化交易。但是,让自动化交易算法在完全没有任何监督的情况下进行交易绝对不是一个好的选择。
因此对冲基金管理者应当有一些深度学习知识或者是雇佣一个懂得一些必要的深度学习技能的人来监管并判断这一系统是否是去了泛化能力而不适合用于交易了。
一旦系统失去了泛化能力,那么就有必要从头开始训练模型并重新进行测试(可以通过引入更多具有判别性的特征或新的信息——使用模型在上一次训练时没有用到的新的历史数据)。
有时候,数据质量差会导致深度学习模型不能够很好地训练和泛化。在这种情况下,一个经验丰富的深度学习工程师应当能够发现并扭转这种局面。
建立一个深度学习交易系统,你需要对冲基金数据科学家,机器学习/深度学习专家(包括科学家和工程师),熟悉机器学习/深度学习的研发工程师等等。
无论他们熟悉机器学习哪个领域的应用,不管是计算机视觉还是语音识别,老练的专家都能够将他们的经验很好地应用于金融领域。
归根结底,不管是哪方面的应用或产业,深度学习都有相同的基础,因此对有经验的人来说从一个主题切换到另一个都应该是简单的。
我们这里所描述的系统是最基本的,要应用于现实世界,需要进行更多的研发工作来增加收益。可能的系统改进方法包括开发更好的交易策略。
同时收集更多的数据来训练模型也是有帮助的,但是这样的数据一般都很贵。
缩短时间节点间的间隔也能够改善模型。使用更多的特征(如数据集中每一时点对应的新闻观点或重要的事件,尽管难以表示为适用于神经网络的形式)、大量的超参数的格点搜索优化以及循环神经网络结构的探索也能给模型带来改善。
此外,在做大量并行实验和处理大量数据(如果收集到了大量的数据)时,我们还需要更多的计算能力(更强的GPU是必需的)。
用深度学习LSTM炒股:对冲基金案例分析的更多相关文章
- 基于深度学习的文本分类案例:使用LSTM进行情绪分类
Sentiment classification using LSTM 在这个笔记本中,我们将使用LSTM架构在电影评论数据集上训练一个模型来预测评论的情绪.首先,让我们看看什么是LSTM? LSTM ...
- 深度学习-LSTM与GRU
http://www.sohu.com/a/259957763_610300此篇文章绕开了数学公式,对LSTM与GRU采用图文并茂的方式进行说明,尤其是里面的动图,让人一目了然.https://zyb ...
- Android学习笔记之ProgressBar案例分析
(1) <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:to ...
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- Deep-learning augmented RNA-seq analysis of transcript splicing | 用深度学习预测可变剪切
可变剪切的预测已经很流行了,目前主要有两个流派: 用DNA序列以及variant来预测可变剪切:GeneSplicer.MaxEntScan.dbscSNV.S-CAP.MMSplice.clinVa ...
- 深度学习在美团点评推荐平台排序中的应用&& wide&&deep推荐系统模型--学习笔记
写在前面:据说下周就要xxxxxxxx, 吓得本宝宝赶紧找些广告的东西看看 gbdt+lr的模型之前是知道怎么搞的,dnn+lr的模型也是知道的,但是都没有试验过 深度学习在美团点评推荐平台排序中的运 ...
- (转)深度学习(Deep Learning, DL)的相关资料总结
from:http://blog.sciencenet.cn/blog-830496-679604.html 深度学习(Deep Learning,DL)的相关资料总结 有人认为DL是人工智能的一场革 ...
- [源码解析] 深度学习分布式训练框架 horovod (3) --- Horovodrun背后做了什么
[源码解析] 深度学习分布式训练框架 horovod (3) --- Horovodrun背后做了什么 目录 [源码解析] 深度学习分布式训练框架 horovod (3) --- Horovodrun ...
- NLP+词法系列(二)︱中文分词技术简述、深度学习分词实践(CIPS2016、超多案例)
摘录自:CIPS2016 中文信息处理报告<第一章 词法和句法分析研究进展.现状及趋势>P4 CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bce ...
随机推荐
- tmux安装与使用
安装 用法 重点 一prefix前缀键 二window和pane的区分 tmux 按照官方给出的介绍是:终端复用工具.说白了就是可以仅仅在开启一个终端的情况下同时处理多个任务. 比如下面我设置的这样一 ...
- FlytestingToolkit工具派送,懒人的测试思考
工欲善其事必先利其器,在IT路上摸爬这些年,去年我们分享了<Fiddler录制jmeter脚本,干货分享>,今天我们有另外的思考,我懒,故我思考. 下载解压后是这样的: 双击 Flytes ...
- HDU 3364
http://acm.hdu.edu.cn/showproblem.php?pid=3364 经典高斯消元解开关问题 m个开关控制n个灯,开始灯全灭,问到达目标状态有几种方法(每个开关至多一次操作,不 ...
- Texas Instruments matrix-gui-2.0 hacking -- run_script.php
<?php /* * Copyright (C) 2011 Texas Instruments Incorporated - http://www.ti.com/ * * * Redistrib ...
- linux平台程序高精度延时问题select-usleep等
前言 微秒级别的延时... 1.能用 #include <unistd.h> int usleep(useconds_t usec); 微秒级:1/10^-6 2 ...
- PyCharm:ModuleNotFoundError: No module named 'HTMLTestRunner'
PyCharm找不到HTMLTestRunner,还是之前的原因PyCharm和之前命令行安装使用的不是一套资源,需要重新导入 查看旧HTMLTestRunner的路径 在PyCharm找到同样类似的 ...
- HihoCoder - 1501:风格不统一如何写程序
时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi写程序时习惯用蛇形命名法(snake case)为变量起名字,即用下划线将单词连接起来,例如:file_name. ...
- Maze dfs倒行
Pavel loves grid mazes. A grid maze is an n × m rectangle maze where each cell is either empty, or i ...
- 【java规则引擎】《Drools7.0.0.Final规则引擎教程》第3章 3.2 KIE概念&FACT对象
转载:https://blog.csdn.net/wo541075754/article/details/74943236 3.2.1 什么是KIE KIE(Knowledge Is Everythi ...
- LG4455 【[CQOI2018]社交网络】
分析 这题我们先转化为图论模型,发现求的其实就是有向图中以1为根的生成树数量.而关于这一问题存在O(3^n * n^2)的算法,一看数据n=250,发现不行.于是需要更高效的算法--Matrix-Tr ...